Trois manières dont nous avons renforcé la scalabilité d'Elasticsearch


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
"Il faut repousser les limites pour trouver les siennes."
Herbert A. Simon
Chez Elastic, nous nous efforçons d'apporter de la valeur aux utilisateurs en leur garantissant des résultats rapides, pertinents et à grande échelle. La vitesse, la scalabilité et la pertinence sont au cœur de notre ADN. Avec Elasticsearch 7.16, nous nous sommes concentrés sur la scalabilité en repoussant les limites de cette solution afin de fournir une recherche plus rapide, une mémoire moins gourmande et des clusters plus stables. Tout au long de notre parcours, nous avons identifié un éventail de dimensions dans le partitionnement et fait passer Elasticsearch à la vitesse supérieure par la même occasion.
Par le passé, nous vous recommandions d'éviter de créer un nombre infini de partitions dans votre cluster à cause de la surcharge de ressources que cela impliquait. Or, grâce à la nouvelle stratégie d'indexation des flux de données dans Fleet, les cas d'utilisation d'observabilité et de sécurité vont générer davantage de petites partitions. Par conséquent, il est essentiel que nous trouvions de nouvelles manières de gérer ce nombre croissant de partitions. Dans cet article, nous passons en revue trois défis de scaling pour Elasticsearch et expliquons comment nous avons amélioré l'expérience dans la version 7.16 et les suivantes.

Rationalisation de l'autorisation
Imaginez que vous entrez dans un bar, que le videur vous demande votre carte d'identité pour vous y donner accès, puis que le barman fait de même à chaque fois que vous commandez à boire. Voici la façon dont l'autorisation procédait aux vérifications avant la version 7.16 : chaque nœud (la porte d’entrée dans notre exemple) et chaque partition (les commandes de boissons) nécessitaient une vérification de l'autorisation. Et s'il suffisait d'une seule vérification d'identité au moment où vous entrez dans le bar ? Appliquons cette idée à l'autorisation dans Elasticsearch.
Elasticsearch permet aux utilisateurs de configurer un contrôle d'accès basé sur les attributs/rôles afin d'accorder une autorisation précise en fonction des champs, des documents ou des niveaux d'index. Auparavant, le mot authorize se retrouvait dans de nombreuses requêtes de recherche afin que les requêtes non autorisées n'aient pas accès aux données non justifiées. Toutefois, la vigilance de la fonctionnalité d'autorisation a un coût. En outre, une part de cette logique ne se scale pas de manière horizontale à mesure que la taille du cluster grandit. Par exemple, fournir les fonctionnalités requises pour tous les champs de l'ensemble des index au sein d'un grand cluster pourrait prendre plusieurs secondes, voire quelques minutes. La majeure partie de ce temps d'exécution serait consacré à des tâches liées à l'autorisation.
La version 7.16 permet de relever ces défis sur deux fronts :
- Les améliorations algorithmiques accélèrent l'autorisation des requêtes individuelles, qu'il s'agisse d'une requête REST ou d'une communication entre les nœuds au niveau de la couche de transport (c'est-à-dire pour l'ensemble du réseautage interne entre les nœuds) au sein d'un cluster Elasticsearch.
- Dans la plupart des cas, l'autorisation des requêtes internes est héritée des vérifications précédentes ou devient un processus bien moins cher. Avant la version 7.16, Elasticsearch exécutait la même logique que pour la requête externe initiale lors de l'autorisation des requêtes de transport internes au sein du cluster. Cette technique évitait l'introduction d'un éventail d'attaques dans les communications internes entre les nœuds qui permettraient à un utilisateur malveillant de générer des requêtes internes afin de contourner la logique d'autorisation. Il est désormais possible d'arriver au même résultat pour des coûts bien inférieurs en ignorant l'expansion des caractères génériques dans les sous-requêtes, en ignorant l'autorisation pour les requêtes locales de nœuds (c'est-à-dire à l'intérieur du même nœud) et en diminuant le nombre global de requêtes nécessaires pour mener des opérations, comme la recherche.
Diminution des requêtes de partition à l'étape pre-filter
Une nouvelle stratégie de recherche a été mise en œuvre dans la version 7.16 aux étapes pre-filter afin de diminuer le nombre de requêtes jusqu'à atteindre une par nœud correspondant. Avant la version 7.16, la première étape d'une recherche qui essaie de filtrer toutes les partitions d'une requête ne contenant pas de données pertinentes nécessitait une requête par partition depuis le nœud de coordination jusqu'à un nœud de données. Lorsqu'une requête concernait des milliers de partitions simultanément, il fallait envoyer des milliers de requêtes par recherche depuis le nœud de coordination, gérer des milliers de réponses sur le nœud de coordination, mais aussi gérer toutes ces requêtes sur les nœuds de données et y répondre. Si le cluster scalait pour comprendre davantage de nœuds de données, la gestion d'un tel nombre de requêtes était bien plus performante sur ces nœuds, mais pas sur le nœud de coordination.
Avec la version 7.16, la stratégie exécutant l'étape pre-filter a été modifiée afin d'envoyer une seule requête par nœud à ce moment, ce qui permet de couvrir toutes les partitions du nœud concerné. La figure 1 ci-dessous l'illustre parfaitement bien. Ainsi, un cluster contenant des milliers de partitions sur trois nœuds de données verrait le nombre de requêtes réseau effectuées à l'étape initiale de recherche passer de plusieurs milliers à trois au maximum, indépendamment du nombre de partitions sur lequel la recherche porte. Étant donné que le nombre de requêtes en fonction des partitions envoyées avant la version 7.16 contenait globalement les mêmes données que l'ensemble des partitions (c'est-à-dire la requête de recherche), en envoyant une seule requête par nœud, ces informations ne sont plus dupliquées pour plusieurs requêtes. Ainsi, le nombre d'octets à envoyer sur le réseau est considérablement réduit.
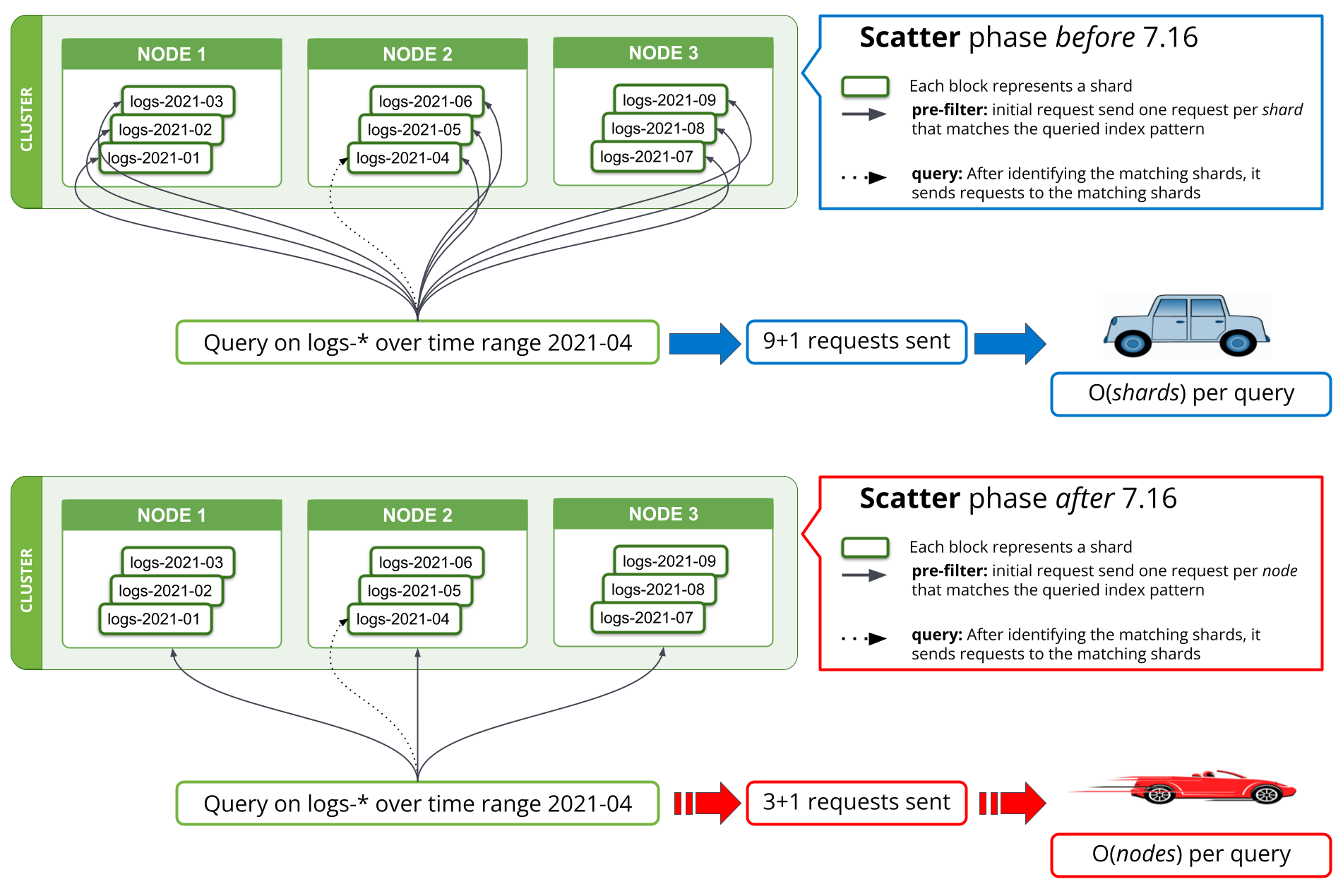
Une mise en œuvre similaire a été effectuée pour field_caps, qui est utilisé par les requêtes *QL et Kibana. En théorie, le nombre de requêtes de recherche économisé sur le réseau est passé de O(shards) à O(nodes) par requête. En pratique, nos résultats comparatifs montrent qu'effectuer une requête dans les logs contenant plusieurs mois de données au sein d'un grand cluster de logging prend désormais moins de 10 secondes contre plusieurs minutes auparavant. Les économies réalisées concernent le nombre de requêtes réseau, diminuant par la même occasion l'utilisation du processeur et de la mémoire dans le cadre de ces opérations.
Diminution de l'empreinte mémoire
Cela peut paraître surprenant, mais les compagnies aériennes ont réalisé des économies considérables en matière de poids en supprimant une seule olive dans les salades qu'elles servaient aux passagers, en utilisant des verres plus fins et en imprimant des magazines de taille plus petite. Nous adoptons une approche similaire dans Elasticsearch en diminuant le coût de la mémoire selon les champs. Même s'il s'agit de quelques kilooctets par champ, en les multipliant par les millions de champs provenant de tous les index au sein d'un cluster, nous avons pu économiser une quantité phénoménale de mémoire.
L'utilisation de la mémoire sur les nœuds de données d'Elasticsearch dépend du nombre d'index, de champs par index et de partitions stockées dans l'état du cluster. Lorsque le nombre d'index est élevé, le segment de mémoire est sans cesse occupé, indépendamment de la charge pesant sur le nœud. Dans la version 7.16, nous avons restructuré l'outil de conception des champs pour text et number, ce qui a diminué leur empreinte mémoire et la mémoire de plus de 90 % uniquement pour conserver ces structures de champs.
Ingestion, recherche et réussite
Depuis le lancement de la version, nous avons observé des améliorations dans les clusters de charge de travail réalistes. Voici quelques schémas illustrant l'effet de la mise à niveau sur ces 60 clusters de nœuds de données.
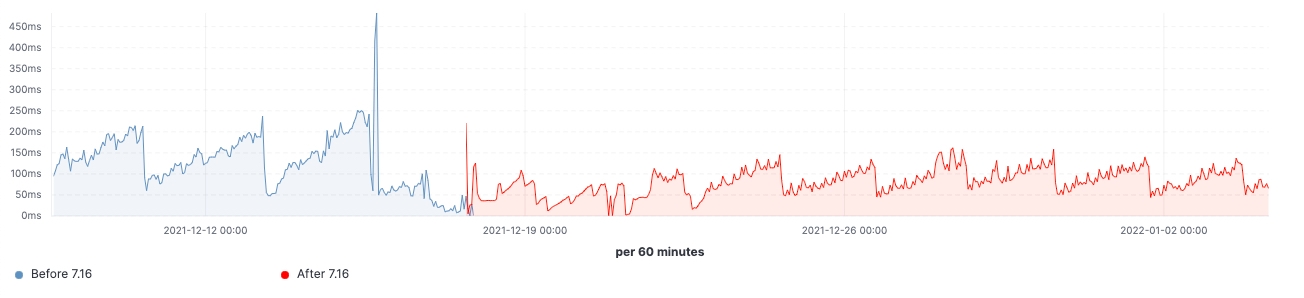
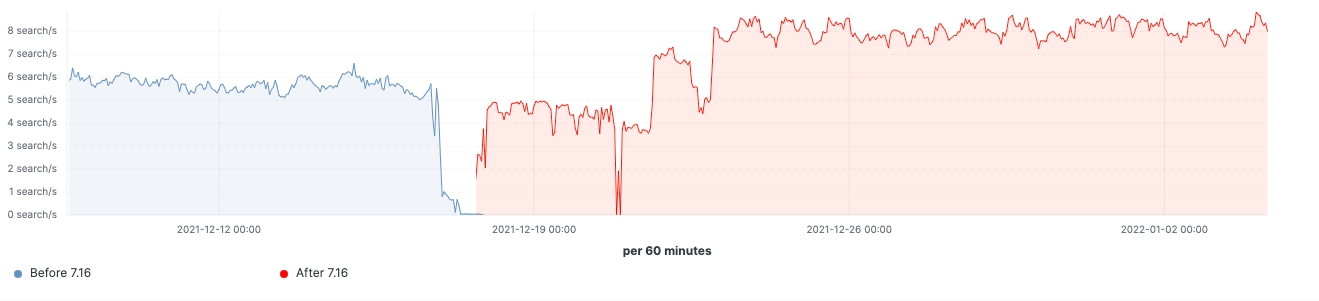
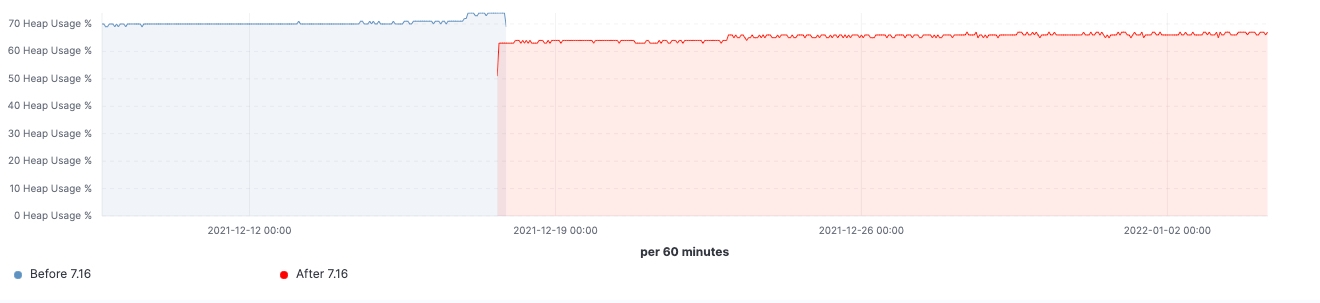
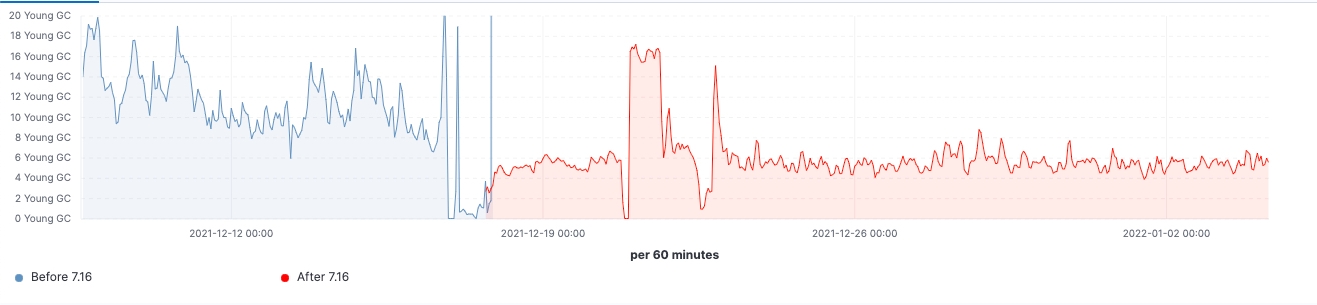
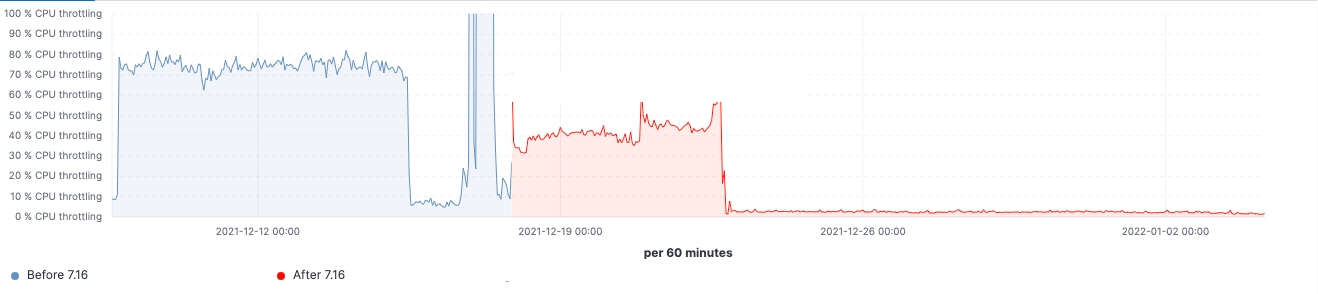
Pour ce cluster, nous avons pu observer une charge de travail cohérente avant et après la mise à niveau. Toutefois, le 99e percentile de la latence de recherche a baissé de manière uniforme, le nombre de recherches (débit) a augmenté et l'utilisation de la mémoire sur les nœuds frozen est considérablement réduite grâce à la diminution de l'empreinte mémoire sur la structure de stockage des données. Ces résultats devraient avoir un impact sur l'ensemble des niveaux de données. Cependant, l'effet le plus notable devrait concerner le niveau frozen où la mémoire est principalement utilisée pour la structure de stockage des données, contrairement aux nœuds hot où la mémoire pourrait être utilisée pour l'indexation, la recherche et d'autres opérations. En fonction de leurs rôles, les nœuds de coordination présentent la diminution la plus significative de la quantité de la récupération de mémoire récente grâce à la réduction du nombre de requêtes dans les partitions à l'étape pre-filter. Enfin, grâce à la meilleure gestion de l'état des clusters, la demande en régulation du processeur sur les nœuds maîtres a considérablement diminué.
Nous avons enquêté sur les raisons pour lesquelles Elasticsearch rencontrait des problèmes de performances lorsqu'elle scalait pour gérer des dizaines de milliers de partitions. Nous nous sommes efforcés d'améliorer la scalabilité dans Elasticsearch 7.16. La gestion d'un nombre phénoménal de partitions et l'explosion du mapping sont les principales causes d'un plantage d'Elasticsearch, une situation toujours susceptible de survenir et à éviter. Grâce aux améliorations apportées dans la version 7.16, si cela arrive, l'impact devrait être moins important. Dans cette version, les améliorations concernent la taille globale du cluster. Ainsi, un nœud maître plus petit peut gérer les mises à jour de l'état du cluster et la coordination de la recherche est rationalisée sur un vaste éventail d'index.
En libérant toute la puissance d'Elasticsearch dans la version 7.16, votre moteur de recherche gagne en rapidité, votre mémoire est moins gourmande et la stabilité de votre cluster est renforcée. Pour bénéficier de tout cela, il vous suffit d'appliquer la mise à niveau ! Nous continuons d'apporter des améliorations en matière de scalabilité. Nous vous ferons part des résultats obtenus lors du lancement de la version 8.x.
Prêt à scaler un cran plus loin encore ?
Les clients qui utilisent déjà Elastic Cloud peuvent accéder à la majorité de ces fonctionnalités directement depuis la console Elastic Cloud. Vous débutez sur Elastic Cloud ? Aucun souci. Consultez nos guides de démarrage rapide (qui sont de petites vidéos de formation pour que vous soyez rapidement opérationnel) ou nos formations gratuites sur les notions de base. Comme toujours, vous pouvez aussi vous lancer avec un essai gratuit d'Elastic Cloud pendant 14 jours. Et si vous préférez une expérience autogérée, vous pouvez choisir de télécharger gratuitement la Suite Elastic.
Pour en savoir plus sur ces fonctionnalités et d'autres sujets, lisez les notes de publication d'Elastic 7.16. Pour connaître d'autres points forts de la Suite Elastic, lisez notre article sur le lancement d'Elastic 7.16.Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer