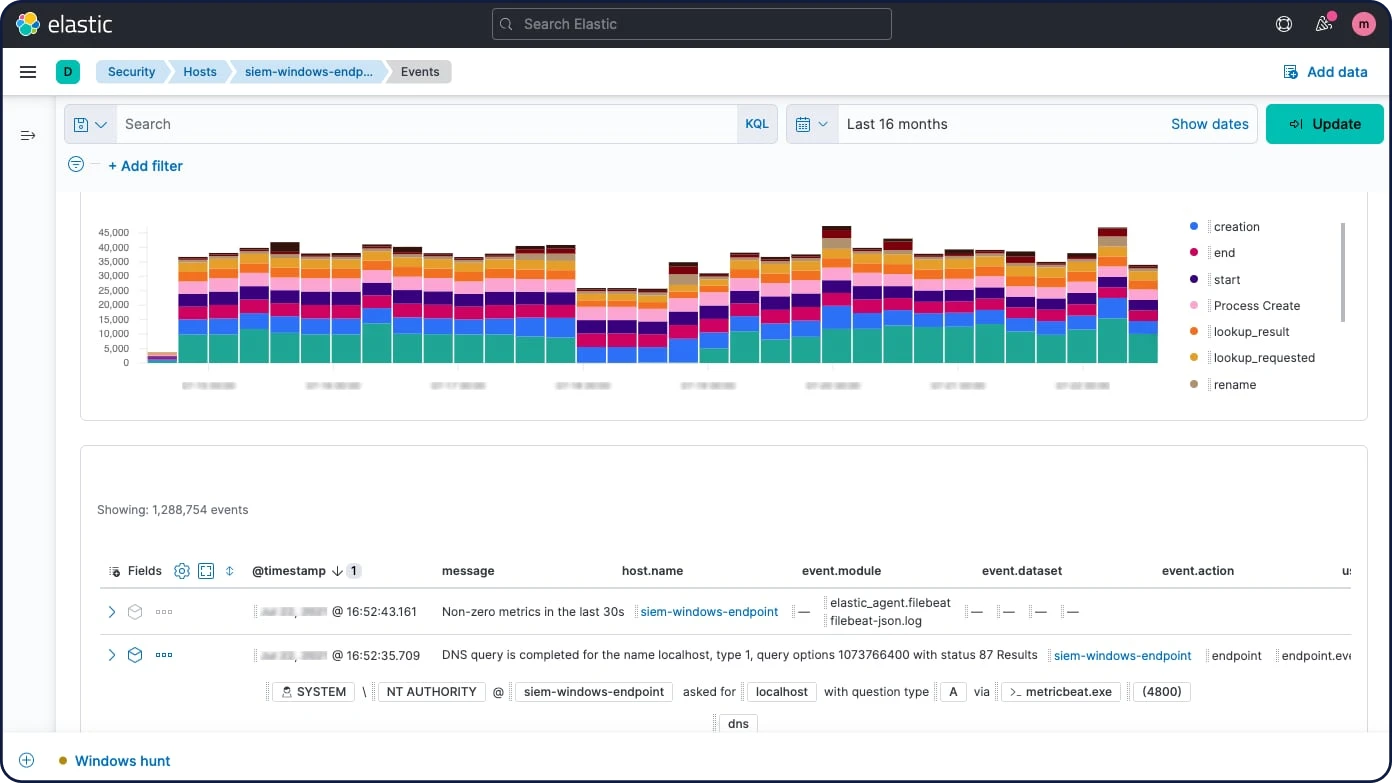
Fonctionnalités d'Elasticsearch
Elasticsearch est un moteur d'analyse et de recherche RESTful distribué qui centralise le stockage de vos données pour que vous puissiez rechercher, indexer et analyser des données de tout acabit.
Ingérer et enrichir
Stockage de données
Flexibilité
Sécurité
Rechercher et analyser
Recherche full-text
Gestion et opérations
Gestion et opérations
Scalabilité et résilience
Ce n'est pas un hasard si, dès l'origine, nous avons opté pour un environnement distribué conçu pour rimer avec tranquillité d'esprit. Nos clusters évoluent en fonction de vos besoins – il suffit d'ajouter un nœud.
Clustering et haute disponibilité
Un cluster est un ensemble constitué d'un ou de plusieurs nœuds (serveurs). Il stocke toutes vos données et vous permet de centraliser l'indexation et la recherche des données sur l'ensemble des nœuds. Les clusters Elasticsearch sont dotés de partitions principales et de copies pour fournir un basculement en cas de panne d'un nœud. Lorsqu'une partition principale tombe en panne, la copie prend sa place.
Découvrir le clustering et la haute disponibilitéRécupération automatique de nœud
Lorsqu'un nœud sort du cluster pour n'importe quelle raison, intentionnelle ou non, le nœud maître réagit en remplaçant le nœud par une copie et en rééquilibrant les partitions. Ces actions ont pour but de protéger le cluster contre la perte de données en s'assurant que toutes les partitions sont entièrement répliquées aussi vite que possible.
En savoir plus sur l'attribution de nœudRééquilibrage automatique des données
Le nœud maître de votre cluster Elasticsearch décide automatiquement quelles partitions attribuer à quels nœuds, et quand déplacer les partitions entre les nœuds pour rééquilibrer le cluster.
Découvrir le rééquilibrage automatique des donnéesScalabilité horizontale
Plus vous utilisez Elasticsearch, plus il scale avec vous. Ajoutez plus de données, plus de cas d'utilisation, et lorsque vous commencez à manquer de ressources, ajoutez simplement un autre nœud à votre cluster pour augmenter sa capacité et sa fiabilité. Enfin, lorsque vous ajoutez plus de nœuds à un cluster, Elasticsearch attribue automatiquement des partitions copies pour que vous soyez préparé pour les événements futurs.
Découvrir la montée en charge horizontaleOpérations de rack
Vous pouvez utiliser des attributs de nœud personnalisés en tant qu'attributs d'opération pour permettre à Elasticsearch de prendre en compte la configuration de votre matériel physique lorsqu'il affecte des partitions. Si Elasticsearch sait quels nœuds se situent sur le même serveur physique, dans le même rack, ou dans la même zone, il peut distribuer la partition principale et les partitions répliquées pour minimiser le risque de perte de toutes les copies de partition en cas de panne.
Découvrir les opérations d'attributionRéplication inter-clusters
La fonctionnalité de réplication inter-clusters (CCR) permet de répliquer les index situés dans des clusters distants sur un cluster local. Cette fonctionnalité peut être utilisée dans des cas d'utilisation de production communs.
Découvrir la CCRReprise d'activité après sinistre : si un cluster principal tombe en panne, un cluster secondaire peut servir de sauvegarde "hot".
Proximité géographique : les lectures peuvent être servies localement et diminuer le temps de réponse du réseau.
Réplication inter-data center
Cela fait longtemps que la réplication inter-data center est une exigence des applications critiques d'Elasticsearch. Auparavant, Elasticsearch recourait à des technologies supplémentaires pour répondre à cette exigence. Grâce à la réplication inter-cluster d'Elasticsearch, vous n'avez pas besoin de technologies supplémentaires pour répliquer des données dans plusieurs data centers, régions ou clusters Elasticsearch.
Découvrir la réplication inter-data centerGestion et opérations
Direction
Elasticsearch comprend un grand nombre d'outils de gestion et d'API qui vous confèrent un contrôle total sur les données, les utilisateurs, les opérations de cluster, et plus encore.
Récupération à partir des snapshots
Les clusters d'Elasticsearch qui utilisent le stockage d'objets dans le cloud peuvent désormais transférer certaines données, comme la réplication et la restauration des partitions provenant des nœuds ES et le stockage d'objets, au lieu de transférer des données entre les nœuds ES, ce qui diminue les coûts de stockage et de transfert des données.
En savoir plus sur la récupération à partir des snapshotsGestion du cycle de vie des index
La gestion du cycle de vie des index (ILM) permet à l'utilisateur de définir et d'automatiser des règles de contrôle de la durée pendant laquelle un index doit être utilisé dans les quatre phases, ainsi que les actions à effectuer dans l'index pendant chaque phase. Cela permet de mieux contrôler le coût des opérations, car on peut placer les données dans des niveaux de ressource différents.
Découvrir l'ILM"Hot" (brûlant) : fréquemment mis à jour et recherché
"Warm" (chaud) : toujours recherché, malgré l'absence de mise à jour
"Cold/Frozen" (froid/glacé) : aucune mise à jour et presque jamais recherché (la recherche est possible, mais plus lente)
"Delete" (supprimer) : l'index n'est plus nécessaire
Niveaux de données
Les niveaux de données constituent une approche formalisée pour répartir les données sur des nœuds hot, warm et cold. C'est un attribut de rôle de nœud qui définit automatiquement la stratégie de gestion du cycle de vie des index de vos nœuds. En attribuant des rôles hot, warm et cold aux nœuds, vous pouvez grandement simplifier et automatiser le processus de déplacement des données, et passer ainsi d'un stockage coûteux à hautes performances à un stockage économique aux performances inférieures, le tout, sans sacrifier la visibilité recherchée.
Découvrir les niveaux de données- Hot : données fréquemment mises à jour et interrogées sur l'instance la plus performante
Warm : données interrogées de temps à autre sur des instances un peu moins performantes
Cold : données en lecture seule, rarement interrogées ; réduction drastique du stockage sans perte de performances, permise par les snapshots interrogeables
Gestion du cycle de vie des snapshots
En tant que gestionnaires de snapshots d'arrière-plan, les API "Snapshot Lifecycle Management" (SLM) permettent aux administrateurs de définir la fréquence à laquelle sont effectués les snapshots d'un cluster Elasticsearch. Grâce à l'interface utilisateur SLM dédiée, les utilisateurs peuvent configurer les règles de conservation applicables à SLM, mais aussi créer, planifier et supprimer automatiquement des snapshots. Cela assure que pour un cluster donné, les sauvegardes nécessaires sont effectuées à une fréquence suffisante pour permettre une restauration conforme aux SLA du client.
Découvrir le SLMSnapshot et restauration
Un instantané est une sauvegarde d'un cluster Elasticsearch en cours d'exécution. Vous pouvez créer un snapshot soit d'index individuels, soit de tout le cluster, et stocker ce snapshot dans un référentiel dans un système de fichier partagé. Des plug-ins qui prennent également en charge les référentiels distants sont disponibles.
Découvrir la fonction sauvegarder et restaurerSnapshots interrogeables
Avec les snapshots interrogeables, pas besoin de passer par une procédure de restauration longue et fastidieuse pour effectuer une recherche sur vos snapshots. Tout se fait en un claquement de doigts. En effet, pour traiter la requête, seuls les éléments nécessaires sont lus sur chaque snapshot. Par ailleurs, avec le niveau "cold", les snapshots interrogeables vous permettent de faire des économies sur vos coûts de stockage. Ils sauvegardent vos partitions répliquées dans des systèmes de stockage d'objets comme Amazon S3, Azure Storage ou Google Cloud Storage, tout en vous concédant un accès complet pour y faire vos recherches.
En savoir plus sur les snapshots interrogeablesCumul de données
Conserver les données historiques pour les analyser est extrêmement utile, mais il s'agit de quelque chose qu'on évite souvent en raison du coût financier associé à l'archivage de quantités astronomiques de données. Par conséquent, les périodes de conservation sont influencées par les réalités financières plutôt que par l'utilité d'avoir à disposition une quantité importante de données historiques. La fonctionnalité de cumul vous donne le moyen de résumer et stocker les données historiques pour pouvoir les analyser, mais pour seulement une fraction du coût de stockage des données brutes.
Découvrir les cumuls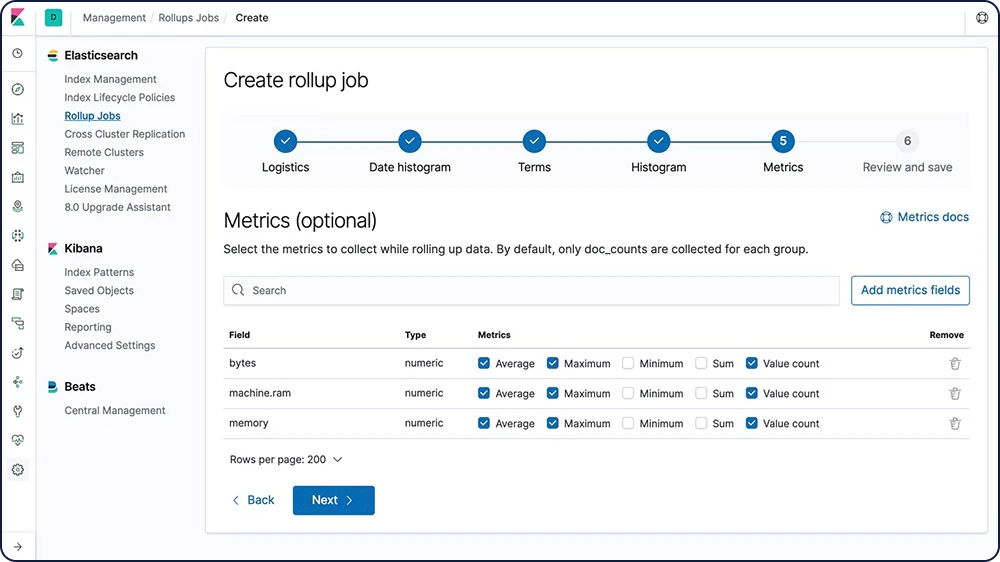
Flux de données
Avec les flux de données, vous ingérez, recherchez et gérez des données de séries temporelles générées en continu. Pratique !
En savoir plus sur les flux de donnéesTransformations
Les transformations sont des structures de données tabulaires bidimensionnelles qui rendent les données indexées plus faciles à assimiler. Elles réalisent des agrégations qui réorganisent vos données dans un nouvel index centré sur les entités. En transformant et en résumant vos données, vous avez la possibilité de les visualiser et de les analyser de manière différente, y compris en tant que source pour d'autres analyses de Machine Learning.
Découvrir les transformationsAPI d'assistant de mise à jour
L'API d'assistant de mise à jour vous permet de consulter le statut de mise à jour de votre cluster Elasticsearch et de réindexer les index créés dans la version majeure précédente. L'assistant vous aide à vous préparer pour la prochaine version majeure d'Elasticsearch.
Découvrir l'API d'assistant de mise à jourGestion des clés d'API
La gestion des clés d'API doit être suffisamment flexible pour permettre aux utilisateurs de gérer leurs propres clés, tout en limitant l'accès à leurs rôles respectifs. Via une interface utilisateur dédiée, les utilisateurs peuvent créer des clés d'API et s'en servir pour fournir des informations de connexion à long terme pour leurs interactions avec Elasticsearch – une méthode couramment employée pour les scripts automatiques ou l'intégration de workflows avec d'autres logiciels.
Découvrir la gestion des clés d'APIGestion et opérations
Sécurité
Les fonctionnalités de sécurité de la Suite Elastic accordent aux utilisateurs les droits d'accès appropriés. Les équipes informatiques, opérationnelles, et celles en charge des applications peuvent s'appuyer sur ces fonctionnalités pour gérer les utilisateurs bien intentionnés et repousser les acteurs malveillants. La direction et les clients sont plus zen : les données stockées dans la Suite Elastic sont totalement sécurisées.
Paramètres sécurisés d'Elasticsearch
Certains paramètres sont sensibles. Il est insuffisant de se fier aux seules autorisations des systèmes de fichiers pour protéger leurs valeurs. Elasticsearch propose donc un magasin de clés pour empêcher les accès non autorisés aux paramètres sensibles du cluster. Et pour encore plus de sécurité, vous avez aussi la possibilité de protéger le magasin de clés par mot de passe.
En savoir plus sur les paramètres sécurisésCommunications chiffrées
Les attaques réseau sur les données de nœud Elasticsearch peuvent être contrées grâce au chiffrement du trafic à l'aide du protocole SSL/TLS, de certificats d'authentification de nœud, et autres.
Découvrir le chiffrement des communicationsPrise en charge du chiffrement au repos
Bien que la Suite Elastic ne mette pas en place le chiffrement au repos de base, nous vous recommandons de configurer un chiffrement au niveau du disque dur sur l'ensemble des machines hôtes. De plus, les cibles de snapshot doivent aussi assurer le chiffrement des données au repos.
Contrôle d'accès basé sur les rôles (RBAC)
Le contrôle d'accès basé sur les rôles (RBAC) vous permet d'accorder des autorisations à certains utilisateurs en attribuant des privilèges à certains rôles et en attribuant des rôles à des utilisateurs ou des groupes.
Découvrir le RBAC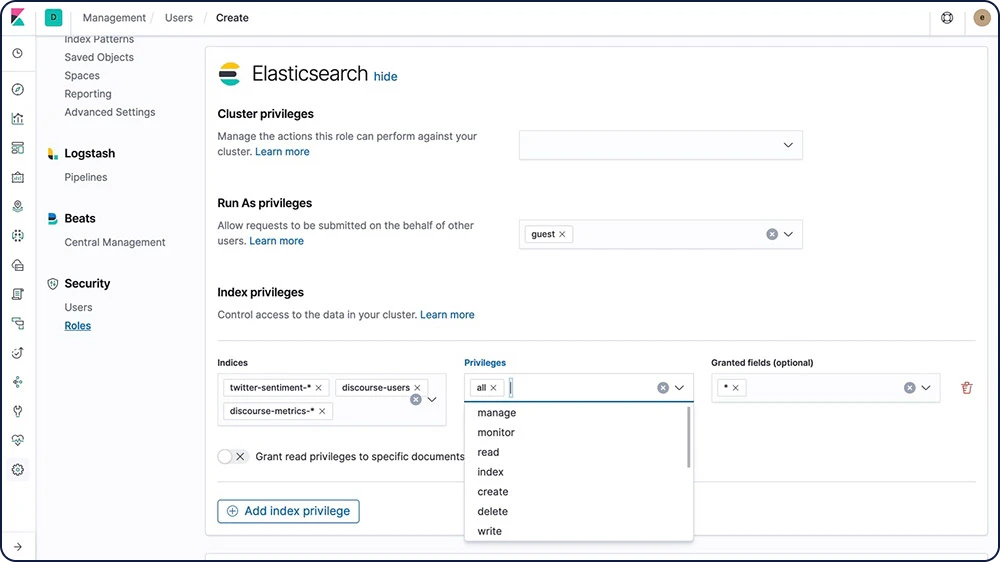
Contrôle d'accès basé sur les attributs (ABAC)
Les fonctionnalités de sécurité de la Suite Elastic fournissent également un mécanisme de contrôle d'accès basés sur les attributs (ABAC) qui vous permet d'utiliser les attributs pour restreindre l'accès aux documents dans les requêtes de recherche et les agrégations. Cela vous permet de mettre une règle d'accès en place dans une définition de rôle pour que les utilisateurs ne puissent lire un document spécifique que s'ils ont les attributs requis.
Découvrir l'ABACSécurité au niveau du champ et du document
La sécurité au niveau du champ restreint les champs auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau du champLa sécurité au niveau du document restreint les documents auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau du documentLogging d'audits
Vous pouvez activer les audits pour suivre les événements de sécurité comme les échecs d'authentification et les connexions refusées. Le logging de ces événements vous permet de monitorer votre cluster à la recherche d'activité suspicieuse et vous fournit des preuves en cas d'attaque.
Découvrir le logging d'auditFiltrage IP
Vous pouvez appliquer un filtrage IP aux clients d'application, de nœud et de transport, en plus d'autres nœuds qui tentent de rejoindre le cluster. Si l'adresse IP d'un nœud se trouve sur la liste noire, les fonctionnalités de sécurité d'Elasticsearch autorisent la connexion à Elasticsearch, mais celle-ci est abandonnée immédiatement et aucune requête n'est traitée.
Adresse IP ou ensemble
xpack.security.transport.filter.allow: "192.168.0.1" xpack.security.transport.filter.deny: "192.168.0.0/24"
Liste blanche
xpack.security.transport.filter.allow: [ "192.168.0.1", "192.168.0.2", "192.168.0.3", "192.168.0.4" ] xpack.security.transport.filter.deny: _all
IPv6
xpack.security.transport.filter.allow: "2001:0db8:1234::/48" xpack.security.transport.filter.deny: "1234:0db8:85a3:0000:0000:8a2e:0370:7334"
Nom d'hôte
xpack.security.transport.filter.allow: localhost xpack.security.transport.filter.deny: '*.google.com'Découvrir le filtrage IP
Domaines de sécurité
Les fonctionnalités de sécurité de la Suite Elastic authentifient les utilisateurs à l'aide de domaines et d'un ou plusieurs services d'authentification par token. On utilise les domaines pour résoudre et authentifier les utilisateurs en fonction de tokens d'authentification. Les fonctionnalités de sécurité fournissent plusieurs domaines intégrés.
Découvrir les domaines de sécuritéAuthentification unique (SSO)
La Suite Elastic prend en charge l'authentification unique (SSO) SAML dans Kibana, en utilisant Elasticsearch comme service back-end. L'authentification SAML permet aux utilisateurs de se connecter à Kibana à l'aide d'un fournisseur d'identité externe, comme Okta ou Auth0.
Découvrir la SSOIntégrations tierces de sécurité
Si vous utilisez un système d'authentification non pris en charge dès le départ avec les fonctionnalités de sécurité de la Suite Elastic, vous pouvez créer un domaine personnalisé pour authentifier les utilisateurs.
Découvrir la sécurité tierceGestion et opérations
Alerting
Avec les fonctionnalités d'alerting de la Suite Elastic, toute la puissance du langage de requête d'Elasticsearch est entre vos mains : vous pouvez ainsi identifier les modifications apportées aux données qui vous intéressent. En d'autres termes, tout ce que vous pouvez rechercher dans Elasticsearch peut aussi faire l'objet d'une alerte.
Alerting hautement disponible et évolutif
Ce n'est pas par hasard que les organisations de toutes tailles font confiance à la Suite Elastic pour gérer leurs besoins d'alerte. En ingérant de manière fiable et sécurisée les données de toutes les sources, dans tous les formats, les analystes peuvent faire des recherches, analyser, et visualiser des données clés en temps réel ; tout cela avec un système d'alerte fiable et personnalisé.
En savoir plus sur AlertingNotifications par e-mail, webhooks, IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, Slack, xMatters
Liez les alertes à des outils d'intégration embarqués pour IBM Resilient, Jira, Microsoft Teams, PagerDuty, ServiceNow, xMatters et Slack ou encore les e-mails. Intégrez-les à tout autre système tiers via une sortie webhook.
Options de notification d'alerte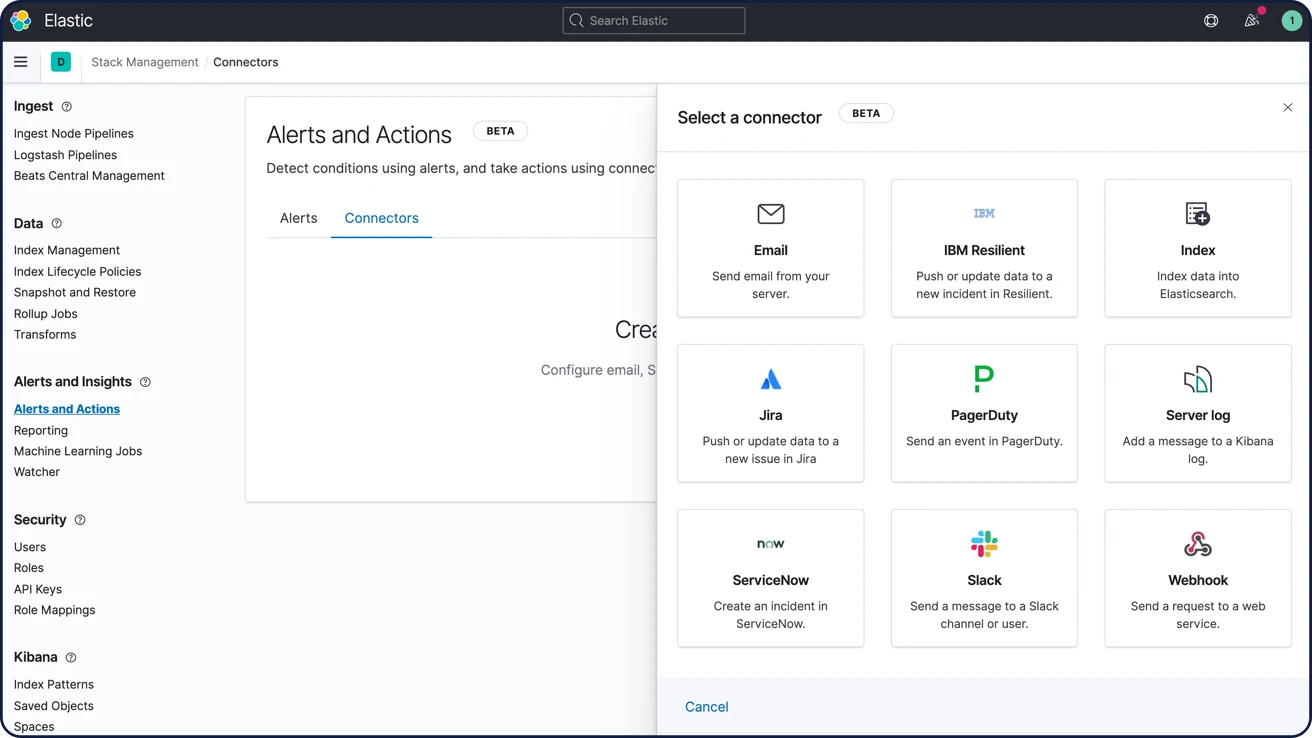
Gestion et opérations
Clients
Elasticsearch vous permet de travailler avec des données en employant la méthode qui vous convient le mieux. Grâce à ses API RESTful, ses clients de langage, ou encore ses DSL performants (sans oublier SQL), elle rime avec flexibilité et élargit le champ des possibles.
Clients de langage
Elasticsearch utilise des API RESTful et JSON standards. Nous créons et maintenons également des clients dans de nombreux langages tels que Java, Python, .NET, SQL et PHP. Et, notre communauté en a ajouté encore plus. À l'image d'Elasticsearch, ils sont simples à utiliser, leur utilisation est naturelle, et ils vous offrent une foule de possibilités.
Explorer les clients linguistiques disponiblesElasticsearch DSL
Elasticsearch fournit un Query DSL complet (langage spécifique à un domaine) qui se base sur le langage JSON pour définir les requêtes. Query DSL met à disposition des options de recherche puissantes pour la recherche full-text, y compris la correspondance de termes et de phrases, la correspondance partielle, les caractères génériques, les requêtes géographiques, et bien plus encore.
Découvrir Elasticsearch DSLGET /fr/_search
{
"query": {
"match" : {
"message" : {
"query" : "this is a test",
"operator" : "and"
}
}
}
}
Elasticsearch SQL
Elasticsearch SQL est une fonctionnalité qui permet d'exécuter les requêtes de type SQL en temps réel sur Elasticsearch. Tous les clients peuvent utiliser SQL pour rechercher et agréger des données nativement dans Elasticsearch, qu'il utilise l'interface REST, une ligne de commande ou JDBC.
Découvrir Elasticsearch SQL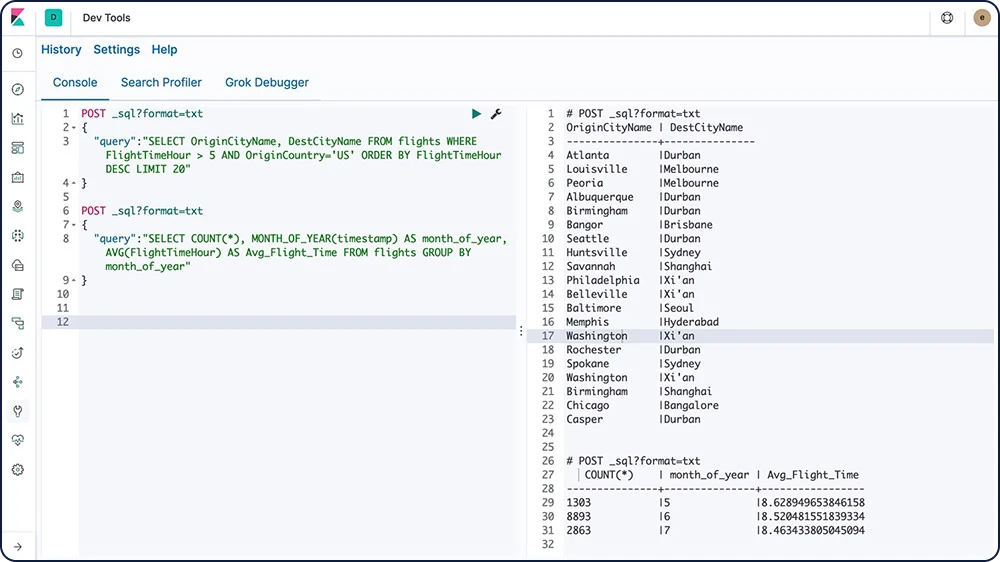
Event Query Language (EQL)
Grâce à sa capacité à interroger des séquences d'événements répondant à des conditions spécifiques, Event Query Language (EQL) convient parfaitement à des cas d'utilisation comme l'analyse de la sécurité.
Découvrir EQLClient JDBC
Le pilote JDBC Elasticsearch SQL est un pilote JDBC riche et ultracomplet pour Elasticsearch. Il s'agit d'un pilote de type 4, qui ne dépend donc pas d'une plateforme, fonctionne en autonomie, se connecte directement à la base de données et est écrit en Java. Il convertit les appels JDBC en Elasticsearch SQL.
Découvrir le client JDBCClient OBDC
Le pilote ODBC Elasticsearch SQL est un pilote ODBC 3.80 riche en fonctionnalités pour Elasticsearch. Il s'agit d'un pilote au niveau cœur qui expose toutes les fonctionnalités accessibles à travers l'API ODBC SQL d'Elasticsearch et qui convertit les appels ODBC en Elasticsearch SQL.
Découvrir le client ODBCConnecteur Tableau pour Elasticsearch
Le connecteur Tableau pour Elasticsearch facilite l'accès aux données dans Elasticsearch pour les utilisateurs de Tableau Desktop et Tableau Server.
Télécharger le connecteur TableauOutils CLI
Elasticsearch fournit plusieurs outils qui permettent de configurer la sécurité et de réaliser d'autres tâches par le biais de lignes de commande.
Explorer les outils CLIGestion et opérations
API REST
Elasticsearch intègre une API REST complète et performante, qui vous permet d'interagir avec votre cluster.
API de document
Réalisez des opérations CRUD (créer, lire, mettre à jour, supprimer) sur des documents individuels, ou sur plusieurs documents à l'aide d'API de document.
Explorer les API de document disponiblesAPI de recherche
Les API de recherche d'Elasticsearch vous permettent de mettre en place quelque chose de plus complet que la recherche full-text seule. Ils vous aident aussi à implémenter les outils de suggestion (termes, phrases, complétion, etc.), à réaliser des évaluations de classement et fournissent même des retours sur la raison pour laquelle un document s'affiche ou non avec la recherche.
Explorer les API de recherche disponiblesAPI d’agrégations
Le framework d'agrégations s'appuie sur une requête de recherche pour fournir des données agrégées. Il est adossé à de simples composantes de base appelées agrégations, que vous pouvez exploiter pour créer des résumés complexes de vos données. On peut voir une agrégation comme une unité de travail qui construit des informations analytiques à partir d'un ensemble de documents.
Découvrir les API d’agrégations disponiblesAgrégations d'indicateurs
Agrégations d’intervalles
Agrégations de pipelines
Agrégations de matrices
Agrégations de cardinalité cumulative
Agrégations de grilles hexagonales géométriques
API d'ingestion
Utilisez les API d'ingestion pour effectuer des opérations CRUD dans vos pipelines de données, ou utilisez l'API de simulation d'API pour exécuter un pipeline spécifique sur un ensemble de documents.
Explorer les API d'ingestion disponiblesAPI de gestion
Gérez votre cluster Elasticsearch par programmation avec plusieurs API de gestion. Il s'agit d'API qui permettent de gérer des index, des mappings, des clusters, des nœuds, des licences, la sécurité, et bien plus encore. Si vous souhaitez obtenir vos résultats dans un format lisible par l'utilisateur, vous pouvez simplement utiliser les API cat.
Gestion et opérations
Intégrations
Elasticsearch étant une application open source compatible avec tous les langages, vous pouvez facilement étendre ses fonctionnalités avec des plug-ins et des intégrations.
Elasticsearch-Hadoop
Elasticsearch pour Apache Hadoop (Elasticsearch-Hadoop ou ES-Hadoop) est une petite bibliothèque gratuite, ouverte, indépendante et auto-contenue qui permet aux tâches Hadoop d'interagir avec Elasticsearch. Utilisez-la pour développer des applications de recherche intégrées et dynamiques pour traiter vos données Hadoop ou lancer des analyses complexes à faible latence, s'appuyant sur des agrégations, des requêtes full-text ou des requêtes géospatiales.
Découvrir ES-HadoopApache Hive
Elasticsearch pour Apache Hadoop propose un support technique de premier ordre pour Apache Hive, un système d'entrepôt de données pour Hadoop qui facilite la synthèse des données, les recherches ad hoc et l'analyse de grands ensembles de données stockés dans les systèmes de fichiers compatibles avec Hadoop.
Découvrir l'intégration d'Apache HiveApache Spark
Elasticsearch pour Apache Hadoop propose un support technique de premier ordre pour Apache Spark, un système informatique de cluster rapide et universel. Il fournit des API de haut niveau en Java, Scala et Python, ainsi qu'un moteur optimisé qui prend en charge les graphes généraux d'exécution.
Découvrir l'intégration d'Apache SparkInformatique décisionnelle (BI)
Grâce à ses interfaces JDBC et ODBC, une large gamme d'applications d'informatique décisionnelle tierces peuvent utiliser les capacités d'Elasticsearch SQL.
Découvrir les intégrations BI et SQL disponiblesPlug-ins et intégrations
Elasticsearch étant une application gratuite et ouverte compatible avec tous les langages, vous pouvez facilement étendre ses fonctionnalités avec des plug-ins et des intégrations. Grâce aux plug-ins, vous avez une façon personnalisée d'améliorer les fonctionnalités principales d'Elasticsearch. Les intégrations sont des outils externes ou des modules qui facilitent le travail avec Elasticsearch.
Explorer les plug-ins Elasticsearch disponiblesPlug-ins d'extension d'API
Plug-ins Alerting
Plug-ins d'analyse
Plug-ins de découverte
Plug-ins d'ingestion
Plug-ins de gestion
Plug-ins Mapper
Plug-ins de sécurité
Plug-ins de référentiel d'instantané/de restauration
Plug-ins de stockage
Gestion et opérations
Déploiement
Cloud public, cloud privé, ou quelque part entre les deux. Quel que soit le cas de figure, nous vous facilitons l'exécution et la gestion d'Elasticsearch.
Téléchargement et installation
Pour se lancer, c'est toujours aussi simple : il vous suffit de télécharger et d'installer Elasticsearch et Kibana sous forme d'archive ou via un gestionnaire de package. Vous indexerez, analyserez et visualiserez vos données en un clin d'œil. Et avec la distribution par défaut, vous pouvez aussi essayer des fonctionnalités Platinum comme Machine Learning, Security, ou encore l'analyse de graphes – tout cela, gratuitement, pour une période de 30 jours.
Télécharger la Suite ElasticElastic Cloud
Elastic Cloud, notre famille d'offres SaaS en pleine expansion, facilite le déploiement, l'utilisation et le scaling des produits et des solutions Elastic dans le cloud. Sautez sur le tremplin d'Elastic Cloud pour mettre Elastic à profit pour vous avec fluidité, grâce à l'expérience Elasticsearch facile à utiliser, hébergée et gérée et aux solutions de recherche qui sortent du lot. Essayez un produit Elastic Cloud gratuitement pendant 14 jours, sans carte de crédit.
Lancez-vous dans Elastic CloudLancez-vous avec la version d'essai gratuite d'Elasticsearch Service
Elastic Cloud Enterprise
Avec Elastic Cloud Enterprise (ECE), provisionnez, gérez et monitorez Elasticsearch et Kibana depuis une seule et même console. Et ce, quelles que soient votre infrastructure ou la taille de votre déploiement. Vous vous demandez où exécuter Elasticsearch et Kibana ? Bonne nouvelle : vous avez l'embarras du choix. Matériel physique, environnement virtuel, cloud privé, zone privée au sein d'un cloud public, ou encore cloud public (Google, Azure ou AWS, pour ne citer que ceux-là). À vous de choisir votre infrastructure.
Essayez ECE gratuitement pendant 30 joursElastic Cloud sur Kubernetes
Basé sur le modèle Kubernetes Operator, Elastic Cloud sur Kubernetes (ECK) vient étendre les fonctionnalités d'orchestration de base de Kubernetes, qui deviennent compatibles avec la configuration et la gestion d'Elasticsearch et Kibana sur Kubernetes. Avec Elastic Cloud sur Kubernetes, l'exécution d'Elasticsearch sur Kubernetes et les processus de déploiement, de mise à niveau, d'instantanés, de montée en charge, de haute disponibilité, de sécurité… Tout cela gagne en simplicité.
Déployez avec Elastic Cloud sur KubernetesHelm Charts
Avec l'offre officielle Helm Charts Elasticsearch et Kibana, offrez-vous un déploiement en quelques minutes.
Découvrir l'offre officielle Helm Charts d'ElasticConteneurisation de Docker
Exécutez Elasticsearch et Kibana sur Docker avec les conteneurs officiels du hub Docker.
Exécuter la Suite Elastic sur DockerIngérer et enrichir
Ingérer et enrichir
Ingestion
Ingérez vos données dans la Suite Elastic comme bon vous semble. API RESTful, clients de langage, nœuds d'ingestion, agents de transfert légers ou Logstash... À vous de choisir. La liste de langages n'est pas limitée et comme nous avons fait le choix de l'open source, vous pouvez ingérer n'importe quel type de données. Si vous n'avez qu'un seul type de données à transférer, nous vous fournissons les bibliothèques et vous indiquons les étapes à suivre pour créer vos propres méthodes d'ingestion. Si vous le souhaitez, vous pouvez même les partager avec la communauté pour que les utilisateurs qui exploitent le même type de données n'aient pas besoin de réinventer la roue.
Clients et API
Elasticsearch utilise des API RESTful et JSON standards. Nous créons et maintenons également des clients dans de nombreux langages tels que Java, Python, .NET, SQL et PHP. Et, notre communauté en a ajouté encore plus. À l'image d'Elasticsearch, ils sont simples à utiliser, leur utilisation est naturelle, et ils vous offrent une foule de possibilités.
Nœud d'ingestion
Elasticsearch propose plusieurs types de nœuds, et l'un d'eux sert spécifiquement à ingérer des données. Les nœuds d'ingestion peuvent exécuter des pipelines de prétraitement, qui se composent d'un processeur d'ingestion ou plus. En fonction du type d'opération réalisé par les processeurs d'ingestion et des ressources nécessaires, cela peut être utile de dédier des nœuds d'ingestion à la réalisation de cette tâche.
Beats
Les agents Beats sont des agents de transfert de données open source que vous pouvez installer sur vos serveurs pour envoyer des données opérationnelles à Elasticsearch ou Logstash. Elastic vous fournit des agents Beats qui permettent de capturer plusieurs types de logs communs, d'indicateurs et d'autres types de données.
Auditbeat pour les logs d'audit Linux
Filebeat pour les fichiers log
Functionbeat pour les données cloud
Heartbeat pour les données de disponibilité
Journalbeat pour les journaux systemd
Metricbeat pour les indicateurs d'infrastructure
Packetbeat pour le trafic réseau
Winlogbeat pour l'analyse des logs d'événements Windows
Logstash
Logstash est un moteur de collecte de données open source doté de capacités pipeline en temps réel. Logstash peut rassembler de manière dynamique les données provenant de plusieurs sources et les normaliser vers les destinations de votre choix. Nettoyez et démocratisez toutes vos données pour plusieurs cas d'utilisation d'analytique et de visualisation en aval.
Agents de transfert communautaires
Si vous avez besoin de résoudre un cas d'utilisation spécifique, nous vous encourageons à créer un agent Beat communautaire. Nous avons créé une infrastructure pour simplifier le processus. La bibliothèque libbeat, écrite entièrement en Go, propose l'API que tous les agents Beats utilisent pour transférer des données vers Elasticsearch, configurer les options d'entrée, implémenter des loggings, et plus.
Avec plus de 100 agents Beats partagés par la communauté, il existe des agents pour les logs et les indicateurs de Cloudwatch, les activités de GitHub, les sujets Kafka, MySQL, MongoDB Prometheus, Apache, Twitter, et bien plus encore.
Consulter les agents Beats disponibles développés par la communautéIngérer et enrichir
Enrichissement des données
Elasticsearch convertit les données brutes en précieuses informations grâce à des analyseurs, un générateur de tokens, des filtres et des options d'enrichissement.
Elastic Common Schema
Avec Elastic Common Schema (ECS), analysez de manière homogène les données provenant de différentes sources. Vous pouvez désormais appliquer des règles de détection, des tâches de Machine Learning, des tableaux de bord et d'autres contenus de sécurité à un plus grand nombre de cas d'utilisation, améliorer la précision de vos recherches et utiliser des noms de champs bien plus simples à mémoriser.
Processeurs
Utilisez un nœud d'ingestion pour pré-traiter les documents avant de réellement les indexer. Le nœud d'ingestion intercepte les groupes et indexe les requêtes, applique les transformations, puis renvoie les documents à l'index ou aux API Bulk. Le nœud d'ingestion comprend plus de 25 processeurs, y compris "append" (ajouter), "convert" (convertir), "date" (dater), "dissect" (disséquer), "drop" (abandonner), "fail" (échouer), "grok", "join" (joindre), "remove" (supprimer), "set" (définir), "split" (découper), "sort" (trier), "trim" (simplifier), et bien plus.
Analyseurs
L'analyse consiste en un processus de conversion du texte, comme le corps d'un e-mail, en tokens ou en termes qui sont ensuite ajoutés à un index inversé pour la recherche. Cette analyse est réalisée par un analyseur qui peut être intégré ou personnalisé et défini par index à l'aide d'une combinaison de générateurs de tokens et de filtres.
Exemple : analyseur standard (par défaut)
Entrée : "Les deux renards bruns RAPIDES sautent au-dessus de l'os du chien fainéant."
Sortie : les deux renards bruns rapides sautent au-dessus de l'os du chien fainéant
Générateur de tokens
Un générateur de tokens reçoit un flux de caractères, le divise en tokens (généralement en mots), et sort un flux de tokens. Le générateur de tokens se charge également de l'enregistrement de l'ordre ou de la position de chaque terme (utilisé pour les recherches de proximité de mots et de phrases) ainsi que des décalages de caractère de début et de fin du mot d'origine que le terme représente (utilisés pour mettre en évidence des extraits de recherche). Elasticsearch est doté de plusieurs générateurs de tokens intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Exemple : Générateur de tokens de caractères blancs
Entrée : "Les deux renards bruns RAPIDES sautent au-dessus de l'os du chien fainéant."
Sortie : The 2 QUICK Brown-Foxes jumped over the lazy dog's bone.
Filtres
Les filtres de tokens prennent en charge un flux de tokens en provenance d'un générateur de tokens et peuvent modifier les tokens (par exemple les mettre en minuscules), les supprimer (par exemple éliminer les mots non significatifs), ou en ajouter (par exemple des synonymes). Elasticsearch est doté de plusieurs filtres de tokens intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Vous pouvez utiliser les filtres de caractères pour prétraiter le flux de caractères avant qu'il passe dans le générateur de tokens. Un filtre de caractères reçoit le texte d'origine sous forme de flux de caractère et peut transformer le flux en ajoutant, en éliminant ou en modifiant des caractères. Elasticsearch est doté de plusieurs filtres de caractères intégrés que vous pouvez utiliser pour construire des analyseurs personnalisés.
Découvrir les filtres de caractèresAnalyseurs linguistiques
Effectuez des recherches dans votre langue. Elasticsearch propose plus de 30 analyseurs linguistiques différents, y compris plusieurs langues utilisant des caractères non latins comme le russe, l'arabe et le chinois.
Mapping dynamique
Pas besoin de définir les champs et les types de mapping avant de les utiliser. Grâce au mapping dynamique, les nouveaux noms de champ sont ajoutés automatiquement lorsque vous indexez un document.
Processeur d'enrichissement Match
Le processeur d'ingestion Match permet aux utilisateurs d'interroger leurs données au moment de l'ingestion et leur indique l'index depuis lequel ils peuvent extraire des données enrichies. Très utile pour les utilisateurs Beats qui doivent ajouter quelques éléments à leurs données : plutôt que de passer de Beats à Logstash, ils peuvent directement consulter le pipeline d'ingestion. Grâce au processeur, ils sont aussi en mesure de normaliser les données pour améliorer leurs analyses et traiter les requêtes courantes.
Processeur d'enrichissement Geo-match
Aussi utile que pratique, le processeur d'enrichissement Geo-match permet aux utilisateurs de booster leurs fonctionnalités de recherche et d'agrégation grâce à leurs données géographiques. Le tout, sans devoir définir de requêtes ou d'agrégations en termes de coordonnées géographiques. Comme avec le processeur d'enrichissement Match, les utilisateurs peuvent interroger leurs données au moment de l'ingestion et rechercher l'index optimal depuis lequel ils peuvent extraire des données enrichies.
Stockage de données
Stockage de données
Flexibilité
La Suite Elastic est une solution ultraperformante, capable de répondre à quasiment tous les cas d'utilisation. Bien qu'elle soit surtout connue pour ses capacités de recherche avancée, sa conception flexible en fait un outil parfaitement adapté à différents besoins, comme le stockage de documents, l'analyse de séries temporelles et d'indicateurs, ou encore l'analyse géospatiale.
Types de données
Elasticsearch est compatible avec différents types de données pour les champs d'un document, et chacun de ces types de données présente plusieurs sous-types. Cela vous permet de stocker, d'analyser et d'utiliser vos données avec une efficacité et une efficience maximales, peu importe leur type. Voici quelques exemples de types de données pour lesquels Elasticsearch est optimisé :
Texte
Formes
Nombres
Vecteurs
Histogramme
Séries date/heure
Champ "flattened" (lissé)
Points géographiques/formes géométriques
Données non structurées (JSON)
Données structurées
Recherche full-text (index inversé)
Elasticsearch utilise une structure appelée index inversé et conçue pour faire des recherches full-text très rapides. Un index inversé se compose d'une liste des mots uniques qui apparaissent dans un document. Pour chaque mot, cet index comprend une liste de tous les documents dans lesquels il apparaît. Pour créer un index inversé, il faut tout d'abord diviser le champ de contenu de chaque document en mots séparés (qu'on appelle termes ou tokens), puis créer une liste triée de tous les termes uniques, et enfin lister dans quels documents chaque terme apparaît.
Stockage de documents (données non structurées)
Avec Elasticsearch, les données ne doivent pas obligatoirement être structurées pour être ingérées ou analysées (bien que la structuration améliore la vitesse). Cette conception facilite le lancement et fait aussi d'Elasticsearch un espace de stockage de documents efficace. Même si Elasticsearch n'est pas une base de données NoSQL, il propose des fonctionnalités similaires.
Séries temporelles/analyse (structure en colonnes)
Un index inversé permet aux recherches de rapidement trouver des termes de recherche. Cependant, le tri et les agrégations requièrent un autre modèle d'accès aux données. Au lieu de rechercher le terme et de trouver des documents, elles doivent pouvoir rechercher le document et trouver les termes qu'il contient dans un champ. Les valeurs des documents sont la structure de données sur disque dans Elasticsearch. Elles sont créées au moment de l'indexation du document, ce qui signifie que ce modèle d'accès aux données est possible, et permet de faire des recherches en colonnes. Grâce à cela, Elasticsearch excelle dans l'analyse des indicateurs et des séries temporelles.
Données géospatiales (arborescence BKD)
Elasticsearch utilise l'arborescence BKD dans Lucene pour stocker les données géospatiales. Cela permet d'analyser de manière efficace les points géographiques (latitude et longitude) et les formes géométriques (rectangles et polygones).
Stockage de données
Sécurité
La sécurité ne s'arrête pas au niveau du cluster. Dans Elasticsearch, vos données sont sécurisées à tous les niveaux, jusqu'au niveau du champ.
Sécurité des API au niveau des champs et des documents
La sécurité au niveau des champs restreint les champs auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
La sécurité au niveau des documents restreint les documents auxquels les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Découvrir la sécurité au niveau des documentsPrise en charge du chiffrement des données au repos
Bien que la Suite Elastic ne mette pas en place le chiffrement au repos de base, nous vous recommandons de configurer un chiffrement au niveau du disque dur sur l'ensemble des machines hôtes. De plus, les cibles instantanées doivent aussi assurer le chiffrement des données au repos.
Stockage de données
Direction
Elasticsearch vous permet de gérer entièrement vos clusters et leurs nœuds, vos index et leurs partitions, sans oublier l'essentiel : l'intégralité des données qu'ils contiennent.
Index groupés
Un cluster est un ensemble constitué d'un ou de plusieurs nœuds (serveurs). Il stocke toutes vos données et vous permet de centraliser l'indexation et la recherche des données sur l'ensemble des nœuds. Son architecture facilite le scaling horizontal. Elasticsearch intègre une API REST complète et performante, ainsi que des interfaces utilisateur, qui vous permettent d'interagir avec vos clusters.
Snapshot et restauration des données
Un instantané est une sauvegarde d'un cluster Elasticsearch en cours d'exécution. Vous pouvez créer un snapshot soit d'index individuels, soit de tout le cluster, et stocker ce snapshot dans un référentiel dans un système de fichier partagé. Des plug-ins qui prennent également en charge les référentiels distants sont disponibles.
Index de cumul
Conserver les données historiques pour les analyser est extrêmement utile, mais il s'agit de quelque chose qu'on évite souvent en raison du coût financier associé à l'archivage de quantités astronomiques de données. Par conséquent, les périodes de conservation sont influencées par les réalités financières plutôt que par l'utilité d'avoir à disposition une quantité importante de données historiques. La fonctionnalité de cumul vous donne le moyen de résumer et stocker les données historiques pour pouvoir les analyser, mais pour seulement une fraction du coût de stockage des données brutes.
Rechercher et analyser
Rechercher et analyser
Recherche full-text
Elasticsearch est connu pour ses puissantes capacités de recherche full-text. Sa rapidité ? Il la doit à l'index inversé intégré au cœur du moteur de recherche. Sa puissance ? Il la tire de son score de pertinence ajustable, de son Query DSL avancé et d'une pléthore de fonctions qui vous permettent de booster la recherche.
Index inversé
Elasticsearch utilise une structure appelée index inversé et conçue pour faire des recherches full-text très rapides. Un index inversé se compose d'une liste des mots uniques qui apparaissent dans un document. Pour chaque mot, cet index comprend une liste de tous les documents dans lesquels il apparaît. Pour créer un index inversé, il faut tout d'abord diviser le champ de contenu de chaque document en mots séparés (qu'on appelle termes ou tokens), puis créer une liste triée de tous les termes uniques, et enfin lister dans quels documents chaque terme apparaît.
Champs d'exécution
Les champs d'exécution sont des champs évalués au moment de la requête (schéma de lecture). Ils peuvent être ajoutés ou modifiés à tout moment, y compris après l'indexation des documents, et peuvent être définis dans une requête. Les champs d'exécution sont affectés par les requêtes dans la même interface que celle des champs indexés. Un champ peut donc être un champ d'exécution dans certains indices d'un flux de données, et un champ indexé dans d'autres indices de ce flux de données, sans que les requêtes ne puissent faire la différence. Bien que les performances des requêtes soient déjà optimales pour les champs indexés, les champs d'exécution ne sont pas en reste en permettant la modification flexible de la structure de données une fois les documents indexés.
Champ d'exécution de recherche
Les champs d'exécution de recherche vous offrent la possibilité d'ajouter des informations depuis un index de recherche dans les résultats et depuis un index principal en définissant une clé sur les deux index qui lient les documents. Comme les champs d'exécution, cette fonctionnalité est utilisée au moment de la recherche pour assurer un enrichissement flexible des données.
Recherche inter-clusters
La fonctionnalité de recherche inter-clusters (CCS) permet à n'importe quel nœud de se comporter comme un client fédéré sur plusieurs clusters. Un nœud de recherche inter-cluster ne contacte pas le cluster distant. Il se connecte plutôt à un cluster distant de manière légère pour exécuter des recherches fédérées.
Score de pertinence
Une fonction de similarité (score de pertinence/modèle de classement) définit comment les documents correspondants sont notés. Par défaut, Elasticsearch utilise la similarité BM25, une similarité TF/IDF avancée qui est dotée d'une normalisation tf intégrée qui convient parfaitement pour les champs courts (comme les noms). Plusieurs autres options de similarité sont disponibles.
Recherche vectorielle (ANN)
Grâce à la nouvelle prise en charge de la recherche approximative du plus proche voisin ou ANN de Lucene 9 fondée sur l'algorithme HNSW, le nouveau point de terminaison de l'API _knn_search permet de mener des recherches plus performantes et scalables en fonction de la similarité vectorielle. Pour ce faire, un équilibre est trouvé entre rappel et performance : grâce à des compromis mineurs en matière de rappel, les très grands ensembles de données deviennent bien plus performants (par rapport à la méthode existante de similarité vectorielle par force brute).
Query DSL
La recherche full-text requiert un langage de requête robuste. Elasticsearch fournit un Query DSL complet (langage spécifique à un domaine) qui se base sur le langage JSON pour définir les requêtes. Créez des requêtes simples pour faire correspondre des termes et des phrases, ou développez des requêtes composées qui peuvent combiner plusieurs requêtes. De plus, vous pouvez appliquer des filtres au moment de la requête pour éliminer des documents avant de leur attribuer des notes de pertinence.
Recherche asynchrone
L'API de recherche asynchrone vous permet d'exécuter en arrière-plan les requêtes qui prennent du temps. Vous pouvez en surveiller la progression et récupérer des résultats partiels à mesure qu'ils sont disponibles.
Surligneurs
Les surligneurs vous permettent de mettre en évidence des extraits d'un ou plusieurs champs dans vos résultats de recherche pour pouvoir montrer aux utilisateurs où se trouvent les correspondances de recherche. Lorsque vous demandez l'affichage des surlignages, la réponse contient un élément de surlignage supplémentaire pour chaque résultat de recherche comprenant les champs surlignés et les fragments surlignés.
Saisie semi-automatique (complétion automatique)
L'outil de suggestion de saisie semi-automatique vous fournit une fonctionnalité de complétion automatique/de recherche en cours de frappe. Il s'agit d'une fonctionnalité de navigation qui guide les utilisateurs vers des résultats pertinents en cours de frappe, ce qui améliore la précision de recherche.
Outil de suggestion (did-you-mean)
L'outil de suggestion de phrase ajoute une fonctionnalité did-you-mean à votre recherche en bâtissant une logique supplémentaire par-dessus l'outil de suggestion de terme pour sélectionner des phrases corrigées entières au lieu de tokens individuels pondérés sur la base de modèles de langage ngram. En pratique, cet outil de suggestion est capable de prendre de meilleures décisions quant aux tokens à sélectionner en fonction des co-occurrences et des fréquences.
Corrections (correcteur orthographique)
L'outil de suggestion de termes est à la racine du correcteur orthographique. Il suggère des termes en fonction de la distance d'édition. Le texte de suggestion fourni est analysé avant de suggérer des termes. Les termes suggérés sont fournis par tokens textuels de suggestion analysés.
Filtres
Les filtres retournent le modèle de recherche standard, où on utilise une recherche pour trouver un document stocké dans un index, et peuvent être utilisés pour faire correspondre des documents à des recherches stockées dans un index. La recherche de filtre en elle-même contient le document qui est utilisé comme recherche pour être associée aux recherches stockées.
Système de profilage/d'optimisation des requêtes
L'API de profilage fournit des informations de temporisation détaillées à propos de l'exécution de composants individuels dans une requête de recherche. Il permet de mieux comprendre comment les requêtes de recherche s'exécutent à bas niveau pour que vous puissiez comprendre pourquoi certaines requêtes sont lentes et prendre des mesures pour les améliorer.
Résultats de recherche en fonction des autorisations
La sécurité au niveau des champs et la sécurité au niveau des documents restreint les résultats de recherche à ce à quoi les utilisateurs peuvent accéder en lecture. En particulier, elle restreint les champs et les documents auxquels on peut accéder depuis des API de lecture qui se basent sur les documents.
Mise à jour dynamique des synonymes
L'API "Reload search analyzers" vous permet de recharger la définition du synonyme. Le contenu du fichier de synonymes configuré est alors rechargé, et la définition des synonymes qu'utilise le filtre est mise à jour. Vous pouvez exécuter l'API _reload_search_analyzers sur un ou plusieurs index. Celle-ci déclenche le rechargement des synonymes depuis le fichier configuré.
Épinglage des résultats
Cette fonctionnalité vous permet de mettre en avant certains documents, afin qu'ils s'affichent en premier, avant d'autres résultats de recherche. Elle sert généralement à diriger l'utilisateur vers des documents pertinents, mis en avant par rapport aux résultats de recherche "naturelle". Pour identifier les documents ainsi mis en avant (ou "épinglés"), on utilise les identifiants de document stockés dans le champ _id.
Rechercher et analyser
Analytique
La recherche des données n'est que le début. Les puissantes fonctionnalités d'analyse d'Elasticsearch vous permettent de découvrir ce que veulent vraiment dire les données que vous avez recherchées et collectées. Que l'on parle de l'agrégation de résultats, de la découverte de relations entre des documents ou de la création d'alertes selon des valeurs de seuil, tout s'appuie sur une fonction de recherche performante.
Agrégations
L'architecture d'agrégations vous aide à obtenir des données agrégées à l'aide d'une requête de recherche. Il est adossé à de simples composantes de base appelées agrégations, que vous pouvez exploiter pour créer des résumés complexes de vos données. On peut voir une agrégation comme une unité de travail qui construit des informations analytiques à partir d'un ensemble de documents.
Agrégations d'indicateurs
Agrégations d'intervalles
Agrégations de pipelines
Agrégations de matrices
Agrégations de grilles hexagonales géométriques
Agrégations d'échantillonnage aléatoire
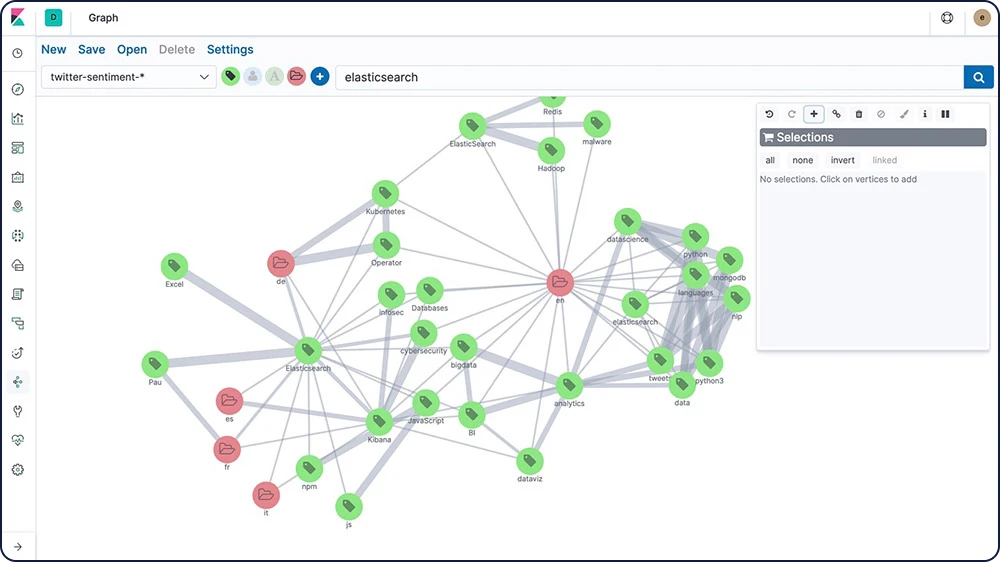
Exploration de graphes
L'API d'exploration Graph vous permet d'extraire et de résumer des informations à propos des documents et des termes qui se trouvent dans votre index Elasticsearch. La meilleure façon de comprendre le comportement de cette API est d'utiliser Graph dans Kibana pour explorer les relations.
Rechercher et analyser
Machine Learning
Les fonctionnalités de Machine Learning d'Elastic modélisent automatiquement le comportement de vos données Elasticsearch (tendances, périodicité, etc.). Le tout, en temps réel. Leur mission : identifier les problèmes plus rapidement, rationaliser l'analyse des causes et réduire le nombre de faux positifs.
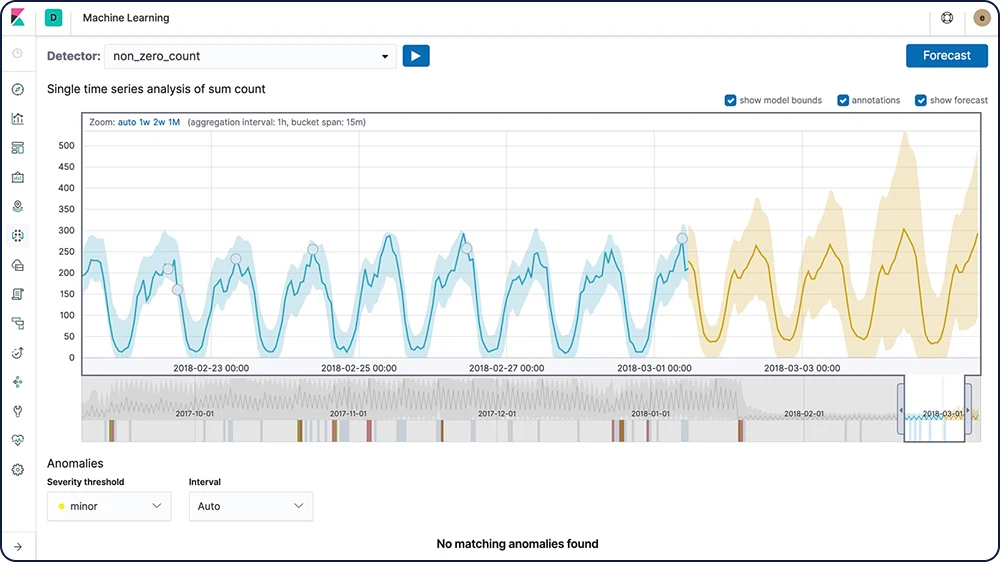
Prévisions relatives aux séries temporelles
Une fois que la fonctionnalité de Machine Learning d'Elastic a créé des points de comparaison de comportements normaux pour vos données, vous pouvez utiliser ces informations pour extrapoler les comportements futurs. Créez ensuite une prévision afin d'estimer une valeur temporelle à une date future spécifique ou pour estimer la probabilité d'occurrence d'une valeur temporelle dans le futur
Détection des anomalies dans les séries temporelles
Les fonctionnalités de Machine Learning d'Elastic automatisent l'analyse des données temporelles en créant des points de comparaison précis de comportements normaux dans les données et en identifiant les modèles anormaux dans celles-ci. Les anomalies sont détectées, notées et liées à des influenceurs importants du point de vue statistique dans les données à l'aide d'algorithmes de Machine Learning propriétaires.
Les anomalies liées aux écarts temporels de valeurs, de nombres ou de fréquences
Rareté statistique
Les comportements inhabituels pour le membre d'une population
Alerting associé aux anomalies
Certaines modifications sont difficiles à définir au moyen de règles et de seuils. Dans ce cas, vous pouvez associer l'alerting à des fonctionnalités de Machine Learning non supervisé qui vous permettront de détecter les comportements inhabituels. Ensuite, vous pouvez aussi recevoir des notifications en fonction des scores d'anomalies et lorsque des problèmes surviennent.
Inférence
L'inférence vous permet d'utiliser des processus de Machine Learning supervisé, comme la régression ou la classification, pour réaliser notamment des analyses par lot. Vous pouvez aussi utiliser ces processus de manière continue. Avec l'inférence, il est possible d'appliquer des modèles entraînés de Machine Learning sur les données entrantes.
Détection de la langue
La détection de la langue est un modèle entraîné dont vous pouvez vous servir pour déterminer la langue d'un texte. Vous pouvez référencer le modèle de détection de la langue dans un processeur d'inférence.