Qu'est-ce que la récupération d'informations ?
Définition de la récupération d'informations
La récupération d'informations (RI) est un processus qui permet de récupérer efficacement des informations pertinentes dans de vastes volumes de données non structurées ou semi-structurées. Les systèmes de RI facilitent la recherche, la localisation et la présentation des informations correspondant à la requête ou au besoin d'un utilisateur.
C'est la méthode privilégiée pour accéder aux informations. Chaque jour, des milliards de personnes utilisent des moteurs de recherche dans cette optique. Les systèmes de RI déploient des modèles, des algorithmes et des techniques innovantes (comme la recherche vectorielle) pour permettre aux utilisateurs de faire des recherches sur des sources diverses et variées, parmi lesquelles des documents, des éléments de document, des métadonnées, ou encore des bases de données de textes, d'images, de vidéos et de sons.
Bref historique de la récupération d'informations
Les origines de la récupération d'informations remontent à des temps anciens. À l'époque, on commence à mettre en place des bibliothèques et des archives dans le but d'organiser et de stocker les informations. Plusieurs méthodes sont employées, notamment l'indexation et le classement par ordre alphabétique des travaux académiques. Dans les années 1800, on utilise des cartes perforées pour traiter les informations. En 1931, Emanuel Goldberg dépose un brevet pour le premier appareil électromagnétique de récupération de documents, connu sous le nom de "Machine statistique". Cet appareil est conçu pour faire des recherches sur des données encodées sur des microfilms.
La récupération d'informations commence à prendre la forme officielle de ce qui deviendrait une discipline scientifique vers la moitié du XXe siècle, en parallèle du développement des ordinateurs modernes. Gerard Salton et Hans Peter Luhn sont les premiers à travailler sur des modèles avant-gardistes de récupération automatisée des documents. C'est dans les années 1960 que Gerard Salton et ses collègues de l'Université Cornell créent le système de recherche d’informations SMART, une étape majeure dans le domaine qui a posé les bases des techniques de RI modernes et des concepts clés associés, comme la matrice termes-documents, le modèle vectoriel, le retour de pertinence et la classification Rocchio.
Dans les années 1970, avec l'émergence de techniques de récupération plus avancées, de modèles probabilistes et de frameworks de traitement vectoriel entièrement articulés, le domaine connaît des avancées significatives. Puis les moteurs de recherche font leur apparition à la fin des années 1990. Les systèmes et modèles de RI, qui étaient jusque-là l'apanage des universités, institutions et bibliothèques, se démocratisent.
Types de modèles de récupération d'informations
Chaque type de modèle de récupération d'informations est conçu pour résoudre des problématiques spécifiques et pour établir des processus afin de récupérer des informations pertinentes. Il y a des modèles classiques, qui constituent le socle du domaine, des modèles non classiques, qui tentent d'abroger les limites des approches traditionnelles, et des modèles de RI alternatifs, qui vont encore plus loin, souvent en intégrant des technologies avancées comme le Machine Learning et les modèles de langage. De façon générale, les modèles de récupération d'informations les plus courants sont les suivants :
Modèle booléen
C'est l'un des modèles de récupération d'informations les plus simples et les plus anciens. Le modèle booléen se base sur la logique booléenne, qui utilise les opérateurs AND, OR et NOT pour combiner les termes de requête. Les documents sont représentés comme des ensembles de termes, et une requête est traitée pour identifier les documents qui correspondent aux conditions définies. Même s'il s'agit d'une méthode efficace pour renvoyer des correspondances précises, le modèle booléen ne peut pas classer les documents selon leur pertinence, ni fournir de correspondances partielles.
Modèle vectoriel
Dans ce modèle, les documents et les requêtes sont représentés sous forme de vecteurs dans un espace à plusieurs dimensions. Chaque dimension correspond à un terme unique. La valeur associée à une dimension traduit l'importance et la fréquence du terme dans le document ou la requête. La similarité cosinus entre le vecteur de la requête et les vecteurs d'un document est calculée pour déterminer la pertinence desdits documents par rapport à la requête. Le modèle vectoriel a été développé en partie pour pallier les inconvénients que présente le modèle booléen. Il peut fournir des résultats classés selon des scores de pertinence. Il est couramment utilisé dans la récupération de textes.
Modèle probabiliste
Ce modèle estime la probabilité qu'un document soit pertinent pour une requête donnée. Il prend en compte plusieurs facteurs, comme la fréquence d'un terme et la longueur du document, pour calculer les probabilités de pertinence. C'est un modèle particulièrement utile lorsqu'il faut brasser de larges volumes de données. Étant donné qu'il fonctionne avec des statistiques pondérées, c'est un modèle idéal pour avoir un classement des résultats.
Indexation sémantique latente (LSI)
La LSI s'appuie sur la décomposition en valeurs singulières pour établir les relations sémantiques entre les termes et les documents. À l'instar de la recherche sémantique, l'indexation sémantique se penche sur l'intention et le contexte pour identifier les documents traitant d'un même concept, même s'ils ne partagent pas exactement les mêmes termes. Grâce à cette fonctionnalité clé, la LSI est utile pour extraire la signification contextuelle des mots dans le corps d'un texte.
Okapi BM25
L'une des variantes les plus populaires du modèle probabiliste est la fonction BM25, qui est une fonction de classement selon la pertinence de la recherche. Les moteurs de recherche s'en servent pour évaluer la pertinence d'un document par rapport à une requête de recherche. La fonction BM25 ordonne un ensemble de documents en fonction de la fréquence des termes qui apparaissent dans chaque document, indépendamment des relations pouvant exister entre ces termes. Elle dispose de nombreuses fonctions de notation ayant différents composants et paramètres. BM signifie "best matching", c'est-à-dire la meilleure correspondance qui soit.
En quoi la récupération d'informations est-elle importante ?
En cette ère dominée par l'information, des données sont générées à chaque instant, à une échelle qui était inimaginable auparavant. Sans moyen viable pour accéder aux informations qu'elles renferment, les données sont inutiles. Les systèmes de RI font en sorte que les utilisateurs puissent obtenir les informations pertinentes dont ils ont besoin, malgré l'explosion des volumes de données.
Les informations jouent un rôle essentiel dans pratiquement tous les secteurs et domaines du monde moderne, depuis le milieu scolaire et le e-commerce jusqu'à la santé et à la défense. Il s'agit d'une interface homme-machine qui aide à la prise de décision, la recherche et la découverte de connaissances, aussi bien au niveau de l'entreprise qu'au niveau individuel. Qu'il s'agisse de trouver un bureau local ou de s'informer de ce qui se passe dans le monde, de réaliser une recherche sur le génome ou de filtrer des spams, la récupération d'informations intervient dans presque chaque aspect de nos vies.
Les moteurs de recherche s'appuient sur des modèles de récupération pour fournir des résultats précis. Les plateformes de e-commerce s'en servent également pour recommander des produits selon les préférences et les comportements des utilisateurs. Les bibliothèques numériques exploitent la science de la récupération d'informations pour aider les utilisateurs à faire des recherches. Dans le domaine de la santé, les systèmes de RI facilitent la recherche dans les bases de données pour trouver les dossiers des patients, les recherches médicales et les protocoles de traitement appropriés. Quant aux professionnels juridiques, ils se servent de la récupération d'informations pour passer de gros volumes d'affaires judiciaires au peigne fin afin de déterminer l'existence éventuelle d'une jurisprudence.
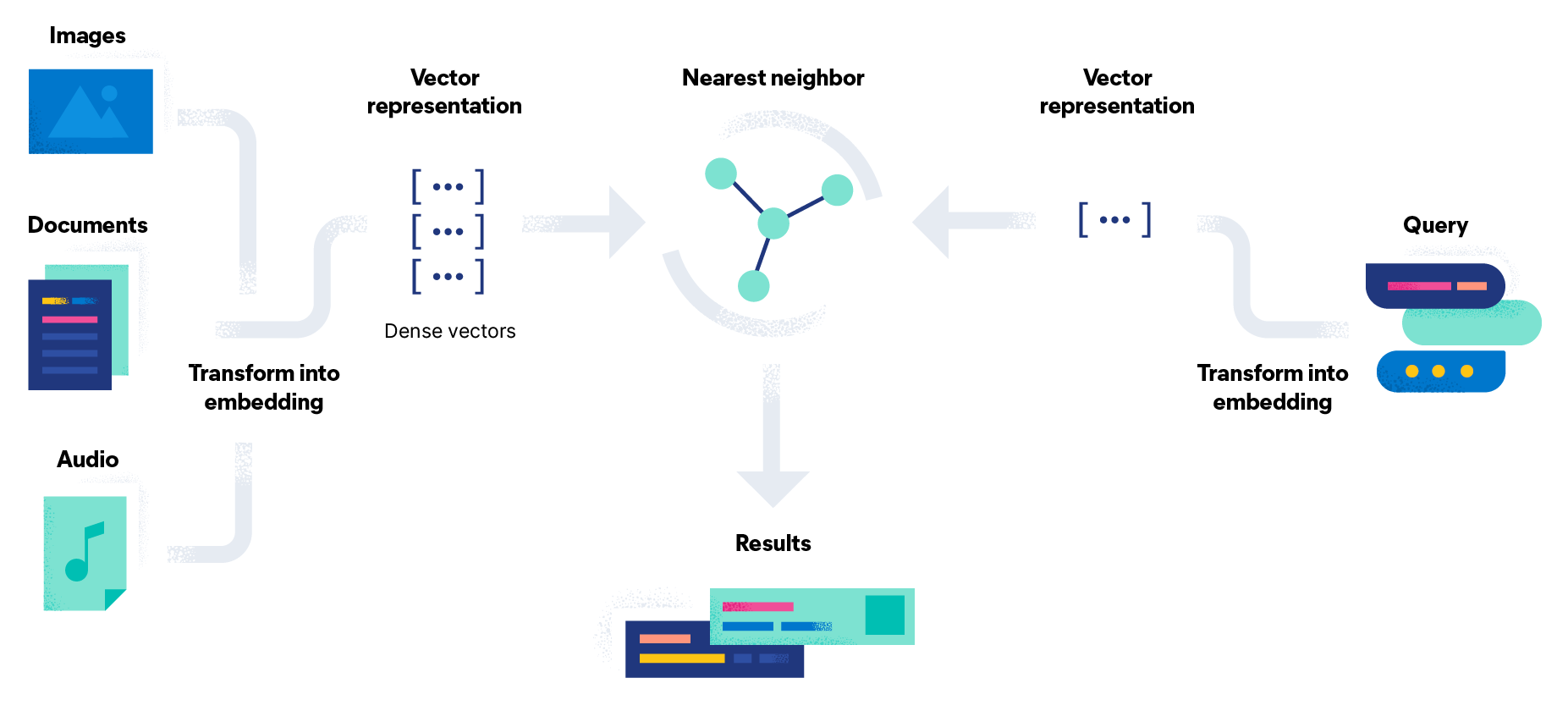
Comment un système de récupération d'informations fonctionne-t-il ?
Le processus de récupération d'informations s'enclenche à partir du moment où un utilisateur entre une requête formelle qui énonce son besoin en informations dans un système. Le système de RI crée alors un index des documents qui figurent dans un ensemble de contenus ou dans une base de données. Les objets de données, y compris ceux provenant de documents texte, d'images, de documents audio et de vidéos, sont traités pour en extraire les termes pertinents et les données représentatives. Les structures de données, quant à elles, servent à stocker et à récupérer ces entités avec efficacité.
Lorsqu'un utilisateur soumet une requête, le système la traite pour en identifier les termes pertinents et évaluer leur importance. Le système classe ensuite les documents en fonction de leur pertinence par rapport à la requête. Dans de nombreux cas, les modèles et algorithmes de RI servent à calculer un score numérique en fonction du degré de correspondance de chaque objet de la collection et de la base de données par rapport à la requête. La plupart des requêtes n'obtiendront pas de correspondance exacte. Dans ce cas, les documents sont classés par ordre de pertinence, les premiers étant les plus pertinents. Ce classement des résultats est l'une des principales différences qui existent entre une recherche dans le cadre d'une récupération d'informations et une recherche dans une base de données.
Principaux composants d'un système de récupération d'informations
Un système de récupération d'informations est constitué de plusieurs composants fondamentaux :
Collection de documents
Ensemble de documents à partir desquels le système peut récupérer des informations.
Composant d'indexation
Un index est créé à partir des données et documents source traités. Il mappe les termes et données qui y sont associés, souvent dans une structure de données optimisée et dédiée.
Outil de traitement des requêtes
L'outil de traitement des requêtes analyse les requêtes et les mots-clés de l'utilisateur, puis les prépare afin de les comparer aux entités indexées.
Algorithme de classement
L'algorithme de classement détermine la pertinence des documents par rapport à une requête et leur attribue un score. L'algorithme le plus courant est le BM25 (Best Match 25), qui se distingue par l'approche qu'il emploie concernant la fréquence des termes pour éviter de saturer le document de mots-clés et de répétitions de termes.
Interface utilisateur
L'interface utilisateur est l'écran grâce auquel l'utilisateur interagit avec le système, soumet ses requêtes et obtient des résultats. Dans cette interface, les résultats peuvent être ajustés selon la précision avec laquelle ils répondent à la requête de l'utilisateur. Dans certains cas, des mécanismes peuvent permettre aux utilisateurs d'évaluer la pertinence des documents récupérés, afin d'améliorer les récupérations ultérieures.
Avantages de la récupération d'informations
Les principaux avantages des modèles de récupération d'informations sont les suivants :
- Un accès efficace aux informations : premier avantage, et non des moindres, les systèmes de RI permettent aux utilisateurs d'économiser beaucoup de temps et d'efforts. En effet, les utilisateurs peuvent accéder rapidement aux informations qui les intéressent sans avoir à faire une recherche manuelle fastidieuse dans de vastes volumes de documents et de données.
- La découverte des connaissances : la récupération d'informations est un outil puissant qui permet d'extraire le sens des données. Avec la RI, les utilisateurs peuvent identifier les tendances, les schémas et les relations au sein des données, qui ne seraient pas forcément visibles de prime abord.
- Personnalisation : certains systèmes de RI peuvent adapter les résultats de façon pertinente selon les préférences et les comportements des utilisateurs.
- Soutien à la décision : les professionnels ont les moyens de prendre des décisions éclairées en accédant aux informations les plus pertinentes lorsqu'ils en ont besoin.
Défis et limitations de la récupération d'informations
Malgré des avancées significatives, la récupération des informations n'est pas parfaite. Des problèmes, défis et limitations persistent, parmi lesquels :
Ambiguïté : le langage naturel est fondamentalement ambigu, ce qui complique l'interprétation des requêtes de l'utilisateur. Un langage flou et les incertitudes sont des problèmes similaires qui peuvent également avoir une incidence sur le processus d'indexation et d'évaluation, en particulier avec des objets comme les images et les vidéos.
Pertinence : la détermination de la pertinence est subjective et peut varier selon le contexte et l'intention de l'utilisateur. Les critères utilisés pour déterminer la valeur et l'importance peuvent être régis par un ensemble de normes générales imparfaites, qui ne reflètent en rien les besoins spécifiques de l'utilisateur concerné.
Écarts sémantiques : les systèmes de récupération peuvent avoir du mal à comprendre la signification profonde du contenu en raison d'un écart entre la représentation textuelle et la compréhension humaine. Le manque de clarté dans les informations et dans les expressions de l'utilisateur représente un véritable obstacle pour que la RI soit réussie. Le traitement du langage naturel (NLP) adossé à l'IA cherche à combler ces écarts, que ce soit au niveau de la sémantique ou de l'ambiguïté.
Scalabilité : avec l'augmentation des volumes de données, il devient de plus en plus compliqué de maintenir une récupération et une indexation efficaces, car les ressources et la puissance informatique dont elles ont besoin sont de plus en plus conséquentes.
Tendances à venir concernant la récupération d'informations
Avec les innovations récentes en matière d'IA générative et de Machine Learning, la récupération d'informations telle que nous la connaissons est sur le point de changer.
Les techniques avancées du Machine Learning contribuent déjà à améliorer la récupération. Elles lui permettent d'apprendre des interactions utilisateur et de s'adapter au contexte, à l'emplacement géographique et aux préférences. Grâce à l'amélioration du traitement du langage naturel et de l'analyse sémantique, il est plus facile de comprendre les requêtes de l'utilisateur et le contenu des documents. Les systèmes de récupération évoluent aussi pour gérer efficacement le déferlement croissant de contenus multimédia.
L'IA générative peut donc avoir un impact révolutionnaire sur la récupération d'informations. Plutôt que d'obtenir une liste de résultats, dans laquelle nous devons faire le tri manuellement en fonction des liens et des documents existants pour trouver ce que nous cherchons, nous recevons une réponse concrète à nos questions. Le contexte sera pris en compte de question en question, ce qui permettra d'effectuer des requêtes complexes, conversationnelles,en plusieurs étapes, grâce la suppression quasi-complète des barrières liées au traitement du langage humain et à l'intention. Nous n'aurons plus à assembler les réponses par nous-mêmes : ce sont les moteurs de recherche qui s'en chargeront. Ils synthétiseront les informations en résultats spécifiques et personnalisés, présentés sous forme de contenu original qui répondra avec exactitude à notre besoin, sans rien de superflu.
Découvrez les grandes tendances en matière de recherche technique pour 2024. Regardez ce webinar pour vous familiariser avec les bonnes pratiques et les méthodologies émergentes, ainsi que pour découvrir les grandes tendances incontournables pour les développeurs en 2024.
La récupération d'informations avec Elasticsearch
Elastic s'est fixé un objectif : celui d'améliorer de manière continue les fonctionnalités de récupération d'informations disponibles dans la Suite Elastic. Notre modèle de récupération le plus récent, Elastic Learned Sparse Encoder, vient renforcer la récupération prête à l'emploi que propose Elastic grâce à un modèle de langage pré-entraîné. Et pour offrir une expérience simplissime, nous l'avons intégré dans le nouveau moteur Elasticsearch Relevance Engine.
Elasticsearch fournit également d'excellentes fonctionnalités de récupération lexicale et des outils enrichis pour combiner les résultats de différentes requêtes. On appelle ce concept "récupération hybride". Et ce n'est pas tout. Nous renforçons les fonctionnalités de chatbot avec le NLP et la recherche vectorielle, nous publions des modèles tiers de traitement du langage naturel pour les plongements textuels et nous évaluons nos performances à l'aide d'un sous-ensemble de Benchmarking-IR.
Plus de ressources sur la récupération d'informations
- Improving information retrieval in the Elastic Stack: Introducing Elastic Learned Sparse Encoder, our new retrieval model
- Improving information retrieval in the Elastic Stack: Steps to improve search relevance
- Improving information retrieval in the Elastic Stack: Benchmarking passage retrieval
- Vers une récupération d'informations améliorée dans la Suite Elastic : la récupération hybride
- Understanding AI search algorithms
Prochaines étapes conseillées
Pour aller plus loin, voici quatre méthodes qui vous aideront à révéler des informations exploitables à partir des données de votre entreprise :
- Démarrez un essai gratuit et découvrez l'aide qu'Elastic peut apporter à votre entreprise.
- Faites le tour de nos solutions afin de savoir comment Elasticsearch Platform fonctionne et comment elles s'adaptent à vos besoins.
- Découvrez comment mettre en place l'IA générative dans votre entreprise.
- Partagez cet article avec une personne de votre réseau qui pourrait être intéressée par son contenu. Partagez cet article par e-mail, sur LinkedIn, sur Twitter ou sur Facebook.