Que sont les plongements lexicaux ?
Définition des plongements lexicaux
Le plongement lexical est une technique utilisée dans le traitement du langage naturel (NLP). Elle consiste à représenter des mots sous forme de nombres, afin qu'un ordinateur puisse s'en servir pour travailler. Il s'agit d'une approche populaire en matière de représentations numériques de texte à apprendre.
Les machines ont besoin d'aide pour savoir comment traiter les mots. C'est pourquoi chaque mot doit se voir attribuer un format numérique pour qu'il puisse être traité. Dans cette optique, plusieurs approches sont possibles :
- L'encodage 1 parmi n, ou encore encodage one-hot, attribue à chaque mot un nombre unique dans le corps d'un texte. Ce nombre est converti en vecteur binaire (à l'aide de 0 et de 1) qui représente le mot.
- La représentation distributionnelle compte le nombre de fois où un mot apparaît dans le corps d'un texte et lui attribue un vecteur correspondant.
- La combinaison SLIM (Sparse Late Interaction Models) utilise ces deux méthodes pour que l'ordinateur puisse à la fois comprendre le sens des mots et déterminer le nombre d'apparitions de ces mots dans le texte.
Un plongement lexical crée un espace à haute dimensionnalité dans lequel chaque mot est associé à un vecteur dense de nombres (sujet que nous détaillerons ci-dessous). Un ordinateur peut ensuite se servir de ces vecteurs pour comprendre les relations entre les mots et formuler des prédictions.
Comment un plongement lexical fonctionne-t-il dans le traitement du langage naturel ?
Dans le cadre du traitement du langage naturel, le plongement lexical représente les mots sous forme de vecteurs denses de nombres réels dans un espace à haute dimensionnalité, pouvant compter jusqu'à 1 000 dimensions. La vectorisation est le processus qui consiste à convertir les mots en vecteurs numériques. Un vecteur dense est un vecteur dans lequel la plupart des entrées sont différentes de 0. C'est l'opposé d'un vecteur creux, comme l'encodage one-hot, qui contient de nombreuses entrées égales à 0. Cet espace à haute dimensionnalité est appelé "espace de plongement".
Les mots qui ont des sens similaires ou qui sont utilisés dans des contextes analogues se voient attribuer des vecteurs équivalents, ce qui signifie qu'ils se situent à proximité les uns des autres dans l'espace de plongement. Par exemple,"thé" et "café" sont des mots similaires qui se situeraient l'un à côté de l'autre, alors que les mots "terre" et "verre" seraient plus éloignés étant donné qu'ils n'ont pas le même sens, même s'ils ont une orthographe similaire.
Même s'il existe différentes méthodes pour créer des plongements lexicaux dans le cadre du traitement du langage naturel, elles impliquent toutes un entraînement sur un large volume de données textuelles, qu'on appelle corpus. Ce corpus peut varier. Wikipedia et Google Actualités sont deux exemples communs de corpus utilisés pour l'entraînement.
Le corpus peut aussi se présenter sous la forme d'une couche de plongement personnalisée, spécifiquement conçue pour un cas d'utilisation lorsque d'autres corpus pré-entraînés ne peuvent pas fournir suffisamment de données. Lors de l'entraînement, le modèle apprend à associer chaque mot avec un vecteur unique d'après les schémas d'utilisation de ce mot dans les données. Ces approches peuvent être utilisées pour transformer les mots qui se trouvent dans de nouvelles données textuelles en vecteurs denses.
Comment les plongements lexicaux sont-ils réalisés ?
Plusieurs techniques permettent de réaliser les plongements lexicaux. Le choix de la technique dépend des exigences spécifiques de la tâche que vous devez exécuter. Vous devez prendre en compte la taille de l'ensemble de données, le domaine des données et la complexité de la langue. Parmi les techniques les plus populaires pour réaliser des plongements lexicaux, citons :
- Word2vec est un algorithme basé sur un réseau de neurones à deux couches, dont l'entrée est un corpus de textes et la sortie, un ensemble de vecteurs (d'où son nom). Voici un exemple commun de Word2vec : "Roi – Homme + Femme = Reine". En se basant sur la relation entre "Roi" et "Homme" et entre "Homme" et "Femme", l'algorithme peut déduire que "Reine" est le mot approprié correspondant à "Roi". Word2vec est entraîné soit avec un algorithme Skip-Gram, soit avec un algorithme Continuous Bag of Words (CBOW). L'algorithme Skip-Gram essaye de prédire des mots contextuels à partir d'un mot cible. L'algorithme Continuous Bag of Words a le fonctionnement inverse : il prédit le mot cible en se basant sur le contexte des mots qui l'entourent.
- GloVe (Global Vectors) part du principe que le sens d'un mot peut être déduit à partir de sa coexistence avec d'autres mots dans un corpus de textes. L'algorithme crée une matrice de coexistence qui détermine à quelle fréquence ces mots apparaissent ensemble dans le corpus.
- fastText est une extension du modèle Word2vec, qui vise à représenter les mots comme des sacs de caractères n-grammes, ou sous-unités de mots, plutôt que des mots en tant que tels. Basée sur un modèle similaire à Skip-Gram, fastText capture des informations sur la structure interne des mots qui l'aident à traiter le vocabulaire nouveau et inhabituel.
- ELMo (Embeddings from Language Models) est différent des plongements lexicaux présentés ci-dessus, car il se sert d'un réseau de neurones profond qui analyse l'intégralité du contexte dans lequel un mot apparaît. Il peut ainsi saisir les subtilités de sens à côté desquelles d'autres techniques de plongement peuvent passer.
- TF-IDF (Term Frequency - Inverse Document Frequency) est une valeur mathématique que l'on calcule en multipliant la fréquence d'un terme (TF) par la fréquence inverse de document (IDF). La TF désigne le rapport entre un terme cible et tous les termes dans le document. L'IDF est un logarithme du rapport entre le nombre total de documents et le nombre de documents contenant le terme cible.
Quels sont les avantages des plongements lexicaux ?
Les plongements lexicaux offrent plusieurs avantages pour représenter les mots dans le traitement du langage naturel par rapport aux approches traditionnelles. Ils constituent désormais une approche standard du NLP. On trouve de nombreux plongements lexicaux qui sont pré-entraînés et utilisables dans un éventail d'applications. Grâce à cette vaste disponibilité, les chercheurs et les développeurs ont pu les intégrer facilement dans leurs modèles sans devoir les entraîner de zéro.
C'est un plongement lexical qui a servi à améliorer la modélisation du langage, c'est-à-dire la tâche qui consiste à prédire le mot suivant dans une séquence de texte. En représentant les mots sous forme de vecteurs, les modèles peuvent mieux capturer le contexte dans lequel un mot apparaît et formuler des prédictions plus précises.
L'élaboration de plongements lexicaux peut être plus rapide que les techniques d'ingénierie traditionnelles, car le processus d'entraînement d'un réseau de neurones sur un grand corpus de données textuelles n'est pas supervisé, ce qui permet d'économiser du temps et des efforts. Une fois que le plongement est entraîné, il peut servir de caractéristique d'entrée pour un large éventail de tâches de NLP, sans qu'il y ait besoin de créer de caractéristique supplémentaire.
Les plongements lexicaux ont généralement une dimensionnalité bien inférieure à celle des vecteurs à encodage one-hot. Ils ont donc besoin de moins de mémoire et de moins de ressources informatiques à stocker et à manipuler. Étant donné qu'un plongement lexical est une représentation des mots en vecteurs denses, il représente les mots avec plus d'efficacité que les techniques à vecteurs creux. Il peut également mieux établir les relations sémantiques qui existent entre les mots.
Quels sont les inconvénients des plongements lexicaux ?
Même si les plongements lexicaux présentent de nombreux avantages, ils s'accompagnent également d'inconvénients dont il faut tenir compte.
L'entraînement des plongements lexicaux peut mobiliser beaucoup de ressources informatiques, en particulier lorsque leur entraînement se fait avec des ensembles de données volumineux ou des modèles complexes. Les plongements pré-entraînés peuvent aussi nécessiter un espace de stockage conséquent, ce qui peut poser problème aux applications disposant de ressources limitées. Les plongements lexicaux sont entraînés sur un vocabulaire défini. Ils peuvent donc se retrouver dans l'incapacité de représenter des mots qui ne font pas partie de ce vocabulaire. Cela peut être un problème pour les langues ayant un vocabulaire varié ou pour une terminologie spécifique à l'application.
Si les données entrées servant au plongement lexical contiennent des biais, le plongement lexical les reflétera. Par exemple, les plongements lexicaux peuvent encoder des biais en ce qui concerne le genre, la race ou d'autres stéréotypes, ce qui peut avoir des conséquences sur les situations concrètes dans lesquelles ils sont utilisés.
On considère souvent les plongements lexicaux comme une boîte noire car les modèles qui les sous-tendent, comme les réseaux de neurones GloVe ou Word2Vec, sont complexes et difficiles à interpréter.
L'adéquation d'un plongement lexical dépend de celle de ses données d'entraînement. Il est important de s'assurer que le volume de données à utiliser par le plongement lexical est suffisant en pratique. Même si les plongements lexicaux comprennent les relations générales qui existent entre les mots, ils peuvent passer à côté de certaines nuances humaines, comme le sarcasme, qui sont bien plus difficiles à reconnaître.
Étant donné qu'un plongement lexical attribue un vecteur à chaque mot, il peut éprouver des difficultés face aux homographes, qui sont des mots qui ont la même orthographe mais qui ont des sens différents. (Par exemple, le mot "fier" peut désigner le sentiment de fierté ou le fait de pouvoir faire confiance à quelque chose/quelqu'un.)
Pourquoi les plongements lexicaux sont-ils utilisés ?
Les plongements lexicaux servent dans le cadre de la recherche vectorielle. Ils jouent un rôle essentiel dans les tâches de traitement du langage naturel, telles que l'analyse des sentiments, la classification de textes et la traduction. Les plongements lexicaux offrent un moyen efficace aux machines de reconnaître et de capturer les relations sémantiques entre les mots. Ainsi, les modèles NLP gagnent plus de précision et d'efficacité qu'avec l'ingénierie manuelle des caractéristiques. Le résultat final est donc plus accessible et efficace pour les utilisateurs.
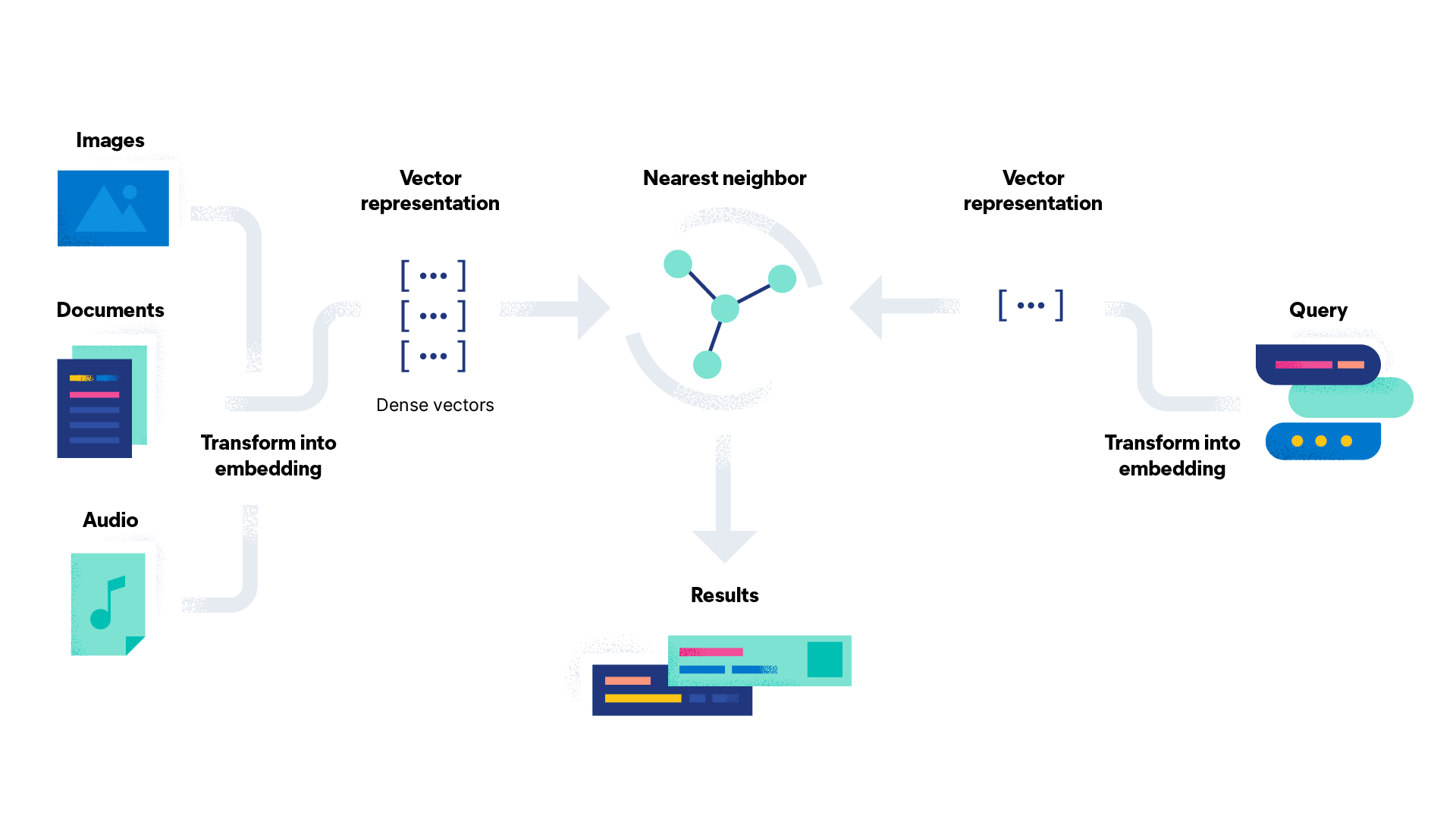
Les plongements lexicaux peuvent être utiles pour de nombreuses tâches. En voici quelques cas d'utilisation :
- Analyse des sentiments : l'analyse des sentiments utilise les plongements lexicaux pour classer un fragment de texte comme étant positif, négatif ou neutre. Les entreprises y ont souvent recours pour analyser les commentaires sur leurs produits venant des évaluations client ou des publications sur les réseaux sociaux.
- Systèmes de recommandation : les systèmes de recommandation suggèrent des produits ou des services aux utilisateurs en fonction de leurs interactions précédentes. Par exemple, un service de streaming peut se servir des plongements lexicaux pour recommander de nouveaux titres d'après l'historique de visionnage de l'utilisateur.
- Chatbots : les chatbots communiquent avec les clients en s'aidant du traitement du langage naturel pour répondre de façon appropriée à leurs requêtes.
- Moteurs de recherche : la recherche vectorielle est utilisée par les moteurs de recherche pour améliorer la précision des résultats. Elle se sert des plongements lexicaux pour analyser les requêtes de l'utilisateur et les confronter au contenu des pages web afin d'établir les meilleures correspondances.
- Contenu d'origine : pour créer un contenu d'origine, il faut transformer les données en langage naturel lisible. Un plongement lexical peut être appliqué à un vaste éventail de types de contenus, depuis les descriptions de produits jusqu'aux rapports sportifs après match.
Lancez-vous avec les plongements lexicaux, la recherche vectorielle et Elasticsearch
Elasticsearch est un moteur de recherche et d'analyse distribué, gratuit et ouvert pour tous types de données, notamment pour l'analyse de textes structurés et non structurés. Il stocke vos données en toute sécurité pour une recherche rapide, une pertinence sur mesure et des analyses puissantes qui s'adaptent efficacement. Elasticsearch est le composant principal de la Suite Elastic, un ensemble d'outils gratuits et ouverts d'ingestion, d'enrichissement, de stockage, d'analyse et de visualisation de données.
Elasticsearch vous aide à :
- améliorer l'expérience utilisateur et augmenter le nombre de conversions ;
- découvrir de nouvelles informations exploitables et mettre en place l'automatisation, les analyses et le reporting ;
- améliorer la productivité des employés sur les documents et les applications internes.
Ressources sur les plongements lexicaux
- Comment déployer le traitement du langage naturel : plongements textuels et recherche vectorielle
- 5 raisons pour lesquelles les responsables informatiques ont besoin de la recherche vectorielle pour améliorer les expériences de recherche
- Recherche de similarités textuelles grâce aux champs vectoriels
- How to deploy a text embedding model and use it for semantic search