- Elasticsearch Guide: other versions:
- Getting Started
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Important System Configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission check
- Starting Elasticsearch
- Stopping Elasticsearch
- Adding nodes to your cluster
- Installing X-Pack
- Set up X-Pack
- Configuring X-Pack Java Clients
- X-Pack Settings
- Bootstrap Checks for X-Pack
- Upgrade Elasticsearch
- API Conventions
- Document APIs
- Search APIs
- Aggregations
- Metrics Aggregations
- Avg Aggregation
- Weighted Avg Aggregation
- Cardinality Aggregation
- Extended Stats Aggregation
- Geo Bounds Aggregation
- Geo Centroid Aggregation
- Max Aggregation
- Min Aggregation
- Percentiles Aggregation
- Percentile Ranks Aggregation
- Scripted Metric Aggregation
- Stats Aggregation
- Sum Aggregation
- Top Hits Aggregation
- Value Count Aggregation
- Bucket Aggregations
- Adjacency Matrix Aggregation
- Auto-interval Date Histogram Aggregation
- Intervals
- Children Aggregation
- Composite Aggregation
- Date Histogram Aggregation
- Date Range Aggregation
- Diversified Sampler Aggregation
- Filter Aggregation
- Filters Aggregation
- Geo Distance Aggregation
- GeoHash grid Aggregation
- Global Aggregation
- Histogram Aggregation
- IP Range Aggregation
- Missing Aggregation
- Nested Aggregation
- Range Aggregation
- Reverse nested Aggregation
- Sampler Aggregation
- Significant Terms Aggregation
- Significant Text Aggregation
- Terms Aggregation
- Pipeline Aggregations
- Avg Bucket Aggregation
- Derivative Aggregation
- Max Bucket Aggregation
- Min Bucket Aggregation
- Sum Bucket Aggregation
- Stats Bucket Aggregation
- Extended Stats Bucket Aggregation
- Percentiles Bucket Aggregation
- Moving Average Aggregation
- Moving Function Aggregation
- Cumulative Sum Aggregation
- Bucket Script Aggregation
- Bucket Selector Aggregation
- Bucket Sort Aggregation
- Serial Differencing Aggregation
- Matrix Aggregations
- Caching heavy aggregations
- Returning only aggregation results
- Aggregation Metadata
- Returning the type of the aggregation
- Metrics Aggregations
- Indices APIs
- Create Index
- Delete Index
- Get Index
- Indices Exists
- Open / Close Index API
- Shrink Index
- Split Index
- Rollover Index
- Put Mapping
- Get Mapping
- Get Field Mapping
- Types Exists
- Index Aliases
- Update Indices Settings
- Get Settings
- Analyze
- Index Templates
- Indices Stats
- Indices Segments
- Indices Recovery
- Indices Shard Stores
- Clear Cache
- Flush
- Refresh
- Force Merge
- cat APIs
- Cluster APIs
- Query DSL
- Mapping
- Analysis
- Anatomy of an analyzer
- Testing analyzers
- Analyzers
- Normalizers
- Tokenizers
- Standard Tokenizer
- Letter Tokenizer
- Lowercase Tokenizer
- Whitespace Tokenizer
- UAX URL Email Tokenizer
- Classic Tokenizer
- Thai Tokenizer
- NGram Tokenizer
- Edge NGram Tokenizer
- Keyword Tokenizer
- Pattern Tokenizer
- Char Group Tokenizer
- Simple Pattern Tokenizer
- Simple Pattern Split Tokenizer
- Path Hierarchy Tokenizer
- Path Hierarchy Tokenizer Examples
- Token Filters
- Standard Token Filter
- ASCII Folding Token Filter
- Flatten Graph Token Filter
- Length Token Filter
- Lowercase Token Filter
- Uppercase Token Filter
- NGram Token Filter
- Edge NGram Token Filter
- Porter Stem Token Filter
- Shingle Token Filter
- Stop Token Filter
- Word Delimiter Token Filter
- Word Delimiter Graph Token Filter
- Multiplexer Token Filter
- Conditional Token Filter
- Predicate Token Filter Script
- Stemmer Token Filter
- Stemmer Override Token Filter
- Keyword Marker Token Filter
- Keyword Repeat Token Filter
- KStem Token Filter
- Snowball Token Filter
- Phonetic Token Filter
- Synonym Token Filter
- Synonym Graph Token Filter
- Compound Word Token Filters
- Reverse Token Filter
- Elision Token Filter
- Truncate Token Filter
- Unique Token Filter
- Pattern Capture Token Filter
- Pattern Replace Token Filter
- Trim Token Filter
- Limit Token Count Token Filter
- Hunspell Token Filter
- Common Grams Token Filter
- Normalization Token Filter
- CJK Width Token Filter
- CJK Bigram Token Filter
- Delimited Payload Token Filter
- Keep Words Token Filter
- Keep Types Token Filter
- Exclude mode settings example
- Classic Token Filter
- Apostrophe Token Filter
- Decimal Digit Token Filter
- Fingerprint Token Filter
- Minhash Token Filter
- Remove Duplicates Token Filter
- Character Filters
- Modules
- Index Modules
- Ingest Node
- Pipeline Definition
- Ingest APIs
- Accessing Data in Pipelines
- Conditional Execution in Pipelines
- Handling Failures in Pipelines
- Processors
- Append Processor
- Bytes Processor
- Convert Processor
- Date Processor
- Date Index Name Processor
- Dissect Processor
- Drop Processor
- Dot Expander Processor
- Fail Processor
- Foreach Processor
- Grok Processor
- Gsub Processor
- Join Processor
- JSON Processor
- KV Processor
- Lowercase Processor
- Pipeline Processor
- Remove Processor
- Rename Processor
- Script Processor
- Set Processor
- Set Security User Processor
- Split Processor
- Sort Processor
- Trim Processor
- Uppercase Processor
- URL Decode Processor
- SQL Access
- Monitor a cluster
- Rolling up historical data
- Set up a cluster for high availability
- Secure a cluster
- Overview
- Configuring security
- Encrypting communications in Elasticsearch
- Encrypting communications in an Elasticsearch Docker Container
- Enabling cipher suites for stronger encryption
- Separating node-to-node and client traffic
- Configuring an Active Directory realm
- Configuring a file realm
- Configuring an LDAP realm
- Configuring a native realm
- Configuring a PKI realm
- Configuring a SAML realm
- Configuring a Kerberos realm
- FIPS 140-2
- Security settings
- Security files
- Auditing settings
- How security works
- User authentication
- Built-in users
- Internal users
- Realms
- Realm chains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- User authorization
- Auditing security events
- Encrypting communications
- Restricting connections with IP filtering
- Cross cluster search, tribe, clients, and integrations
- Tutorial: Getting started with security
- Tutorial: Encrypting communications
- Troubleshooting
- Can’t log in after upgrading to 6.5.4
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Alerting on Cluster and Index Events
- Command line tools
- How To
- Testing
- Glossary of terms
- X-Pack APIs
- Info API
- Cross-cluster replication APIs
- Explore API
- Licensing APIs
- Migration APIs
- Machine learning APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create calendar
- Create datafeeds
- Create filter
- Create jobs
- Delete calendar
- Delete datafeeds
- Delete events from calendar
- Delete filter
- Delete forecast
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Find file structure
- Flush jobs
- Forecast jobs
- Get calendars
- Get buckets
- Get overall buckets
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get machine learning info
- Get model snapshots
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Revert model snapshots
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filter
- Update jobs
- Update model snapshots
- Rollup APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete users
- Disable users
- Enable users
- Get application privileges
- Get role mappings
- Get roles
- Get token
- Get users
- Has privileges
- Invalidate token
- SSL certificate
- Watcher APIs
- Definitions
- Release Highlights
- Breaking changes
- Release Notes
- Elasticsearch version 6.5.4
- Elasticsearch version 6.5.3
- Elasticsearch version 6.5.2
- Elasticsearch version 6.5.1
- Elasticsearch version 6.5.0
- Elasticsearch version 6.4.3
- Elasticsearch version 6.4.2
- Elasticsearch version 6.4.1
- Elasticsearch version 6.4.0
- Elasticsearch version 6.3.2
- Elasticsearch version 6.3.1
- Elasticsearch version 6.3.0
- Elasticsearch version 6.2.4
- Elasticsearch version 6.2.3
- Elasticsearch version 6.2.2
- Elasticsearch version 6.2.1
- Elasticsearch version 6.2.0
- Elasticsearch version 6.1.4
- Elasticsearch version 6.1.3
- Elasticsearch version 6.1.2
- Elasticsearch version 6.1.1
- Elasticsearch version 6.1.0
- Elasticsearch version 6.0.1
- Elasticsearch version 6.0.0
- Elasticsearch version 6.0.0-rc2
- Elasticsearch version 6.0.0-rc1
- Elasticsearch version 6.0.0-beta2
- Elasticsearch version 6.0.0-beta1
- Elasticsearch version 6.0.0-alpha2
- Elasticsearch version 6.0.0-alpha1
- Elasticsearch version 6.0.0-alpha1 (Changes previously released in 5.x)
Adding nodes to your cluster
editAdding nodes to your cluster
editWhen you start an instance of Elasticsearch, you are starting a node. An Elasticsearch cluster
is a group of nodes that have the same cluster.name attribute. As nodes join
or leave a cluster, the cluster automatically reorganizes itself to evenly
distribute the data across the available nodes.
If you are running a single instance of Elasticsearch, you have a cluster of one node. All primary shards reside on the single node. No replica shards can be allocated, therefore the cluster state remains yellow. The cluster is fully functional but is at risk of data loss in the event of a failure.

You add nodes to a cluster to increase its capacity and reliability. By default, a node is both a data node and eligible to be elected as the master node that controls the cluster. You can also configure a new node for a specific purpose, such as handling ingest requests. For more information, see Nodes.
When you add more nodes to a cluster, it automatically allocates replica shards. When all primary and replica shards are active, the cluster state changes to green.
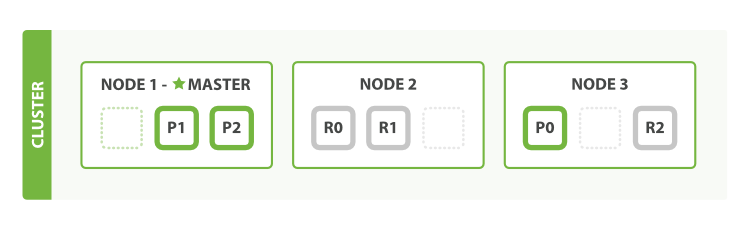
To add a node to a cluster:
- Set up a new Elasticsearch instance.
-
Specify the name of the cluster in its
cluster.nameattribute. For example, to add a node to thelogging-prodcluster, setcluster.name: "logging-prod"inelasticsearch.yml. - Start Elasticsearch. The node automatically discovers and joins the specified cluster.
For more information about discovery and shard allocation, see Discovery and Cluster.