- Elasticsearch Guide: other versions:
- Elasticsearch introduction
- Getting started with Elasticsearch
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Important System Configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission check
- Discovery configuration check
- Starting Elasticsearch
- Stopping Elasticsearch
- Adding nodes to your cluster
- Full-cluster restart and rolling restart
- Set up X-Pack
- Configuring X-Pack Java Clients
- Bootstrap Checks for X-Pack
- Upgrade Elasticsearch
- Aggregations
- Metrics Aggregations
- Avg Aggregation
- Weighted Avg Aggregation
- Cardinality Aggregation
- Extended Stats Aggregation
- Geo Bounds Aggregation
- Geo Centroid Aggregation
- Max Aggregation
- Min Aggregation
- Percentiles Aggregation
- Percentile Ranks Aggregation
- Scripted Metric Aggregation
- Stats Aggregation
- Sum Aggregation
- Top Hits Aggregation
- Value Count Aggregation
- Median Absolute Deviation Aggregation
- Bucket Aggregations
- Adjacency Matrix Aggregation
- Auto-interval Date Histogram Aggregation
- Children Aggregation
- Composite aggregation
- Date histogram aggregation
- Date Range Aggregation
- Diversified Sampler Aggregation
- Filter Aggregation
- Filters Aggregation
- Geo Distance Aggregation
- GeoHash grid Aggregation
- GeoTile Grid Aggregation
- Global Aggregation
- Histogram Aggregation
- IP Range Aggregation
- Missing Aggregation
- Nested Aggregation
- Parent Aggregation
- Range Aggregation
- Rare Terms Aggregation
- Reverse nested Aggregation
- Sampler Aggregation
- Significant Terms Aggregation
- Significant Text Aggregation
- Terms Aggregation
- Subtleties of bucketing range fields
- Pipeline Aggregations
- Avg Bucket Aggregation
- Derivative Aggregation
- Max Bucket Aggregation
- Min Bucket Aggregation
- Sum Bucket Aggregation
- Stats Bucket Aggregation
- Extended Stats Bucket Aggregation
- Percentiles Bucket Aggregation
- Moving Average Aggregation
- Moving Function Aggregation
- Cumulative Sum Aggregation
- Cumulative Cardinality Aggregation
- Bucket Script Aggregation
- Bucket Selector Aggregation
- Bucket Sort Aggregation
- Serial Differencing Aggregation
- Matrix Aggregations
- Caching heavy aggregations
- Returning only aggregation results
- Aggregation Metadata
- Returning the type of the aggregation
- Metrics Aggregations
- Query DSL
- Search across clusters
- Scripting
- Mapping
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Char Group Tokenizer
- Classic Tokenizer
- Edge n-gram tokenizer
- Limitations of the
max_gramparameter - Keyword Tokenizer
- Letter Tokenizer
- Lowercase Tokenizer
- N-gram tokenizer
- Path Hierarchy Tokenizer
- Path Hierarchy Tokenizer Examples
- Pattern Tokenizer
- Simple Pattern Tokenizer
- Simple Pattern Split Tokenizer
- Standard Tokenizer
- Thai Tokenizer
- UAX URL Email Tokenizer
- Whitespace Tokenizer
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Modules
- Index modules
- Ingest node
- Pipeline Definition
- Accessing Data in Pipelines
- Conditional Execution in Pipelines
- Handling Failures in Pipelines
- Enrich your data
- Processors
- Append Processor
- Bytes Processor
- Circle Processor
- Convert Processor
- Date Processor
- Date Index Name Processor
- Dissect Processor
- Dot Expander Processor
- Drop Processor
- Enrich Processor
- Fail Processor
- Foreach Processor
- GeoIP Processor
- Grok Processor
- Gsub Processor
- HTML Strip Processor
- Join Processor
- JSON Processor
- KV Processor
- Lowercase Processor
- Pipeline Processor
- Remove Processor
- Rename Processor
- Script Processor
- Set Processor
- Set Security User Processor
- Split Processor
- Sort Processor
- Trim Processor
- Uppercase Processor
- URL Decode Processor
- User Agent processor
- Managing the index lifecycle
- Getting started with index lifecycle management
- Policy phases and actions
- Set up index lifecycle management policy
- Using policies to manage index rollover
- Update policy
- Index lifecycle error handling
- Restoring snapshots of managed indices
- Start and stop index lifecycle management
- Using ILM with existing indices
- Getting started with snapshot lifecycle management
- Snapshot lifecycle management retention
- SQL access
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Monitor a cluster
- Frozen indices
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure a cluster
- Overview
- Configuring security
- User authentication
- Built-in users
- Internal users
- Token-based authentication services
- Realms
- Realm chains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Security privileges
- Document level security
- Field level security
- Granting privileges for indices and aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enabling audit logging
- Encrypting communications
- Restricting connections with IP filtering
- Cross cluster search, clients, and integrations
- Tutorial: Getting started with security
- Tutorial: Encrypting communications
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Alerting on cluster and index events
- Command line tools
- How To
- Testing
- Glossary of terms
- REST APIs
- API conventions
- cat APIs
- Cluster APIs
- Cross-cluster replication APIs
- Document APIs
- Enrich APIs
- Explore API
- Index APIs
- Add index alias
- Analyze
- Clear cache
- Clone index
- Close index
- Create index
- Delete index
- Delete index alias
- Delete index template
- Flush
- Force merge
- Freeze index
- Get field mapping
- Get index
- Get index alias
- Get index settings
- Get index template
- Get mapping
- Index alias exists
- Index exists
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists
- Open index
- Put index template
- Put mapping
- Refresh
- Rollover index
- Shrink index
- Split index
- Synced flush
- Type exists
- Unfreeze index
- Update index alias
- Update index settings
- Index lifecycle management API
- Ingest APIs
- Info API
- Licensing APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendar
- Create datafeeds
- Create filter
- Delete calendar
- Delete datafeeds
- Delete events from calendar
- Delete filter
- Delete forecast
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Find file structure
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get machine learning info
- Get model snapshots
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Revert model snapshots
- Set upgrade mode
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filter
- Update jobs
- Update model snapshots
- Machine learning data frame analytics APIs
- Migration APIs
- Reload search analyzers
- Rollup APIs
- Search APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete users
- Disable users
- Enable users
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get token
- Get users
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect Prepare Authentication API
- OpenID Connect authenticate API
- OpenID Connect logout API
- SAML prepare authentication API
- SAML authenticate API
- SAML logout API
- SAML invalidate API
- SSL certificate
- Snapshot lifecycle management API
- Put snapshot lifecycle policy
- Get snapshot lifecycle policy
- Execute snapshot lifecycle policy
- Get snapshot lifecycle stats
- Delete snapshot lifecycle policy
- Execute snapshot lifecycle retention
- Stop Snapshot Lifecycle Management
- Start Snapshot Lifecycle Management
- Get Snapshot Lifecycle Management status
- Transform APIs
- Watcher APIs
- Definitions
- Release highlights
- Breaking changes
- Release notes
- Elasticsearch version 7.5.2
- Elasticsearch version 7.5.1
- Elasticsearch version 7.5.0
- Elasticsearch version 7.4.2
- Elasticsearch version 7.4.1
- Elasticsearch version 7.4.0
- Elasticsearch version 7.3.2
- Elasticsearch version 7.3.1
- Elasticsearch version 7.3.0
- Elasticsearch version 7.2.1
- Elasticsearch version 7.2.0
- Elasticsearch version 7.1.1
- Elasticsearch version 7.1.0
- Elasticsearch version 7.0.0
- Elasticsearch version 7.0.0-rc2
- Elasticsearch version 7.0.0-rc1
- Elasticsearch version 7.0.0-beta1
- Elasticsearch version 7.0.0-alpha2
- Elasticsearch version 7.0.0-alpha1
Transform overview
editTransform overview
editThis functionality is in beta and is subject to change. The design and code is less mature than official GA features and is being provided as-is with no warranties. Beta features are not subject to the support SLA of official GA features.
You can use transforms to pivot your data into a new entity-centric index. By transforming and summarizing your data, it becomes possible to visualize and analyze it in alternative and interesting ways.
A lot of Elasticsearch indices are organized as a stream of events: each event is an individual document, for example a single item purchase. Transforms enable you to summarize this data, bringing it into an organized, more analysis-friendly format. For example, you can summarize all the purchases of a single customer.
Transforms enable you to define a pivot, which is a set of features that transform the index into a different, more digestible format. Pivoting results in a summary of your data in a new index.
To define a pivot, first you select one or more fields that you will use to group your data. You can select categorical fields (terms) and numerical fields for grouping. If you use numerical fields, the field values are bucketed using an interval that you specify.
The second step is deciding how you want to aggregate the grouped data. When using aggregations, you practically ask questions about the index. There are different types of aggregations, each with its own purpose and output. To learn more about the supported aggregations and group-by fields, see Transform resources.
As an optional step, you can also add a query to further limit the scope of the aggregation.
The transform performs a composite aggregation that paginates through all the data defined by the source index query. The output of the aggregation is stored in a destination index. Each time the transform queries the source index, it creates a checkpoint. You can decide whether you want the transform to run once (batch transform) or continuously (continuous transform). A batch transform is a single operation that has a single checkpoint. Continuous transforms continually increment and process checkpoints as new source data is ingested.
ExampleImagine that you run a webshop that sells clothes. Every order creates a document that contains a unique order ID, the name and the category of the ordered product, its price, the ordered quantity, the exact date of the order, and some customer information (name, gender, location, etc). Your dataset contains all the transactions from last year.
If you want to check the sales in the different categories in your last fiscal year, define a transform that groups the data by the product categories (women’s shoes, men’s clothing, etc.) and the order date. Use the last year as the interval for the order date. Then add a sum aggregation on the ordered quantity. The result is an entity-centric index that shows the number of sold items in every product category in the last year.
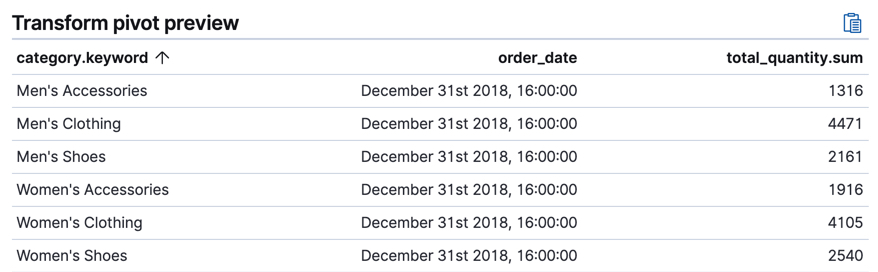
The transform leaves your source index intact. It creates a new index that is dedicated to the transformed data.