画像の類似検索の5つの技術要素


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
このブログ投稿シリーズの最初の部分では、画像の類似検索の概要を説明し、複雑さを低減し、実装を容易にすることができる概要レベルのアーキテクチャを確認しました。このブログでは、画像の類似検索アプリケーションの実装に必要な、各コンポーネントの基になる概念と技術的な考慮事項について説明します。主なトピックは次のとおりです。
- 埋め込みモデル:ベクトル検索を適用するために必要なデータの数値表現を生成する機械学習モデル
- 推論エンドポイント:Elasticで埋め込みモデルをデータに適用するためのAPI
- ベクトル検索:類似検索が最近傍検索と連動する仕組み
- 画像埋め込みの生成:数値表現の生成を大規模なデータセットにスケール
- アプリケーションロジック:インタラクティブなフロントエンドがバックエンドでベクトル検索エンジンと通信する方法
これらの5つの要素を深部まで探り、どのようにしてElasticでベクトル検索を適用し、より直感的な検索エクスペリエンスを実装できるのかという青写真を示します。
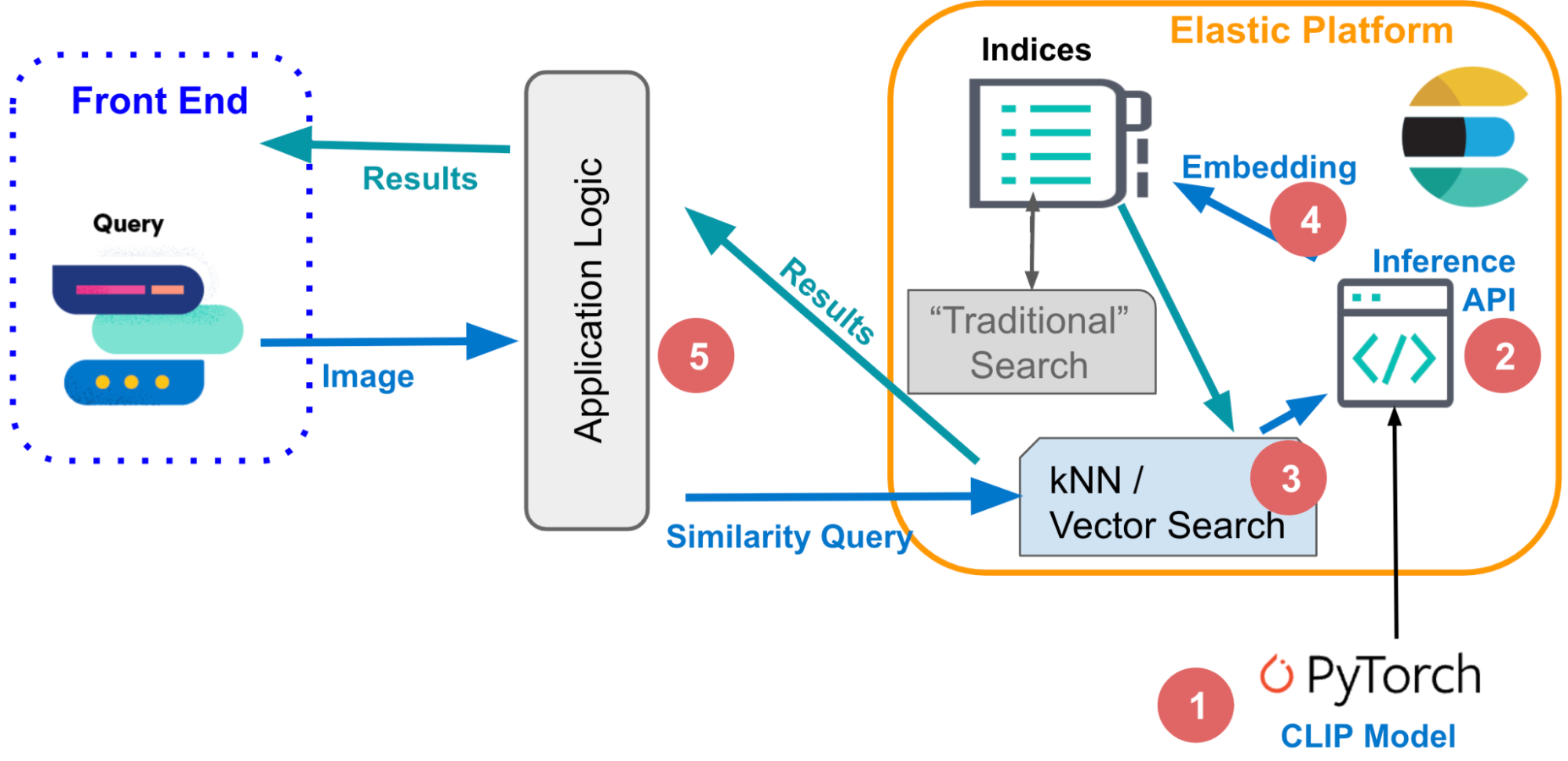
1.埋め込みモデル
類似検索を自然言語または画像データに応用するには、データを数値に変換する機械学習モデルが必要です。これは、ベクトル埋め込みとも呼ばれます。この例では次のような処理が行われます。
- NLP「変換器」モデルが自然言語をベクトルに変換します。
- OpenAI CLIP(Contrastive Language-Image Pre-training)モデルが画像をベクトル化します。
変換器モデルは機械学習モデルで、言語翻訳、テキスト分類、固有表現認識などのさまざまな方法で自然言語データを処理するように学習されています。これらのモデルは、人間言語のパターンと構造を学習するために、非常に大規模な注釈付きテキストデータのデータセットで学習されています。
画像の類似性アプリケーションが、特定のテキストの自然言語説明と一致する画像を検出します。このような種類の類似検索を実装するには、テキストと画像の両方を学習し、テキストクエリをベクトルに変換できるモデルが必要です。そして、そのモデルを使用して、類似した画像を検索できます。
ElasticsearchでNLPモデルをアップロードして使用する方法の詳細 >>
CLIPはOpenAIによって開発された大規模な言語モデルであり、テキストと画像の両方を処理できます。このモデルは、入力として少しテキストを渡すと、画像のテキスト表現を予測するように学習されています。これには、画像の視覚表現とテキスト表現を一致させ、モデルが正確な予測を行えるようにするための学習が関係しています。
CLIPの別の重要な側面は、CLIPは「ゼロショット」モデルであり、具体的に学習されていないタスクを実行できるということです。たとえば、学習中に見たことがない言語同士を翻訳したり、見たことがないカテゴリに画像を分類したりできます。このため、CLIPは非常に柔軟で多目的に使用できるモデルです。
画像のベクトル化では、CLIPモデルを使用します。そして、次に説明するように、Elasticの推論エンドポイントを利用して、大規模な画像のセットに対して推論を実行します(以下のセクション3)。

AI時代の検索ツールキット
Elasticsearch Relevance Engine(ESRE)は、AIを組み込んだ検索アプリを作るのに必要なツールを提供します。
2.推論エンドポイント
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3.ベクトル(類似性)検索
ベクトル埋め込みでクエリとドキュメントの両方にインデックスを作成した後は、類似したドキュメントは埋め込み空間のクエリの最近傍です。一般的なアルゴリズムの1つは、k近傍法(kNN)であり、クエリベクトルのk最近傍ベクトルを検索します。ただし、大規模なデータセットでは、通常は、画像検索アプリケーションで処理されます。kNNでは必要な演算リソースが非常に大きいため、実行時間が非常に長くなる可能性があります。解決策として、近似近傍法(ANN)探索がありますが、大規模に高次元埋め込み空間で効率的に実行できる代わりに、完璧な正解率という点でトレードオフが生じます。
Elasticでは、_search検索エンドポイントは正確近傍法と近似近傍法の両方の検索をサポートします。kNN検索では次のコードを使用します。your-image-indexのすべての画像の埋め込みがimage_embeddingフィールドで使用可能であることを前提としています。次のセクションでは、埋め込みを作成する方法について検討します。
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}ElasticでのkNNの詳細については、ドキュメント(https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html)を参照してください。
4.画像埋め込みの生成
前述の画像埋め込みは、画像の類似検索で高パフォーマンスを実現するために非常に重要です。画像埋め込みは、画像埋め込み用の別のインデックスに格納されます。これは上記のコードでyou-image-indexとして参照されます。インデックスは、画像ごとのドキュメント、コンテキストのフィールドと画像の密ベクトル(画像埋め込み)解釈から構成されます。画像埋め込みは低次元空間の画像を表します。類似した画像はこの空間の近傍点にマッピングされます。未加工の画像は、解像度によっては、数MBのサイズになる場合があります。
このような埋め込みがどのように生成されるのかという具体的な詳細は異なる場合があります。一般的に、この処理では、画像から特徴量を抽出してから、数学関数を使用して低次元空間にその特徴量をマッピングします。通常、この関数は大きい画像データセットで学習されており、低次元空間で特徴量を表すための最適な方法を学習しています。埋め込みの生成は1回かぎりのタスクです。
このブログでは、CLIPモデルを使用して埋め込みを生成します。CLIPモデルはOpenAIによって配布されており、画像埋め込みのちょうど良い出発点になります。分類したい画像のタイプがCLIPモデルを学習するために使用される公開データでどのように適切に表現されているかどうかによっては、特殊なユースケース用にカスタム埋め込みモデルを学習し、必要なパフォーマンスを実現しなければならない場合があります。
Elasticの埋め込み生成はインジェスト時に実行される必要があります。このため、検索の外部プロセスで、次のステップに従って行われます。
- CLIPモデルを読み込みます。
- すべての画像で次のステップが実行されます。
- 画像を読み込みます。
- モデルを使用して画像を評価します。
- 生成された埋め込みをドキュメントに保存します。
- ドキュメントをデータストア/Elasticsearchに保存します。
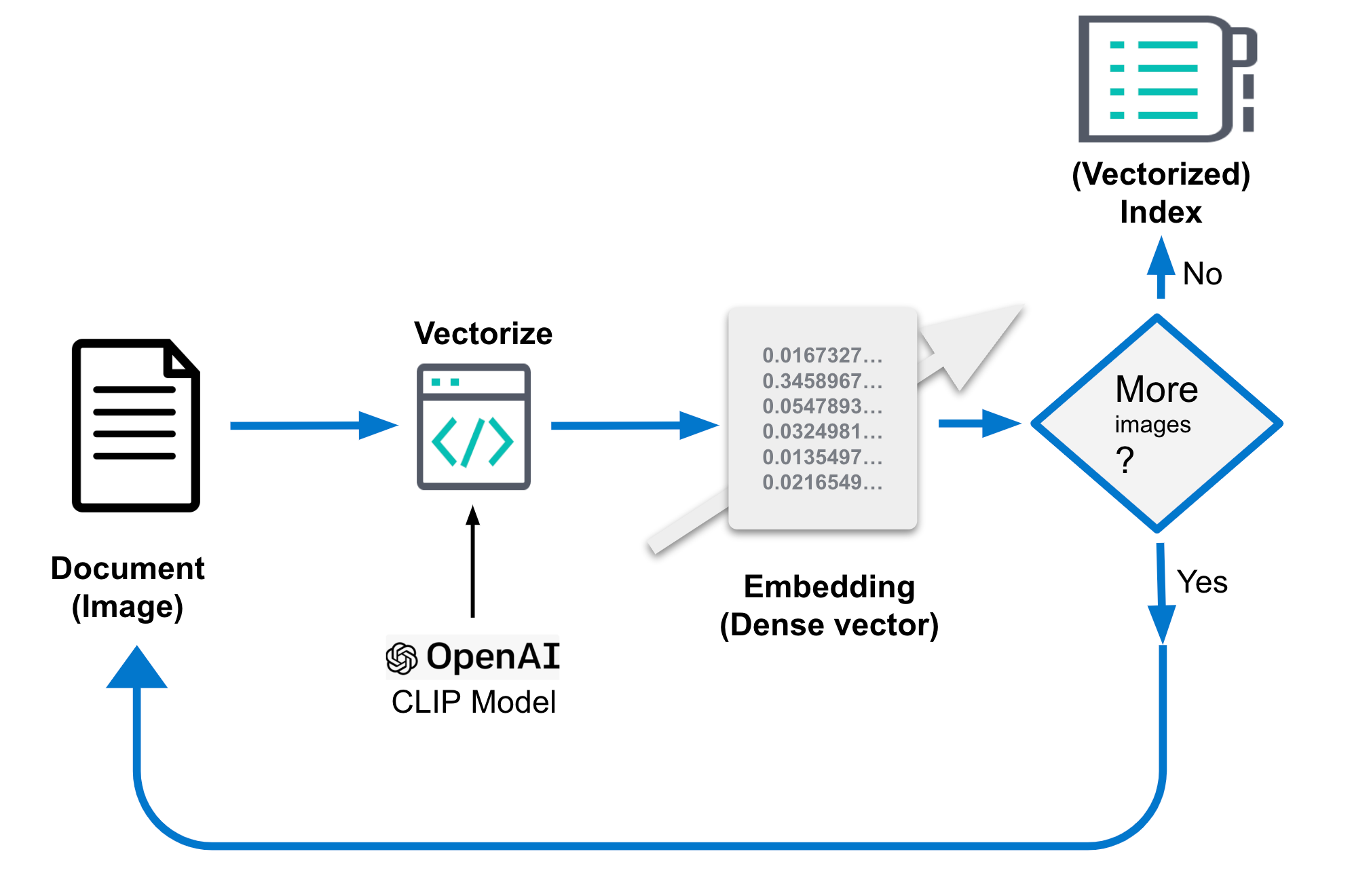
疑似コードには、これらのステップがさらに具体的に記述されています。詳細なコードはサンプルリポジトリから入手できます。
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...あるいは、次の図の例を参照してください。
処理後のドキュメントは次のようになります。重要な部分は、密ベクトル表現が格納されるフィールド「image_embedding」です。
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5.アプリケーションロジック
このような基本の要素に基づき、最後にすべての部分を結合して、ロジックを作成し、インタラクティブな画像の類似検索を実装できます。まずは、特定の説明と一致する画像をインタラクティブに取得したいときに、どのような処理が実行される必要があるのかという概念的なことから始めます。
テキストクエリでは、「rose」などの1単語のようにシンプルな語句を入力したり、「a mountain covered in snow」などの長い説明を入力したりできます。 あるいは、画像を入力し、持っている画像と類似している画像を検索できます。
別の様式を使用してクエリを作成している場合でも、基になるベクトル検索では、いずれも同じステップシーケンスを使用して実行されます。つまり、埋め込みによって(「密」ベクトル)と表現されるドキュメントに対してクエリ(kNN)が使用されます。前のセクションでは、大きい画像データセットで必要な、非常に高速でスケーラブルなベクトル検索をElasticsearchで実行できるメカニズムについて説明しました。ElasticでkNN検索をチューニングして効率化するための詳細な方法については、このドキュメントを参照してください。
- では、どのように前述のロジックを実装できるのでしょうか。次のフロー図では、情報がどのように流れるのかがわかります。ユーザーがテキストまたは画像として発行したクエリは、埋め込みモデルによってベクトル化されます。このモデルは入力のタイプによって異なり、テキスト説明の場合はNLPモデル、画像の場合はCLIPモデルになります。
- いずれのモデルも入力クエリを数値表現に変換し、Elasticsearchで結果を密ベクトル型に格納します([数値, 数値, 数値...])。
- このベクトル表現がkNN検索で使用され、類似ベクトル(画像)を探索します。そして、類似ベクトルが結果として返されます。
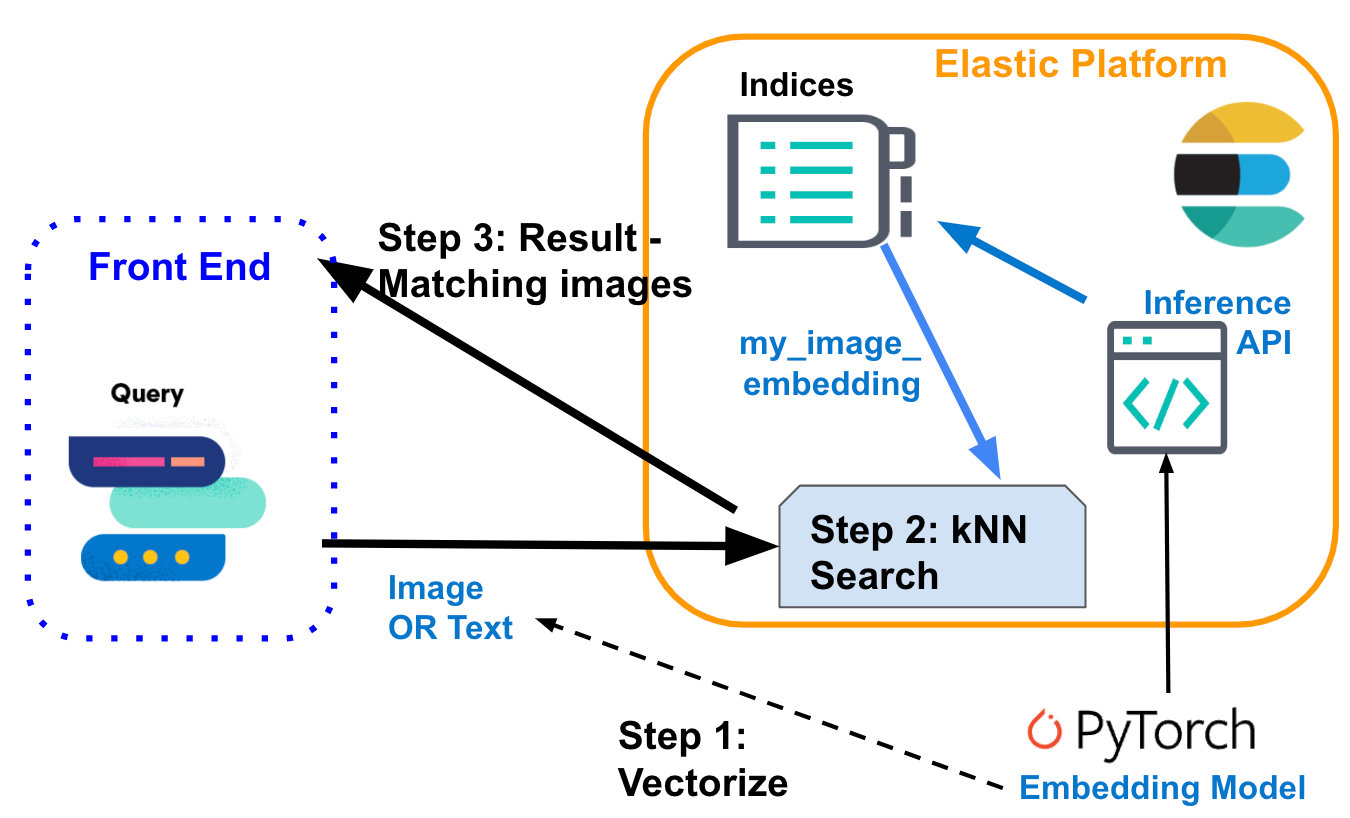
推論:ユーザーのクエリをベクトル化する
バックグラウンドのアプリケーションはElasticsearchの推論APIにリクエストを送信します。テキスト入力では次のようになります。
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}画像では、次の簡素化されたコードを使用して、CLIPモデルで1つの画像を処理できます。これは前もってElastic機械学習ノードに読み込んでおく必要があります。
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)次のように、512列のFloat32値の配列が返されます。
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}検索:類似画像
いずれのタイプの入力でも検索は同じように実行されます。kNN検索定義を含むクエリを画像埋め込みmy-image-embeddingsが格納されたインデックスに対して送信します。前のクエリ("query_vector": [ ... ])から密ベクトルを配置し、検索を実行します。
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}Elasticsearchからの応答では、kNN検索クエリに基づいた最も一致率が高い結果が返され、その結果がドキュメントとしてElasticに格納されます。
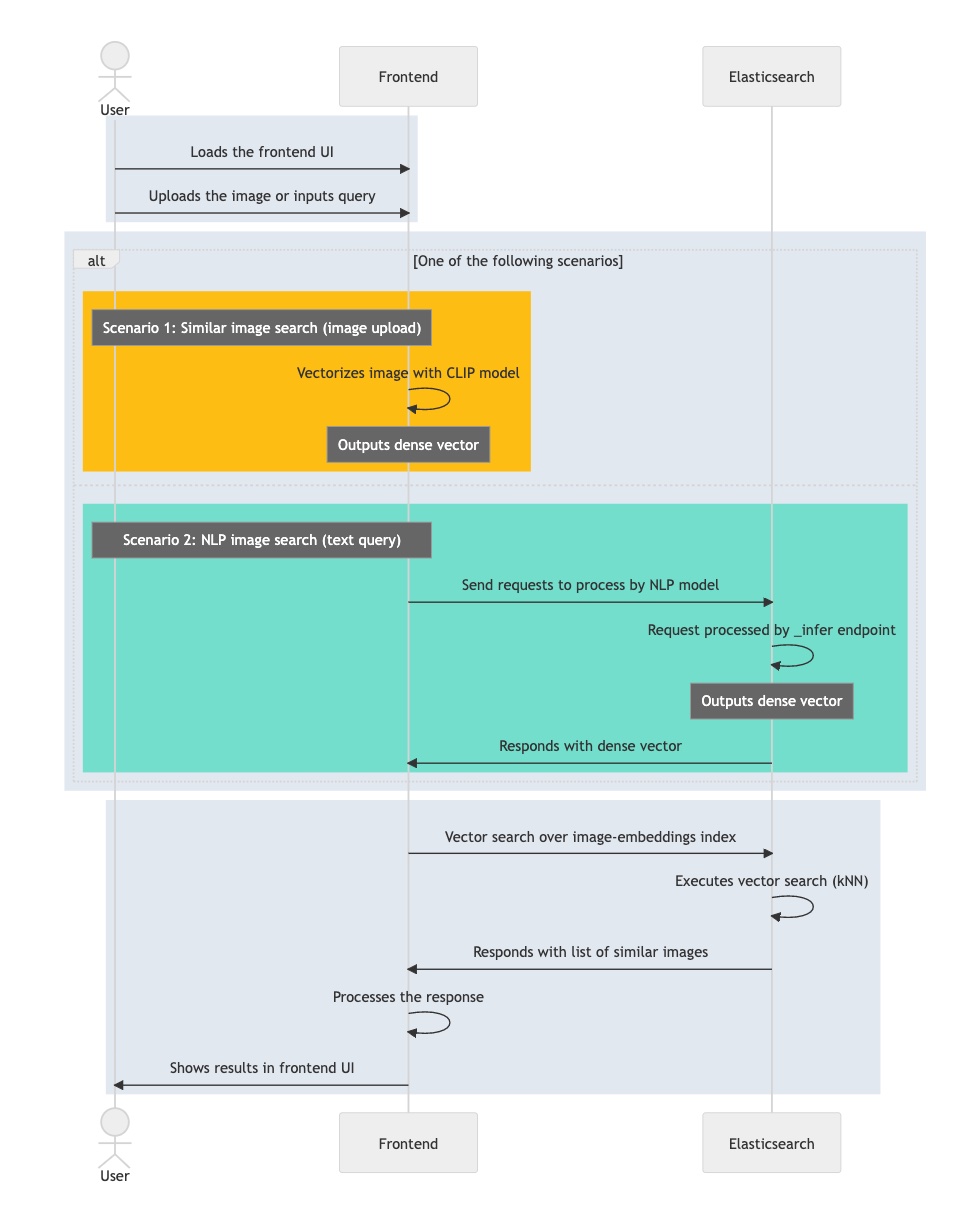
次のフロー図は、ユーザークエリの処理中にインタラクティブなアプリケーションが遷移するステップの要約です。
- インタラクティブなアプリケーション(フロントエンド)を読み込みます。
- ユーザーが関心のある画像を選択します。
- アプリケーションで、CLIPモデルを適用して画像をベクトル化し、結果の埋め込みを密ベクトルとして格納します。
- アプリケーションはElasticsearchでkNNクエリを開始します。kNNは埋め込みを入力し、最近傍を返します。
- アプリケーションで応答が処理され、1つ(または複数)の一致する画像が表示されます。
インタラクティブな画像の類似検索を実装するために必要な主な要素と情報フローが理解できたところで、このシリーズの最後の部分に入り、どのように検索を実行するのかということを説明します。アプリケーション環境を設定し、NLPモデルをインポートして、画像埋め込み生成する方法については、段階的なガイドが用意されています。そして、自然言語を使用して画像を検索できます。キーワードは不要です。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷

