Logstashの実践的な説明
Elastic StackはElasticsearchにデータを取り込む操作を可能な限り簡単にしています。Filebeatはファイルをtailするためのすばらしいツールで、最小限の設定で共通のログフォーマットを取り込むことができるようになる モジュールのセットを提供しています。取り込むデータがこれらのモジュールで網羅されていない場合、 LogstashとElasticsearchのIngestノードが柔軟でパワフルな方法を提供し、テキストベースのデータのほとんどのタイプを解析し、処理できるようにします。
このブログでは、Logstashの説明を簡単に行い、サンプルとしてSquidキャッシュアクセスログを解析します。また、これらをElasticsearchに取り込むための設定を開発する際にLogstashを操作する方法を示します。
Logstashの簡単な説明
Logstashはプラグインベースのデータ収集・処理エンジンです。幅広い範囲のプラグインがあり、多くのさまざまなアーキテクチャーでデータの収集、処理、転送を行えるように簡単に設定できます。
処理は1つ以上のパイプラインに整理されます。各パイプラインで、1つ以上の入力プラグインがデータを受信や収集し、その時点で内部キューに登録します。デフォルトではこれは小さく、メモリに保持されますが、大きくして、ディスクに保持し、信頼性とレジリエンシーを向上できるように設定できます。
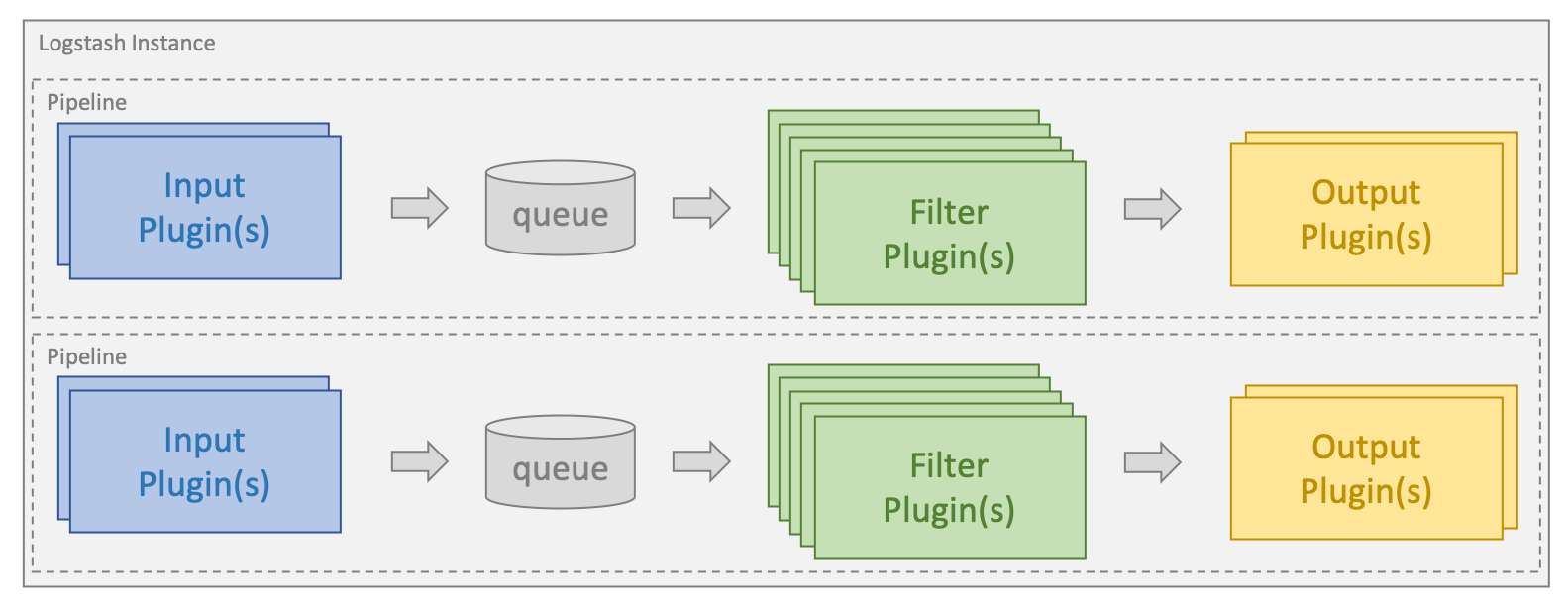
処理スレッドは、マイクロバッチでキューからのデータを読み取り、これらを任意の設定済みのフィルタープラグインにより順番に処理します。Logstashにはデフォルトで多数のプラグインがあり、これらのプラグインは処理の特定タイプをターゲットとしています。これが、データを解析し、処理し、リッチ化する方法です。
データがいったん処理されると、処理スレッドは適切な出力プラグインにデータを送信します。これらのプラグインは、データをフォーマットし、Elasticsearchなど先へ送信する責任を担います。
入力と出力のプラグインにはコーデックプラグインも設定できます。これにより、内部キューに配置される前、あるいは出力プラグインに送信される前に、解析および/またはフォーマットを行えるようになります。
LogstashとElasticsearchのインストール
このブログにある例を実行するには、LogstashとElasticsearchをまずインストールする必要があります。お客様のオペレーティングシステムでこれを実行する方法に関する手順のリンクがありますのでクリックしてください。Elastic Stackバージョン6.2.4を使用します。
パイプラインの指定
Logstashパイプラインは1つ以上の設定ファイルに基づいて作成されます。始める前に、利用できるさまざまなオプションについて簡単に説明します。このセクションで説明するディレクトリーはインストールモードとオペレーティングシステムにより異なることがあり、ドキュメントで定義されています。
単一の設定ファイルを使用する単一のパイプライン
このブログを通じて使用するLogstashを最も簡単な方法で起動する方法は、-fコマンドラインパラメーターで指定する単一の設定ファイルで単一のパイプラインをLogstashに読み込ませる方法です。
複数の設定ファイルを使用する単一のパイプライン
Logstashは、指定ディレクトリーの全ファイルを設定ファイルとして使用する設定にすることもできます。これは、logstash.ymlファイルにより設定することも、-fコマンドラインパラメーターを使用してコマンドラインでディレクトリーパスを受け渡すことによって設定することもできます。Logstashをサービスとしてインストールする場合は、これがデフォルトです。
ディレクトリーが指定されると、ディレクトリーの全ファイルが辞書順で結合され、単一の設定ファイルとして解析されます。したがって、条件文を使用してフローをコントロールしない限り、すべての入力のデータがすべてのフィルターに処理され、すべての出力に送信されます。
複数のパイプラインを使用
Logstash内で複数のパイプラインを使用するには、Logstashにあるpipelines.ymlファイルを編集する必要があります。これは設定ディレクトリーにあり、Logstashインスタンスがサポートするすべてのパイプラインの設定ファイルと設定パラメーターが含まれています。
複数のパイプラインを使用すると、さまざまな論理フローを分けることができ、使用される条件文の複雑性と量を激減できます。これにより、設定の調整や運用が簡単になります。同時にパイプラインを通じて流れるデータが均一になるため、出力プラグインを効率よく使用でき、パフォーマンスも劇的に向上します。
最初の設定を作成
Logstashの設定は少なくとも1つの入力プラグインと1つの出力プラグインを含む必要があります。フィルターはオプションです。シンプルな設定ファイルがどのようなものであるかについて、ファイルからテストデータのセットを読み込み、これを構造化された形でコンソールに出力するものを手始めに提示します。設定のイテレーションと構築をすばやく行うため、これは設定を開発しているときに非常に役立つ設定です。このブログを通じて使用する、設定ファイルをtest.confと呼び、テストデータのファイルと共に“/home/logstash”ディレクトリーに保存するものとします。
input {
file {
path => ["/home/logstash/testdata.log"]
sincedb_path => "/dev/null"
start_position => "beginning"
}
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
これはLogstashの各設定の一部である3つのトップレベルのグルーピングです。入力、フィルター、出力です。入力セクションでは、ファイル入力プラグインを指定し、パスディレクティブでテストデータファイルのパスを指定しています。start_positionディレクティブを“beginning”に設定し、新しいファイルの検出時に常にファイルを読み込むようにプラグインに指示します。
処理されている各入力ファイル内にあるデータの記録を残すために、Logstashファイル入力プラグインはsincedbというファイルを使用して、現在の位置を記録します。設定を開発している間は、ファイルは繰り返し読み込むため、sincedbファイルの使用を無効にする必要があります。これを行うには、sincedb_pathディレクティブをLinuxベースシステムで“/dev/null”に設定します。Windowsでは、これは“nul”として設定されます。
Logstashファイル入力プラグインは設定を開発するのに適したすばらしい方法ですが、ログ収集やホストサーバーからのシップにはFilebeatが推奨製品です。FilebeatはログをLogstashに出力でき、LogstashはこれらのログをBeats入力で受信し、処理できます。このブログで説明されている解析ロジックはまだどちらのシナリオでも適用できますが、Filebeatのほうがパフォーマンスに対して最適化されていて、リソース使用率が低いため、エージェントとして実行するのに理想的です。
stdout出力プラグインがコンソールにデータを書き込み、rubydebugコーデックが構造を表示するのを支援します。これにより、設定開発中のデバッグが簡素化されます。
Logstashの起動
Logstashと設定ファイルが機能することを検証するために、“testdata.log”というファイルを“/home/logstash”ディレクトリーで作成します。これには“Hello Logstash!”という文字列が含まれ、別の行がこれに続きます。
Logstashのバイナリーがパスにある場合、次のコマンドを使用してLogstashを起動できます。
logstash -r -f "/home/logstash/test.conf"
前述した-fコマンドラインパラメーターに加えて、-rフラグも使用しました。これにより、設定が変更される度にLogstashは設定を自動的にリロードします。これは開発中に特に非常に役立ちます。sincedbファイルを無効にしたため、設定がリロードされる度に入力ファイルが再度読み込まれ、開発を続行しながら設定をすばやくテストできます。
Logstashからコンソールへの出力には、起動に関連するログがいくつか表示されます。この後、ファイルが処理され、次のようなスクリプトが表示されます。
{
"message" => "Hello Logstash!",
"@version" => "1",
"path" => "/home/logstash/testdata.log",
"@timestamp" => 2018-04-24T12:40:09.105Z,
"host" => "localhost"
}
これはLogstashが処理したイベントです。データがメッセージフィールドに保存され、処理されたタイムスタンプやどこで発生したイベントかといったメタデータをLogstashがいくつか追加しているのがわかります。
これはすべて非常に良好で、メカニクスが機能していることを証明しています。この時点で、さらにリアリスティックなテストデータを追加して、これがどのように解析されるかを表示します。
ログの解析方法
ログがJSON形式である場合のjsonフィルターなど、データを解析するのに使用できる完璧なフィルターがあることがあります。しかし、多くの場合は、テキストフォーマットのさまざまなタイプでログを解析する必要があります。このブログで使用する例は、Squidキャッシュアクセスログの数行で、次のように表示されます。
1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 - 1524206424.145 106 207.96.0.0 TCP_HIT/200 68247 GET http://elastic.co/guide/en/logstash/current/images/logstash.gif - NONE/- image/gif
各行にはSquidキャッシュに対する1つのリクエストの情報が含まれていて、解析する必要のある多数の明確なフィールドにブレークダウンすることができます。

テキストログを解析する際、特に2つのフィルターが一般的に使用されます。区切り文字でログをパースするdissectと、正規表現マッチングに基づいて動作するgrokです。
データの構造がよく定義されているとき、dissectフィルターは非常によく機能し、非常に高速かつ効率よく動作します。特に、正規表現になじみのないユーザーにとっては、簡単に開始できることがよくあります。
Grokは一般的により強力で、より幅広い範囲のデータを処理できます。しかし、正規表現マッチングはより多くのリソースを使用し、適切に最適化されていないときに特にスピードが遅いです。
解析に進む前に、testdata.logファイルにこの2行を入力します。各行の後に改行されていることを確認します。
dissectでログを解析
dissectフィルターで操作を行う場合、フィールドの順番を正確に指定し、これらのフィールドの間に区切り文字を指定します。フィルターがデータ上でシングルパスを実行し、パターンに沿って区切り文字をマッチングします。これと同時に、区切り文字の間のデータが指定のフィールドに割り当てられます。フィルターは抽出中のデータのフォーマットを検証しません。
dissectフィルターを使用してデータを解析する際に使用されるセパレーターは、以下でピンク色にハイライトされています。

最初のフィールドはタイムスタンプを含んでいて、1つ以上のスペースがこれに続きます。これは、次の期間フィールドの長さにより異なります。タイムスタンプフィールドを%{timestamp}の形式で指定できますが、スペースの変数の数をセパレーターとして受け入れるには、->の接尾辞をフィールドに追加する必要があります。ログエントリーにある他のすべてのセパレーターは、一文字でのみ構成されます。したがって、パターンの構築を開始し、次のようなフィルターセクションを得ることができます。
{
"@version" => "1",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:42:23.003Z,
"path" => "/home/logstash/testdata.log",
"host" => "localhost",
"duration" => "19395",
"timestamp" => "1524206424.034",
"rest" => "TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"client_ip" => "207.96.0.0"
}
この時点で、パターンを段階を追って構築し続けることができます。すべてのフィールドの解析に成功したら、メッセージフィールドを削除し、同じデータを2回保持することがないようにします。これは、remove_fieldディレクティブを使用して行えます。このディレクティブは解析が正常に行われた場合のみ実行され、次のようなフィルターブロックを生成します。
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
}
}
サンプルデータに対して実行すると、最初のレコードは次のようになります。
{
"user" => "-",
"content_type" => "-",
"host" => "localhost",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:43:07.406Z,
"duration" => "19395",
"request_method" => "GET",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"timestamp" => "1524206424.034",
"status_code" => "304",
"server" => "10.0.5.120",
"@version" => "1",
"client_address" => "207.96.0.0",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT"
}
ドキュメントにはいくつかの良い例があり、このブログはフィルターの設計と目的について適切な説明を提供しています。
かなり簡単だったと思います。後ほどこれをさらに処理しますが、まずgrokで同じことをどのようにできるかを確認してみましょう。
grokの最適な操作方法
Grokは正規表現パターンを使用して、フィールドと区切り文字の両方をマッチします。以下の図は、キャプチャーするフィールドを青で表示し、区切り文字を赤で表示します。

Grokは、先頭の設定済みのパターンのマッチングを開始し、イベント全体がマッピングされるか、マッチを検出できないことが判別するまで続行します。使用されるパターンのタイプにより、データの部分を複数回処理するためにgrokが必要となることがあります。
Grokには幅広い範囲の既成パターンがあります。一般的なものは ここで確認できますが、このリポジトリーにはまた、共通データタイプに対しての多数の特化されたパターンも用意されています。実際にはSquidアクセスログの解析用のものがありますが、単純にこれを直接使用するのではなく、このチュートリアルではゼロからこれを構築する方法を説明します。しかしながら、カスタムなパターンの作成に着手する前に、適切なパターンがすでに存在していないかこのリポジトリーを確認するのは有益であることが示されています。
grokの設定を作成する際、一般的に使用される標準パターンが多数あります。
- WORD-単一のワードにマッチするパターン
- NUMBER-正または負の整数あるいは浮動小数点数にマッチするパターン。
- POSINT-正の整数にマッチするパターン
- IP-IPv4またはIPv6のIPアドレスにマッチするパターン
- NOTSPACE-スペース以外のものすべてにマッチするパターン
- SPACE-連続しているスペースの任意の数にマッチするパターン
- DATA-制限された量のあらゆる種類のデータにマッチ(最短マッチ)するパターン
- GREEDYDATA-すべての残りのデータにマッチするパターン
grokフィルター設定の構築時に使用するパターンはこのようなものです。grok設定を作成する方法は、通常左から開始し、徐々にパターンを構築します。 GREEDYDATAパターンを使用して残りのデータをキャプチャーするのです。次のパターンとフィルターのブロックを使用して開始できます。
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{GREEDYDATA:rest}"
}
}
}
このパターンでは、grokが文字列の初めの数を確認し、これをtimestampというフィールドに保存します。この後、restというフィールドにデータの残りを保存する前に、スペースの数のマッチングを行います。これのために分割フィルターブロックをスイッチすると、最初のレコードが次のように表示されます。
{
"timestamp" => "1524206424.034",
"rest" => "19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"path" => "/home/logstash/testdata.log",
"message" => "1524206424.034 19395 207.96.0.0 TCP_MISS/304 15363 GET http://elastic.co/android-chrome-192x192.gif - DIRECT/10.0.5.120 -",
"@timestamp" => 2018-04-24T12:45:11.026Z,
"@version" => "1",
"host" => "localhost"
}
Grok Debuggerの使用
このようにフルパターンを開発できますが、grokパターン作成を簡素化できるKibanaのツールがあります。Grok Debuggerです。以下のビデオで、これを使用して、このブログで使用されているサンプルログのパターンを構築する方法を説明します。
設定が構築され、解析が正常に行われると、メッセージフィールドをドロップします。これにより、フィルターブロックが次のようになります。
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp}%{SPACE}%{NUMBER:duration}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code}\s%{NUMBER:bytes}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
これは既成パターンに似ていますが、同一ではありません。サンプルデータに対して実行すると、最初の記録が分割フィルターを使用したときと同じ方法で解析されます。
{
"request_method" => "GET",
"cache_result" => "TCP_MISS",
"@timestamp" => 2018-04-24T12:48:15.123Z,
"timestamp" => "1524206424.034",
"user" => "-",
"bytes" => "15363",
"path" => "/home/logstash/testdata.log",
"hierarchy_code" => "DIRECT",
"duration" => "19395",
"client_address" => "207.96.0.0",
"@version" => "1",
"status_code" => "304",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"content_type" => "-",
"host" => "localhost",
"server" => "10.0.5.120"
}
パフォーマンスのためにgrokを調整
Grokはデータ解析のための非常にパワフルで柔軟なツールですが、パターンを効率よく使用しないと期待通りのパフォーマンスを確保できません。したがって、grokを本格的に使用する前に、このgrokのパフォーマンスの調整に関するブログに目を通すことを推奨します。
フィールドが適切なタイプであることを確認
上記の例で確認したように、すべてのフィールドが文字列フィールドとして解析されています。これをElasticsearchにJSONドキュメントの形式で送信する前に、bytes、duration、status_codeのフィールドを整数に変更し、timestampを浮動小数点数に変更します。
これを実行する1つの方法はmutate filter とその convertオプションを使用することです。
mutate {
convert => {
"bytes" => "integer"
"duration" => "integer"
"status_code" => "integer"
"timestamp" => "float"
}
}
これを直接分割フィルターとgrokフィルターで行うこともできます。分割フィルターでは、convert_datatypeディレクティブを通じて行います。
filter {
dissect {
mapping => {
"message" => "%{timestamp->} %{duration} %{client_address} %{cache_result}/%{status_code} %{bytes} %{request_method} %{url} %{user} %{hierarchy_code}/%{server} %{content_type}"
}
remove_field => ["message"]
convert_datatype => {
"bytes" => "int"
"duration" => "int"
"status_code" => "int"
"timestamp" => "float"
}
}
}
grokを使用する場合は、パターンのフィールド名の後ろに直接タイプを指定できます。
filter {
grok {
match => {
"message" => "%{NUMBER:timestamp:float}%{SPACE}%{NUMBER:duration:int}\s%{IP:client_address}\s%{WORD:cache_result}/%{POSINT:status_code:int}\s%{NUMBER:bytes:int}\s%{WORD:request_method}\s%{NOTSPACE:url}\s%{NOTSPACE:user}\s%{WORD:hierarchy_code}/%{NOTSPACE:server}\s%{NOTSPACE:content_type}"
}
remove_field => ["message"]
}
}
日付フィルターの使用
ログから抽出されるタイムスタンプはエポック以降の秒単位とミリ秒単位です。これを抽出して、@timestampフィールドに保存できる標準的なタイムスタンプ形式に変換します。このために、日付フィルタープラグインを、保持しているデータとマッチするUNIXのパターンと合わせて使用します。
date {
match => [ "timestamp", "UNIX" ]
}
Elasticsearchに保存されているすべての標準的なタイムスタンプはUTC(協定世界時)の時間帯です。抽出されるタイムスタンプにもこれが適用されているため、時間帯を指定する必要はありません。別の形式のタイムスタンプがある場合は、事前に定義されているUNIXのパターンの代わりにこの形式を指定できます。
これとタイプの変換を設定に追加すると、最初のイベントが次のように表示されます。
{
"duration" => 19395,
"host" => "localhost",
"@timestamp" => 2018-04-20T06:40:24.034Z,
"bytes" => 15363,
"user" => "-",
"path" => "/home/logstash/testdata.log",
"content_type" => "-",
"@version" => "1",
"url" => "http://elastic.co/android-chrome-192x192.gif",
"server" => "10.0.5.120",
"client_address" => "207.96.0.0",
"timestamp" => 1524206424.034,
"status_code" => 304,
"cache_result" => "TCP_MISS",
"request_method" => "GET",
"hierarchy_code" => "DIRECT"
}
求めている形式になり、データをElasticsearchに送信し始める準備ができたようです。
Elasticsearchにデータを送信する方法
Elasticsearch出力プラグインを使用してデータを送信し始める前に、マッピングの役割について確認し、Logstashで変換できるタイプとこれらがどのように異なるかを確認する必要があります。
Elasticsearchには、文字列と数字のフィールドを自動的に検出する機能があり、マッピングの決定は新しいフィールドが初めて出てきたドキュメントに基づいて行われます。JSONのデータの形式により、適切なマッピングが行われることも、行われないこともあります。通常は浮動小数点数であるが一部の記録で`0`のフィールドがある場合などです。どのドキュメントが最初に処理されるかによりますが、これは浮動小数点数ではなく整数としてマッピングされることがあります。
Elasticsearchには、日付フィールドを自動的に検出する機能もあります。日付フィルターが標準的な形式のものを生成する限りこれは有効です。
geo_pointやipなど他のフィールドのタイプは、自動的に検出されず、インデックステンプレートで明示的に定義する必要があります。インデックステンプレートはAPIを通じてElasticsearchで直接管理できます。Logstashにより、適切なテンプレートがElasticsearch出力プラグインを通じてロードされていることを確認することもできます。
今回のデータに関しては、デフォルトマッピングでだいたいは満足できます。serverフィールドにはダッシュや有効なIPアドレスが含まれているため、これをIPフィールドとしてマッピングしません。手動のマッピングを必要とするフィールドの1つに、タイプipを指定するclient_addressフィールドがあります。アグリゲーションを行う文字列フィールドもいくつかありますが、フリーテキスト検索を実行する必要はありません。これらを明示的にkeywordフィールドとしてマッピングします。これらのフィールドは、user、path、content_type、cache_result、request_method、server、hierarchy_codeです。
データを接頭辞squid-で始まるタイムベースのインデックスで保存するつもりです。この例では、Logstashと同じホストで、Elasticsearchがデフォルトの設定で実行されているものとします。
次に、squid_mapping.jsonというファイルに保存される次のテンプレートを作成できます。
{
"index_patterns": ["squid-*"],
"mappings": {
"doc": {
"properties": {
"client_address": { "type": "ip" },
"user": { "type": "keyword" },
"path": { "type": "keyword" },
"content_type": { "type": "keyword" },
"cache_result": { "type": "keyword" },
"request_method": { "type": "keyword" },
"server": { "type": "keyword" },
"hierarchy_code": { "type": "keyword" }
}
}
}
}
このテンプレートは、インデックスパターンsquid-*にマッチするすべてのインデックスに適用するように設定されます。ドキュメントタイプdoc Elasticsearch 6.xのデフォルト)では、これはclient_addressフィールドに対してマッピングを指定しipに変換し、他の指定フィールドに対してマッピングを指定しキーワードをマッピングします。
これを直接Elasticsearchにアップロードできますが、Elasticsearch出力プラグインを設定して、これを処理する方法を説明します。Logstash設定の出力セクションで、次のようなブロックを追加します。
elasticsearch {
hosts => ["localhost:9200"]
index => "squid-%{+YYYY.MM.dd}"
manage_template => true
template => "/home/logstash/squid_mapping.json"
template_name => "squid_template"
}
この時点でこの設定を実行し、サンプルドキュメントをElasticsearchでインデックスします。マッピング取得APIを通じてインデックスのマッピングの結果を取得すると、次のようなマッピングが表示されます。
{
"squid-2018.04.20" : {
"mappings" : {
"doc" : {
"properties" : {
"@timestamp" : {
"type" : "date"
},
"@version" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"bytes" : {
"type" : "long"
},
"cache_result" : {
"type" : "keyword"
},
"client_address" : {
"type" : "ip"
},
"content_type" : {
"type" : "keyword"
},
"duration" : {
"type" : "long"
},
"hierarchy_code" : {
"type" : "keyword"
},
"host" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"path" : {
"type" : "keyword"
},
"request_method" : {
"type" : "keyword"
},
"server" : {
"type" : "keyword"
},
"status_code" : {
"type" : "long"
},
"timestamp" : {
"type" : "float"
},
"url" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"user" : {
"type" : "keyword"
}
}
}
}
}
}
テンプレートが適用され、指定のフィールドが適切に指定されたことがわかります。このブログの主なフォーカスはLogstashであるため、マッピングがどのように機能するかについてはほんの少ししか説明していません。この重要なトピックについては、ドキュメントで詳細を確認してください。
まとめ
このブログでは、カスタムなサンプル設定を開発する際のLogstashの最適な操作方法について説明しました。この操作を通じてElasticsearchに正常に書き込まれることが保証されます。しかし、このブログではLogstashでできることのほんの少ししか紹介していません。このブログにリンクされているドキュメントや他のブログに目を通してください。また、公式の入門書、ならびに利用できる入力、出力、フィルターのプラグインを確認してください。利用できるものを理解するだけですぐに、Logstashはデータ処理の最高のツールとなります。
問題に直面したり、追加の質問がある場合、いつでも弊社のディスカッションフォーラムのLogstashカテゴリーにアクセスしてください。別のサンプルデータやLogstash設定を確認したい場合、https://github.com/elastic/examples/に別のサンプルがあります。
楽しく解析しましょう!!!