Elasticsearchのキャッシングに関する詳細:クエリスピードを高速化できるキャッシュ方法を1つずつ順に解説
キャッシュは、スピーディなデータ取得の王道です。Elasticsearchがさまざまなキャッシュをどのように使用して、データの取得を可能な限り高速化できるようにしているかについてご興味をお持ちなら、15分間だけ気を引き締めてこの記事をお読みください。このブログでは、Elasticsearchのさまざまなキャッシング機能についてスポットを当てます。それらの機能は、最初のデータアクセス後のデータの取得を高速化するのに役立ちます。Elasticsearchはさまざまなキャッシュのヘビーユーザーですが、この記事では次のものに焦点を当てます。
- ページキャッシュ(ファイルシステムキャッシュと呼ばれることもあります)
- シャードレベルリクエストのキャッシュ
- クエリキャッシュ
これらの各キャッシュが何を実行しているか、その仕組み、およびどのキャッシュがどのユースケースに最適かについて説明します。また、優れたキャッシングを行うために、キャッシングを制御できる場合と他のコンポーネントを信頼する必要がある場合についても見ていきます。
さらに、ページキャッシュがデータの有効期限をどのように処理するかについても触れます。絶対に遭遇したくないものの1つは、古いデータを返すキャッシュです。キャッシュはデータのライフサイクルにバインドされている必要があり、それぞれのキャッシュでそれがどのように機能するかを見ていきます。
この記事が自分に当てはまるかどうかが分からないと思っているかもしれませんが、自社でElasticsearchを実行していても、Elastic Cloudを使用していても、追加設定の必要なく、これらのキャッシュを活用することができます。それでは詳細の説明を始めましょう。
ページキャッシュ
この最初のキャッシュはオペレーティングシステムレベルに存在します。このセクションでは主にLinux環境についてお話ししますが、その他のオペレーティングシステムにも同様の機能があります。
ページキャッシュの基本的な考え方は、ディスクからデータを読み込んだ後、利用可能なメモリにそのデータを保存することです。そうすることで、次に読み込むときにはデータがメモリから返されるため、ディスクをシークしてデータを取得する必要がありません。そのすべてはアプリケーションに対して完全に透過的に実行されます。つまり、同じシステムコールが実行されますが、ディスクから読み込むのではなく、ページキャッシュを使用する機能をオペレーティングシステムが持っているのです。
下図を見てください。アプリケーションがディスクからデータを読み込むためのシステムコールを実行し、カーネル/オペレーティングシステムがディスクにアクセスして最初の読み込みを実行して、データをページキャッシュとしてメモリに入れます。そして2回目の読み込みは、カーネルによってオペレーティングシステムのメモリ内にリダイレクトされるため、大幅に高速化されます。
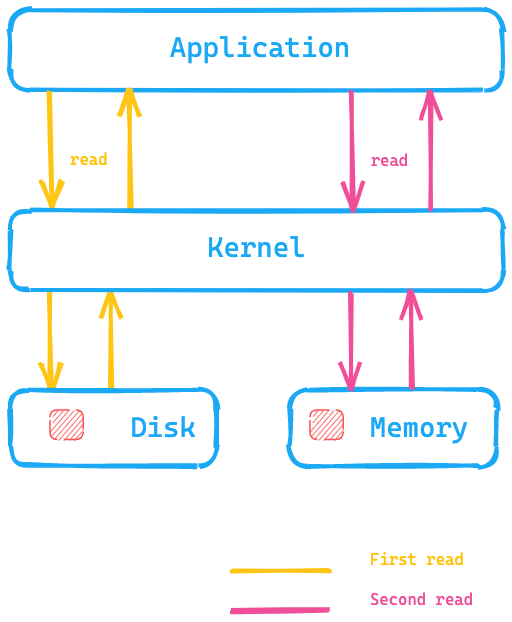
Elasticsearchにとって、これは何を意味するのでしょうか。ディスクのデータにアクセスするのではなく、ページキャッシュを使用することですばやくデータにアクセスできるということです。Elasticsearchのメモリに関する推奨事項では、一般的に、利用可能なメモリの半分以上を使用しないようにすることとしていますが、その理由の1つはこのためです。つまり、メモリの残りの半分はページキャッシュのために使用できるようにしたいからです。これはメモリが無駄にならないことも意味します。ページキャッシュに再利用されるからです。
では、データはどのようにしてキャッシュから期限切れになるのでしょうか。データ自体が変更されると、ページキャッシュはそのデータを古いデータとしてマークし、そのデータはページキャッシュから除去されます。ElasticsearchおよびLuceneではセグメントが書き込まれるのは一度のみであり、このメカニズムがデータの格納方法に非常に適しています。セグメントは、最初に書き込まれた後、読み取り専用となるため、データの変更としてはマージまたは新しいデータの追加が考えられます。その場合、新たなディスクアクセスが必要になります。または、メモリがいっぱいになることも考えられます。その場合、キャッシュはLRUキャッシュと同じ挙動となります(カーネルに関するドキュメントに記載されています)。
ページキャッシュのテスト
ページキャッシュの機能をチェックしたい場合は、hyperfineを使用することができます。hyperfineはCLIによるベンチマーキングツールです。ddを使用して、10 MBのサイズのファイルを作成してみましょう
dd if=/dev/urandom of=test1 bs=1M count=10
上記をmacOSで実行したい場合は、gddを使用します
brewでcoreutilsを必ずインストールします。
Linuxの場合 hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
OS Xの場合 hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User:1.4 ms, System:17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User:0.7 ms, System:2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
ページキャッシュをクリアせずに、同じcatコマンドを実行している私のローカルのmacOSインスタンスでは、約10倍高速です。ディスクアクセスがスキップされるからです。Elasticsearchデータには、この種のアクセスパターンが絶対に必要です。
さらに詳細
Luceneインデックスを読み込むためのクラスは、HybridDirectoryクラスです。Luceneインデックス内のファイルの拡張子に基づいて、メモリマッピングを使用するか、Java NIOを使用した通常のファイルアクセスを使用するかが決定されます。
注意が必要なのは、一部のアプリケーションが独自のアクセスパターンに着目して、独自の非常に特殊かつ最適化されたキャッシュを使用しているにもかかわらず、ページキャッシュがそれに反して機能することになる場合があることです。必要な場合は、ファイルを開く際にO_DIRECTを使用すると、どのアプリケーションでもページキャッシュがバイパスされます。これについては、この記事の最後に再度触れます。
キャッシュヒット率をチェックしたい場合は、perf-toolsの一部であるcachestatを使用できます。
最後に、Elasticsearchに関してもう1つ。インデックス設定で、データをページキャッシュに事前ロードするようにElasticsearchを構成することが可能です。これはエキスパート用の設定であるとお考えください。この設定で、ページキャッシュが常にスラッシングされないように気を付ける必要があります。
まとめ
ページキャッシュは、オペレーティングシステムのメインメモリに完全なインデックスデータ構造をロードすることにより、任意の検索をより高速に実行するのに役立ちます。それ以上の粒度はなく、データのアクセスパターンのみに基づいています。キャッシュの削除はオペレーティングシステムが実行します。
では、キャッシュの次のレベルに進みましょう。
シャードレベルリクエストのキャッシュ
このキャッシュは、アグリゲーションのみで構成される検索応答をキャッシュすることで、Kibanaの高速化に大いに役立ちます。このキャッシュで解決される問題を視覚化するために、いくつかのインデックスからフェッチされたデータでアグリゲーションの応答をオーバーレイしてみましょう。
オフィス内のKibanaダッシュボードは通常、いくつかのインデックスからのデータを表示し、 ユーザーは単に、たとえば過去7日間などのタイムスパンを指定します。ユーザーはどれくらい多くのインデックスまたはシャードがクエリされるかについては気にしていません。時間ベースのインデックスにデータストリームを使用している場合、 下記のように5つのインデックスをカバーするビジュアライゼーションになると思います。
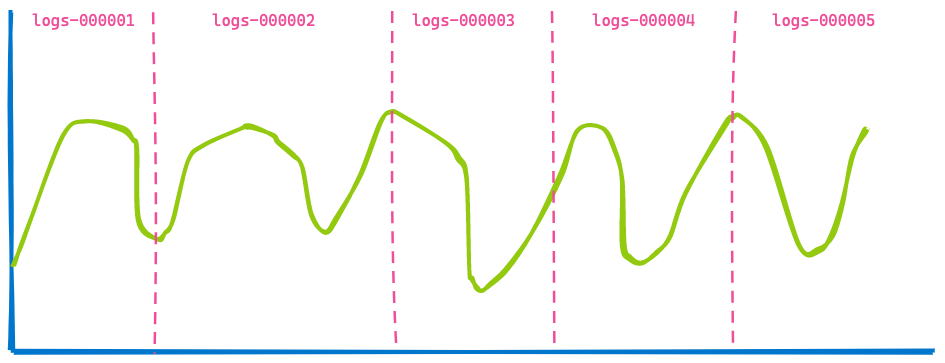
そこで、タイムスパンを3時間後に変更して、同じダッシュボードの表示を見てみます。
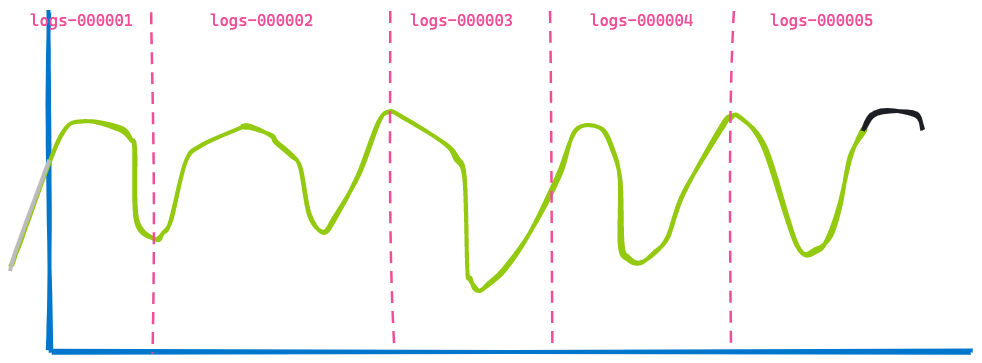
この2つ目のビジュアライゼーションは1つ目のものに非常に似ています。一部のデータが古くなったため表示されなくなり(左の青線)、また一部のデータが最後に追加されています(黒線)。何が変わっていないか分かりますか?インデックスlogs-000002、logs-000003、およびlogs-000004から返されているデータです。
これらのデータがページキャッシュにあったものだとしても、検索を実行し、その結果のアグリゲーションを実行する必要があります。つまり、この重複作業を実行する必要はないのです。これを実現するために、Elasticsearchにもう1つ最適化が加えられています。それは、クエリの再記述機能です。ログのインデックスlogs-000002、logs-000003、およびlogs-000004のタイムスタンプの範囲を指定するのではなく、それをmatch_allクエリ内に記述することができます。これにより、そのタイムスタンプに関してインデックス内のすべてのドキュメントが一致することになります(もちろんその他のフィルターも適用可能です)。この再記述機能により、これら3つのインデックスに対して両方のリクエストがまったく同じリクエストとなるため、キャッシュすることができます。
これはシャードレベルリクエストのキャッシュとなります。リクエストのフルレスポンスをキャッシュするという考え方です。検索をまったく実行する必要なく、基本的にレスポンスが瞬時に返されます。データが変更されていなければ、古いデータが返されることはありません。
さらに詳細
キャッシングのために必要なコンポーネントは、IndicesRequestCacheクラスです。このメソッドは、クエリフェーズの実行時にSearchService内で使用されます。また、クエリがキャッシング対象として適切かどうかについての追加チェックもあります。たとえば、結果が歪曲されないようにするために、プロファイル中のクエリがキャッシュされることはありません。
このキャッシュはデフォルトで有効化されています。ヒープ全体の最大1パーセントを占める可能性があり、必要に応じてリクエストごとに構成することもできます。デフォルトでは、このキッシュはヒットを返さない検索リクエストに対して有効になっています。これはまさにKibanaビジュアライゼーションリクエストです。ただし、リクエストパラメータを介して有効にすることで、ヒットが返されるときにこのキャッシュを使用することもできます。
次のようにすることで、このキャッシュの使用に関する統計を取得できます。
GET /_nodes/stats/indices/request_cache?human
まとめ
シャードレベルリクエストのキャッシュは検索リクエストに対するフルレスポンスを記憶し、同じクエリが再度実行された場合は、ディスクやページキャッシュにアクセスすることなく、フルレスポンスを返します。名前が示すとおり、そのデータ構造は、データを含むシャードと結び付けられており、古いデータを返すこともありません。
クエリキャッシュ
この記事の最後に説明するキャッシュは、クエリキャッシュです。このキャッシュの動作方法も他のキャッシュとは異なります。ページキャッシュは、クエリから実際に読み込まれるデータの量に関係なく、データをキャッシュします。シャードレベルクエリのキャッシュは、同様のクエリが使用されたときにデータをキャッシュします。このクエリキャッシュはさらに粒度が細かく、異なるクエリ間で再利用されるデータをキャッシュすることができます。
その仕組みを見てみましょう。複数のログ間で検索することを想像してみてください。3人の異なるユーザーが今月のデータをブラウジングしているとします。ただし、それぞれのユーザーは異なる検索語を使用しています。
- ユーザー1は「failure」を検索
- ユーザー2は「Exception」を検索
- ユーザー3は「pcre2_get_error_message」を検索
各検索では異なる結果が返されますが、全員が同じタイムフレーム内を検索しています。ここがクエリキャッシュの出番です。クエリのその部分だけをキャッシュすることができるのです。ディスクを探すのではなく、情報をキャッシュし、そのキャッシュされたドキュメントのみに対して検索を実行するというのが基本的な考え方です。おそらくクエリは次のようになるでしょう。
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte":"2021-02-01",
"lt":"2021-03-01"
}
}
}
]
}
}
}
どのクエリでも「filter」の部分は同じままです。これは、転置インデックスでのデータの様子を表した、非常に簡略化されたビューです。各タイムスタンプはドキュメントIDにマッピングされます。
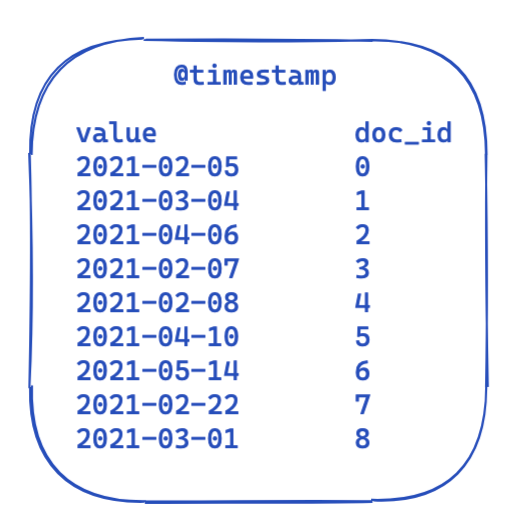
では、これがどのようにしてクエリ間で最適化および再利用されるのでしょうか。ここで登場するのがビットセットです(ビットアレイとも呼ばれます)。ビットセットは基本的に配列であり、各ビットがドキュメントを表します。この@timestampフィルター専用の、1か月をカバーするビットセットを作成することができます。0はドキュメントがその範囲外であることを意味し、1は範囲内であることを意味します。結果のビットセットは次のようになります。
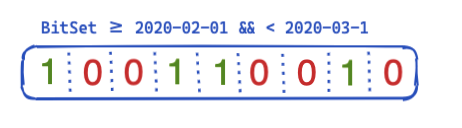
セグメントベースでこのビットセットを作成した後(つまり、マージされたり、新たにセグメントが作成された場合は常に再作成する必要が生じます)、次のクエリでは、フィルターを実行する前に、4つのドキュメントを除外するためにディスクにアクセスする必要はありません。ビットセットにはいくつかの興味深い特性があります。まず、組み合わせることができます。2つのフィルターと2つのビットセットがある場合、両方のビットが設定されているドキュメントを簡単に把握できます。または、ORクエリをマージすることができます。その他の興味深い特性には圧縮があります。デフォルトでは、フィルターごとにドキュメントあたり1つのビットが必要です。しかし、固定ビットセットではなくroaring bitmapなどの別の実装を使用することで、メモリ要件を減らすことができます。
ElasticsearchおよびLuceneでの実装はどのようになるでしょうか。見てみましょう。
さらに詳細
ElasticsearchはIndicesQueryCacheクラスを備えています。このクラスはIndicesServiceのライフサイクルにバインドされています。キャッシュ自体がJavaヒープを使用することからも分かるとおり、これはインデックスごとではなくノードごとの機能です。そのインデックスクエリキャッシュには、次の2つの構成オプションがあります
indices.queries.cache.count:キャッシュエントリの合計数。デフォルトは10,000indices.queries.cache.size:このキャッシュに使用されるJavaヒープの割合。デフォルトは10%
IndicesQueryCacheコンストラクターでは、新しいElasticsearchLRUQueryCacheが設定されます。このキャッシュはLuceneのLRUQueryCacheクラスから拡張されています。そのクラスは次のコンストラクターを持ちます。
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
MinSegmentSizePredicateは、 少なくとも10,000ドキュメントを持つセグメントのみがキャッシュ対象となるようにするとともに、そのシャードの全ドキュメントの3%を超えるように保証します。
ただし、ここからは少し複雑になります。データがJVMヒープにある場合でも、最も一般的なクエリ部分を追跡してそれらのみをキャッシュに格納するという別のメカニズムがあります。ただし、この追跡はシャードレベルで実行されます。FrequencyTrackingRingBufferを使用するUsageTrackingQueryCachingPolicyクラスがあります(固定サイズの整数アレイを使用して実装)。このキャッシングポリシーには、そのshouldNeverCacheメソッド内に追加のルールもあり、用語クエリ、all document/no documentとの一致クエリ、または空クエリなどの特定のクエリのキャッシングを防止します。これらはキャッシングしなくても十分高速だからです。また、1回の呼び出しでキャッシュがいっぱいにならないようにするために、キャッシング対象となるための最低頻度に関する条件もあります。使用状況、キャッシュビット率、その他の情報については以下によって追跡できます。
GET /_nodes/stats/indices/query_cache?human
まとめ
クエリキャッシュの粒度は一段上のレベルであり、クエリ間で再利用できます。組み込みのヒューリスティックにより、複数回使用されるフィルターのみがキャッシュされます。また、フィルターに基づいて、キャッシュする価値があるか、または既存のクエリ方法がヒープメモリの浪費を回避するのに十分な速度でクエリを実行できるかどうかも判断されます。古いデータが返されるのを防ぐために、これらのビットセットのライフサイクルはセグメントのライフサイクルにバインドされます。新しいセグメントが使用されれば、新しいビットセットを作成する必要があります。
キャッシュは高速化を実現する唯一の方法か?
状況によります(この記事のどこかで、このことに触れられるはずだと誰もが思っていたことでしょう)。Linuxカーネルに関する最近の開発はかなり有望です:io_uring。これは、Linux 5.1以降で使用可能な完了キューを使用して、Linuxで非同期I/Oを実行する新しい方法です。io_uringはまだ開発中であることにご注意ください。ただし、io_uringをNettyのように使うというのは、Javaの世界では初めての試みです。単純なアプリケーションのパフォーマンステストでは非常に期待できるようです。実際のパフォーマンスの数値を見るには少し待たなければなりませんが、私はこれによってもかなりの変化が見られると期待しています。どこかの時点でJDKでもサポートされるようになることを願っています。Project Loomの一部としてio_uringをサポートするというプランがあり、これによってio_uringがJVMにもたらされるかもしれません。madvise()を介してLinuxカーネルにアクセスパターンのヒントを提示できるなどのさらなる最適化も、JVMではまだ公開されていません。このヒントにより、カーネルが次の読み込みを見越して必要以上のデータを読み込もうとする先読みの問題を防止できます。これは、ランダムアクセスが必要な場合には役に立ちません。
他にもさまざまな新機能があります。Luceneの開発者は、どのシステムも有効活用できるように忙しく取り組んでいます。外部メモリAPIを使用したLuceneMMapDirectoryの再記述に関する最初のドラフトも作成中であり、これはJava 16でプレビュー機能となる可能性があります。ただし、これはパフォーマンスを理由としておらず、現在のmmap実装の特定の制限を克服するものとして考えられたものです。
Luceneに関するもう1つの最近の変更は、FileChannelクラスで直接I/O(O_DIRECT)を使用してネイティブ拡張を取り除くことです。これは、データの書き込みによってページキャッシュがスラッシングされないことを意味します。これはLucene 9の機能となる見込みです。
場合によっては、キャッシュについて考える必要がなくなることもあるような、処理の高速化方法もあり、それによって運用の複雑さを軽減できます。最近、数回にわたって、date_histogramアグリゲーションの高速化に関する大きな改善がありました。長文ではありますが、学ぶべきことの多いこのブログ記事をぜひお読みください。
大幅な改善に関するその他のすばらしい(キャッシングを使用しない)例には、Elasticsearch 7.0でのBlock-Max WANDの採用があります。その詳細については、Adrien Grandによるこちらのブログ記事をお読みください。
キャッシングの詳細に関するまとめ
さまざまなキャッシュに関して掘り下げましたが、楽しんでいただけたでしょうか。どのキャッシュがいつ効力を発揮するかについてお分かりいただけたと思います。覚えておいていただきたいのは、キャッシュが理に適っているかどうかや、常に追加や期限切れが発生することでスラッシングが継続するかどうかを把握するためには、キャッシュを監視することが特に有効であるということです。Elasticクラスターの監視を有効にすると、ノードの[Advanced]タブでクエリキャッシュやリクエストキャッシュによるメモリ使用を確認することができ、また特定のインデックスを見ることでインデックスごとに確認することもできます。
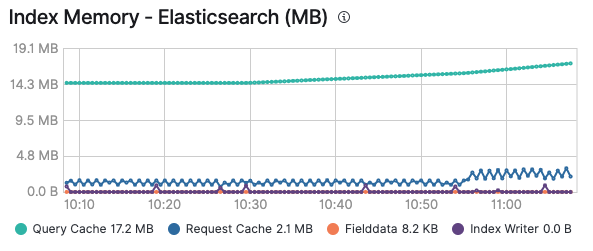
Elastic Stack上の既存のソリューションはすべて、これらのキャッシュを使用して、できるだけ高速にクエリの実行とデータの提供を行えるようにしています。Elastic Cloudでのロギングと監視の有効化は1回のクリックででき、追加コストの必要なく、すべてのクラスターを監視できるということを覚えておいてください。ぜひお試しください。