Elasticの機械学習によって検出された異常の説明


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
なぜ、このデータはこんなにも異常なのか。なぜ、異常スコアがもっと高くならないのか。異常検知は、ElasticセキュリティとElasticオブザーバビリティの機械学習機能の中でも有用な機能です。ですが、残念なことに、その数値の見方は少々ややこしいことがあります。わかりやすく説明できる詳しい人を探すか、図を描いてみるしかない場合もあるほどです。
Elastic 8.6では、異常レコードのさらなる詳細を表示できるようになっています。これらの詳細情報からは、異常スコアリングアルゴリズムの裏側が見て取れます。
異常スコアリングと正規化については、過去のブログでご説明しています。異常検知アルゴリズムでは、時系列のデータをオンラインで分析します。日、週、月、年など、さまざまな時間スケールでの傾向と周期的パターンを特定します。現実世界のデータは、通常、さまざまな時間スケールでの傾向と周期的パターンが入り混じっています。しかも、異常のように見えたものが、実は反復的に発生するパターンだったということもあります。
異常検知ジョブは、データを説明できる仮説を作成します。これらの仮説は、得られた証拠を使用して重み付けしたうえで混合されます。仮説はすべて、確率分布となります。これにより、観測されたデータの"正常度"に関する信頼区間が判断されます。この信頼区間から外れたデータは異常です。
異常スコアの影響要因
ここで、疑問に思う方もいるかもしれません。このやり方は筋道が通っているとしても、予期せぬ振る舞いが見られた場合、その異常度はどうやって評価すればいいのでしょう。
レコードに付与される初期異常スコアは、次の3つの要素で構成されることがあります。
- 単一バケットの影響
- 複数バケットの影響
- 異常特性の影響
異常検知ジョブでは時系列データが時間バケットに分割されることにご注意ください。バケット内のデータは関数を使用して集計されます。異常検知はバケット値に基づいて行われます。バケットに関する詳細と、適切なバケットスパンを選択することの重要性については、こちらのブログ記事をご覧ください。
まず、混合された仮定に基づいて、バケット内の実際の値の確率を調べます。この確率は、類似の値が過去にいくつ見られたかによって異なります。これはしばしば、実際の値と代表値との差に関係します。代表値とは、バケットの確率分布の中央値です。この確率は単一バケットの影響と関係します。これは通常、短いスパイクまたはディップの形で見られる初期異常スコアとなります。
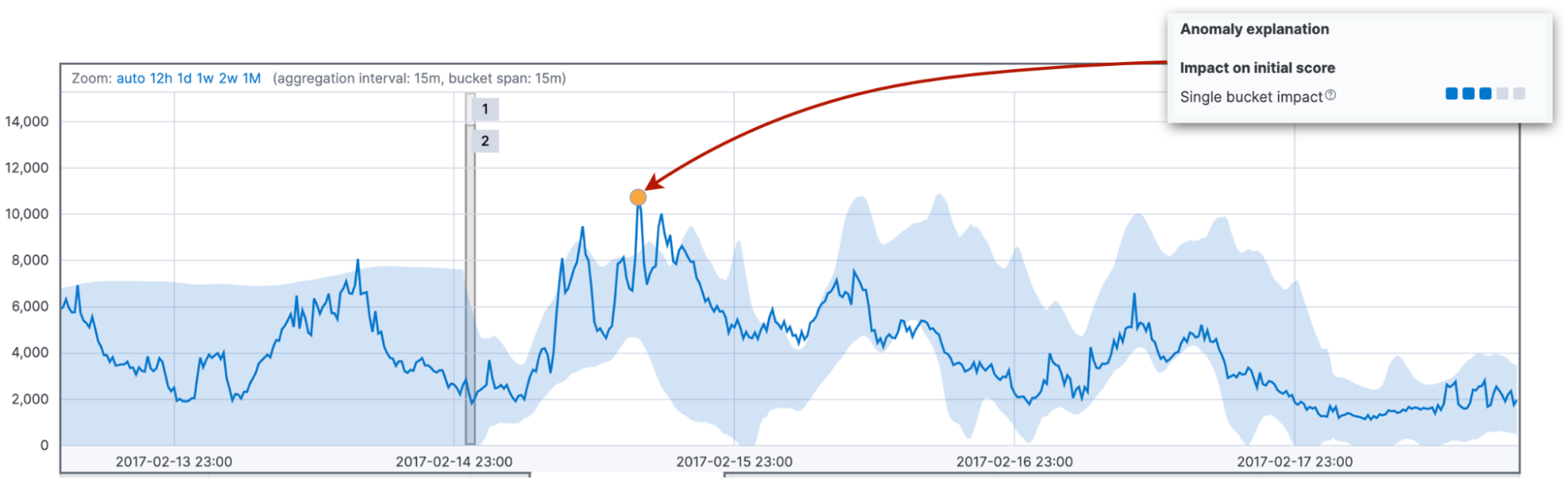
次に、前の11個のバケットの値が現在のバケットで観測される確率を調べます。実際の値と代表値との差が多数あるようなら、現在のバケットの初期異常スコアには複数バケットの影響があると考えられます。
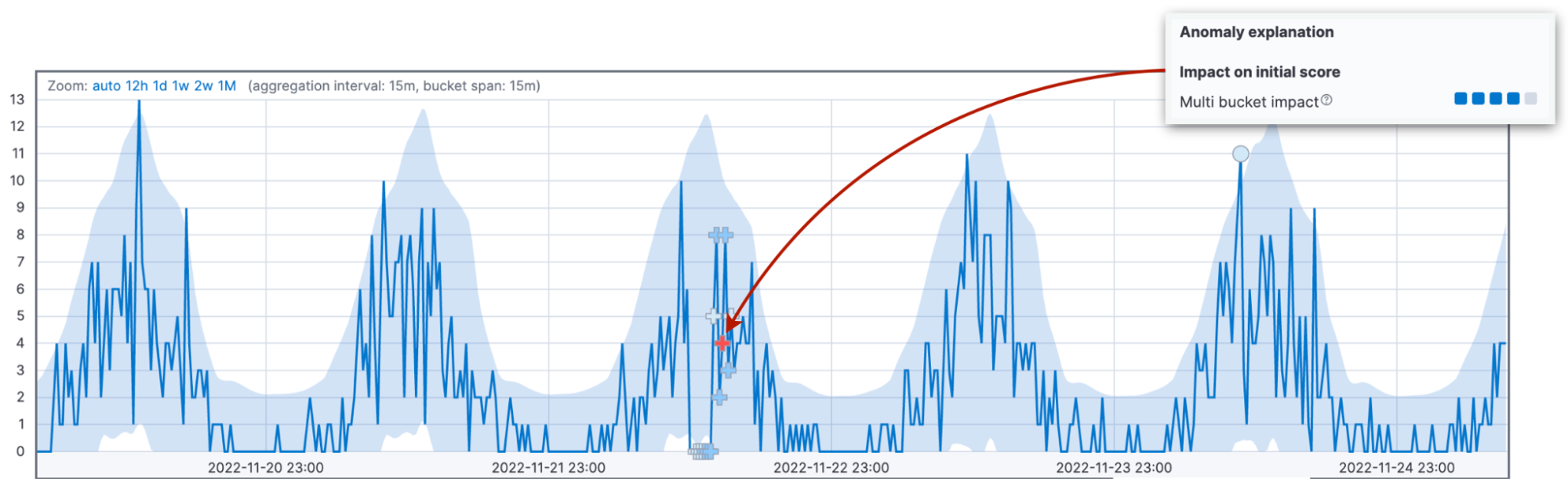
複数バケットの影響は、異常スコアがわかりにくくなる原因の2位であるため、もう少し詳しくご説明します。これは12個のバケットにわたって偏差を調査し、その影響を現在のバケットと関連付けたものです。複数バケットの影響が強ければ、それは現在のバケットより前の間隔で普通でない振る舞いがあったということです。現在のバケット値が95%信頼区間内に戻っているかどうかは、気にするべきことではありません。
この違いを強調するために、複数バケットの影響が強い異常には異なるマーカーすら使用されます。上の図の複数バケットの異常をよく見てみると、円ではなく十字記号(+)で異常がマークされていることがわかります。
最後に、長さやサイズなどの異常特性の影響を考慮します。ここでは、上記のような固定された間隔ではなく、現在までの合計期間で異常を判断します。その際のバケット数は、1個でも30個でも構いません。異常の長さとサイズを過去の平均値と比較することで、顧客ならではのデータ領域やパターンを見出すことができます。
さらに、アルゴリズムのデフォルトの振る舞いでは、持続期間の短いスパイクよりも長さの長い異常のスコアの方が高くなります。実際には、短い異常はデータの不具合であることがよくありますが、長い異常は対応が必要なものである場合が多いです。
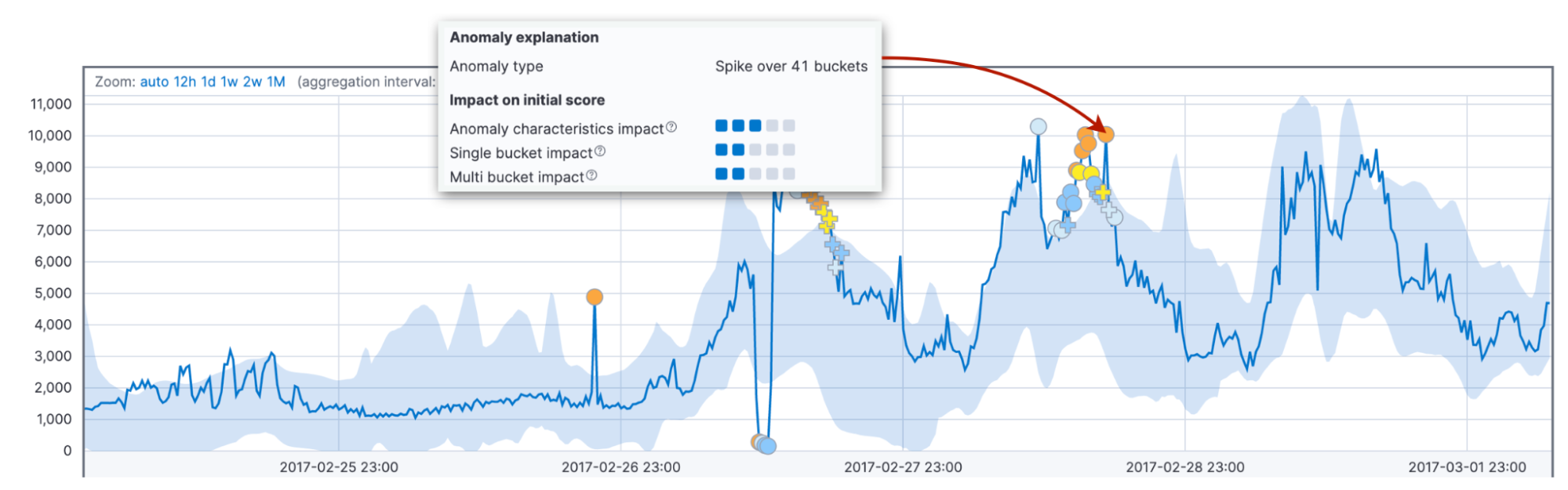
固定された間隔と可変間隔の両方の要因を見るのは理由があります。これらを組み合わせることで、さまざまな領域での異常な振る舞いを、より確実に検出できるようになるからです。
レコードのスコアの低下
ここで、スコアの話をわかりにくくさせている主な原因、スコアのくりこみについて説明します。異常スコアは0~100の範囲で正規化されます。100に近い値は、そのジョブにおいて発生した過去の異常の中でも最大の異常であることを意味します。つまり、かつてないほど大きな異常が発生した場合は、過去の異常スコアを減らす必要が出てきます。
上で説明した3つの要素は、初期異常スコアの値に影響を及ぼします。初期のスコアは、オペレーターへの警告の基準となる重要なデータです。新しいデータが到着すると、異常検知アルゴリズムが過去の異常スコアを調節します。設定パラメーター(renormalization_window_days)は、調整時の時間間隔を指定します。したがって、異常自体は大きいはずなのに異常スコアが極度に低いのは、その後にそのジョブでもっと大きな異常が発生したためである可能性があります。
Kibanaバージョン8.6のシングルメトリックビューアーでは、この変更がハイライトされます。
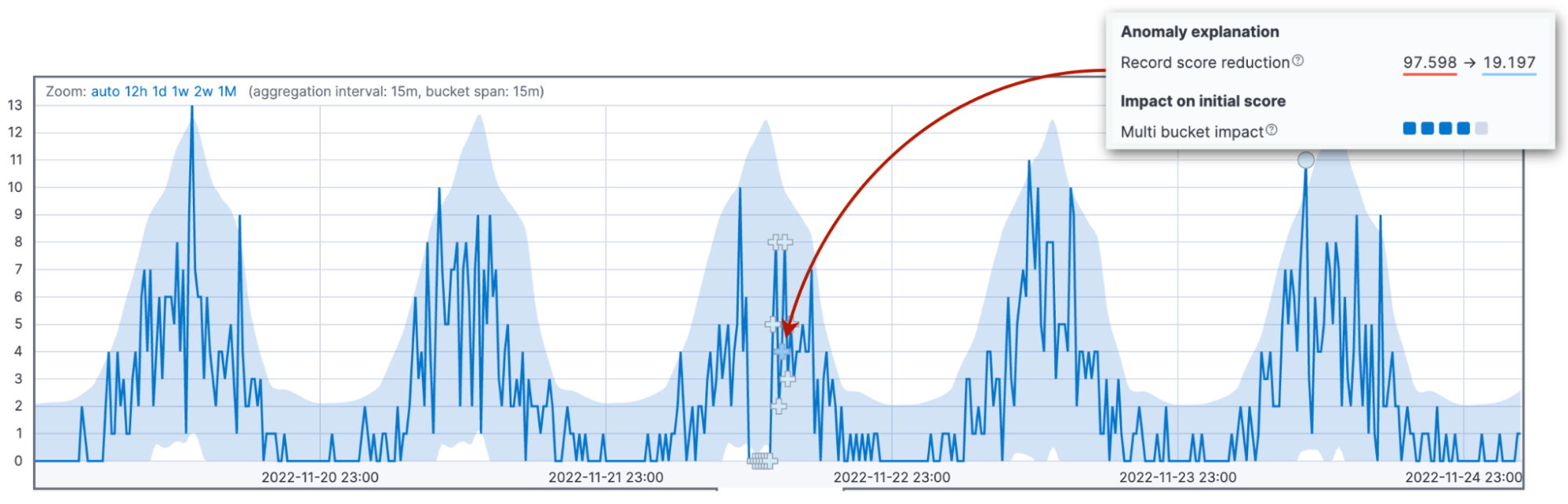
スコアが下がるその他の要因
初期のスコアが下がる原因は、もう2つ考えられます。変動の多い間隔と、不完全なバケットです。
現在のバケットが、データの変動の多い季節パターンの一部である場合、異常検知の信頼性は低くなります。たとえば、サーバーメンテナンスのジョブが毎日真夜中に実行されているとします。これらのジョブが原因で、リクエスト処理の遅延が大きく変動する場合があります。
なお、現在のバケットの観測値の数が過去の予想と類似しているなら、信頼性が高くなります。
すべてを組み合わせて判断
多くの場合、現実世界の異常にはいくつかの要因が影響しています。それらはシングルメトリックビューアーの新しい詳細ビューで次のように表示されます。
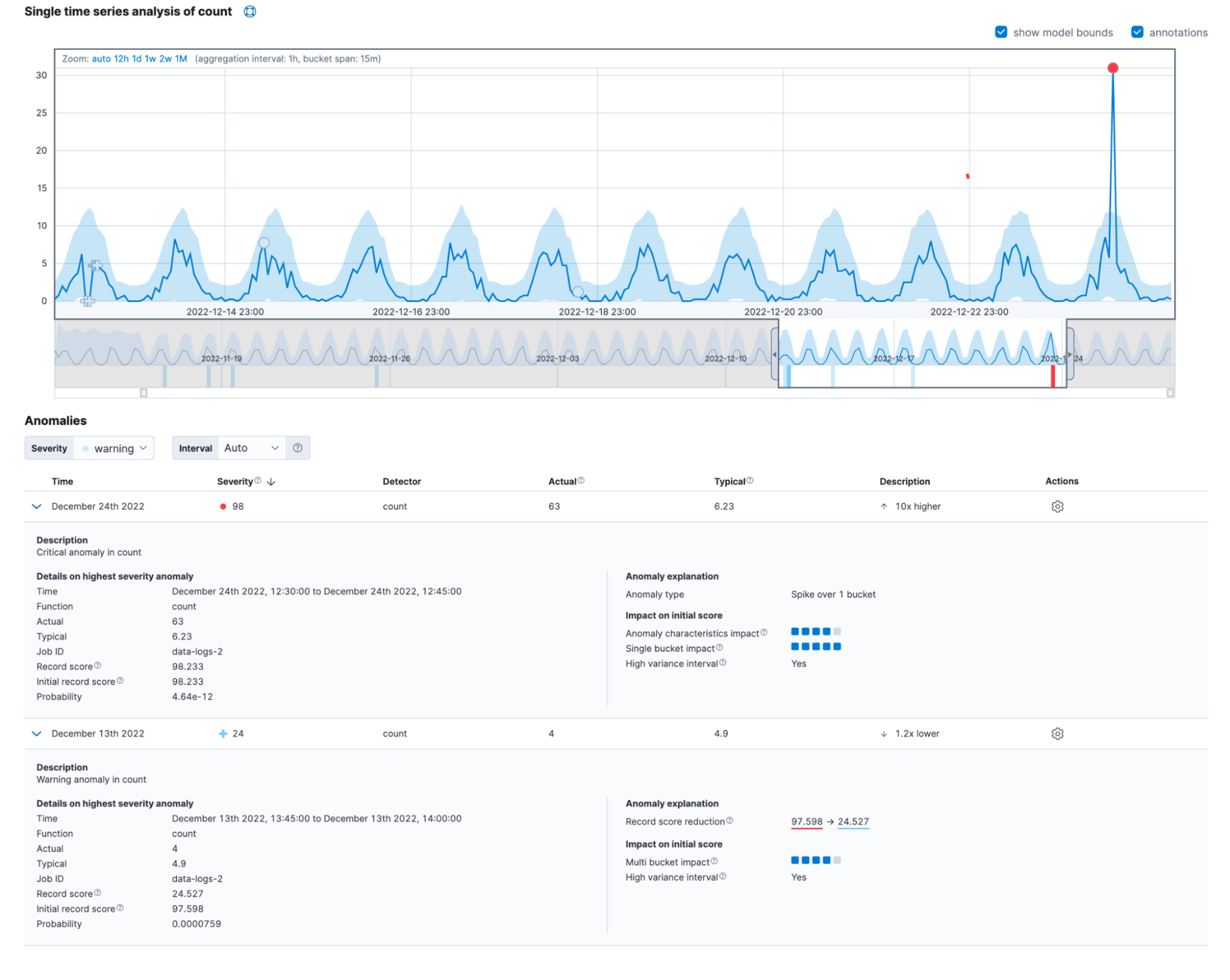
この情報は、レコード取得APIのanomaly_score_explanationフィールドでも確認できます。
まとめ
異常レコードの新しい詳細ビューを使用できるようになったElasticsearch Serviceの最新バージョンを、Elastic Cloudでご利用ください。今すぐ無料のElastic Cloudトライアルを開始してプラットフォームにアクセスしてみましょう。色々な使い方をぜひお試しください。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷