ES|QL(Elasticsearch Query Language)を使い始める
ES|QLを使用して、アグリゲーション、ビジュアライゼーション、アラートをDiscoverから直接作成することで、インサイトを得られるまでの時間を短縮

 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
ES|QL(Elasticsearch Query Language)とは
ES|QL(Elasticsearch Query Language)とは、Elastic®の新しい革新的なパイプ型クエリ言語です。パワフルなコンピューティング機能とアグリゲーション機能でデータの分析と調査をスピードアップするよう設計されています。
展開中のサイバー攻撃の識別や運用上の問題の特定といった複雑な作業を、より簡単かつ効率的に行えるようになります。
ES|QLは、大規模データセットの検索、アグリゲーション、ビジュアライゼーションをシンプル化するだけでなく、ルックアップやリアルタイム処理などの高度な機能でユーザーを支援します。しかも、これらすべての操作を、Discoverの1つの画面で行うことができます。
ES|QLがElastic Stackに追加するパワフルな3つの機能
-
_queryを強化する新しい高速な分散型の専用クエリエンジン:新しいES|QLのクエリエンジンは、並行処理を利用した高度な検索機能により、データのソースや構造に左右されることなく高速化と効率化を実現します。新しいエンジンのパフォーマンスの測定結果は公開されています。こちらの公開ダッシュボードでパフォーマンスのベンチマーキングをご覧いただけます。
-
パワフルな新しいパイプ型言語:ES|QLは、データ調査に変革、拡充、シンプル化をもたらす、Elasticの新しいパイプ型言語です。ES|QL言語の機能について詳しくは、こちらのドキュメントでご確認ください。
-
一元化された新しいデータ探索/調査エクスペリエンス:1画面でアグリゲーションとビジュアライゼーションを作成できるのでワークフローの中断がなく、問題解決までの時間が短縮されます。
ElasticがES|QLに時間と労力を投入した理由
ユーザーが求めているのは、データを表示するだけでなく、データを効率よく活用できる手段を提供してくれるアジャイルなツールと、リアルタイムでインサイトに基づいて行動したり、取り込み後データを処理したりできる機能です。
Elasticは、ユーザーのデータ探索エクスペリエンスを強化する取り組みを進めてきましたが、その結果たどり着いたのがES|QLへの投資でした。ES|QLは、初心者には使いやすく、エキスパートには頼もしい設計になっています。ES|QLは直感的なインターフェースで、ユーザーは多くのことを修得しなくても、すぐに利用を開始してデータを深掘りできます。自動入力とアプリ内ドキュメントにより、高度なクエリの作成も、ワークフローを中断せずに進められます。
さらに、ES|QLは数字を見せてくれるだけでなく、それに命を吹き込んでくれます。クエリの性質に合わせて自動調整されるLensのサジェストエンジンを活用した、コンテクストに基づくビジュアライゼーションにより、インサイトを明確に把握できます。
また、ダッシュボード機能とアラート機能への直接の統合により、エンドツーエンドで統一感のあるエクスペリエンスというElasticのビジョンが反映されています。
要するに、ES|QLへの投資は、コミュニティの進化するニーズに対するElasitcからの直接の回答であり、より密接に連携し、インサイトにあふれ、効率的なワークフローに向けた一歩なのです。
セキュリティとオブザーバビリティに関連するユースケースの詳しい紹介
ElasticのES|QLへの取り組みは、ユーザー(サイトリライアビリティエンジニア(SRE)、DevOps、脅威ハンターなど)が直面している課題に関する深い理解に端を発するものでもあります。
SREにとって、オブザーバビリティは不可欠です。ダウンタイムや不具合がわずかでも生じると、そのたびにユーザーエクスペリエンスは悪化し、その影響が収益性の低下にまで連鎖する可能性があります。1つの例が、ES|QLのアラート機能です。切り分けられたインシデントではなく意味のあるトレンドが重視されるES|QLのアラート機能のおかげで、SREは、システムの非効率性や障害を予防的にピンポイントで特定して対応できます。これによりノイズが減少し、システムの安定性を脅かす真の脅威に対して、よりタイムリーかつ効果的な対応を確実に行えるようになります。
DevOpsチームは、複数のアップデート、パッチ、新機能をデプロイしなければならず、常に時間に追われています。ES|QLの新しいパワフルなデータ探索機能とデータビジュアライゼーション機能を使用すれば、デプロイごとの影響をすばやく評価したり、システムの健全性を監視したり、リアルタイムでフィードバックを収集したりできます。これによりデプロイの質が向上するだけでなく、必要に応じて迅速に軌道修正を行うこともできるようになります。
脅威ハンターが相手にしているセキュリティ環境は、常に進化と変化を続けています。この常に変化する環境で、ES|QLがどのように脅威ハンターに役立つかの1つの例が、エンリッチ機能です。この機能を使用すると、多岐にわたるデータセットにわたってデータをルックアップし、その結果に基づいてセキュリティ脅威の兆候である可能性がある、隠れたパターンや異常を解明できます。さらに、コンテクストに基づくビジュアライゼーションのおかげで、生データだけでなく、視覚的に表示される実用的なインサイトも確認できます。これにより潜在的な脅威を識別するのに要する時間が大幅に短縮され、より迅速に脆弱性対策を行えるようになります。
サーバーの負荷が急増する原因を究明しようとしているSREでも、最新リリースの影響を評価しているDevOps専門家でも、侵害の可能性を調査している脅威ハンターでも、ES|QLは、その取り組みを複雑化するのではなく補強するツールになります。
このブログ記事の次のセクションでは、ES|QLを使い始めるにあたってのヒントと、ES|QLがデータを探索する際にどれだけ強力な相棒になるかを紹介する具体的な例をいくつか紹介します。
KibanaでES|QLを使いはじめる方法
ES|QLの使用を開始するには、Discoverに移動してデータビューのメニューから[Try ES|QL](ES|QLを試す)を選択します。わかりやすくて簡単です。
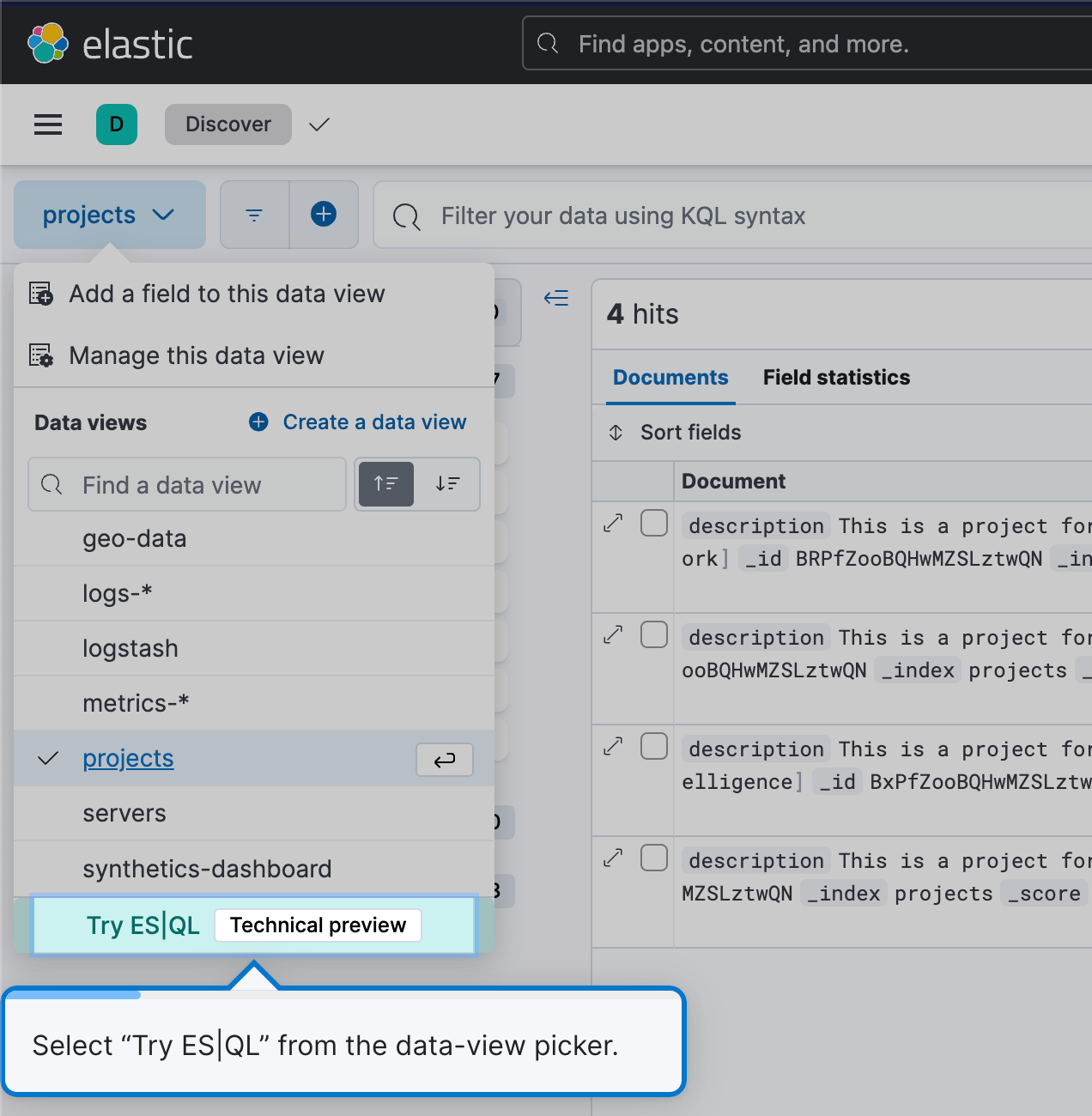
これでDiscoverがES|QLモードになります。
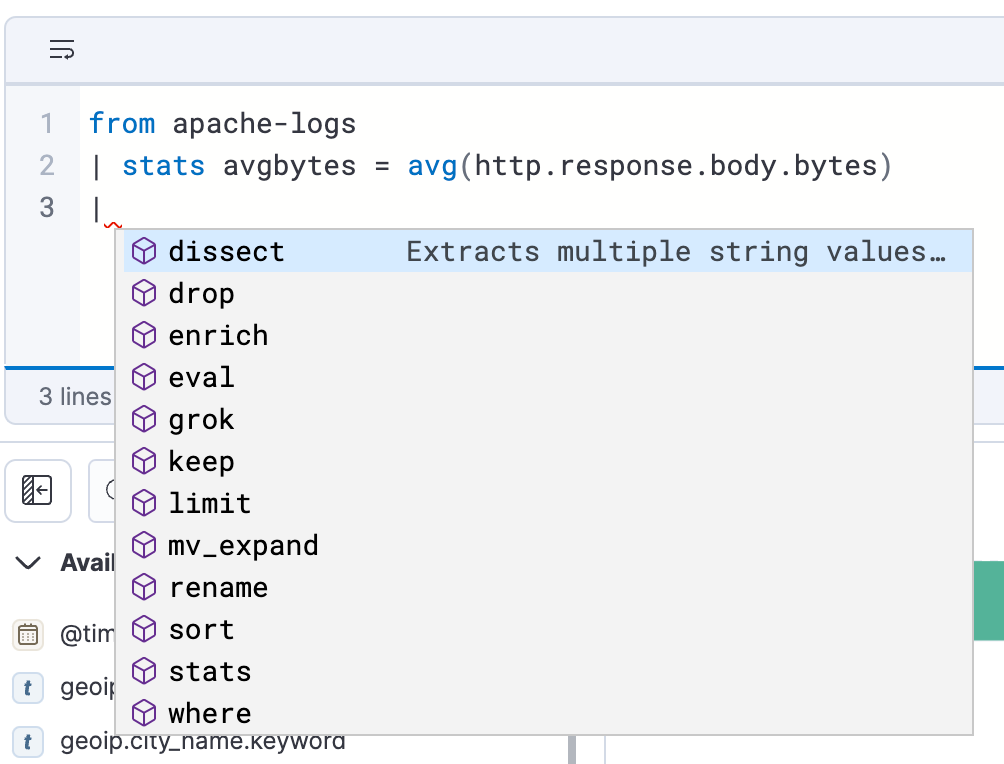
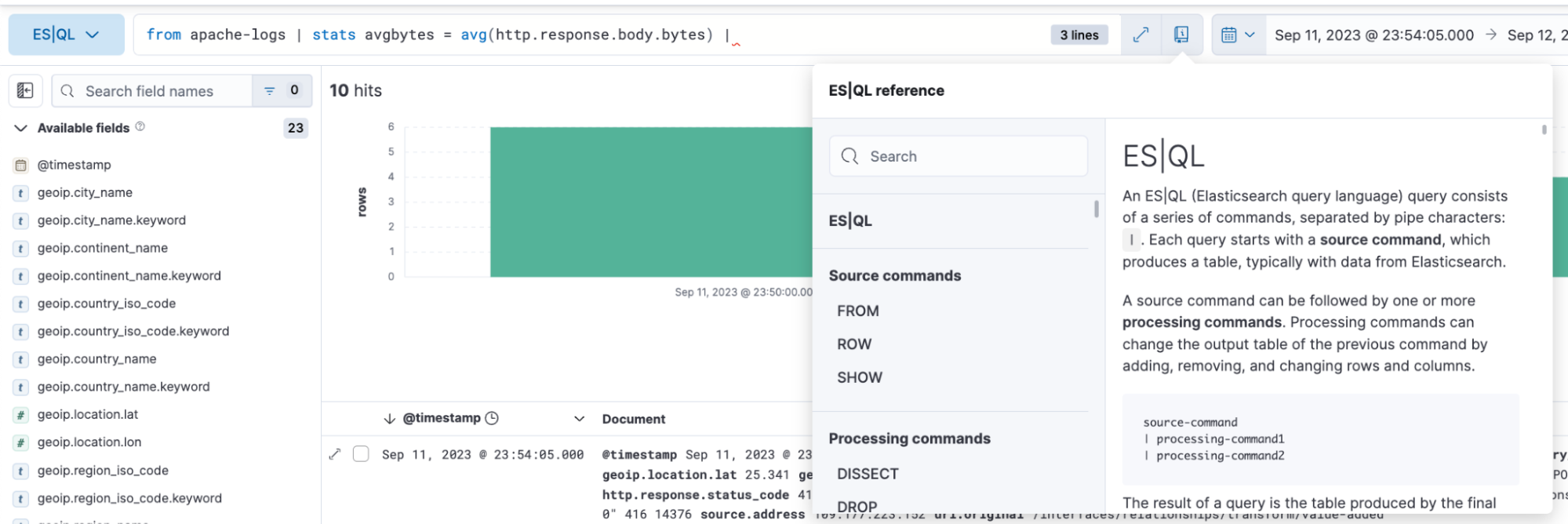
クエリを手軽に効率よく作成
ES|QLをDiscoverで使用すると、自動入力とアプリ内ドキュメントにより、パワフルなクエリをクエリバーで簡単に作成できます。
ES|QLでデータを分析、可視化する方法
ES|QLを使用すれば、包括的でパワフルなデータ探索を実行できます。Discover内でアドホックなデータ探索を実行でき、クエリビルダーから直接、アグリゲーションの作成、データの変換、データセットのエンリッチなどの作業を行えます。結果は実行したクエリに応じて、表形式かビジュアライゼーションで表示されます。
下の方で示すオブザーバビリティのためのES|QLクエリの例では、結果が表形式で表示された場合と、ビジュアライゼーションで表示された場合を掲載しています。
メトリックを使用するES|QLクエリのユースケース:
from metrics*
| stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct), max_mem = max(kubernetes.pod.memory.usage.bytes) by kubernetes.pod.name
| sort max_cpu desc
| limit 10上の例では、以下のソースコマンド、アグリゲーション関数、処理コマンドの使い方を紹介しています。
fromソースコマンド(ドキュメント)
from metrics*:これにより、「metrics*」のパターンと一致するインデックスパターンからクエリが開始されます。 アスタリスク(*)はワイルドカードの役割を果たします。つまり、名前が「metrics」で始まるすべてのインデックスパターンからデータが選択されます。
stats...byアグリゲーション(ドキュメント)、max(ドキュメント)、by(ドキュメント)
このセグメントでは、特定の統計に基づいてデータがアグリゲーションされます。分解すると次のようになります:
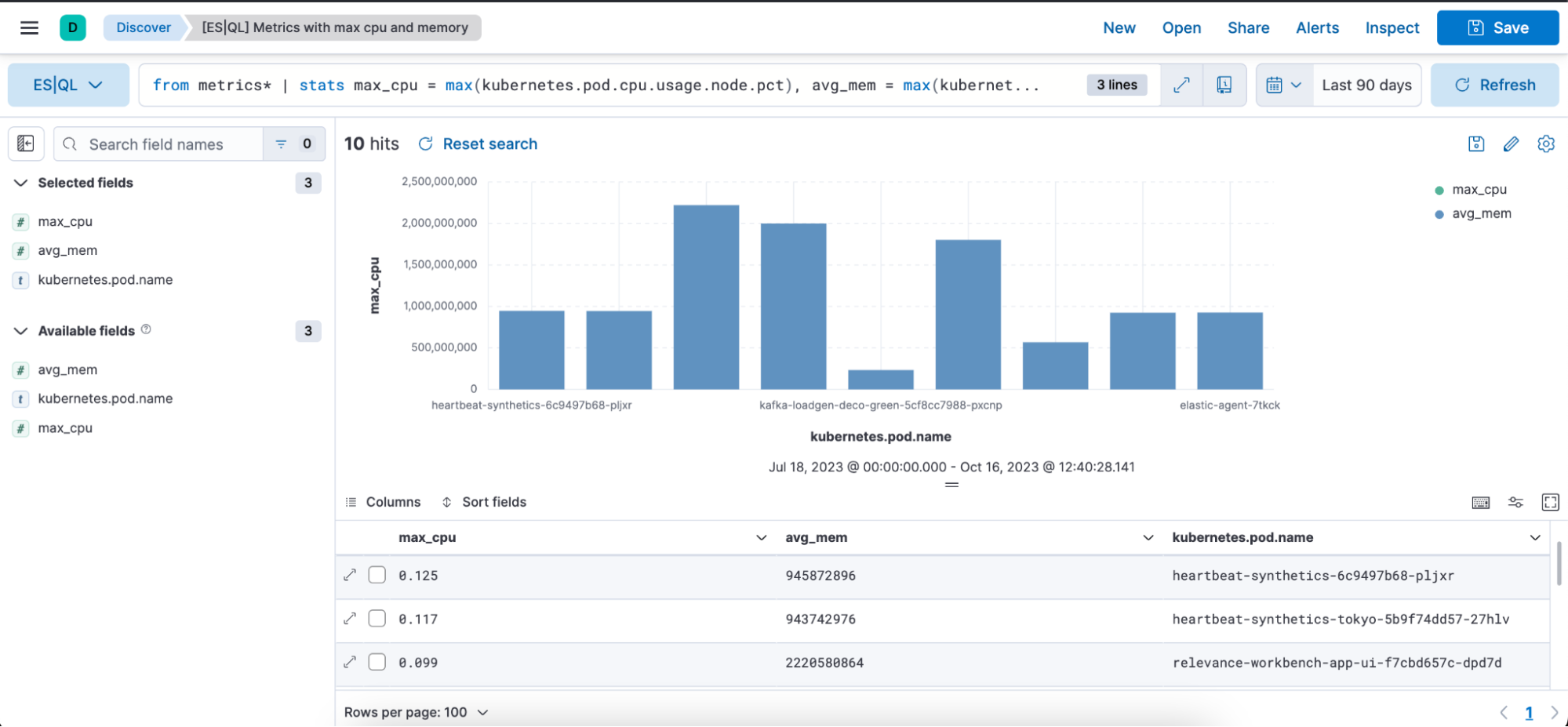
max_cpu=max(kubernetes.pd.cpu.usage.node.pct):それぞれの「kubernetes.pod.name」ごとに最大のCPU使用率が検索され、その値が「max_cpu」という名前の新しい列に格納されます。
max_mem = max(kubernettes.pod.memory.usage.bytes):それぞれの「kubernetes.pod.name」ごとに最大のメモリー使用量(バイト単位)が検索され、その値が「max_mem」という名前の新しい列に格納されます。
処理コマンド(ドキュメント)
sort max_cpu desc:これにより、結果データの行が「max_cpu」列の値に基づいて降順に並べ替えられます。つまり、「max_cpu」の値が最も大きい行が一番上になります。
limit 10:これにより、出力件数が並び替え後の上位10件の行に制限されます。
このクエリをまとめると以下のようになります。
- インデックスパターンを使用して、すべてのメトリックインデックスのデータをグループ化
- データをアグリゲーションし、それぞれのKubernetesポッドについて、最大CPU使用率と最大メモリー使用量を検索
- アグリゲーション済みデータを最大CPU使用率に基づいて降順に並び替え
- CPU使用率で上位10件の行のみ出力
コンテクストに基づくビジュアライゼーション:DiscoverでES|QLクエリを記述すると、Lensのサジェストエンジンによるビジュアル表示が行われます。どのようなビジュアライゼーションが行われるかはクエリの性質によって決まり、メトリック、ヒストグラム、ヒートマップなどがあります。
下の画像には、「max_cpu」、「avg_mem」「kubernetes.pod.name」の各列を含む先ほどのクエリの結果が、棒グラフ形式と表形式でビジュアル表示されています。
オブザーバビリティと時系列データを使用したES|QLクエリのユースケースの例:
from apache-logs |
where url.original == "/login" |
eval time_buckets = auto_bucket(@timestamp, 50, "2023-09-11T21:54:05.000Z", "2023-09-12T00:40:35.000Z") |
stats login_attempts = count(user.name) by time_buckets, user.name |
sort login_attempts desc上のクエリでは、以下のソースコマンド、アグリゲーション関数、処理コマンド、関数の使い方を紹介しています。
fromソースコマンド(ドキュメント)
from apache-logs:これにより「apache-logs」という名前のインデックスからクエリが開始されます。 このインデックスにはApache Webサーバーのトラフィックに関連するログエントリーが含まれています。
where(ドキュメント)
where url.original==”/login”:「url.original」フィールドが「/login」と等しいレコードのみに絞り込まれます。 つまり、ここではログイン試行かログインページへのアクセスに関連するログエントリーだけを見たいということです。
eval(ドキュメント)とauto_bucket(ドキュメント)
eval time_buckets =... :これにより「time_buckets」という名前の新しい列が作成されます。
「auto_bucket」関数は、人間にとってわかりやすいバケットを作成し、行ごとに、その行が属するバケットに対応する日時の値を返します。
「@timestamp」は、各ログエントリーのタイムスタンプが含まれるフィールドです。
「50」はバケットの数です。
「2023-09-11T21:54:05.000Z」:バケット化の開始時間です。
「2023-09-12T00:40:35.000Z」:バケット化の終了時間です。
これは、「2023-09-11T21:54:05.000Z」から「2023-09-12T00:40:35.000Z」までのログエントリーが等間隔で50分割され、各エントリーがタイムスタンプに基づいて特定の間隔に関連付けられることを意味します。
ここでは、正確な目標バケット数を指定するのではなく、指定した目標バケット数を上限として自分のニーズを満たせるように範囲を指定します。得られるバケット数を増やすには、auto_bucketに設定する範囲を狭くしてください。
stats...byアグリゲーション(ドキュメント)、count(ドキュメント)、by(ドキュメント)
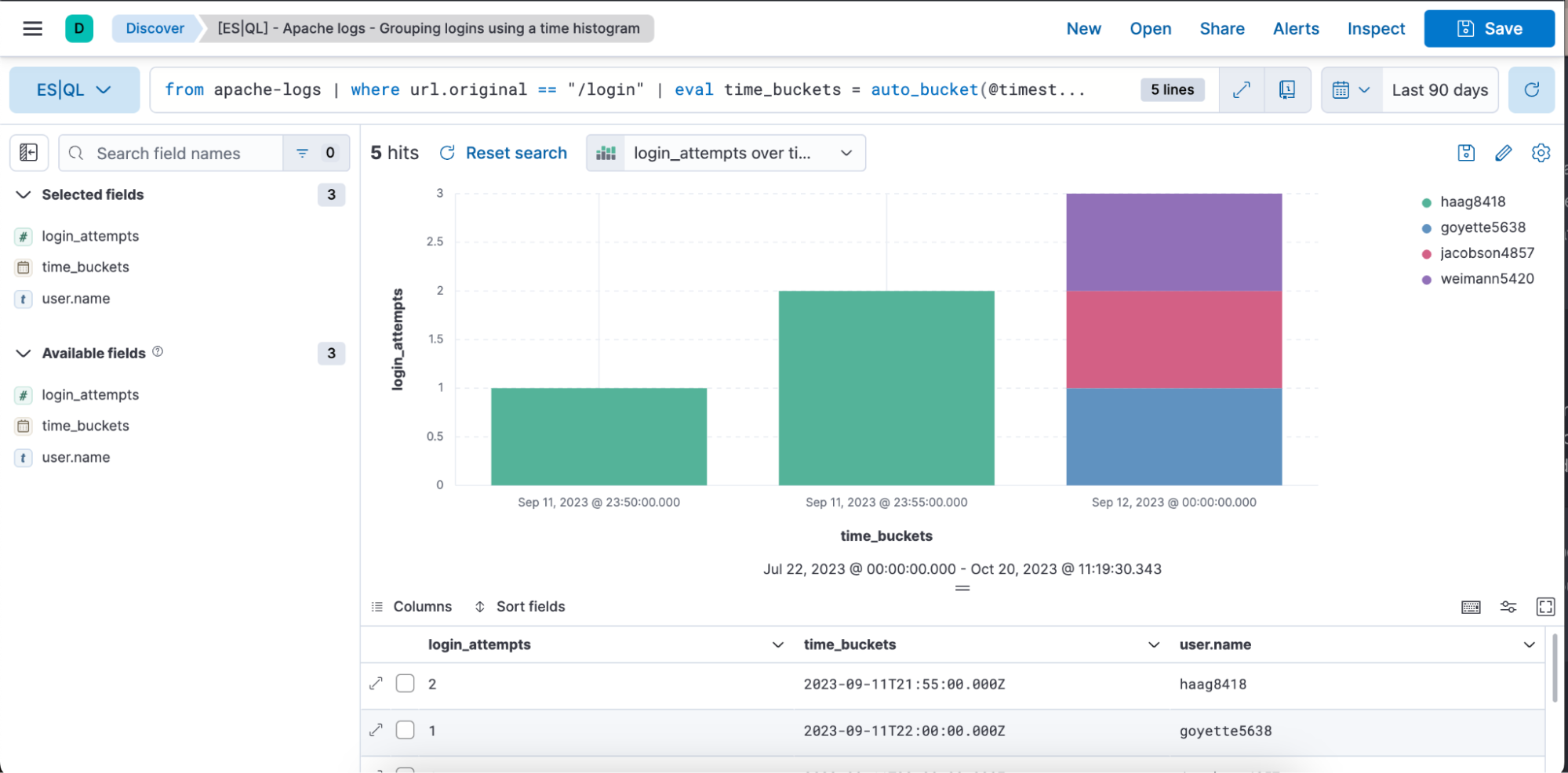
stats login_attempts = count(user.name) by time_buckets, user.name:ログイン試行の回数を計算するためにデータがアグリゲーションされます。そのために、「user.name」(ログインを試行したユニークユーザーを表します) の発生回数がカウントされます。
カウントは「time_buckets」(作成した間隔)と「user.name」の両方でグループ化されます。 つまり、時間バケットごとに、各ユーザーがログインを試行した回数が表示されます。
sort(ドキュメント)
Sort login_attempts desc:最後に、アグリゲーションの結果が「login_attempts」列に基づいて降順で並び替えられます。つまり、ログイン試行回数が最も多い結果が一番上に表示されます。
このクエリをまとめると以下のようになります。
- 「apache-logs」インデックスからデータを選択
- ログインページに関連するログエントリーに絞り込み
- 絞り込んだエントリーを特定の間隔にバケット化
- それぞれの間隔について、ユニークユーザーごとにログイン試行回数をカウント
- 結果をログイン試行回数が多い順に並び替え
下の画像には、「login_attempts」、「time_buckets」「user.name」の各列を含む先ほどのクエリの結果が、棒グラフ形式と表形式でビジュアル表示されています。
DiscoverとDashboardでビジュアライゼーションをインライン編集する
ES|QLのビジュアライゼーションは、DiscoverとDashboard内で編集できます。Lensに移動することなくスピーディに編集でき、シームレスに変更を加えられます。
ここでは、ワークフローをひととおり確認できる動画と、ステップガイドを掲載しています。
ES|QLクエリを記述する
クエリの性質に応じてコンテクストに基づくビジュアライゼーションが表示される
ビジュアライゼーションをインライン編集する
Dashboardに保存する
Dashboardでビジュアライゼーションを編集できるようになる
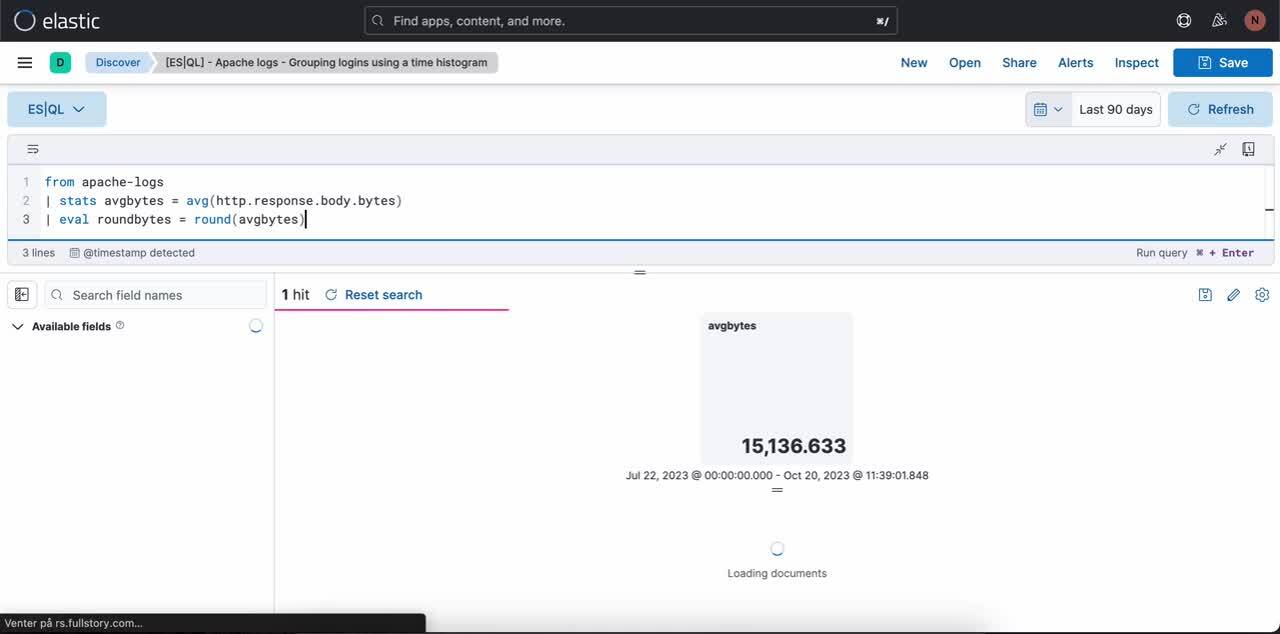
手順1. ES|QLクエリを記述する。この例ではメトリックビジュアライゼーションを生成するクエリを使用します。
from apache-logs
| stats avgbytes = avg(http.response.body.bytes)
| eval roundbytes = round(avgbytes)
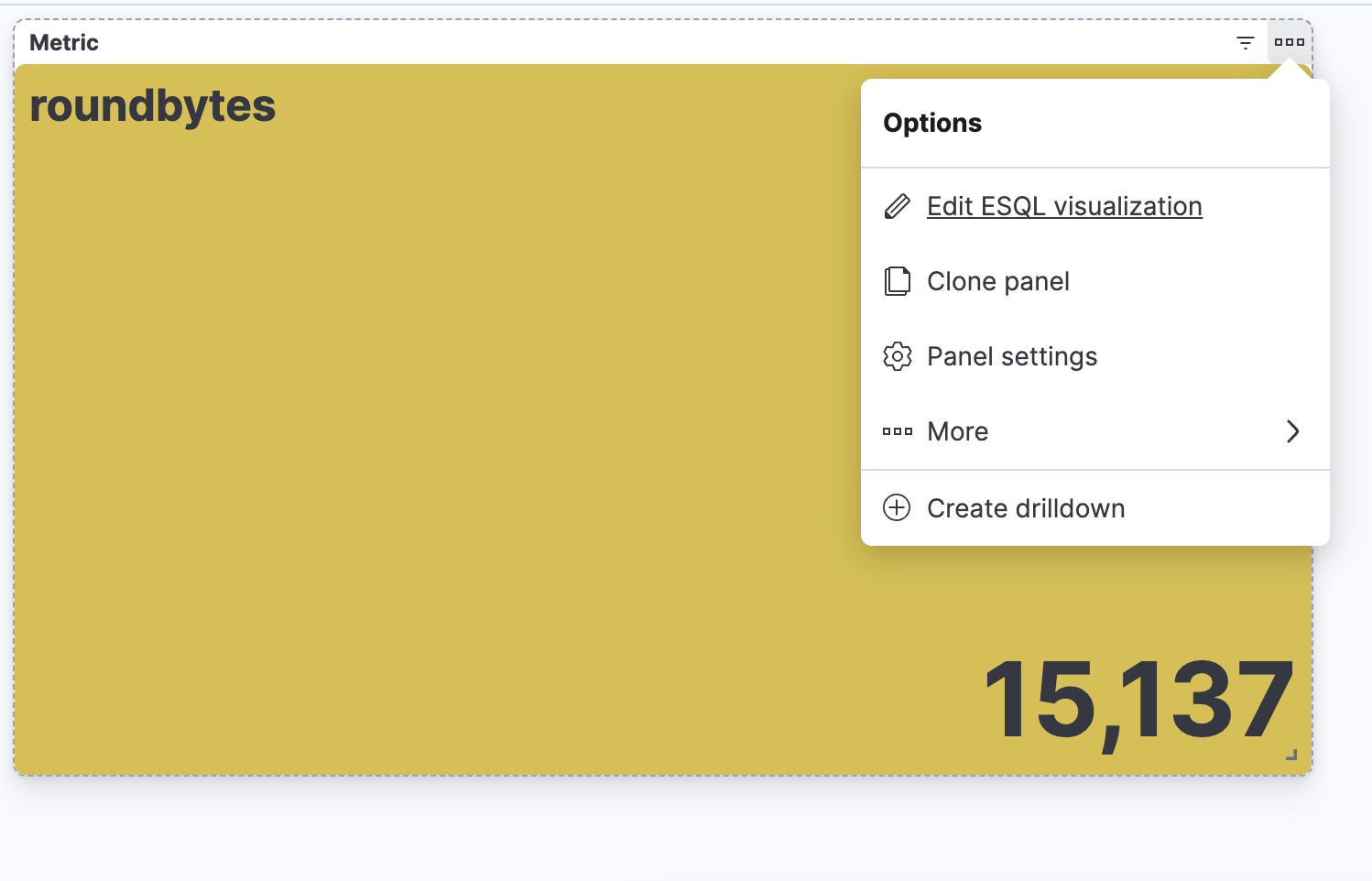
| drop avgbytes手順2. クエリの性質に応じて、コンテクストに基づくビジュアライゼーション(この例ではメトリックビジュアライゼーション)が表示される。鉛筆のアイコンを選択すると、インライン編集モードに移行します。
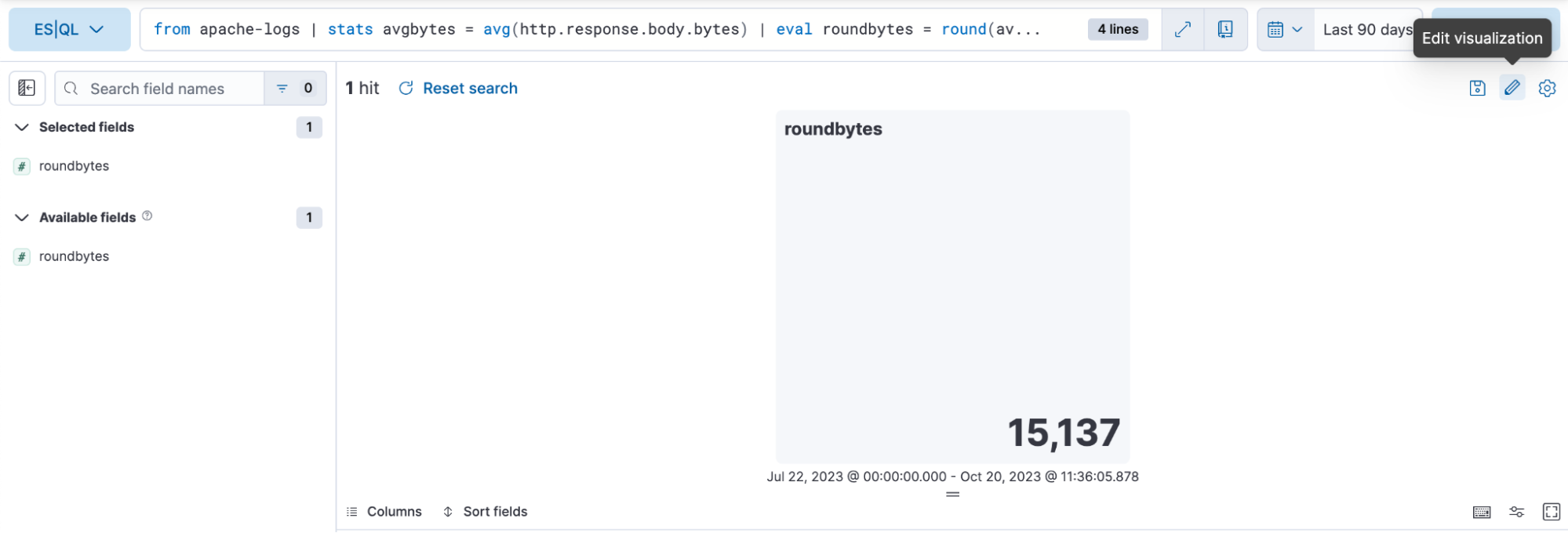
手順3. インライン編集モードでビジュアライゼーションを編集する
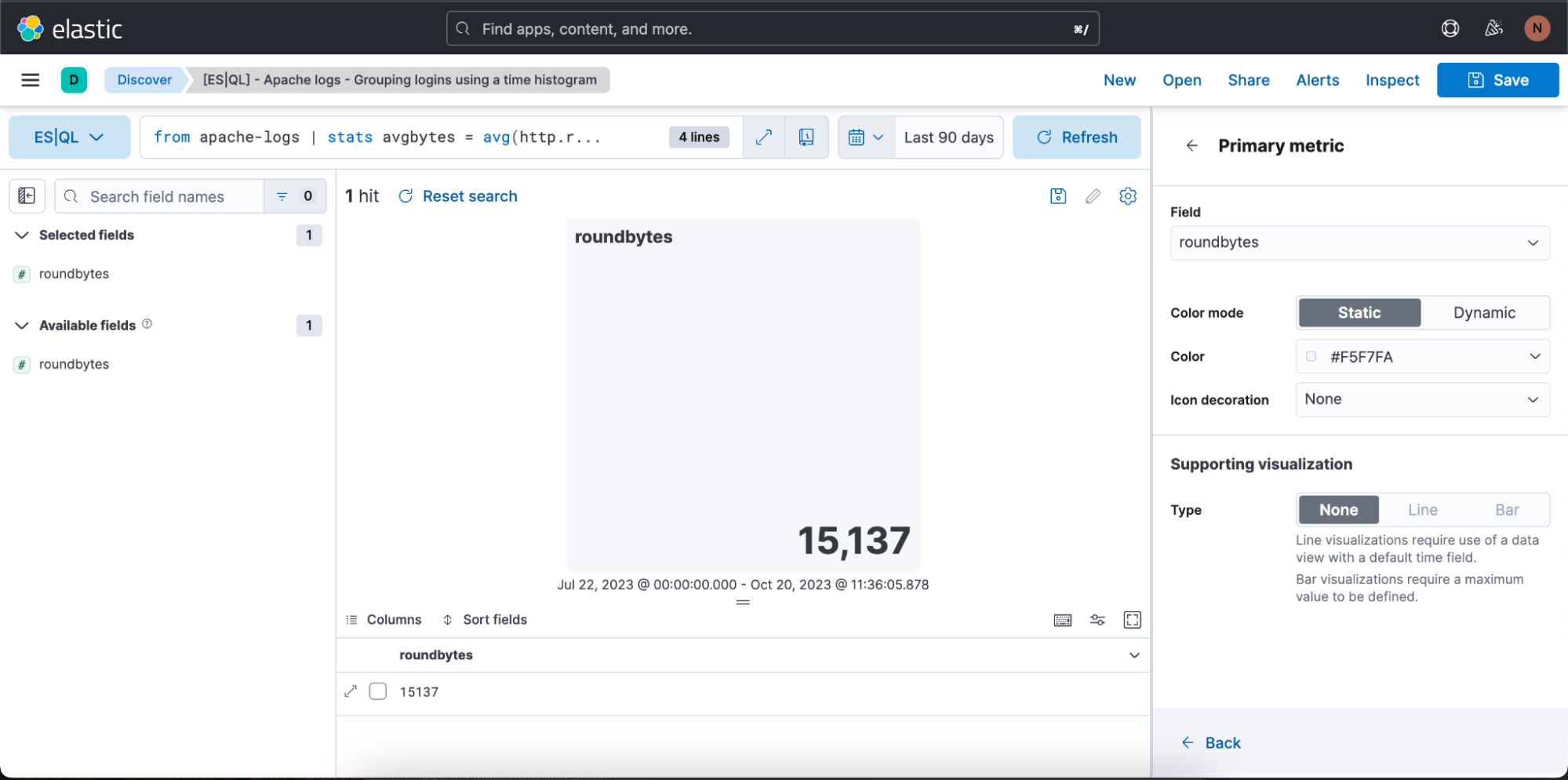
上の例では、ビジュアライゼーションを動的カラーモードにするために[Dynamic](動的)に切り替えています。
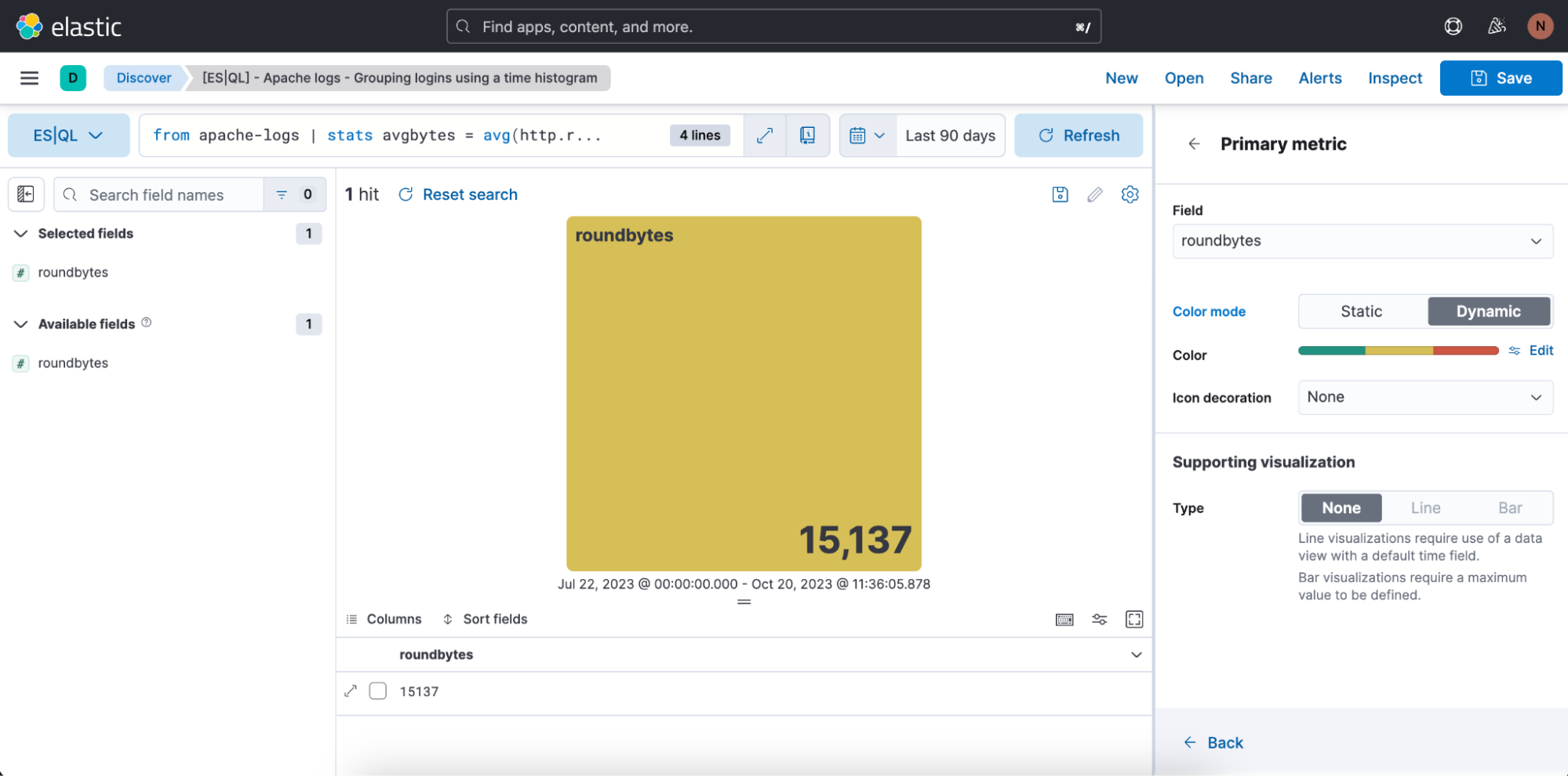
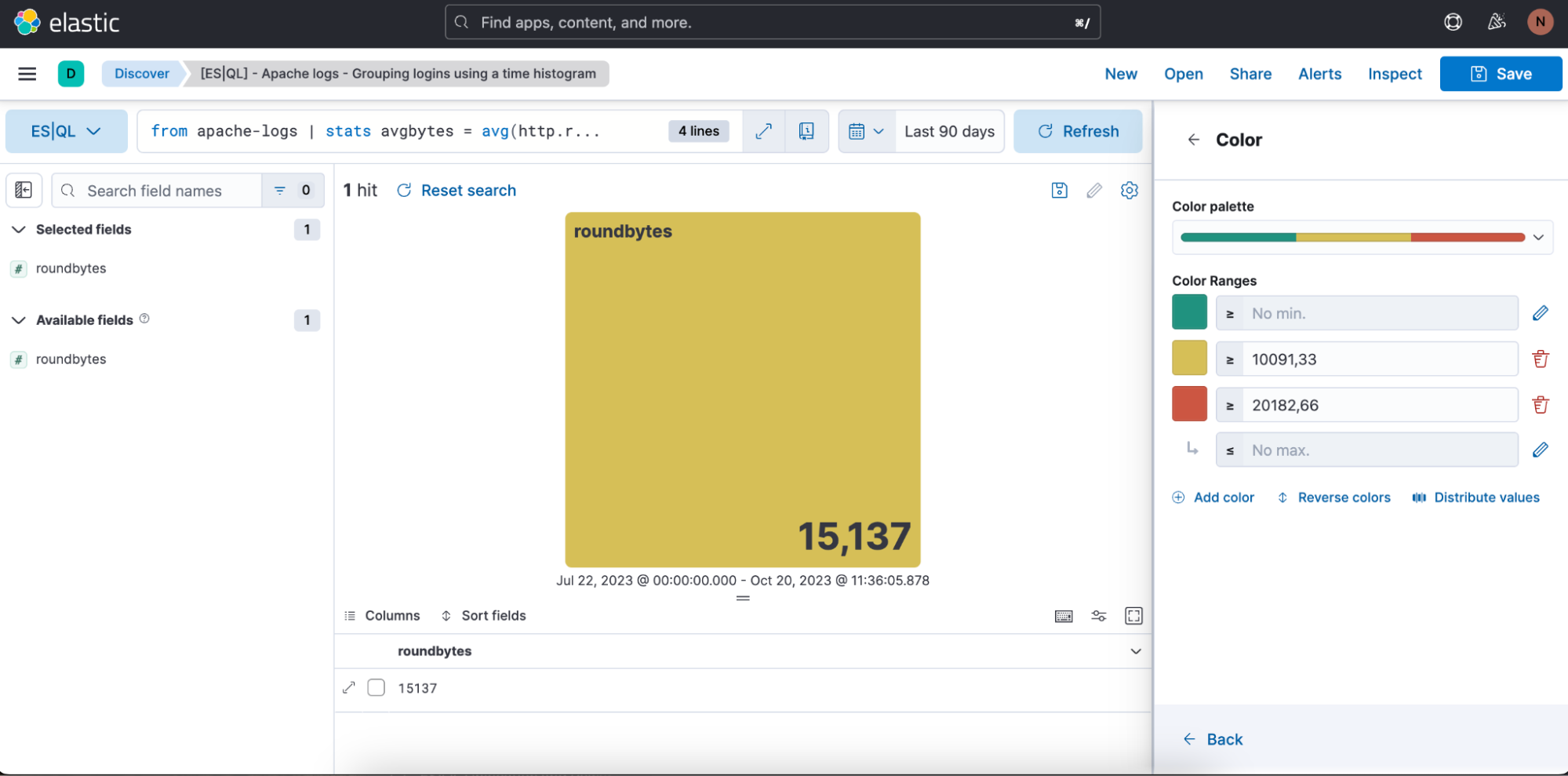
使用する色の範囲を定義することもできます。
手順4. Dashboardに保存する
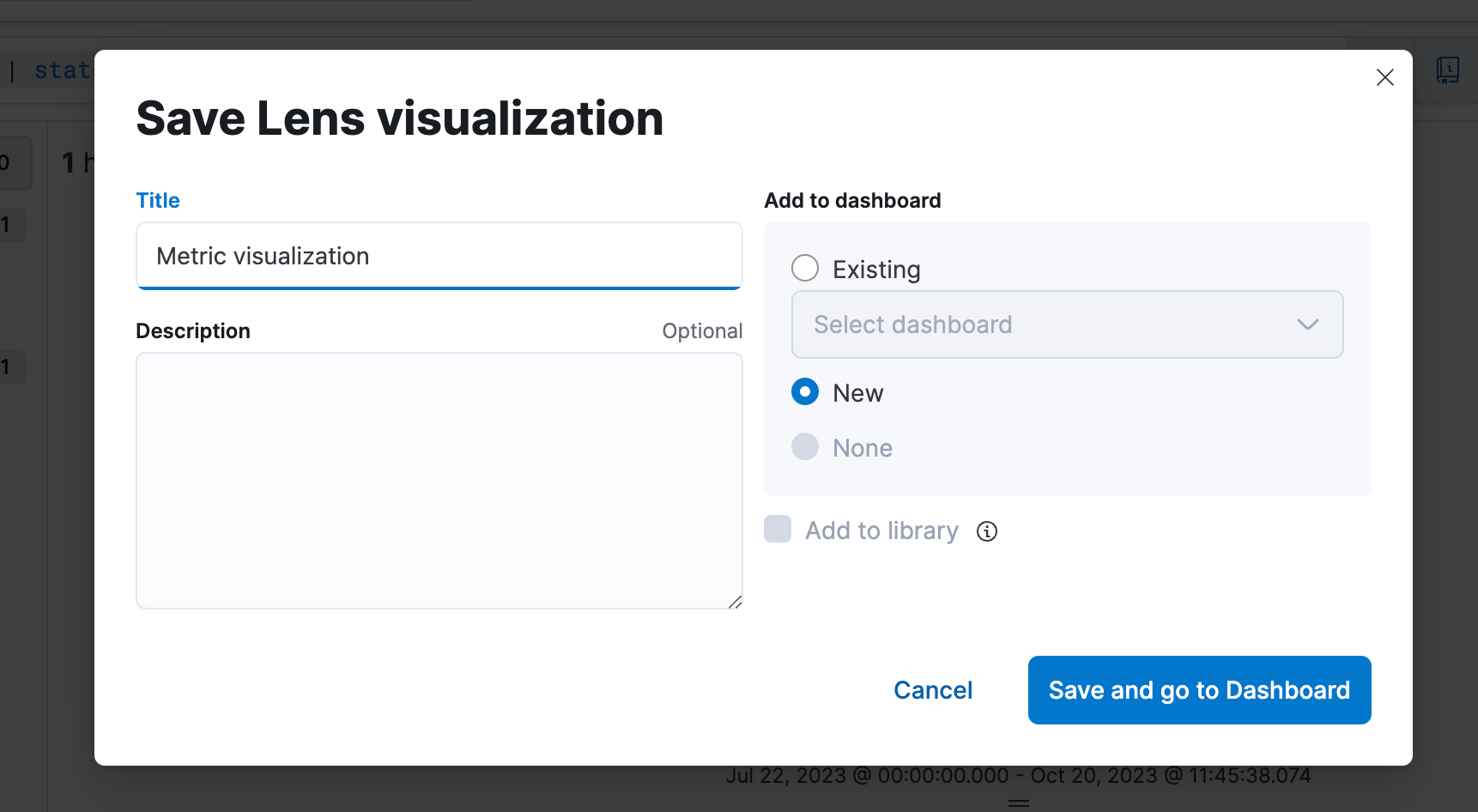
手順5. Dashboardでビジュアライゼーションを編集できるようになる
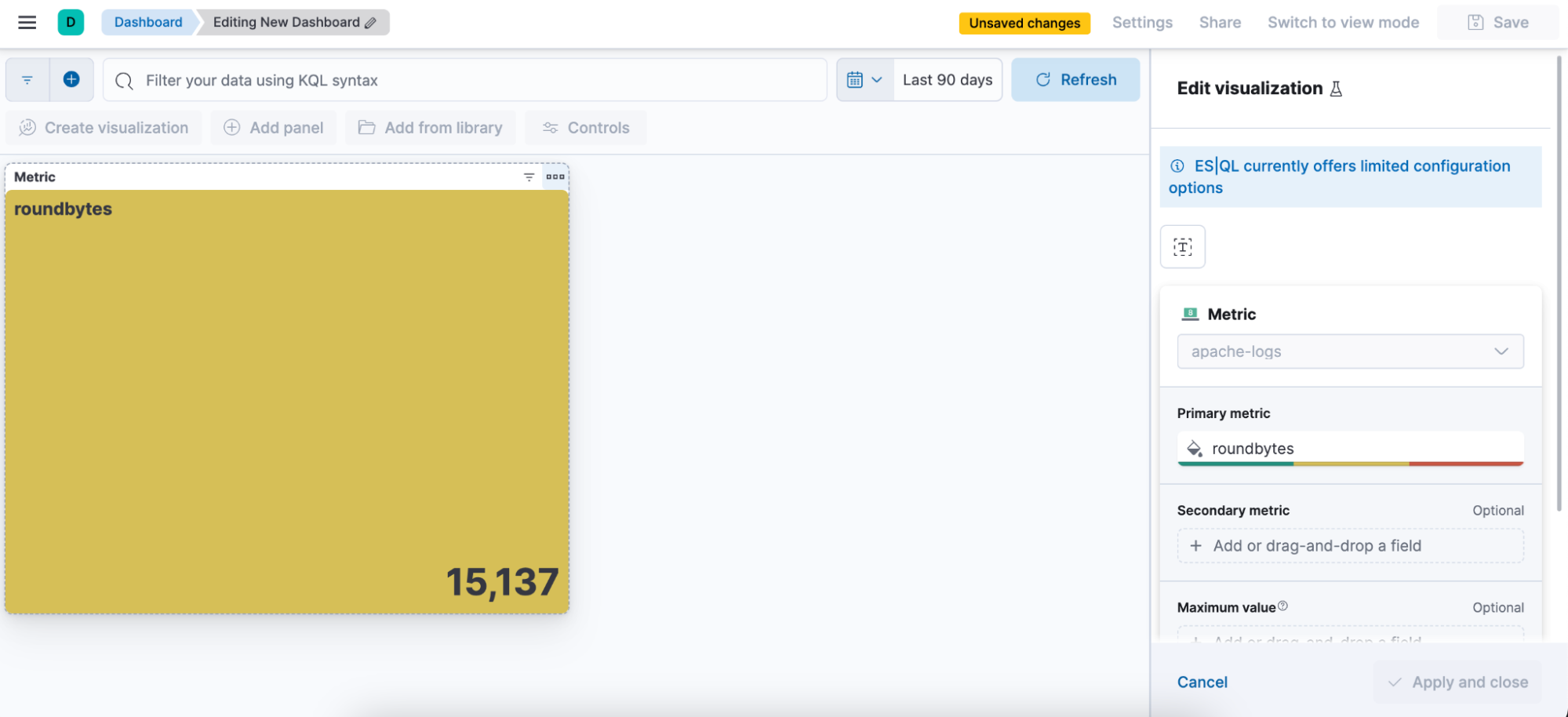
Discoverから直接ES|QLアラートを作成する
ES|QLを使用して、集計値をしきい値に設定したオブザーバビリティアラートやセキュリティアラートを作成できます。切り分けられたインシデントではなく意味のあるトレンドに注目することで誤検知が減り、検知精度を高めて実用的な通知を受け取ることができます。
ここでは、DiscoverでES|QLアラートのルールタイプを作成する方法に絞って解説します。
新しいアラートのルールタイプは、既存のElasticsearchルールタイプに基づいて利用できます。このルールタイプでは、ES|QLに搭載された新しい機能をすべて活用でき、アラートの新しいユースケースの可能性が広がります。
新しいタイプでは、定義したES|QLクエリに基づいてアラートを1件だけ生成し、ルールを保存する前にクエリの結果をプレビューで確認できます。クエリで空の結果が返された場合は、アラートは生成されません。
アラート用のクエリの例:
from metrics-pods |
stats max_cpu = max(kubernetes.pod.cpu.usage.node.pct) by kubernetes.pod.name|
sort max_cpu desc | limit 10
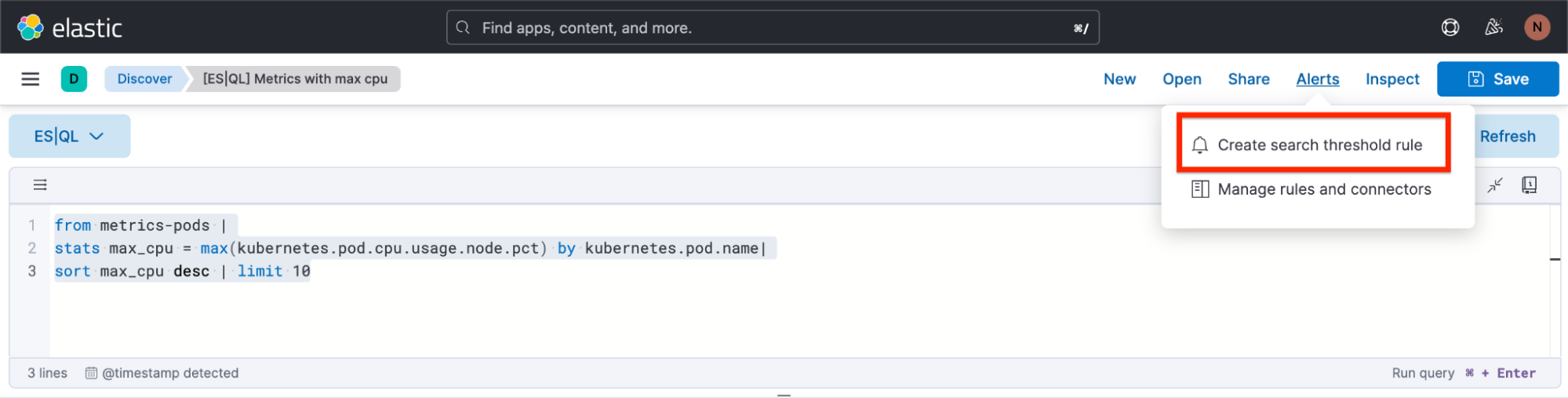
Discoverからアラートを作成する方法
手順1. [Alert](アラート)をクリックし、[Create search threshold rule](検索しきい値ルールの作成)を選択します。 ES|QLアラートのルールタイプの作成は、クエリバーでES|QLクエリを定義した後でも、ES|QLクエリを定義する前でも開始できます。クエリの定義後に作成を開始する場合には、クエリが自動的に[Create Alert](アラートの作成)フライアウトに貼り付けられるというメリットがあります。
手順2. ES|QLアラートのルールタイプの定義を始めます。
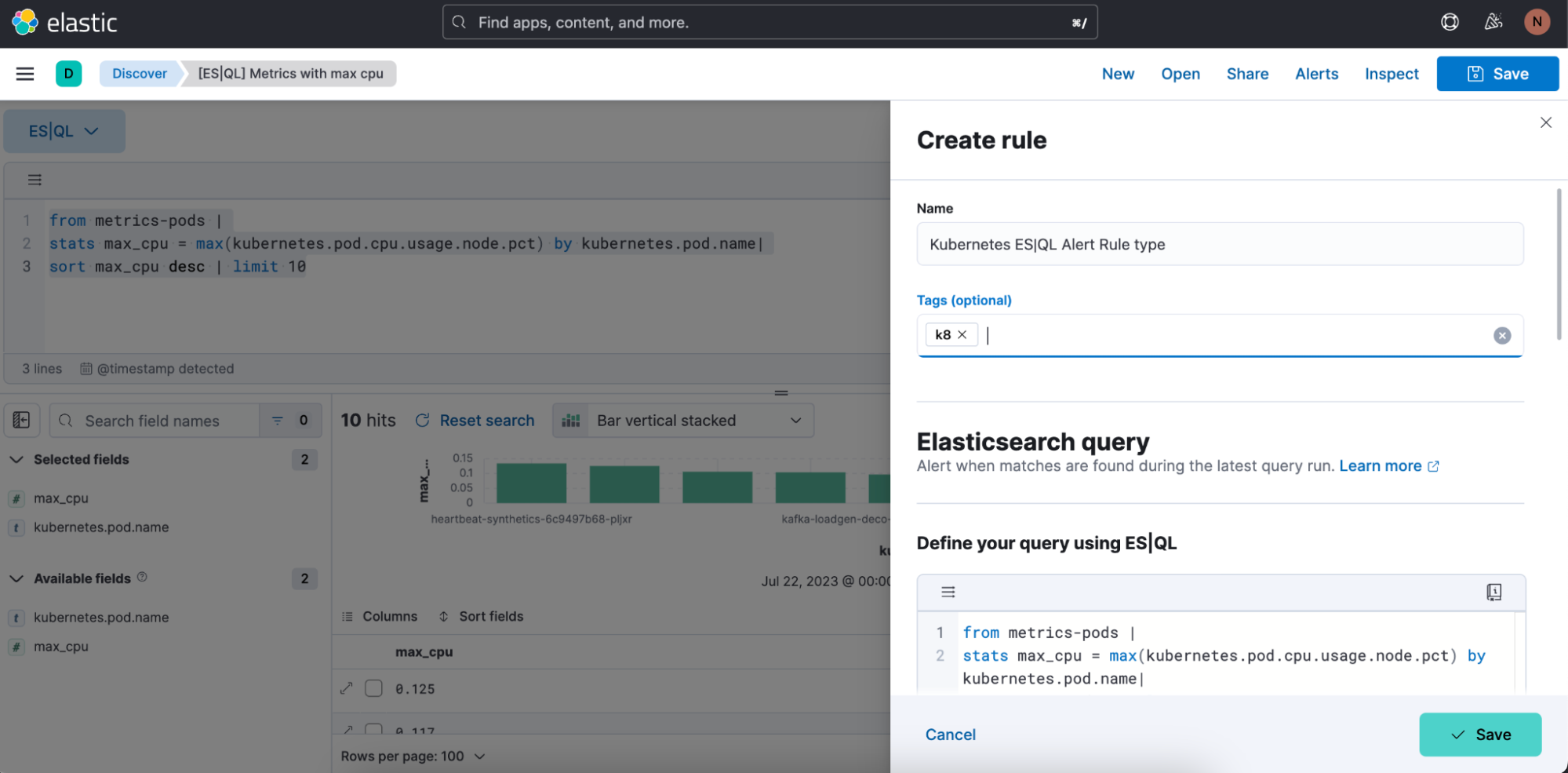
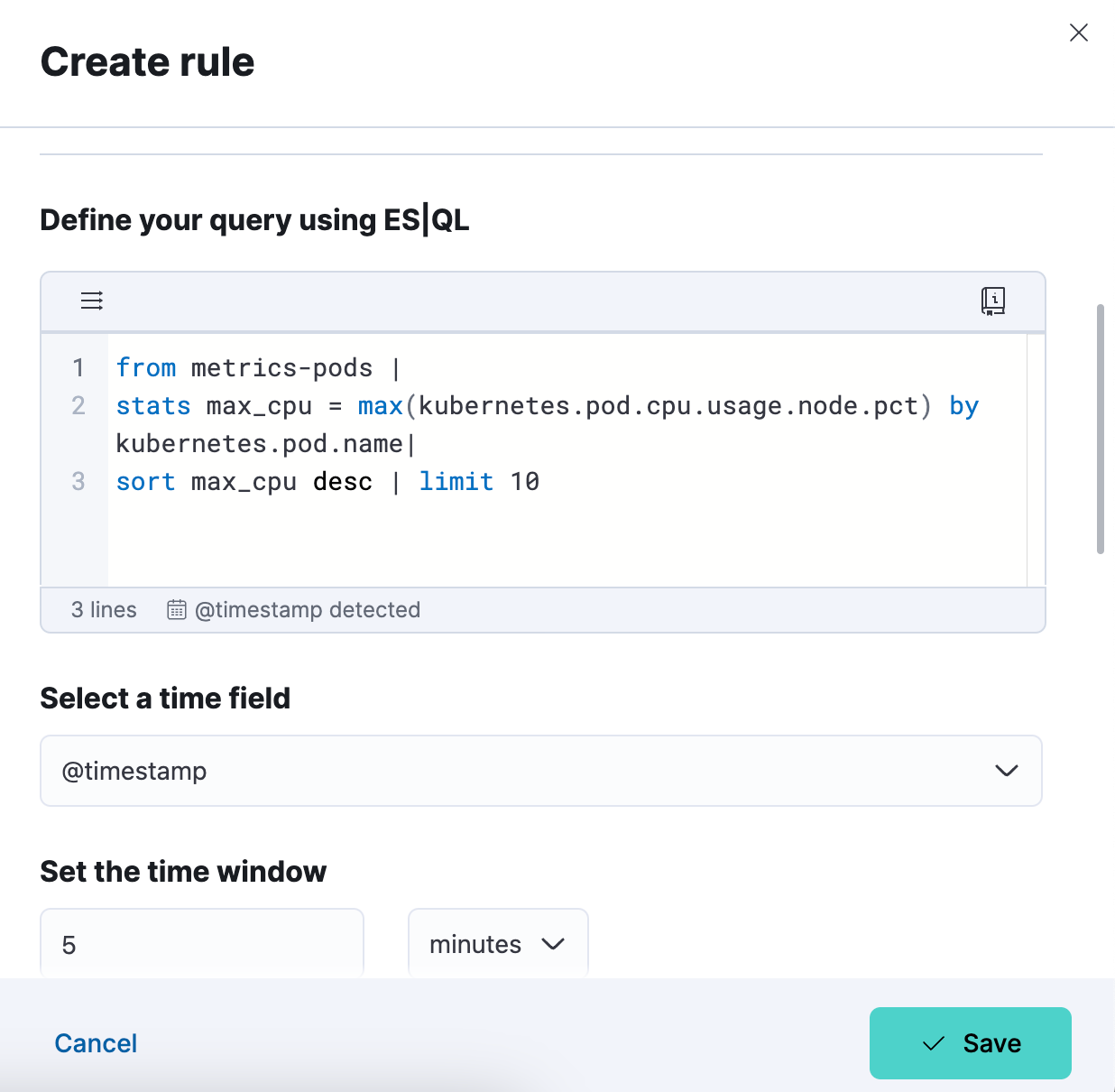
手順3. アラートのルールタイプクエリをテストします。[Test query](クエリのテスト)をクリックすると、貼り付けられたES|QLクエリを繰り返しテストできます。 結果は表形式でプレビュー表示されます。
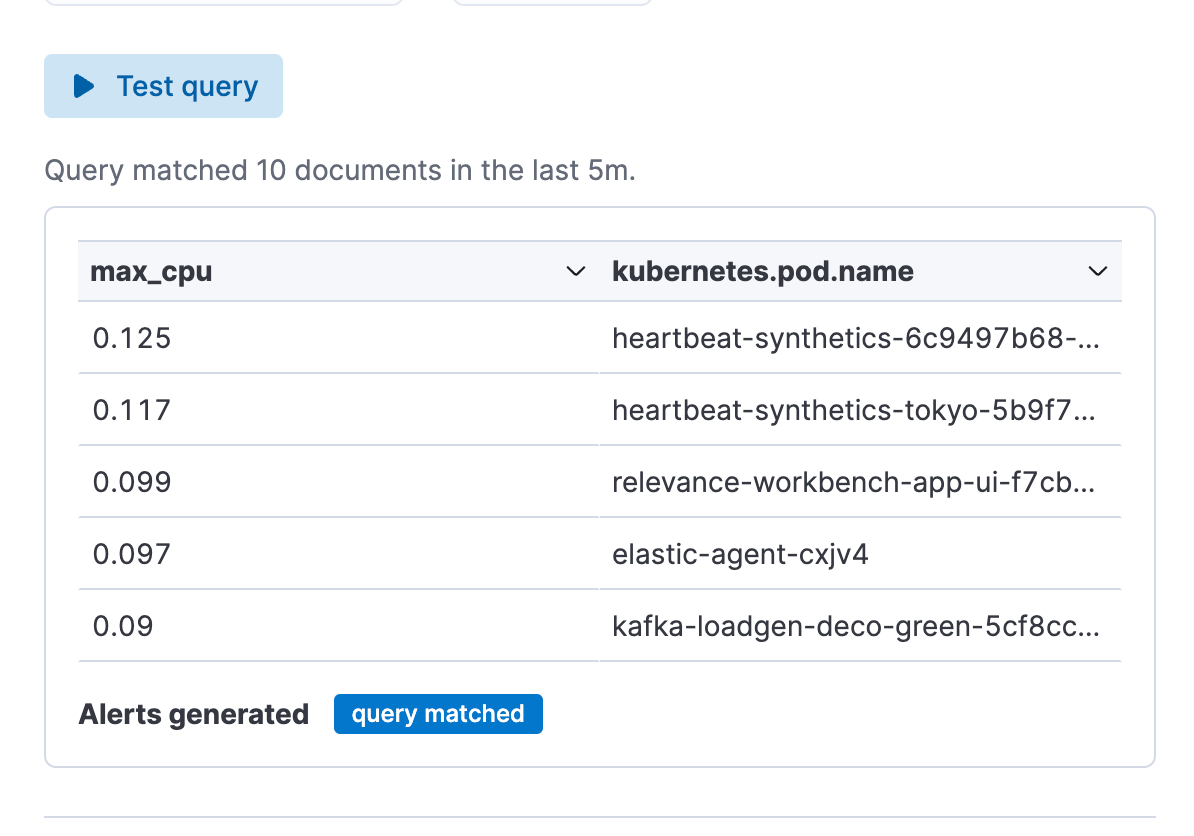
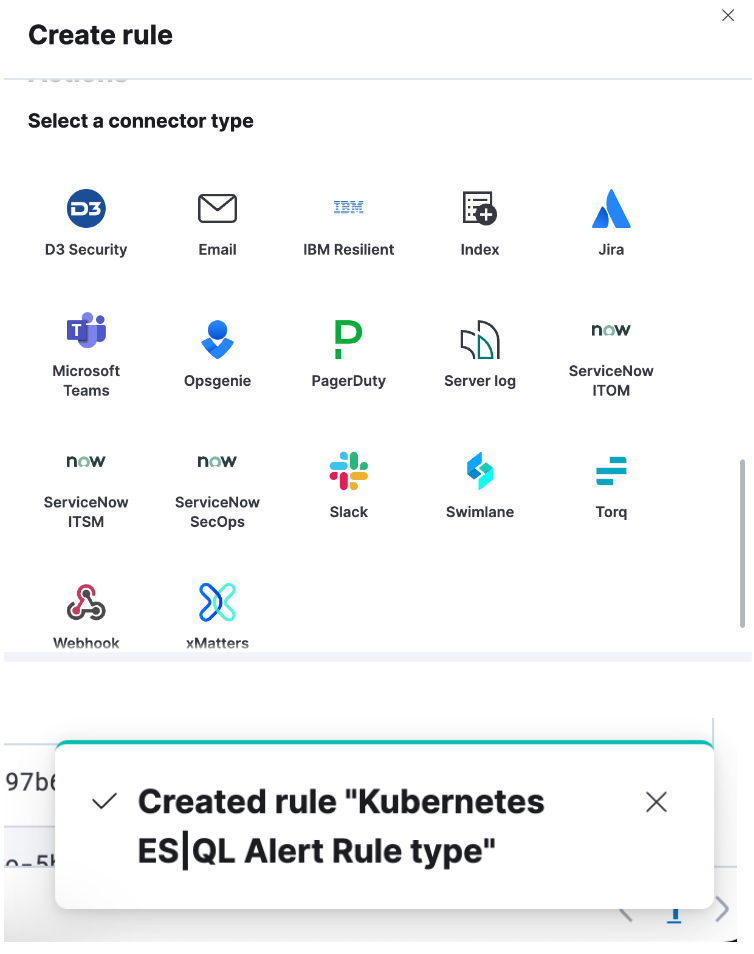
手順4. コネクターを設定して[Save](保存)をクリックします。 これでES|QLアラートのルールタイプが作成されました。
クエリデータセットを別のデータセットのフィールドでエンリッチする
enrichコマンド(ドキュメント)を使用すると、クエリデータセットを別のデータセットのフィールドでエンリッチし、選択したポリシーのコンテクストに合ったサジェスト(一致するフィールドやエンリッチされた列のヒント表示など)で補完できます。
下のenrichを使用したクエリの例では、クエリを介してエンリッチポリシー「servers-to-project」が使用され、name、server_hostname、costでデータセットがエンリッチされています。
from projects* | limit 10 |
enrich servers-to-project on project_id with name, server_hostname, cost |
stats num_of_servers = count(server_hostname), total_cost = sum(cost) by project_id |
sort total_cost desc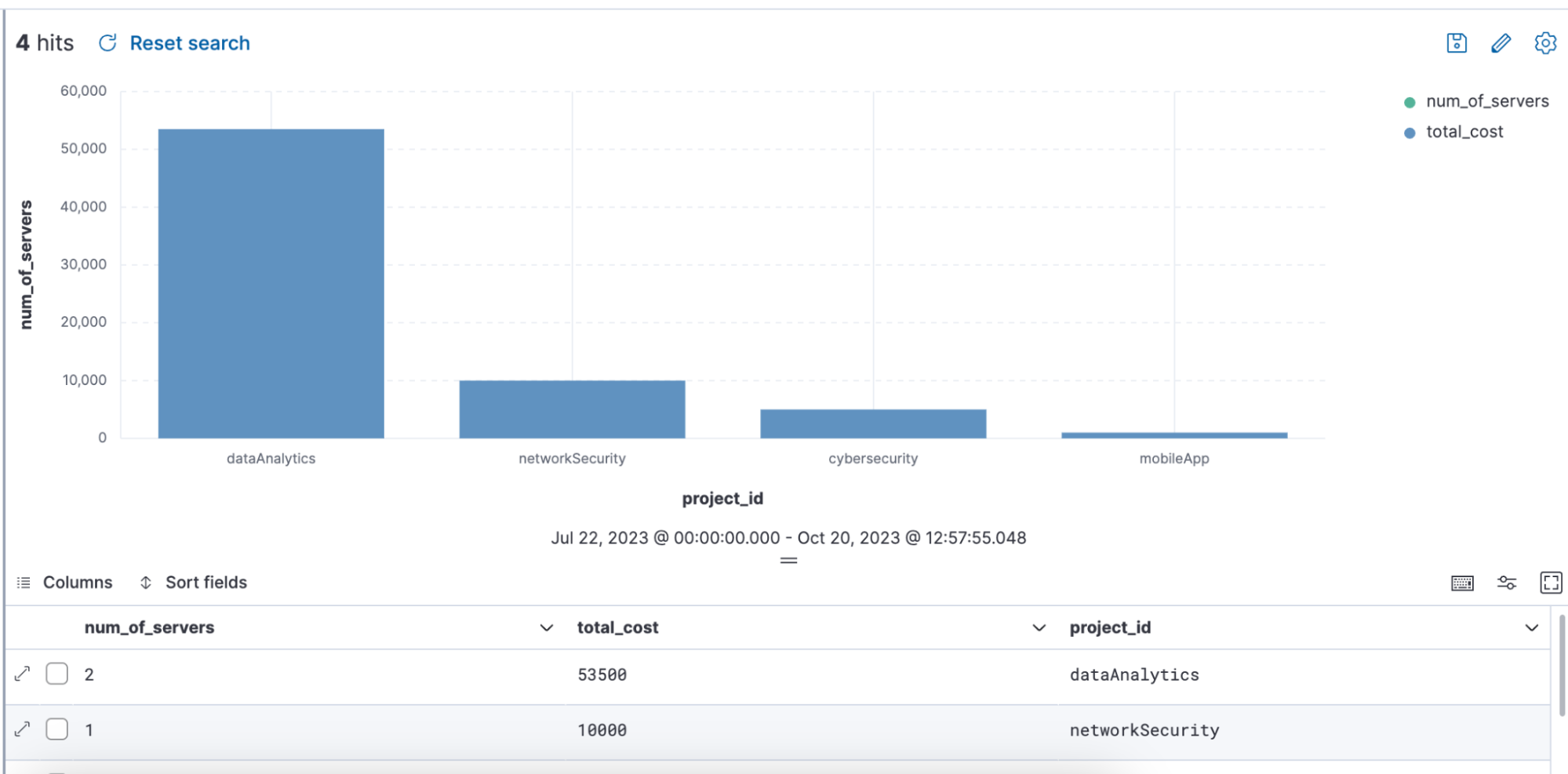
また、簡単にエンリッチポリシーを作成できるように、概要やエンリッチポリシー作成ウィザードも追加されました。
エンリッチポリシーの概要は、[Stack Management](スタックの管理)>[Index Management](インデックスの管理)の順に移動した先の、[Enrich Policies](エンリッチポリシー)というタブのところにあります。
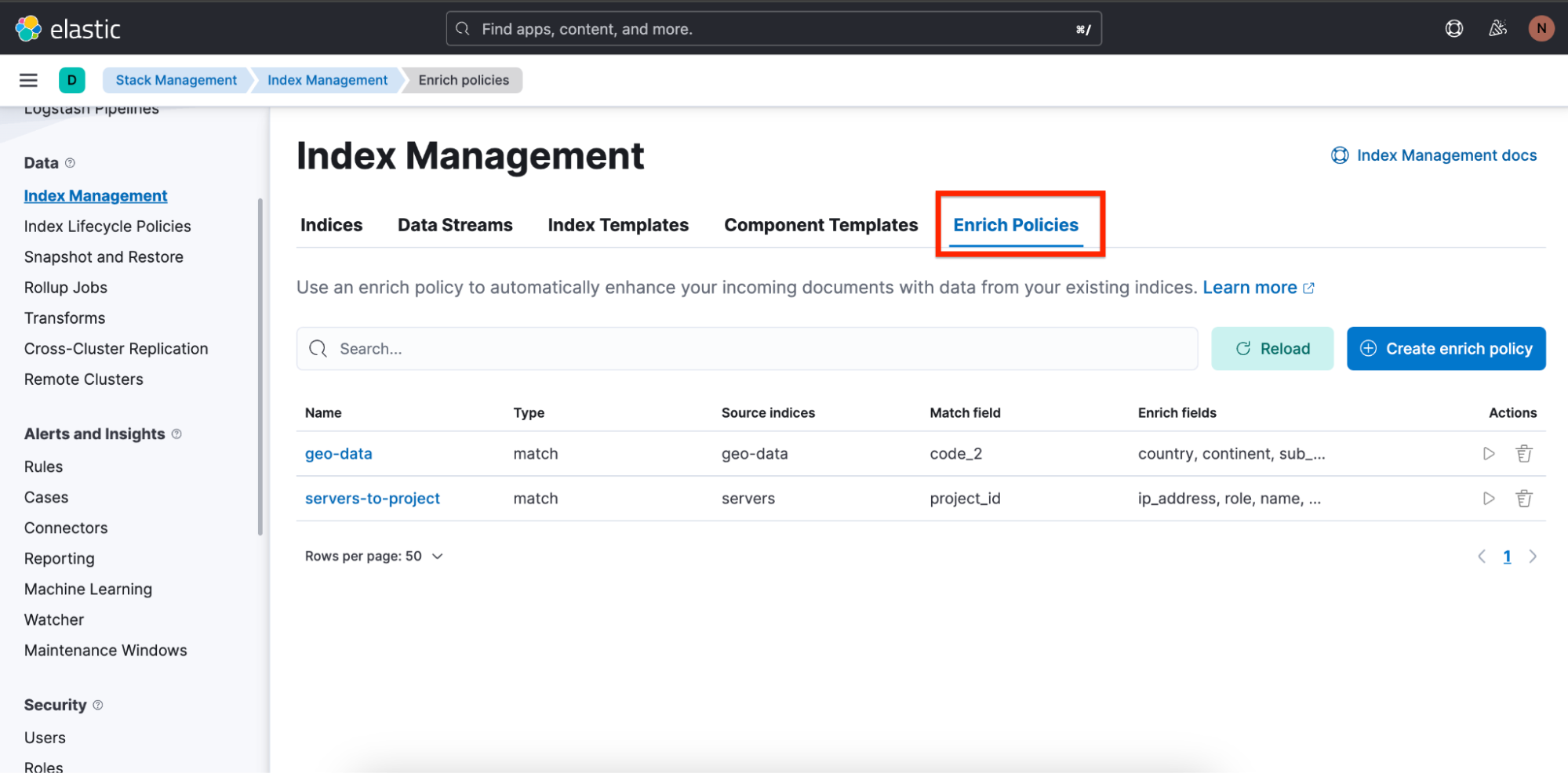
画像には、上のクエリで使用されている「servers-to-project」というエンリッチポリシーが見えます。
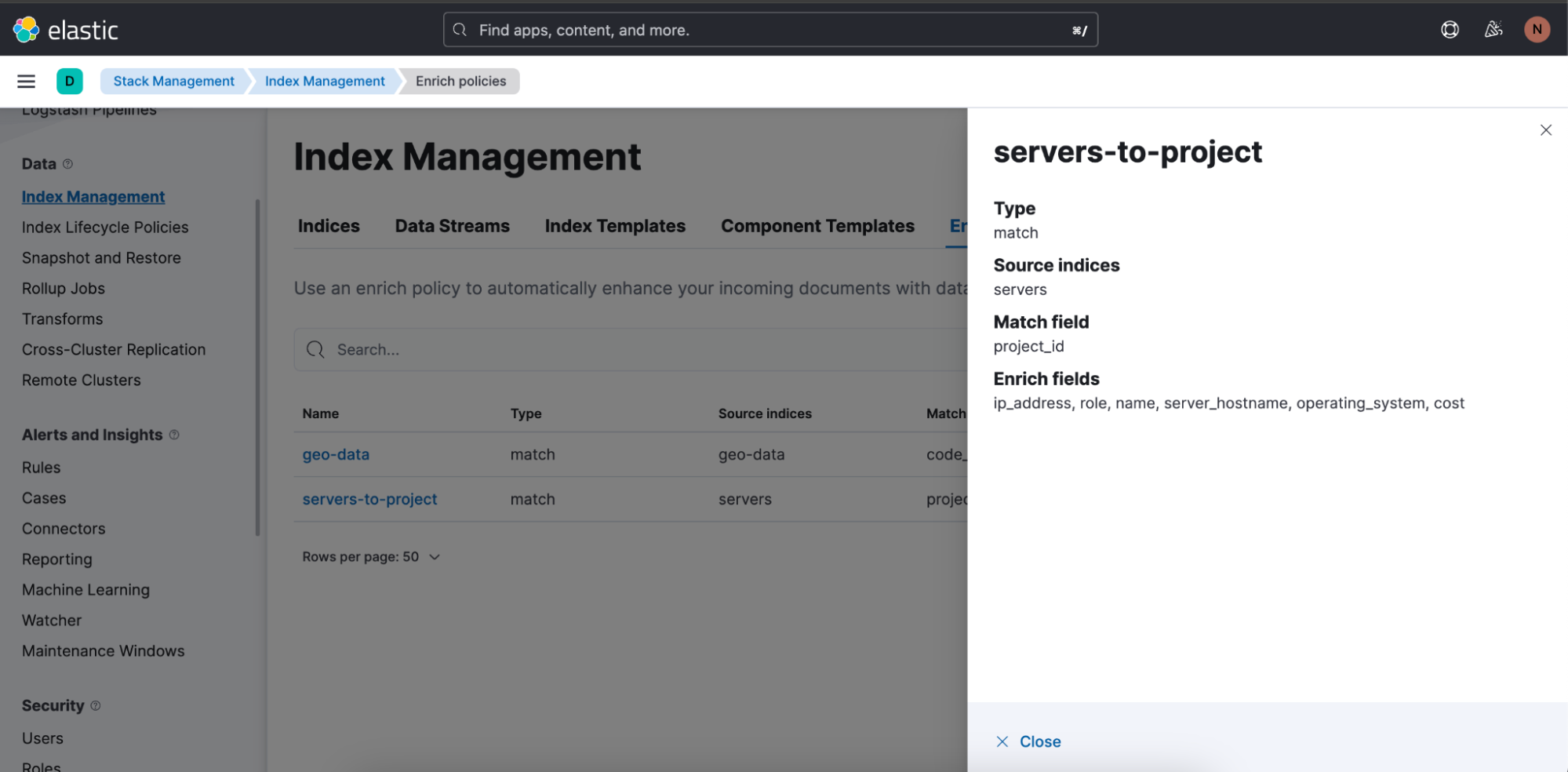
新しいエンリッチポリシーは、[Create enrich policy](エンリッチポリシーの作成)をクリックすると作成できます。エンリッチポリシーを作成して実行すると、すぐにDiscoverのES|QLクエリで使用できるようになります。
データ探索をレベルアップ:ES|QLの能力と約束
ES|QLは、データ分析とデータ探索に進化をもたらす、Elasticの最新イノベーションです。単にデータを表示するだけではなく、データを理解しやすく、実用的で、視覚にも訴えるものにするために開発されました。高速の分散型専用クエリエンジンを搭載し、新しいパイプ型言語として設計され、統一感のあるデータ探索エクスペリエンスが提供されるES|QLは、サイトリライアビリティエンジニア(SRE)、DevOps、脅威ハンター、その他の各種アナリストといったユーザーが抱える課題にマッチします。
ES|QLは、SREがシステムの非効率性を効果的に解消できるようにし、DevOpsが確実に質の高いデプロイを行えるようにし、脅威ハンターにセキュリティ上の潜在的な脅威をすばやく見極めるためのツールを提供します。Dashboardと直接統合されているため、インラインビジュアライゼーション編集、アラート機能、enrichコマンドなどの機能により、シームレスで効率的なワークフローを実現できます。ES|QLのインターフェースは、パワフルさと使いやすさを兼ね備えていて、ユーザーはデータを深く掘り下げることができ、分析はよりシンプルでありながら豊富なインサイトをもたらすものになります。ES|QLのリリースは、データ探索エクスペリエンスの強化と、ユーザーコミュニティの高度化するニーズに関するElasticの取り組みの延長線上にあります。
ES|QLのすべての機能を今すぐお試しいただけます。Elasticトライアルアカウントにご登録いただくか、パブリックデモ環境でお試しください。
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷