NLPの固有表現抽出をデプロイする方法の例


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
本記事は、自然言語処理(NLP)に関する連載シリーズの一部です。今回は固有表現抽出(NER)NLPモデルを使って、非構造化テキストフィールド内にある事前定義済みカテゴリの固有表現を特定して抽出する例を紹介します。はじめに、一般に公開されているモデルをElasticsearchにデプロイします。次に、新しい_infer APIを使用して、テキスト内の固有表現を検索します。そして、NERモデルをインジェストパイプラインの中で使用して、ドキュメントがElasticsearchにインジェストされたときに固有表現を抽出します。
NERモデルは、自然言語を使用して、全文フィールドから人、場所、組織などの固有表現を抽出したいときに役立ちます。
本記事では、例として『レ・ミゼラブル』の英語版からいくつかの段落をNERモデルに渡して、そのモデルを使ってテキストから登場人物と場所を抽出して、それらの関係を可視化します。
NERモデルをElasticsearchにデプロイする
最初に、テキストフィールドから登場人物と場所の名前を抽出できるNERモデルを選択する必要があります。ありがたいことに、Hugging FaceでNERモデルがいくつか公開されており、そこから選ぶことができます。Elasticのドキュメントを確認してみると、Elasticが公開している、大文字と小文字を区別しないNERモデルを使えそうです。
使用するNERモデルを選択できたら、Elandを使ってそのモデルをインストールします。この例では、DockerイメージからElandコマンドを実行しますが、そのためには、まずElandのGitHubリポジトリをクローンしてDockerイメージをビルドし、クライアントシステムにElandのDockerイメージを作成する必要があります。
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
ElandのDockerクライアントの準備ができたら、新しいDockerイメージでeland_import_hub_modelコマンドを使ってNERモデルをインストールします。具体的には、以下のコマンドを実行します。
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startELASTICSEACH_URLは、実際のElasticsearchクラスターのURLに置き換えてください。URLには、認証のために、管理者のユーザー名とパスワードをhttps://username:password@host:portの形式で含める必要があります。
eland importコマンドの最後に--startオプションを使用しているため、Elasticsearchは利用可能なすべての機械学習ノードにモデルをデプロイし、メモリにモデルを読み込みます。モデルが複数あり、デプロイするモデルを選択したい場合は、Kibanaの[Machine Learning](機械学習) > [Model Management](モデル管理)ユーザーインターフェースを使用して、モデルの開始と停止を管理できます。
NERモデルをテストする
デプロイしたモデルは、新しい_infer APIを使用して評価することができます。入力は、分析したい文字列です。以下のリクエストのtext_fieldは、モデルに入力を渡すフィールド名です。このフィールドは、モデルの構成であらかじめ定義されています。モデルがElandを使用してアップロードされた場合、入力フィールドはデフォルトでtext_fieldになります。
Kibanaの開発ツールコンソールで、以下の例を試してみてください。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
モデルによって、人物「Josh」と場所「Berlin」という2つの固有表現が検出されました。
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_valueは、注釈付きテキスト形式の入力文字列です。class_nameは予測されるクラスで、class_probabilityは予測の信頼度を示しています。start_posとend_posは、特定された固有表現の開始文字と終了文字の位置です。
NERモデルを推論インジェストパイプラインに追加する
_infer APIは、初めて使うには簡単でおもしろいのですが、1つの入力しか受け付けず、検出された固有表現はElasticsearchに保存されません。別の方法として、インジェストパイプラインを使用してドキュメントを取り込み、その際に推論プロセッサーを使用して一括推論を実行することができます。
インジェストパイプラインは、スタック管理UIで定義するか、Kibanaコンソールで設定できます。今回使用するインジェストパイプラインには、下記のように、複数のインジェストプロセッサーが含まれています。
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
inferenceプロセッサーから見ていきましょう。field_mapの目的は、paragraph(ソースドキュメント内の分析対象フィールド)とtext_field(モデルで使用するように設定されたフィールド名)を対応付けることです。target_fieldは、推論結果を書き込むフィールド名です。
scriptプロセッサーでは、固有表現を取り出して、タイプ別にグループ化します。最終的には、入力テキストから検出された人物、場所、組織のリストが出来上がります。このPainlessスクリプトを追加することで、作成されたフィールドからビジュアライゼーションを構築できるようになります。
on_failure句は、エラーをキャッチするためにあります。ここでは、2つのアクションを定義しています。1つ目のアクションでは、_indexメタフィールドに新しい値を設定します。ここにはドキュメントが格納されます。2つ目では、エラーメッセージが新しいフィールドingest.failureに書き込まれます。推論が失敗する原因はいくつかありますが、いずれも簡単に修正できます。多くの場合、モデルがデプロイされていないか、ソースドキュメントの一部に入力フィールドがないことが原因です。失敗したドキュメントを別のインデックスにリダイレクトし、エラーメッセージを設定することで、失敗した推論を残しておいて、後で見直すことができます。エラーを修正したら、失敗したインデックスから再インデックスして、失敗したリクエストをやり直します。
推論用のテキストフィールドを選択する
NERは、さまざまなデータセットに適用できます。ここでは、例として、ヴィクトル・ユゴーが1862年に著した古典文学『レ・ミゼラブル』の英語版を使用します。使用する『レ・ミゼラブル』の一節として、Elasitcで用意したサンプルJSONファイルをKibanaのファイルアップロード機能を使用してアップロードできます。テキストは、14,021個のJSONドキュメントに分割されており、それぞれに1つの段落が含まれています。例として、無作為に段落を1つ選んで、見てみましょう。
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
この段落がNERパイプラインでインジェストされると、Elasticsearchに保存されるドキュメントに、1人の人物が特定されてマークアップされます。
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
タグクラウドは、単語が出現する頻度によって大きさが変わるビジュアライゼーションです。『レ・ミゼラブル』で検出された固有表現を表示するのに最適なインフォグラフィックです。タグクラウドを表示するには、Kibanaを開き、アグリゲーションベースのビジュアライゼーションを新規作成して、[Tag Cloud](タグクラウド)を選択します。NERの結果が含まれたインデックスを選択し、tags.PER.keywordフィールドに用語アグリゲーションを追加します。
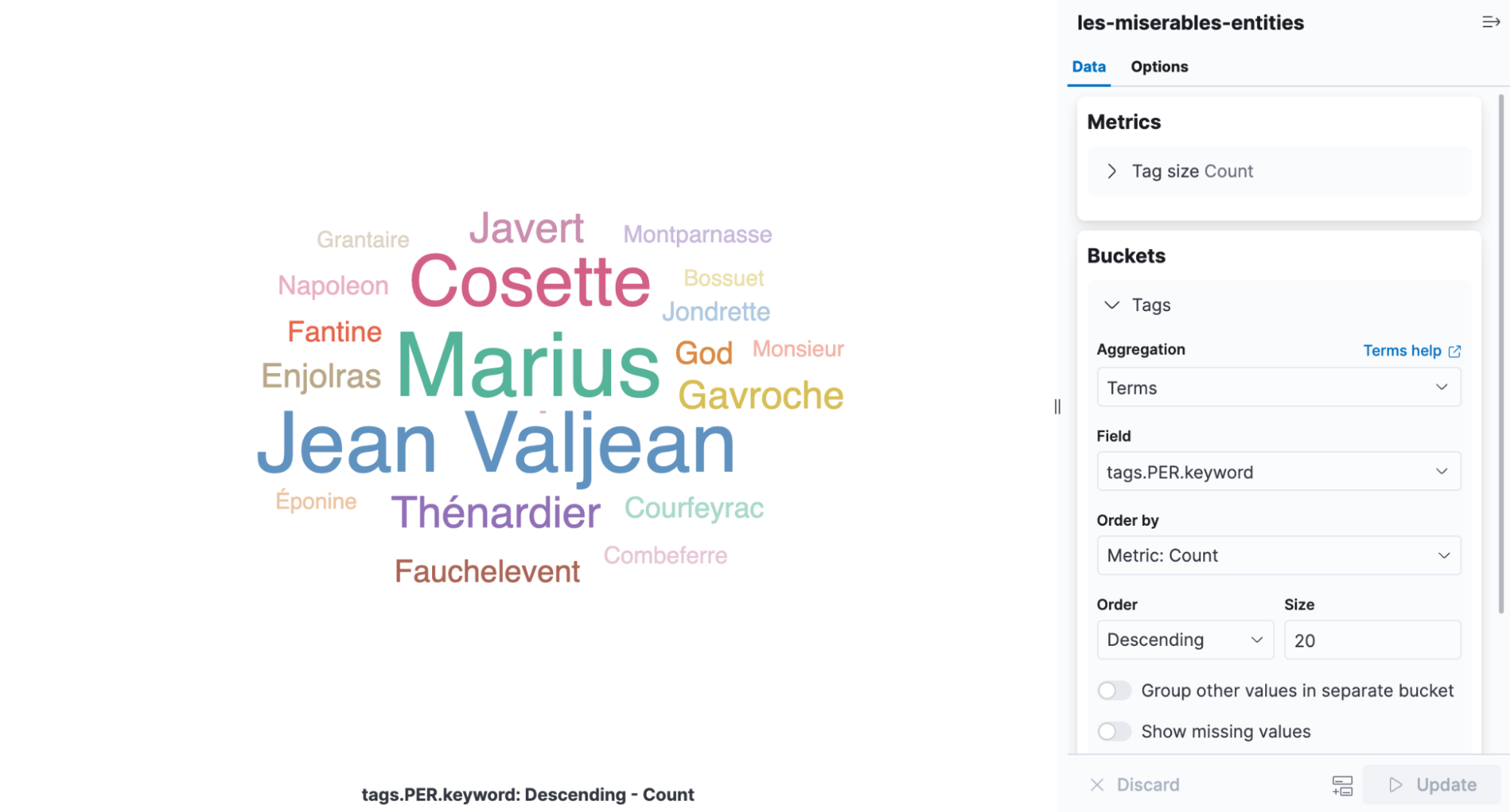
このビジュアライゼーションを見れば、Cosette、Marius、Jean Valjeanが最も頻繁に登場する人物であることがすぐにわかります。
デプロイを調整する
モデル管理UIに戻ると、デプロイの統計情報のところに、平均推論時間が表示されています。これは、1つのリクエストに対して推論を実行するのに要した時間をネイティブプロセスが測定したものです。デプロイを開始する際、inference_threadsとmodel_threadsの2つのパラメーターを使用してCPUリソースの使用方法を制御します。
inference_threadsには、1つのリクエストに対してモデルの実行に使用されるスレッドの数を指定します。inference_threadsを増やすと、ダイレクトに平均推論時間が短縮されます。model_threadsには、並行して評価されるリクエストの数を指定します。この設定では、平均推論時間は短縮されませんが、スループットが向上します。
一般に、inference_threadsの数を増やすことでレイテンシを調整し、model_threadsの数を増やすことでスループットを向上させます。どちらのスレッドも、デフォルトでは「1」に設定されています。これを変更することで十分なパフォーマンスを得ることができます。その効果はNERモデルを使って実証できます。
スレッド設定のいずれかを変更するには、デプロイを停止して再起動する必要があります。デプロイが、本来なら停止できないインジェストパイプラインによって参照されているので、?force=trueパラメーターをstop APIに渡します。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
そして、inference_threadsを「4」にして再起動します。デプロイが再起動すると、平均推論時間はリセットされます。
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4『レ・ミゼラブル』の段落の処理では、スレッドが1つのときはリクエストあたりの平均推論時間が173.86ミリ秒だったのに対して、スレッドが4つのときは55.84ミリ秒に短縮されました。
さらに学び、試してみる
すぐに使えるNLPタスクはいろいろあり、NERはそのうちの1つです。他にも、テキスト分類、ゼロショット分類、テキスト埋め込みなどが可能です。他の例については、こちらのNLPに関するドキュメントで確認できます。すべてを網羅したものではありませんが、Elastic Stackにデプロイできるモデルのリストもあります。
NLPはElastic Stack 8.0の主要な新機能であり、エキサイティングなロードマップも公開されています。最新のリリースや新登場の機能を提供するElastic Cloudにクラスターを構築してご活用ください。本記事でご紹介した手法は、Elastic Cloudの14日間の無料トライアルでもすぐにお試しいただくことができます。
NLPに関するその他の記事はこちらをご覧ください。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷