Elasticsearchで1,000%のパフォーマンス向上を実現
Voxpopmeは世界最大級の学習動画インサイトプラットフォームです。私たちは2013年、"動画は数多くの人々の声を同時伝えることができるもっともパワフルな方法だ"というシンプルな発想からVoxpopmeを設立しました。Voxpopmeのオリジナルソフトウェアは、調査会社のパートナーから送られてきたユーザー録画の動画や長時間のコンテンツ(例:フォーカスグループなど)を受け取り、グラフや閲覧可能なテーマ、カスタマイズできるショーリールなどを作成します。
リリース以来、Voxpopmeは4年をかけて動画から得ることができるインサイトの最適化と自動化を図り、ブランドと消費者の結びつきを妨げるあらゆる障壁を取り除いてきました。クライアントのエクスペリエンスを最大化するためIBM Watsonによる最新の自然言語処理ツールで調査対象者の感情を特定/アグリゲーションし、またAffectiva社の独占的パートナー協力を得て表情に基づく感情分析を実施してきました。そして2017年、クライアントに最高のエクスペリエンスを提供するために加わったツールがElasticsearchです。
レガシーインフラからの脱却
Voxpopmeのテクノロジースタックは、この12か月で大きく変化しました。2017年にVoxpopmeのプラットフォームが処理した調査動画の数は50万本に達し、それまでの4年の数を合計したものと同じ水準になりました。そして2018年、その数字は倍になりました。こうしてたびたびスケーリングの問題が生じ、どちらかといえば嬉しい種類の問題ではあるものの、対応に追われることになりました。
問題の出所は社内のレガシーシステムでした。PHPアプリケーションで画一的に構成され、中核的な機能を果たすため、複数の異なるデータベースと通信していました。当時、データを分類するロジックは次のようなものでした。
- データの大部分をMySQLデータベースに格納。たとえばユーザーや、個々の動画のレスポンスといったデータなどが含まれ、構造化されたリレーショナルデータを外部キーと共にリンクし、RESTful APIで作成、読み取り、更新、削除する。
- クライアントデータはMongoDBクラスターに格納され、どのような形式でも受け入れる。これによりユーザーは好きな用語を使用して、タグや注釈をつけたり、絞り込みを行うことが可能。
- さらに動画中の対象者のトランスクリプト(発言の書き起こし)を小規模なElasticsearchクラスターに格納し、全文テキスト検索を使用。
何年もの間、このアプローチは非常にうまく行っていました。しかしここには、大きな問題がありました。
演算処理能力は無料でも、無限でもない
Voxpopmeのプラットフォームで行われる検索は、シンプルなものから、非常に複雑なものまでさまざまです。比較的シンプルなケースでは、ユーザーは動画レスポンスのプライマリキーから検索します。インデックス済みのMySQLデータベースにクエリをかけるだけの検索です。
しかし、ユーザーがインデックス済みインテジャーと独自のフリーフォームデータでフィルターをかけ、特定の話題に言及したすべての対象者の結果に絞り込みたいと考えたらどうでしょう?たとえばこのような感じです。
調査日が6月1日から6月30日で、対象者の世帯年収が10万ドル-12.5万ドルの範囲にあり、「高すぎる」という発言をしたすべての記録を見つける
以前のアプローチはこうでした:
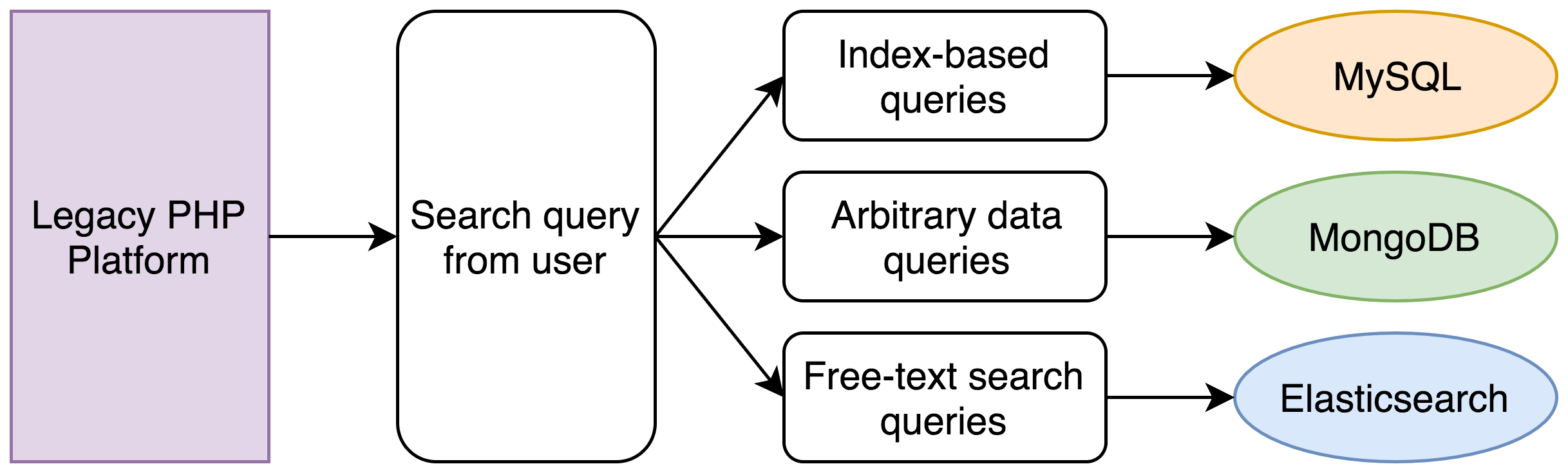
レガシーシステムでは、次の処理を実施します。
- MySQLで、該当の日付範囲にあるすべての記録を見つける
- MongoDBクエリで世帯年収が該当範囲にあるすべての記録を見つける(世帯年収は一例です。調査会社は、任意の情報を格納しています)
- Elasticsearchクエリが、トランスクリプト中の一致する発言をすべて見つける
- 3つの記録から、重複するIDを算出する
- MySQLとMongoDBで新しいクエリを実行し、各記録の完全なデータセットを取得する
- 記録を並べ替え、paginate処理(複数ページに分割)する
シンプルな検索クライテリアですが、5つの異なるデータベースをクエリを使用しました。当初は1秒程度で運用できていましたが、PHPはシングルスレッドであるため、クエリを1つずつ直列に処理します。5年分のデータが蓄積された時点で、この処理に最長で30秒もかかるようになっていました。
このモデルはVoxpopmeを迅速に市場に送り出し、何年もの間非常に良く機能していました。ただ、スムーズにスケールさせることができるモデルではなかったのです。ユーザーエクスペリエンスに影響が出始めていることに気づいた開発チームは、検索メカニズムを書きなおすことを決断しました。
Voxpopmeは従来のロジックですでにElasticsearchを使用していました。そこでElasticのセールスマネージャーに相談し、直面している問題や、複数の場所にある多様なデータ全体にわたって複雑な検索を実施していることを説明しました。最も重要となるのは、適切なソリューションを見つけることです。データをすばやく、効率的に表示して算出できることがプロダクトの魅力であり、データの取得にボトルネックが生じることは許されません。
当初はMongoDBクラスターの拡張も選択肢の1つでした。しかしElasticの担当者と手短な電話を終えた私たちは、Elasticsearchがデータの格納から検索、操作(アグリゲーションなど)まで簡単にこなせる唯一のソリューションだという結論に達しました。
ファーストインプレッション
以前使用していたElasticsearchクラスターは、Compose.ioで取得したバージョン1.5でした。Voxpopmeは他のインフラですでに大規模にAWSへ投資していたことから、まずAmazon Elasticsearch Serviceでバージョン5.xのクラスターをデプロイすることにしました。
新しいモデルでは、フリー形式というトリッキーなクライアントのデータに対して既知のキーでネストした値を使用し、さまざまなデータからなる記録を1つのElasticsearchドキュメントに入れます。これでユーザーがどのような検索を行っても、1つのElasticsearchクエリで処理することができます。
1週間以内に、数千ほどのドキュメントで基本的な概念実証が行われました。Kibanaでクエリを実行した際のファーストインプレッションは非常に良く、バックエンド検索メカニズムの全面的な書き直しも喜んでやりたいとチームが意気込んだほどでした。
新しいアプローチは次の図の通りです。
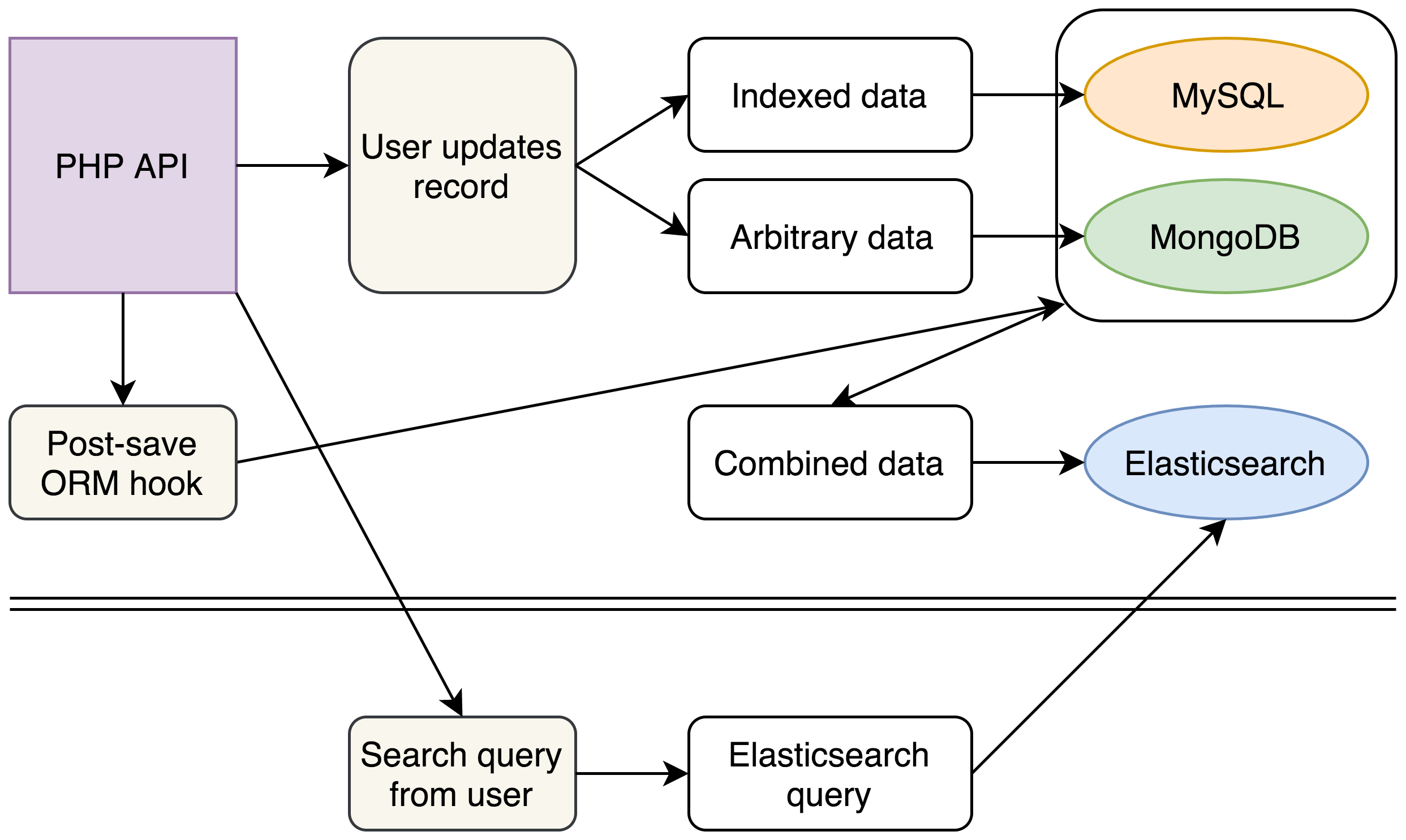
(レガシーのデータベースにはまだ変更は行われていません。複雑な検索を実行できる新しいElasticsearchクラスターの導入が完了したことで、今後MongoDBはVoxpopmeのスタックから完全に削除される予定となっています)
新しいスタックでもMySQLによる記述とMongoDBの使用が継続されました。各記述は別のイベントをトリガーすることでさまざまなソースから全データを収集・フラット化し、1つのJSONドキュメントに入れ、その後Elasticsearchに挿入されます。
同時にバックエンドでは、ユーザーによる既存の検索リクエストから複雑なElasticsearchクエリを構築し、MySQLとMongoDBをクエリするレガシーのコードを削除するための新しい検索メカニズムの記述に開発チームが着手していました。1つのElasticsearchクラスターでクエリできれば、同じデータでも数分の1の時間で取得でき、
Elasticsearchドキュメントの構造によるメリットもあります。既存のAPIはJSONドキュメントを返します。そこでElasticsearchドキュメントを既存のAPIアウトプットと完全に一致させる形で構築し、これまでMySQLとMongoDBから来るデータの結合と再構築化にかかっていた数秒の時間も短縮させました。
この時点で、Voxpopmeはプラットフォームの主要部分で1,000%の基本パフォーマンス向上が見込まれることを事業のさまざまな関係者に報告できました。
"これはおまえさんたちが探してるプロバイダーじゃない"
1,000%のパフォーマンス向上を宣言したVoxpopmeの次の任務はすべてのデータをインデックスすること、そしてサービスの停止日数を最少に留めることでした。
こうしてすべてのデータをAWSクラスターにインデックスしましたが、残念なことに、うまくいきませんでした。
データを1度インデックスした後で何度もクエリするというシンプルなモデルなら、問題が起きる可能性はほとんどありません。しかし、このモデルはMySQLやMongoDBでアップデートがあるたびにデータを結合し、再インデックスするというものです。検索が主に実行される期間中、数千回もこの処理が発生する可能性があります。
開発チームはこれがパフォーマンスに影響し、クエリ時間が数秒にまで落ち込むことを突きとめました。このロジックには2つの側面があり、PHPアプリケーションをロックアップしてしまう可能性もある一方、MySQLの接続をオープンに保つことができる利点もあります。しかし悪影響が連鎖的に生じれば、スタック全体が反応を停止する恐れがありました。
この問題が発覚したころ、ロンドンでElastic{ON}ツアーが開催され、チームがAMAブースでElasticの担当者とクラスターサイズやこの問題について話す機会がありました。クエリタイムが最高で40ミリ秒程度だったことを伝えると、Elasticの担当者はAWSの代わりにElastic Cloudを使うことを提案しました。Elastic Cloudなら、デフォルトの設定でレスポンスタイムが1ミリ秒近くまで短縮できるということでした。
さらにElastic Stackの有償オプション(旧X-Pack)が使えることもElastic Cloudの大きなメリットでした。当時AWSではロギングやグラフのシステムで限られた機能しか使うことができなかったためです。AWSのElasticsearch ServiceにX-Packがなかったことから、Voxpopmeでは複数の比較テストを行ってElastic Cloudクラスターへ移行することを決断しました。すなわち、少なくともAWSクラスターと同等のパフォーマンスを確認することができれば、他のメリットを考慮して切り替えることができます。
Elastic CloudはUIが非常にクリーンで、使いやすくできています。インデックス中、データ処理者の追加に伴いスケールを行う必要がありましたが、クラスターの管理操作があまりに簡単なことにチームは衝撃を受けました。つまり、スライダーを左右に動かし、[Update]をクリックするだけでした。
新しいクラスターにデータをインデックスする作業は成功し、複雑なクエリでもロックアップをほぼ生じさせず、2ミリ秒という早さで実行できるようになりました(その後各種の最適化が実行され、現在は一切のロックを排除できています)。数ミリ秒の違いは、通常エンドユーザーに感じられるものではありません。それでも、以前の水準の5%のレイテンシを達成できることは技術屋にとって非常に嬉しいものです。
データを最大に活用する
チームにとって、以前の古いやり方に戻ることを考えられないのと同様、Elasticsearchをユーザー向けの検索エンジンだけに使用するという選択肢もありませんでした。Elastic Stack関連で目にする多くのサクセスストーリーはロギングにフォーカスしたものです。Voxpopmeも例外ではないことはすぐにわかりました。
Kubernetesのpodで生成されるログを投入する新たなロギングクラスターを設定し、自社サーバーのヘルスを可視化してクリアに把握できるようになりました。これまでは実現できなかったことであり、各種の問題にもすばやく反応できるようになりました。
さらにVoxpopmeのプラットフォームでユーザーに提供する機能も充実しました。たとえばアグリゲーション機能を使用し、ユーザーがデータを視覚的に表示できるようになりました。これはプラットフォームの価値を高める機能拡張ですが、意図されたものではなく、Elasticsearchの導入による純粋な副産物です。
この数か月の間もプロセスの改善と改良が続けられ、VoxpopmeのElasticsearchクラスターは日々パフォーマンスを向上し続けています。パフォーマンス向上の一因として、fielddataを必要とするフィールドをプライマリクラスターからアクセスの頻度が低いより小さなクラスターに移動することでメモリーの増加を実現したことがあります。メモリープレッシャーは以前の水準から75%下がり、25%ほどになりました。さらに新規データをオンデマンドではなく、バルクで記述するようコードを最適化したことで、ピークタイムでもクラスターがよりレスポンシブになりました。
今後Voxpopmeでは、Elasticsearchを高度に活用して社内で保有するデータの分析を進める予定です。クライアント向けプロダクトの中核技術として確かな能力を証明したElasticsearchをさらに活用するため、自社データをElasticsearchインデックスに格納し、社の基幹業務効率についてElastic Stackからインサイトを得るための実験的な取り組みがはじまっています。
 デビッド・メイドメント | Voxpopme社シニアソフトウェアエンジニア。指数的成長を遂げる同社で、プラットフォームの将来性をコードベースで保つことを専門領域とする。
デビッド・メイドメント | Voxpopme社シニアソフトウェアエンジニア。指数的成長を遂げる同社で、プラットフォームの将来性をコードベースで保つことを専門領域とする。
 アンディ・バラクロー | Voxpopmeの共同創業者兼CTO。技術チーム管理と、同社の長期的ビジョン策定を担当。
アンディ・バラクロー | Voxpopmeの共同創業者兼CTO。技術チーム管理と、同社の長期的ビジョン策定を担当。