機械学習の異常スコアリングとElasticsearchの仕組み
編集者注(2021年8月3日):この投稿は廃止予定の機能を使用しています。現在の手順については、逆ジオコーディングを使用したカスタム地域のマッピングドキュメントを参照してください。
機械学習に関してよくいただくお問い合わせに「異常スコア」についての質問や、あるデータセットの個々の現象の「珍しさ」はダッシュボード上の各種スコアでどう表現されているのか、という質問があります。そこで今回は、異常スコアの算出プロセスと、スコアに関する要素、そして異常スコアを予防的なアラートの指標として活用する方法をご紹介します。本記事は、機械学習についての包括的な説明は取り上げません。スコアリングのプロセスに関連して、実用的な情報を中心にお届けします。
はじめに理解しておきたいのが、この「珍しさ」を考える(そしてスコアリングする)にあたって、異なる3つのアプローチがあるということです。すなわち、個々の異常(”record”)へのスコアリングと、ユーザーやIPアドレスといったエンティティ(”influencer”)へのスコアリング、そして時間枠(”bucket”)へのスコアリングです。また、これらのスコアが階層的にどのように相互関連しているかも見ていきましょう。
Recordスコア
最初のスコアリングタイプは、階層の最下層で、「なにか普通ではないこと」が起こっていることを示す、どう見ても異常な状況です。たとえば以下のようなケースです。
・ユーザーログインの失敗率 Adminが直近の1分間で300回の失敗を観測 ・特定のミドルウェアのレスポンスタイムが通常の300%に上昇 ・今日の午後に処理されたオーダー数がいつもの木曜日よりも極端に少ない ・あるリモートIPアドレスに転送されたデータ量がその他のリモートIPに転送された量よりも圧倒的に多い
上記のできごとにはそれぞれ計算された「異常である可能性」の値があります。1e-308のレベルまで非常に細かく計算された値で、過去に観測された挙動を元に作成された基準や可能性により算出されています。この可能性値は確かに便利ですが、そのままでは以下のような具体的な情報が足りません。
・今起こっている異常な状況は過去の異常と比較するとどうなのかこれまでの異常よりも異常性が高いかどうか ・このデータの「珍しさ」は他の異常の可能性のあるその他のユーザー、IPアドレスなどのデータと比較するとどうなのか
そこで、ユーザーがより簡単に理解、優先順位を付けするために、機械学習が異常の可能性を0-100のスケールで正規化します。この値はUIで”anomaly score”として表示されます。
さらに詳細な情報を提供するためにUIは異常の重大性を、スコア75から100の”critical”、スコア50から75の”major”、スコア25から50の”minor”、スコア0から25の”warning”と4段階に分け、それぞれ別の色で表示します。
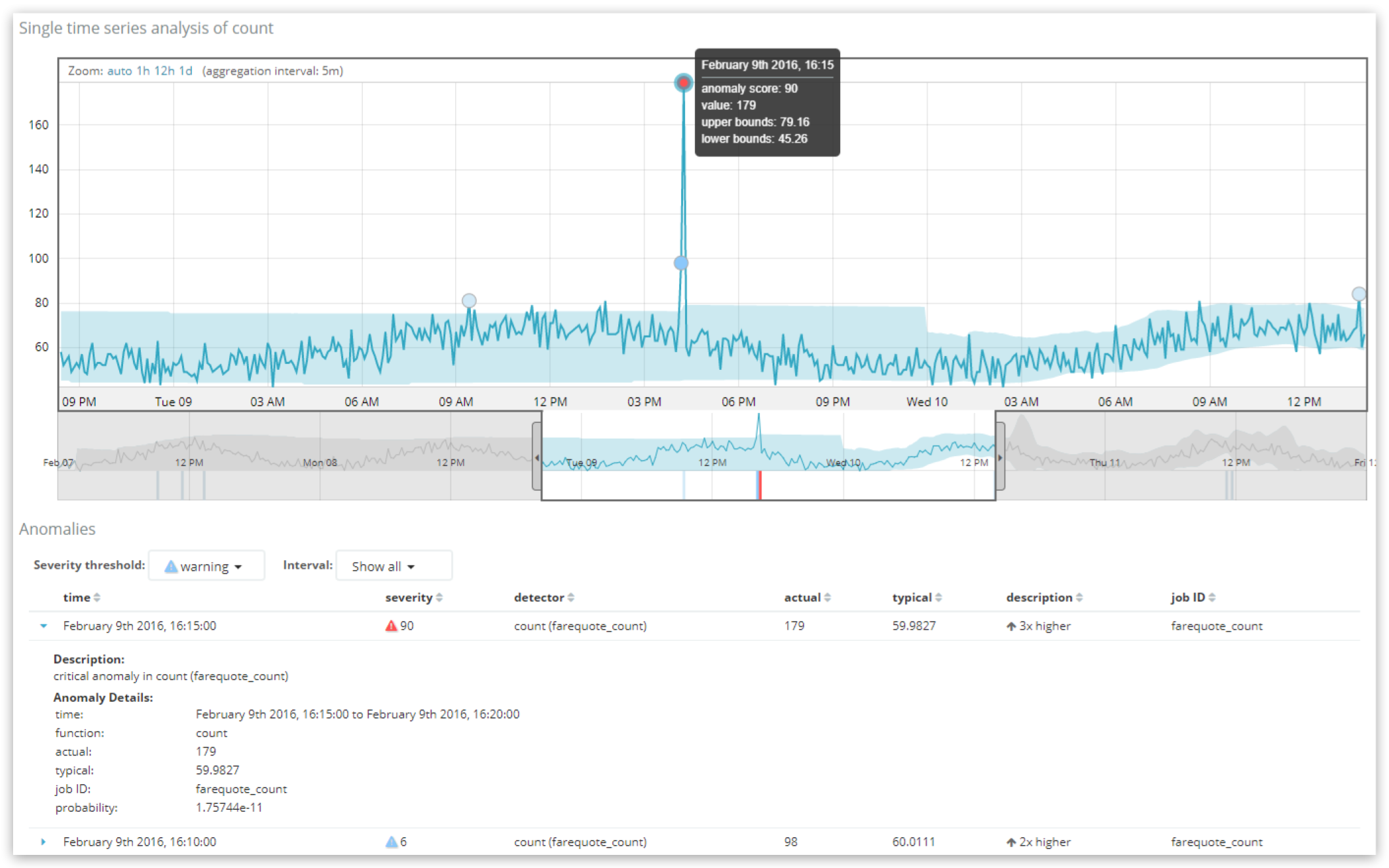
ここではSingle Metric Viewerで2つの異常値を表示しています。値の最大異常スコアは90で、重大性は”critical”です。上の表で”Severity threshold”(重大性閾値)がより重大な異常の値をふるい分けしているのに対し、”Interval”(期間)では値を1時間ごとにグループ化し、それぞれのグループで一番高い異常のスコアを出しています。
例として、機械学習のAPIにfarequote_countという名前のジョブについて、ある5分間に発生した異常についての情報をquery for record resultsで以下のように求めてみます。
GET /_xpack/ml/anomaly_detectors/farequote_count/results/records?human
{
"sort": "record_score",
"desc": true,
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
すると以下のようにアウトプットされます。
{
"count": 1,
"records": [
{
"job_id": "farequote_count",
"result_type": "record",
"probability": 1.75744e-11,
"record_score": 90.6954,
"initial_record_score": 85.0643,
"bucket_span": 300,
"detector_index": 0,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"function": "count",
"function_description": "count",
"typical": [
59.9827
],
"actual": [
179
]
}
]
}
その5分間の(ジョブのbucket_span)”record_score”は90.6954(最大100)で、probability(可能性値)は1.75744e-11です。この結果から、その5分間に実際に179個のドキュメントがあったのは「非常に珍しい」ということがわかります。「いつもの」ドキュメント数はぐっと少なく、60個程度だからです。
これらの値がUIでどのように表示されるか見てみましょう。probabilityの1.75744e-11という値は非常に小さい数なので、「よくある状況」とは考えにくいことを示していますが、パッと見ではその度合いがよくわかりません。そこで0-100のスケールで表してわかりやすくしたのです。このように正規化する手法は独自のものですが、おおまかには同じジョブで過去に検出された異常の可能性値を相互比較してランクづけした値を変化分析したものです。要するに、このジョブのこれまでの履歴の中で、最も可能性が低いものが最も高い異常スコアを示すということです。
よくある間違いとして、異常スコアをUIの”descritption”項目の偏差値と直接関連づけてしまうものがあります。(この場合、3倍も高くなってしまいます)異常スコアは純粋に可能性を計算したものです。”description”、またはtypical値ですら、異常をわかりやすくするために内容を簡易的に表した情報の一部分にすぎないのです。
Influencerスコア
ここまでは個々のデータのスコアリングの概要を説明してきました。次に異常性を考える上で重要なのはエンティティの異常度合いや異常スコアが異常にどのように関連しているかです。機械学習では関連するエンティティのことを”influencer”と呼びます。上記の例では、一定時間の挙動分析だけだったので、あまりにシンプルすぎてinfluencer要素はありませんでした。もっと複雑な分析になってくると、異常発生に補助的な要素が加わっている可能性がでてきます。
たとえば、インターネット利用者数分析で機械学習が検知した、異常なバイト数の送信量と「珍しい」ドメインを訪問した数の場合、「ユーザー」の行動が異常を発生させている「原因」なのですから、「ユーザー」にinfluencerの可能性があることがわかります。(何かが大量のデータを宛先ドメインに送っているはずだからです)influencerスコアは、送信バイト数と訪問ドメイン数の両方または片方についての異常性の度合いとして各ユーザーに与えられます。
infuluencerスコアが高ければ高いほど、異常発生の責任があるまたは関係していると言えます。これは特に複数のdetectorがある機械学習の結果を見る際、有力な手がかりとなります。
すべての機械学習ではジョブ作成時に作成されるinfluencerとは別に、bucket_timeと呼ばれるあらかじめ設定されたinfluencerが常に作成されます。これにはその時間枠内の一連のデータすべてが使用されます。
航空運賃問い合わせのAPIレスポンスタイムのデータセットを例にとって、2つのdetectorが設定されている機械学習ジョブでinfluencerを見てみましょう。
・airlineごとのAPIの呼び出し回数
・airlineごとのAPIの呼び出しの平均(APIレスポンスタイム)
この場合、airlineがinfluencerです。
Anomaly Explorerの結果を見て見ましょう。
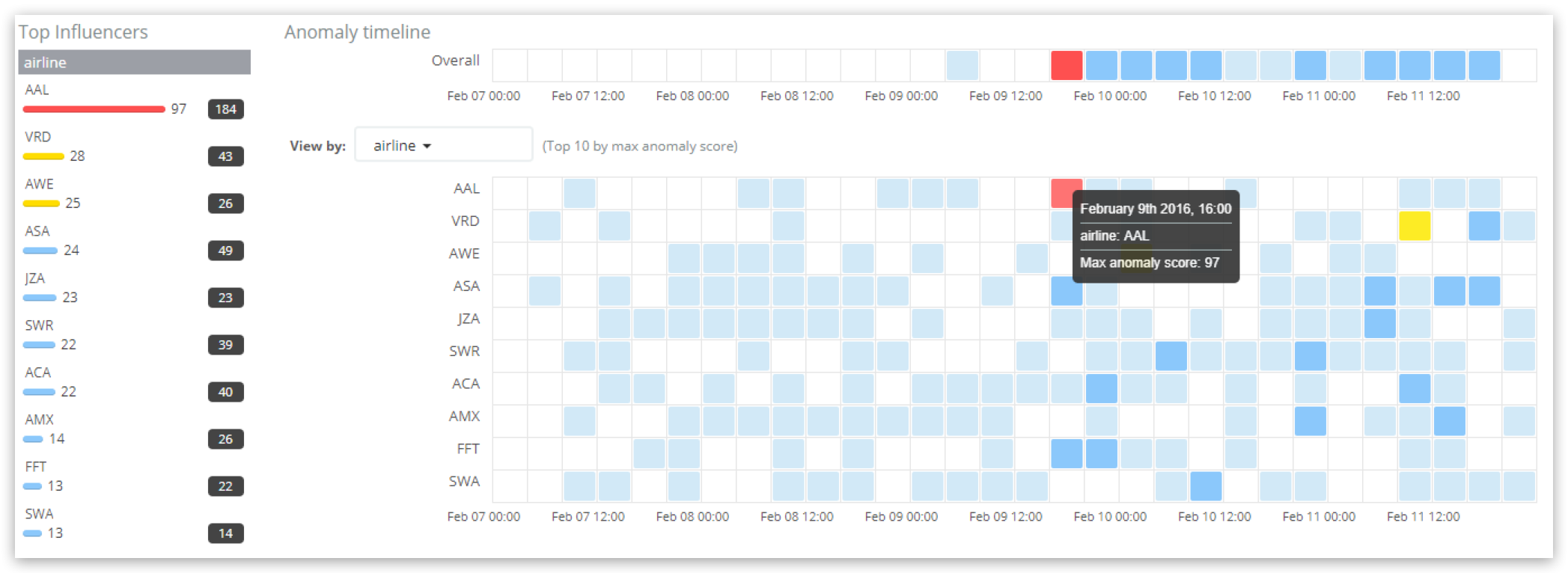
ダッシュボード上で見たい時間枠を選択すると、その時間枠内のinfluencerのスコアランキングが左側の“Top influencers”に表示されます。それぞれのinfluencerに各時間枠ごとの最高influencerスコアが表示されます。ダッシュボードに表示されている全時間内のinfluencerスコアの全時間枠合計も出てきます。航空会社AALに最も高いinfluencerスコアとなる97が表示されています。また、この時間枠全体のinfluenerスコアは合計で184でした。メインのタイムラインはinfluencerごとに結果を表示し、influencerとなる航空会社の最高スコアをハイライトしています。こちらでも97というスコアが示されています。ここでいうinfluencerスコアは、航空会社AALの”Anomalies”の表で示されている各異常の”record scores”とは別のものです。
influencerレベルでのAPIを調べてみます。
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/influencers?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
次の情報が返ってきます。
{
"count": 2,
"influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AAL",
"airline": "AAL",
"influencer_score": 97.1547,
"initial_influencer_score": 98.5096,
"probability": 6.56622e-40,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "influencer",
"influencer_field_name": "airline",
"influencer_field_value": "AWE",
"airline": "AWE",
"influencer_score": 0,
"initial_influencer_score": 0,
"probability": 0.0499957,
"bucket_span": 300,
"is_interim": false,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000
}
]
}
航空会社AALのinfluencer_scoreが97.154(四捨五入で97)という結果がAnomaly ExplorerのUIに表示されます。probability値である6.56622e-40は正規化する前の値で、influencer_scoreのベースになっています。これには特定の航空会社がどの異常にどれくらい影響している可能性があるのかが示されています。
アウトプットにはinitial_influencer_scoreの98.5069が含まれていますが、これは結果が処理された時のもので、この後の正規化で97.1547に微調整される前のものです。これは機械学習ジョブがデータを時間軸にそって処理していて、時間を遡って元となるデータを再度参照したり、分析したりすることがないために起こります。また、2番目のinfluencerとして航空会社AWEも出力されています。しかし、AWEのinfluencerスコアはほぼ0と非常に低く、実質的に無視できる水準です。
influencer_scoreは複数の要素から導き出された値なのでAPIは回数やレスポンス速度のactualやtypicalといった値は表示しません。そのような詳細な情報は、前に挙げたような同じ時間の記録結果を参照すれば見ることができます。
Bucketスコア
最後に紹介する3つ目の異常スコアは時間に着目した、階層的には最高のもので、機械学習ジョブの”bucket_span”を見るものです。ある時、ひとつのデータ、もしくは複数のデータが同時に、「珍しく」なって「珍しい」現象が起こります。
ですので、ひとつの時間枠の異常は複数の要素に起因します。
・その時間枠のそれぞれの異常の大きさ ・その時間枠に同時に起こった異常の数。これはジョブがbyfieldsやpartitionfieldsを使って「分割」されていた場合、またはそのジョブで複数のdetectorを使っていた場合はより多くなります。
bucketスコアの「裏の」計算は単なるすべての異常スコア合計よりも複雑なもので、各時間帯のinfluencerスコアの要素も入っています。
さきほどの例の機械学習ジョブでは2つのdetectorがありました。
・airlineごとのcount(回数)
・airlineごとのmean(平均レスポンスタイム)
Anomaly Explorerで見て見ると、
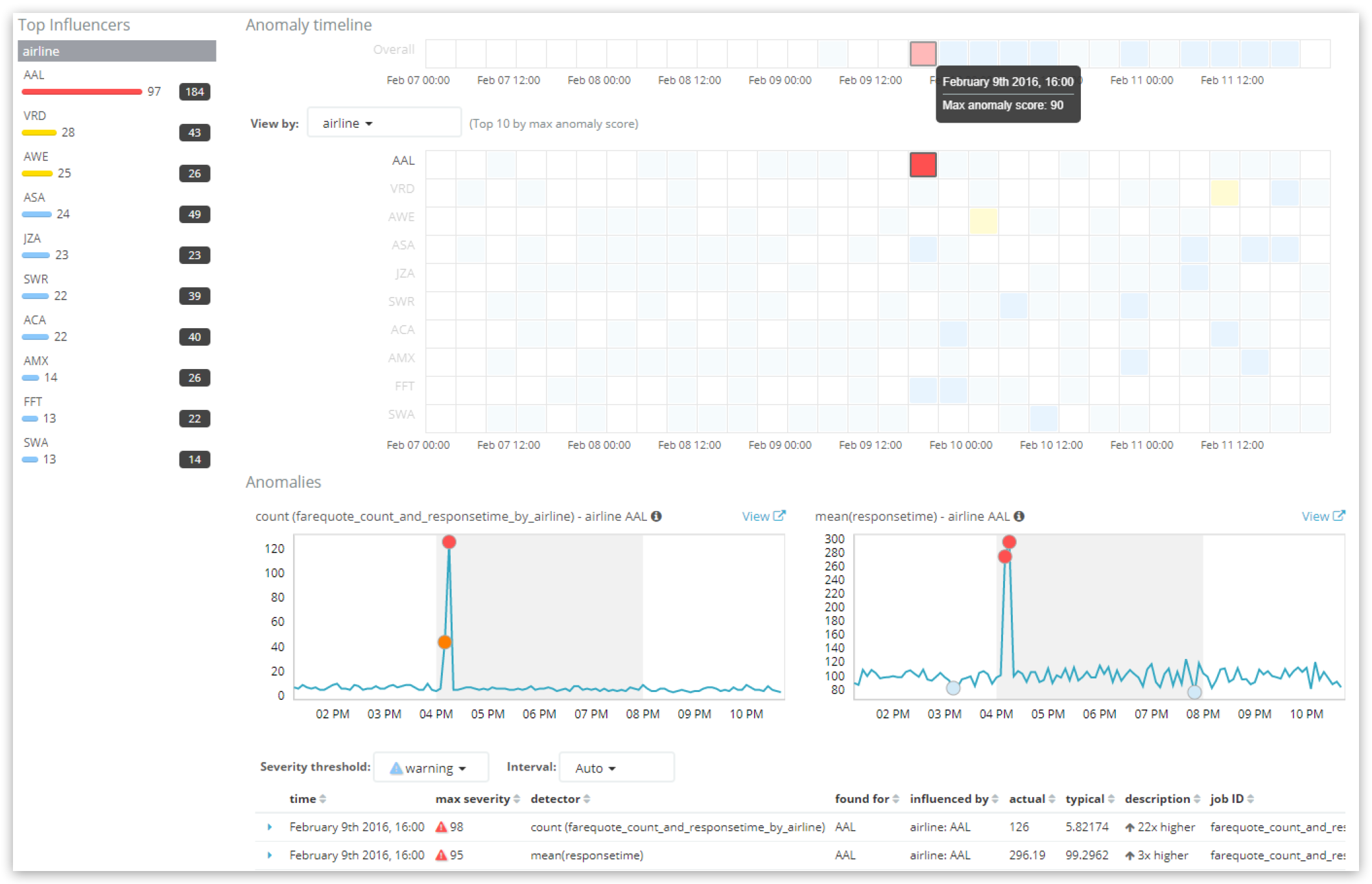
Anomaly timelineの一番上に表示されているoverallの部分に、その時間枠のスコアが表示されているのがわかります。ですが、注意していただきたいのは、UIで長い時間帯を選択していて、かつ機械学習ジョブのbucket_spanが短い場合、UIで表示される時間枠タイルのひとつひとつには実際には複数の時間枠が含まれている場合があるということです。
上の例でいえば、選択されている時間枠タイルの数値は90で、それぞれ98と95の2つのcriticalな異常がその時間内に発生しています。
APIでその時間枠を調べてみましょう。
GET _xpack/ml/anomaly_detectors/farequote_count_and_responsetime_by_airline/results/buckets?human
{
"start": "2016-02-09T16:15:00.000Z",
"end" :"2016-02-09T16:20:00.000Z"
}
すると次の情報が表示されます。
{
"count": 1,
"buckets": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"anomaly_score": 90.7,
"bucket_span": 300,
"initial_anomaly_score": 85.08,
"event_count": 179,
"is_interim": false,
"bucket_influencers": [
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "airline",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
},
{
"job_id": "farequote_count_and_responsetime_by_airline",
"result_type": "bucket_influencer",
"influencer_field_name": "bucket_time",
"initial_anomaly_score": 85.08,
"anomaly_score": 90.7,
"raw_anomaly_score": 37.3875,
"probability": 6.92338e-39,
"timestamp_string": "2016-02-09T16:15:00.000Z",
"timestamp": 1455034500000,
"bucket_span": 300,
"is_interim": false
}
],
"processing_time_ms": 17,
"result_type": "bucket"
}
]
}
この結果で特に見ていただきたいのは次の点です。
・anomaly_score 全体的に情報を集約した、正規化したスコア(この場合90.7)
・initial_anomaly_score その時間枠のanomaly_scoreを処理したもの(前述したように、後の正規化でanomaly_scoreが元の値から変わった場合)。initial_anomaly_scoreはUIにはどこにも表示されない値です。
・bucket_influencers この時間枠に存在するinfluencerタイプ一覧。さきほどinfluencerの話をした時に疑った通り、この一覧にinfluencer_field_name:airlineとinfluencer_field_name:bucket_time(後者はbuilt-in influencerとして常に表示される)の両方が含まれています。どの航空会社か、など特定のinfluencerの詳細は、先に紹介したように、APIに特定のinfluencerまたはrecordの値を問い合わせてみるとわかります。
異常スコアを利用して異常を通知する
recordベース、influencerベース、時間枠ベースの基本的なスコアをご紹介してきましたが、アラートに便利なのはどのスコアでしょうか?答えは、ユーザーの目的と求めているレベルによります。つまりどのようなレベルで通知されたいか、によるのです。
全体的なデータセットのその時々の挙動で、極端に「いつもと違う」時に通知を受け取りたい場合には時間枠によるスコアが最適です。その時々で最も「珍しい」動きをするエンティティについての通知を受け取りたい場合にはinfluencer_scoreが役立ちます。または、ある期間内で一番「珍しい」異常を検知して通知を受け取りたい場合はそれぞれのrecord_scoreを元に通知を受け取ることをおすすめします。
たくさんの通知であふれかえってしまうのを避けるには、時間軸ベースの異常スコアを元にするのをおすすめします。なぜなら時間軸ベースの場合、回数限定、つまりある一定時間内に1回しか通知が来ないからです。逆に言うとrecord_scoreベースの通知を使った場合、一定時間内に通知される異常の数は決まっていないので、非常に多くなる可能性もあります。ですので、ここのデータベースのスコアを使って通知をする場合はこの点に注意してください。
その他の参考記事
Alerting on Machine Learning Jobs in Elasticsearch v5.5Explaining the Bucket Span in Machine Learning for ElasticsearchResults resources, Machine Learning Docs