ノードをクラスターに追加したときのElasticsearchのパフォーマンスを最大化


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elasticsearchクラスターにノードを追加すると、膨大なワークロードに備えてスケーリングできます。パフォーマンスが損なわれる事態にならないよう、Elasticsearchクラスターを拡張する最適な方法を理解しておくことが重要です。
Elasticsearchは、高速かつパワフルな検索テクノロジーです。扱うデータが増えてくると、Elasticsearchの魅力の1つであるスケーラビリティを活用する必要が生じます。クラスターにノードを追加すると、クラスターで保持できるデータの量が増えるだけでなく、同時に処理できるリクエストの数も増え、結果が返ってくるのに要する時間が短縮されます。通常は。
Elasticsearchクラスターにノードを追加したことで動作が不安定になったりダウンタイムが発生したりといった事態が生じると、その理由を突き止めるために悲惨な週末を過ごすはめになり、ストレスはたまり、収益は失われます。そこで、クラスターのスケールアップがパフォーマンスの重大なボトルネックになりかねない、陥りがちな構成をいくつか紹介します。
Elasticでは、「Elasticsearch sizing and capacity planning(Elasticsearchのサイジングとキャパシティープランニング)」という、本当にためになるウェビナーをご用意しています。このウェビナーでは、クラスターにおける4つの主要なハードウェアリソースが定義されています。
- コンピューティング – 中央処理装置(CPU)。クラスターが作業を実行できる速度を左右します。
- ストレージ – ハードディスクドライブ(HDD)またはソリッドステートドライブ(SSD)。クラスターで長期的に保持できるデータの量を左右します。
- メモリー – ランダムアクセスメモリー(RAM)。クラスターが一度に実行できる作業量を左右します。
- ネットワーク – 帯域幅。ノード間でデータが転送される速度を左右します。
このうち、最もパフォーマンスのボトルネックになりがちなのが、コンピューティングとストレージの2つです。これらが不足すると、クラスターのデータノードに重大な影響が及びます。マスター、インジェスト、変換など、他の役割のノードについては、また別の機会に議論することにしましょう。
補足:わかりやすくするため、この記事では単一のElasticsearchクラスターのスケーリングに話を絞っています。共有ハードウェア上で複数のクラスターを実行している場合には、話はもっと複雑になります。
ハードウェアリソースの割り当ては、プラットフォームに応じて異なります。たとえば、ノードが、ハードウェア、仮想マシン、コンテナーのいずれをベースとしたシステムなのかによって違います。
容量を増やすためにElasticsearchノードを追加する場合
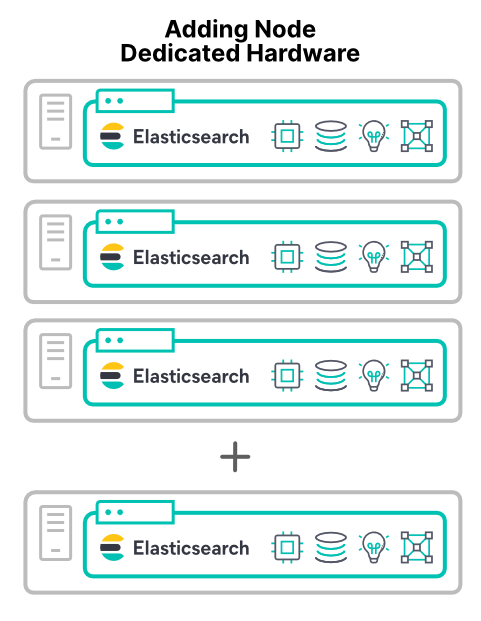
専用ハードウェアノードの追加
クラスターのパフォーマンス向上を最も予測しやすい方法が、新しいハードウェアの追加です。新しい専用ハードウェアを追加すると、4つの主要リソースがすべて増えます。重要な1つの例外(後ほど取り上げます)を除いて、新しいハードウェアノードを追加することでクラスターのパフォーマンスを向上できます。
新しいホスト上の仮想マシンまたはコンテナーへのノードの追加
仮想マシン(VM)またはコンテナーとしてノードを追加する場合は、状況が異なります。新しいホスト上の新しいノードをクラスターに割り当てると、より多くのハードウェアリソースが付与されます。CPUコア数も、RAMも、ストレージも、総帯域幅も増えます。
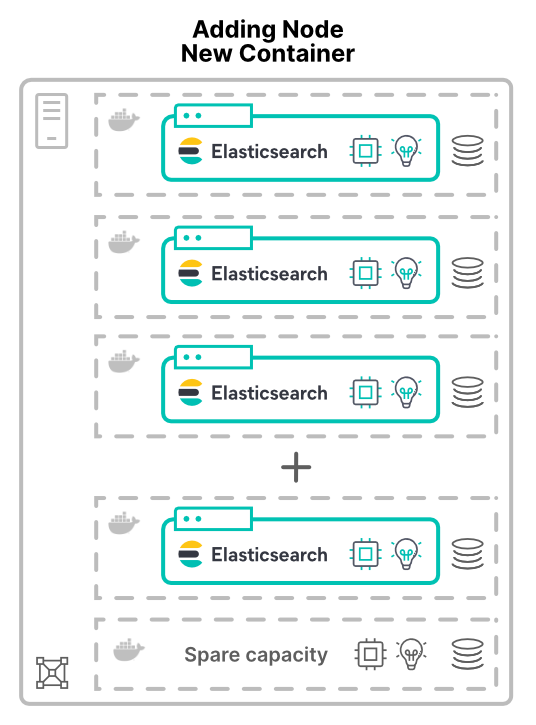
アプリケーションを仮想化(またはコンテナー化)する理由の1つが、ハードウェアの有効活用です。この場合、ノードを追加することで増えるのは、クラスターで利用可能なハードウェアの量だけです。その結果パフォーマンスがどの程度向上するのかは、共有リソースの制限に左右されます。
容量を分割するためにノードを追加する場合
ハードウェアを分割するために使用するのがVMでもコンテナーでも、Elasticsearchノードはハードウェアを共有することになります。ここでの考慮事項は、Elastic Cloud Enterprise(ECE)やElastic Cloud on Kubernetes(ECK)を含む、すべてのデプロイモデルに当てはまります。
コンピューティングボトルネックの発生
CPUの割り当てに仮想マシンを使用する場合は、基本的に不測の事態はありません。それぞれのVMに使用するコア数を割り当てます。コンテナーを使用する場合のCPU共有は、そこまで単純な話ではありません。
Kubernetesのようなコンテナーシステムでは、CPUリソースをCPUの数千分の1の単位(ミリコア)で測定できます。Requests(最低保証量)とLimits(最大量)の間には大きな違いがあります。CPUの最低保証量だけを定義すると、コンテナーはホストのCPUを最大100%まで使用できます。一方、CPU使用の最大量を厳しくしすぎると、高価なリソースを遊ばせておくことになります。
>ヒント:スレッドプールでは、CPUコアが起点として使用されます。コンテナーを利用する場合は、スレッドプールの構成が想定したとおりに動作するかを確認することをお勧めします。
Kubernetesでは、コンテナーのCPU Limitsの合計を利用可能なハードウェアの合計よりも大きく設定できます。これは、すべてのコンテナーで同時にCPUがフルに使用されることはないという想定があるからです。
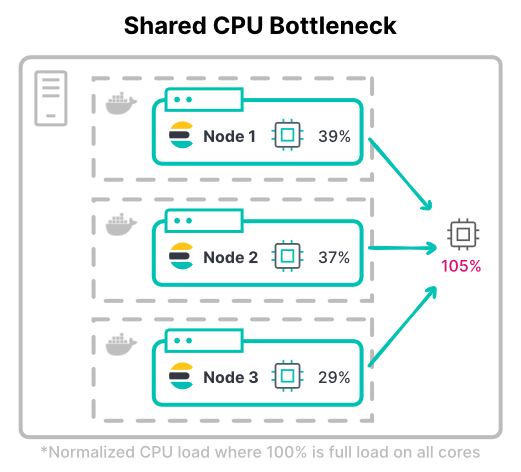
クラスターの最大スループットを考えてみましょう。コンピューティング負荷の高いワークロードでは、インデックスのために、ノードに割り当てられたCPUを限界まで使用する必要が生じることも少なくありません。インデックスが多用されるワークロードで最も一般的なのが、大容量のロギングクラスターです。
>ヒント:CPUの最大量を決める際には、ピーク時のCPU使用量と通常のCPU使用量を考慮しましょう。また、CPUスロットルをどこまで許容できるかも検討しましょう。
ストレージボトルネックの発生
ストレージボトルネックの発生を防ぐのは難しいかもしれません。ストレージはスループットではなく、容量で割り当てられるからです。Elasticsearchノードでストレージ容量が足りなくなると、[Low disk watermark](ディスク容量不足)になり、シャードの割り当てが停止されます。
VMでもコンテナーでも、大半のプラットフォームには、簡単にストレージデバイスの使用量を制限できる方法がありません。IOPS(入出力操作毎秒)や読み取り/書き込みのスループットに制限を設けることができる環境はほとんどありません。推奨されているXFSファイルシステムですら、ディスク容量に基づいてディスククォータを設定できるだけです。
制限がないと、ストレージ負荷の高いワークロードを抱えるコンテナーが、ストレージハードウェアを使い切ってしまう可能性があります。そうなると、そのハードウェアを共有している他のノードのリソースが枯渇します。大規模な環境では、/dataディレクトリで問題が発生する可能性があります。複数のノードが/dataディレクトリを同じストレージエリアネットワーク(SAN)ハードウェアにマウントしている場合、すべてのノードのスループットが合わさり、デバイスが耐えられなくなる可能性があります。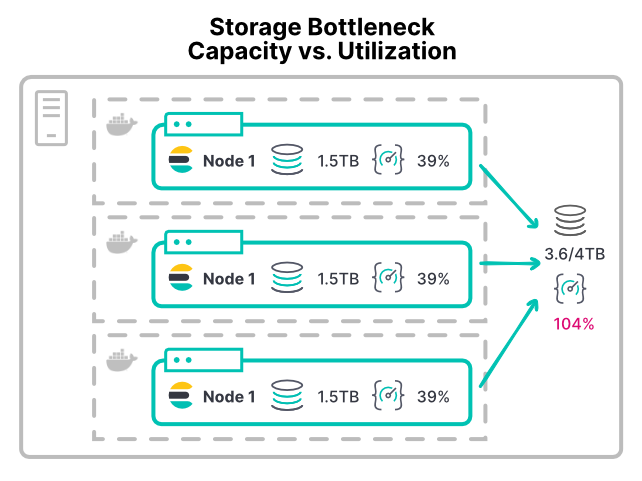
このようにコンテナーをセットアップしている場合、ノードを追加するとクラスターに割り当てられるCPUとメモリーが増えます。その一方で、既存ストレージのスループットの細分化が進みます。これによりディスク操作に時間がかかるようになり、ノードを追加することでパフォーマンスが低下することになります。
>ヒント:CPUのI/O待機時間が10%を超えているのは、ノードでストレージのスループットが不足気味になっていることを示す初期兆候です。この指標は、個々のコンテナーのレポートには現れないので、VMまたはコンテナーのホストで確認するようにしましょう。
中立性のためにノードを追加する場合
最後にもう1つ、効果的なスケーリングのために押さえておくべきポイントがあります。この構成のボトルネックは、物理的ハードウェアを追加する場合であっても発生します。
シャードが十分にない状態でインデックスのスループットを制限
いかなる方法であれ、ノードを追加してもインデックス内のシャード数は変わりません。インデックスに2つのプライマリシャードと1つのレプリカセットがあるなら、合計4つのシャードがあることになります。4ノードのクラスターでは、インデックスのスループットを最大化するために、ノードあたりのシャードは1つだけにすることをお勧めします。
受信データ量が増えたら、クラスターにさらに2つノードを追加します。これによりクラスターのリソースは全部で50%増加しますが、インジェストレートは、まったく増加しません。なぜでしょうか。
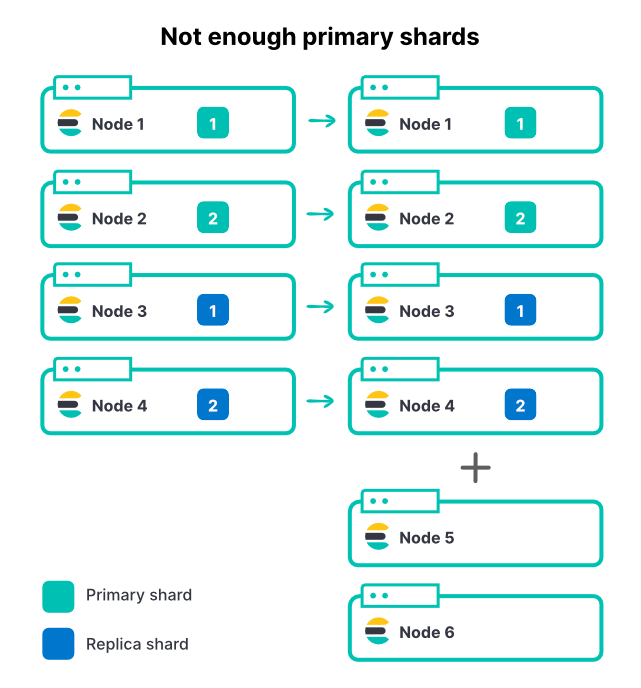
この場合、新しいノードはインデックスに貢献できません。すべてのシャードがすでに割り当てられているからです。インデックスに関してノード増加の恩恵を受けるためには、プライマリシャードの数も増やす必要があります。クラスター内に多数のアクティブなインデックスがある場合(それが普通です)、ノードを追加するとクラスターの総スループットは増えますが、プライマリシャードが限られているため、最もアクティブなインデックスは制限されたままです。キャパシティプランニングの際に、Elasticsearch用に適切なシャード数を選択することが重要です。
上の例では2つだったプライマリシャードを3つに増やし、シャードごとに1つのレプリカを追加することで、合計6つのシャードが6つのノードそれぞれに割り当てられます。
>ヒント:安全策として、index.routing.allocation.total_shards_per_node(ドキュメント)を設定しておくこともできます。ただし、この制限を緩くしすぎると、シャードが割り当てられないままになる可能性があります。
まとめ
Elasticsearchクラスターにノードを追加すればパフォーマンスが向上するかどうかは、場合によります。ノードがハードウェアを共有している場合は、共有リソースのボトルネックに注意する必要があります。ありがちなボトルネックは、CPUとストレージの過剰使用です。慎重に計画して適切なシャード戦略を策定することで、ノードを追加してパフォーマンスを向上できます。
Elastic Cloudでの運用には多くのメリットがありますが、その1つが、シャードリソースのパフォーマンスに関するこの種の懸念を特定し、適切に対応するため、献身的に努力するElasticの担当チームの存在です。https://www.elastic.co/jp/cloud/から、お気軽にクラウドを試用してみてください。
また、「Elasticsearch sizing and capacity planning」をご覧になり、Elasticsearchのパフォーマンスについての理解を深めてください。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷