LangChainとElasticsearchを使用したプライバシー最優先のAI検索


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
私は過去数週間にわたる週末を、"プロンプトエンジニアリング"の魅力的な世界に触れ、Elasticsearch®のようなベクトルデータベースを長期的なメモリーおよびセマンティックナレッジストアして機能させることで、ChatGPTのような大規模言語モデル(LLM)を強化する方法を学習することに費やしてきました。しかし私にとって、そしてその他多くの経験豊富なデータアーキテクトにとっての問題の1つは、公開されているチュートリアルやデモの多くで、大規模なWeb企業やクラウドベースのAI企業にプライベートデータを送信することを余儀なくされるという点です。
プライベートデータはあらゆる形態を取り、複数の理由により保護されています。スタートアップ企業も大企業も、自社のプライベートデータが競争優位性となる場合があることを認識しています。多くの場合、社内データや顧客データには個人を特定できる情報が含まれ、これらが保護されなければ、法的および実際の人的な影響を及ぼします。オブザーバビリティとセキュリティのドメインでは、サードパーティのサービスの活用に注意を払わなければ、データ侵害を引き起こしかねません。AIチャットツールの使用と関連付けられたサイバーセキュリティ侵害の懸念も耳にするようになりました。
たとえElasticのようなプライバシーとセキュリティへの取り組みを強化している企業と連携しても、真のエアギャップ環境にデプロイしても、リスクのない、完全にプライバシーが確保される設計はありません。しかし、多くの機密データのユースケースを扱ってわかったのは、プライバシー重視のアプローチによるAI検索には非常に現実的な価値があることです。同僚のジェフ・ヴェストルは、OpenAIツールをElasticsearchと組み合わせて使用する方法についてすばらしい解説を行っていましたが、この記事では別のアプローチを取ります。
このプロジェクトのアプローチには2つの目的があります。
- プライベート:文字どおりの意味です。クラウドホスト型のElasticsearchを使用する一方で、ユースケースの要求に応じて、完全なエアギャップ環境で動作するようにします。プライベートな知識をサードパーティに送信することなく、AI検索が機能することを証明しましょう。
- 楽しさ:楽しみながら作業しましょう。データサイエンスの演習で人気のある『スター・ウォーズ』のコミュニティWiki、Wookieepediaのスクレイピングを使用して、プライベートなAI豆知識ヘルパーを作成します。この記事を執筆中の現在は、スターウォーズの日である5月4日の少し前で、この記事が公開される頃にはその日も過ぎていますが、私は一年を通じてファンとして活動しています。
実際に自分で試してみる最も簡単な方法は、Elastic CloudでElasticsearchインスタンスを起動し、プロジェクトを小規模に実装する提供されたPythonノートブック通じて実行することです。18万段落に及ぶ『スター・ウォーズ』情報で構成されるWookieepediaの完全なスクレイピングを実行して、『スター・ウォーズ』に精通した知識検索を作成するには、こちらのGitHubレポジトリのコードに従ってください。
すべてを完了すると、このようになります。
オープン性の精神から、Elasticsearchをサポートする2つのオープンソーステクノロジーを取り入れます。Hugging Face Transformersライブラリに加え、楽しく使用できる新しいPythonライブラリのLangChainを使用して、ベクトルデータベースとしてのElasticsearchをでの作業を高速化します。しかも、LangChainを使用するとセットアップされたLLMがプログラム的に置き換え可能になるため、さまざまなモデルで実験できるようになります。
しくみ
LangChainとは何でしょうか。LangChainは、大規模言語モデルを利用するアプリケーションを開発するための、PythonとJavaScript用のフレームワークです。LangChainはOpenAIのAPIと連携しますが、データベースとAIツールの差異を抽象化して除去するのにも優れています。
ChatGPTだけでも、ある程度は『スター・ウォーズ』の豆知識に対応できます。ただし、訓練用データセットは今では数年前のものとなり、一方で利用者は最新のテレビ番組や『スター・ウォーズ』関連のイベントについての回答を求めています。また今回はこのデータが、クラウドの大規模なLLMと共有するにはプライベートすぎるデータであると仮定しています。より最近のデータを使用して大規模言語モデルを調整することもできますが、もっと簡単な方法で、常に利用可能な最新のデータを利用することができます。
今回は小規模でセルフホストが容易なLLMを利用します。Googleのflan-t5-largeモデルでは、インジェクトされたコンテキストから答えを解析する優れた機能によって訓練不足を補うことができ、優れた結果が得られました。セマンティック検索を使用してプライベートな知識を取得し、質問を利用してそのコンテキストをプライベートLLMにインジェクトします。
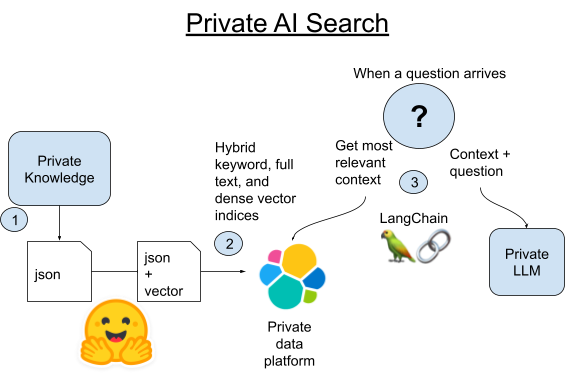
1.Wookieepediaからすべての公式記事をスクレイピングして、データをステージングされたPython Pickleファイルに取り込みます。
2A.LangChainに組み込まれたVectorstoreライブラリを使用して、これらの記事の各段落をElasticsearchに読み込みます。
2B.または、LangChainと、ElasticsearchそのものにPyTorch変換器をホスティングする新たな方法を比較することができます。Elasticsearchにテキスト埋め込みモデルをデプロイして、分散コンピューティングを活用してプロセスを高速化します。
3.質問が入力されると、Elasticsearchのベクトル検索を使用して、その質問に最もセマンティックに類似する段落を見つけます。次にその段落を抜き出し、小規模なローカルLLMのプロンプトに質問へのコンテキストとして追加し、後は生成AIの機能が豆知識の質問に対する短い答えを作成します。
PythonとElasticsearchの環境をセットアップする
お使いのマシンにPython 3.9または同等のバージョンがインストールされていることを確認します。私はGPUアクセラレーションとライブラリの互換性を向上させるために3.9を使用していますが、このプロジェクトでは必ずしも必要ではありません。最近のPython 3.Xバージョンのいずれかで構いません。
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformersサンプルコードをダウンロードした場合は、代わりに以下のpip installコマンドを実行すると、私が使用していたのとまったく同じバージョンのコードを取り込むことができます。
pip install -r requirements.txtこちらの指示に従ってElasticsearchクラスターを設定します。最も手軽な開始方法は、クラウドの無料トライアルです。
フォルダーに.envファイルを作成して、Elasticsearchの接続の詳細を読み込みます。
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"手順1:データのスクレイピング
コードレポジトリには、Dataset/starwars_small_sample_data.pickleに小規模なデータセットがあります。小規模な作業で問題ない場合は、この手順をスキップしても構いません。
スクレイピングコードはデニス・バクイスによる優れたデータサイエンスのブログとプロジェクト(是非ご覧ください)に基づいています。デニス・バクイスは各記事の最初の段落のみを取り込んでいましたが、私はこれをすべて取り込むようにコードを変更しました。デニス・バクイスはデータを一次メモリー内に収まるサイズにする必要があったことも考えられますが、Elasticsearchではメモリーをペタバイト規模に拡張できるため、この点は問題になりません。
また、ここに独自のプライベートデータソースを接続するのも非常に簡単です。LangChainには、テキストデータを分割して短く区切るための、優れたユーティリティライブラリがあります。
スクレイピングはこの記事のテーマではないため、自分自身で小規模に実行したい場合はPythonノートブックを確認するか、ソースコードをダウンロードして次のように実行します。
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py
完了したら、次のように保存されたPickleファイルを確認し、正常に処理されたことを確かめます。
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)Webスクレイピングをスキップした場合は、bookFilePathをstarwars_small_sample_data.pickleに変更して、GitHubレポジトリに追加したサンプルを使用します。
手順2A:埋め込みをElasticsearchに読み込む
以下のコードは、これをLangChainのみで行う方法を示しています。このコードの重要な部分は、上記の例のように保存されたPickleファイルをルーピングして、文字列のリストである段落を抽出し、これらをLangChainVectorstoreのfrom_texts()関数に渡すことです。
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)
手順2B:ホストされている訓練済みモデルを利用して時間とお金を節約する
私の古いIntel Macbookでは、埋め込みを作成するのに何時間もの処理時間が必要になることがわかりました。むしろ数日単位に感じられたほどです。これはElasticのマネージドサービスにおける動的に拡張可能な機械学習(ML)ノードを使用することで高速化でき、コストも削減できると考えました。無料トライアルのクラスターではその階層を拡張できないため、この手順は一部の人により適している可能性があります。
最終的な結果として、このアプローチはノードで40分かかり、Elastic Cloudで実行するコストは1時間あたり5ドルでした。これはローカルで実行するよりもはるかに速く、OpenAIの現在のトークンチャージによる埋め込み処理と同等のコストです。この処理の効率化はより大きなトピックですが、新しいスキルを習得したり、プライバシーが確保されてないAPIにデータを渡したりすることなく、並列推論パイプラインをElastic Cloudで迅速に機能させられることに感銘を受けました。
この手順では、埋め込みの生成をElasticsearchクラスターそのものにオフロードします。Elasticsearchクラスターは埋め込みモデルをホストして、テキストの段落を分散して埋め込むことができます。これを行うには、データを読み込み、インジェストパイプラインを使用して、最終的な形式がLangChainで使用されるインデックスマッピングと一致するよう確認する必要があります。Kibanaの開発ツールで以下のRESTコマンドを実行します。
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
次に、Eland Pythonライブラリを使用して埋め込みモデルをElasticsearchにアップロードします。
source .env
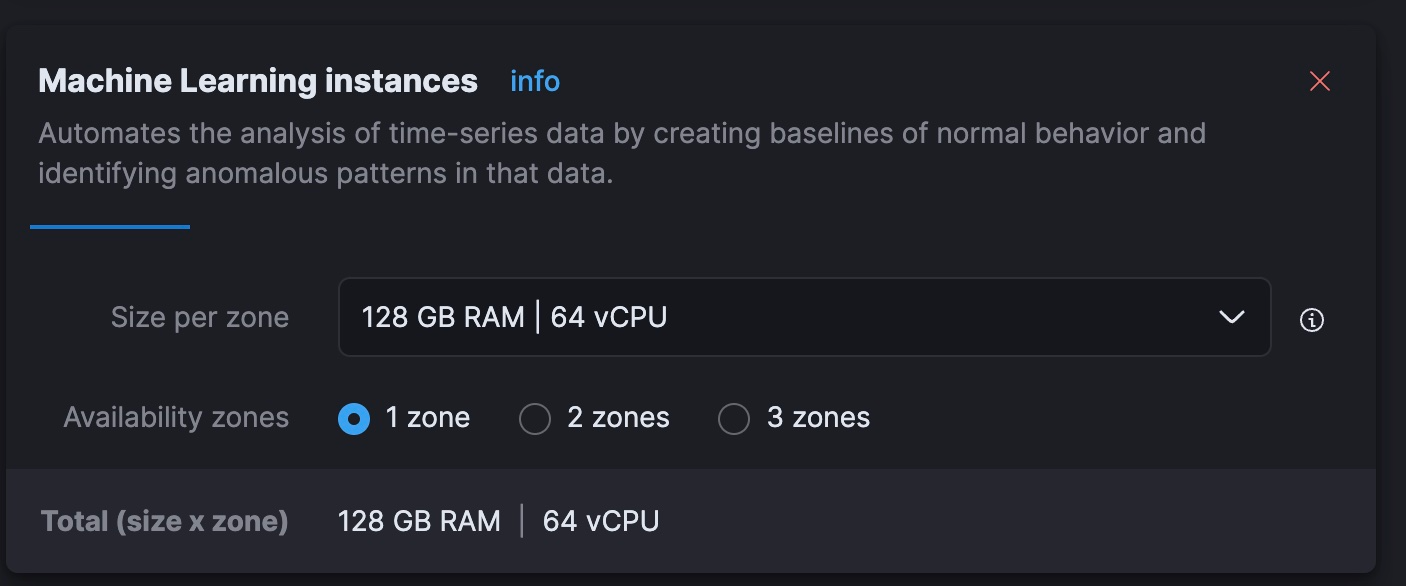
python3 step-3A-upload-model.py次にElastic Cloudコンソールに移動して、ML階層を合計64 vCPU(現在のノートPCの処理能力の8倍)に拡張します。
次に、Kibanaで訓練済みのMLモデルをデプロイします。規模が大きい場合、パフォーマンステストでは、ユーザーはモデルあたり1スレッドの割り当てから開始し、割り当て数を増やしてスループットを向上させることが推奨されています。ドキュメントとガイダンスについてはこちらを参照してください。実験したところ、この小規模なセットでは、32インスタンス(各2スレッド)で最適な結果が得られました。このセットアップを行うには、[Stack Management](スタック管理) > [Machine Learning](機械学習)の順に移動します。保存済みオブジェクトの同期機能を使用して、Pythonコードを使用してElasticsearchにプッシュしたモデルをKibanaが確認できるようにします。次にクリックすると表示されるメニューでモデルをデプロイします。

ここで再び開発ツールを使用して、ドキュメント内のテキスト段落を処理し、結果を"ベクトル"という高密度ベクトルフィールドに配置し、段落を目的の"テキスト"フィールドにコピーする、新しいインデックスとインジェストパイプラインを作成しましょう。
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
パイプラインをテストして機能していることを確認します。
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}
これでElasticsearchの通常のPythonライブラリを使用してデータを一括で読み込み、インジェストパイプラインが適切にベクトル埋め込みを作成するように設定し、データをLangChainの期待と一致するよう変換する準備ができました。
source .env
python3 step-3B-batch-hosted-vectorize.py登録を完了しました。データはOpenAIでいうと約1,300万トークンのため、これらのベクトルをOpenAIやそれに類するクラウドサービスで生成しようとした場合のコストは約5.40ドルです。Elastic Cloudを使用すると、時間あたり5ドルのコストがかかるマシンで40分かかります。
データを読み込んだら、クラウドコンソールを使用してクラウドMLを再びゼロまたはより合理的な値にスケールダウンすることを忘れないでください。
手順3:『スター・ウォーズ』の豆知識で勝利する
次にLLMとLangChainを試してみましょう。このコードを保持するためにライブラリファイルlib_llm.pyを作成しました。
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued below
このうちtemplate_informedは重要ながらも理解しやすい部分です。何を行っているかというと、コンテキストとユーザーからの質問という2つのパラメーターを使用してプロンプトのテンプレートをフォーマットしています。
上記から続く最終的なメインコードは、次のようになります。
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")
まとめ
いくつかのデータラングリングを行うことで、サードパーティでホストされたLLMにデータを公開することなくAIを利用することができました。AIの世界は急速に変化していますが、プライベートデータのセキュリティとコントロールを維持することは、データ侵害が法的、経済的、人的な影響を及ぼすことからも真剣に考慮する必要があります。この点は変わることはないでしょう。Elasticは、さまざまな顧客と連携しています。検索機能を使用して詐欺を調査しているところもあれば、国家を守る業務に取り組んでいるところや、脆弱な患者コミュニティの転帰を改善させようとしているところもあります。プライバシーは重要です。この分野でどのようにElasticが利用されているか、詳しくは以下を参照してください。
LangChainを気に入っていただけたでしょうか。かつて賢明な年老いたジェダイはこのように言いました。「それは良かった。君はより広い世界への最初の一歩を踏み出した」 ここから進むべき方向は多岐にわたります。LangChainは、AIのプロンプトエンジニアリングの作業から複雑性を取り除きます。Elasticsearchには、他にも生成AIの長期メモリーとして果たすべき役割が多くあります。急速に変化するこの分野から何が生まれるか、楽しみでなりません。
このブログ記事では、それぞれのオーナーが所有・運用するサードパーティの生成AIツールを使用している可能性があります。Elasticはこれらのサードパーティのツールについていかなる権限も持たず、これらのコンテンツ、運用、使用、またはこれらのツールの使用により生じた損失や損害について、一切の責任も義務も負いません。個人情報または秘密/機密情報についてAIツールを使用する場合は、十分に注意してください。提供したあらゆるデータはAIの訓練やその他の目的に使用される可能性があります。提供した情報の安全や機密性が確保される保証はありません。生成AIツールを使用する前に、プライバシー取り扱い方針や利用条件を十分に理解しておく必要があります。
Elastic、Elasticsearch、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。他のすべての会社名および製品名は、各所有者の商標、ロゴ、登録商標である場合があります。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷

