schema on writeとschema on read
Elastic Stackはログを保存する用途に広く使われています。
おそらく多くのユーザーはログを構造化せず、タイムスタンプをパースアウトし、フィルター用の簡単なタグをつけたりするだけで保存を開始しています。Filebeatのデフォルトの挙動もそのようになっています。ログをテイルし、まったく構造化せずに、できる限り早くElasticsearchに送る仕様です。KibanaのLogs UIも特にログの構造を想定していません。“@timestamp”と“message”のシンプルなスキーマだけで十分動作します。Elasticでは、この方法をロギングのミニマルスキーマアプローチと呼びます。このアプローチでは、簡単な手順でディスクに保存することができます。しかし、シンプルなキーワード検索や、タグベースのフィルタリング以上のことをやろうとする場合にはあまり便利ではありません。
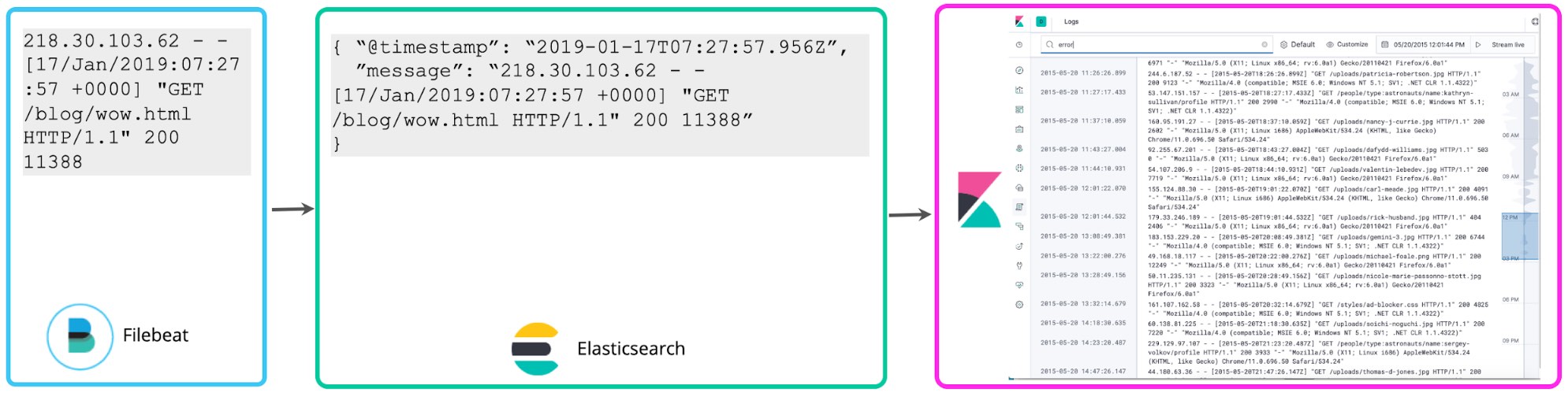
収集したログについて一通りのことがわかったら、大抵の場合、より多くのことをやりたくなります。たとえば複数のログとステータスコードに関連性があると気付いた場合、次は、過去1時間の間に発生した5xxレベルのステータスコードの数を可視化したくなるかもしれません。Kibanaのスクリプテッドフィールドでは、検索時にログに対してスキーマを適用し、このようなステータスコードを抽出してアグリゲーションや可視化、その他の操作を実行することができます。ロギングにおけるこのようなアプローチは、schema on readと呼ばれます。
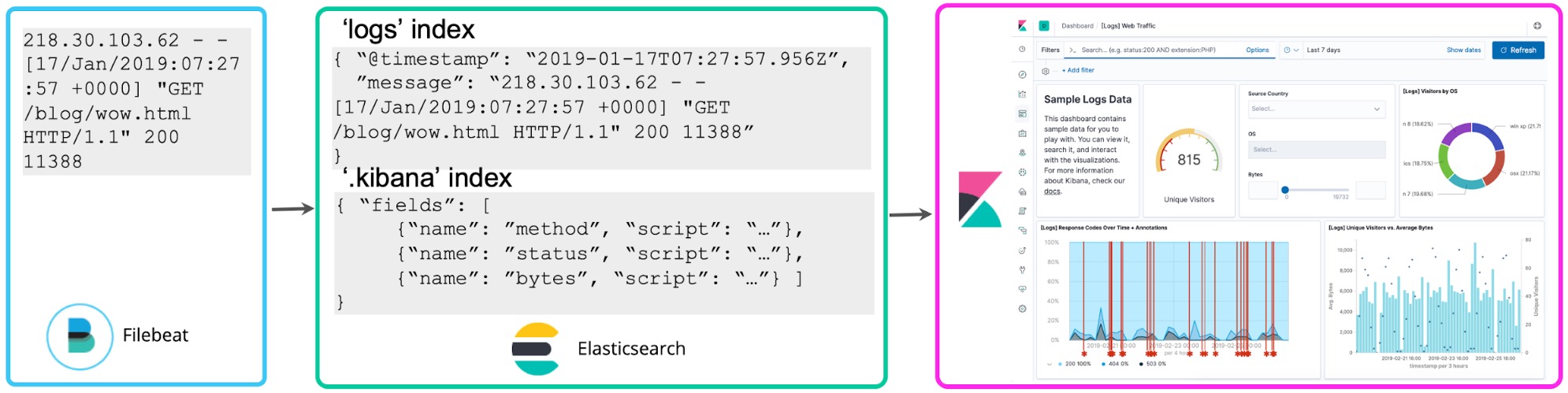
アドホックな探索には便利ですが、このアプローチには欠点もあります。継続して使用するレポートやダッシュボードに適用すると、検索や可視化の再レンダリングを実行するたび、フィールドからの抽出も再実行しなければなりません。では、はじめに必要なフィールドを構造化しておくとどうでしょうか?バックグラウンドで再インデックスプロセスを開始して、永続するElasticsearchインデックスの構造化されたフィールドにスクリプテッドフィールドを“存続”させておくことができます。またElasticsearchへのデータストリーミングにはLogstashまたはを設定し、dissectあるいはgrokプロセッサーで前もって上述のフィールドを抽出するようにします。
ここから、3つ目のアプローチも考えることができます。すなわち、書き込み時点でログをパースし、上述のフィールドを前もって抽出するというアプローチです。このようにして構造化されたログを分析するアプローチでは、複数のメリットがあります。後からフィールドを抽出する要件について悩む必要がなく、クエリを高速化でき、ログデータから得られる価値も高まります。“schema on write”でログ分析を一元化するこのアプローチは、多くのElastic Stackユーザーに支持されています。
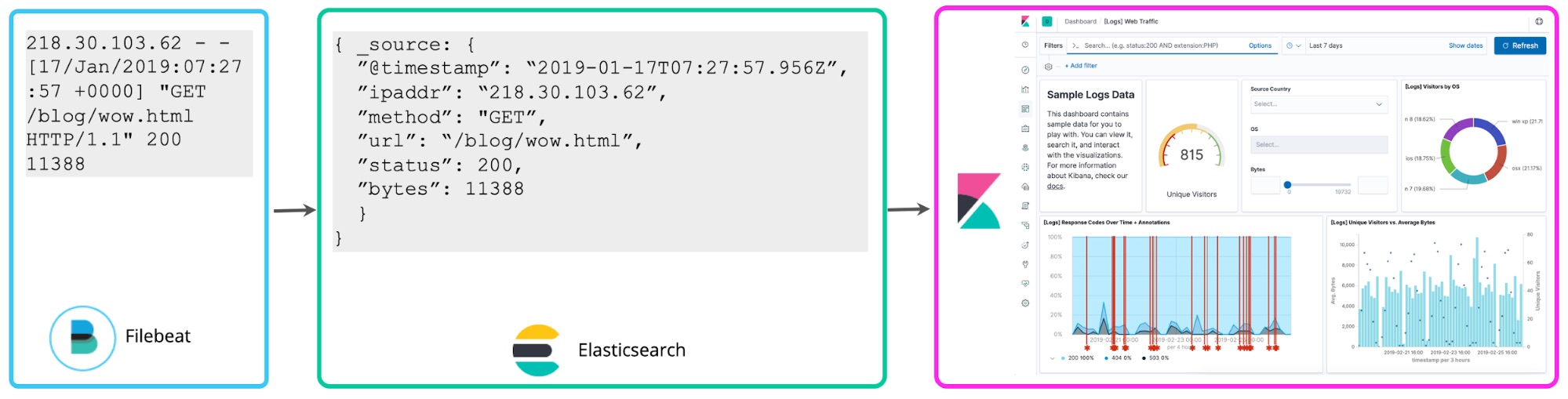
このブログ記事では2つのアプローチの短所も説明し、ロギングの計画を立てる際の考え方もご紹介します。以下では、あらためてログを事前に構造化することの本質的な価値と、事前の構造化を行わずにはじめたケースでも、ロギングのデプロイに習熟するにつれてこのアプローチに自然と行き着く理由をご説明します。
Schema on writeの長所と短所
一元的なロギングクラスターに書き込む際に、ログを構造化する理由やメリットは何でしょうか?
クエリのエクスペリエンスを向上させるため。 情報を求めてログを検索する場合、普通は“error”のようなシンプルなキーワードで検索を開始するはずです。この場合、転置インデックス内で各ログ行を1つのドキュメントとして扱い、全文検索を実施することでクエリの結果を返すことができます。しかし、「my_fieldがNであるすべてのログ行を表示する」など、複雑な問いの場合はどうでしょうか? まずmy_fieldというフィールドをあらかじめ定義しておかなければ、このような質問を直接することはできません(自動入力はありません)。たとえログにこの情報があるとわかっていても、期待値との比較を行うには、このフィールドを抽出するクエリでパースするルールを書く必要があります。Elastic Stackでは事前に構造化されたログに対し、Kibanaの自動入力機能がフィールドや値を自動的に提案してクエリの構築をサポートします。分析の生産性に大きく貢献することがおわかりいただけると思います。構造化しておくことで、あなたも同僚も、どのフィールドがどうなっているか悩んだり、フィールドを抽出するために複雑なパースのルールを書くことなく、直接クエリを実施することが可能になります。
時系列クエリとアグリゲーションが速くなる。 Elastic Stackで構造化したフィールドをクエリすると、大量の時系列データで実施する場合でも、ミリ秒単位で結果が返されます。典型的な“schema on read”型のシステムでは数分から数時間もかかる処理です。このような差が付く理由は、数学的に考えるとわかりやすくなります。つまり、フィールドの抽出と操作のためにすべてのログ行でregexを実行するよりも、構造化したフィールドを抽出し、かつ事前にインデックスしてから統計的なアグリゲーションをフィルタリング/実行する方がはるかに高速です。アドホックなクエリを実施するユースケースでは特にこの点が重要です。調査でどのようなクエリを実行するか事前にわからなければ、事前に準備することは不可能だからです。
ログをメトリックとして扱える。 上記の内容にも関連しますが、構造化されたログから数的な値を抽出した結果は、意外にも時系列ログ、あるいはメトリックのように見えます。運用の観点では、データポイント上ですばやくアグリゲーションを実行できることに、大きな価値があります。フィールドを構造化することで、大規模なログ中の数的なデータポイントをメトリックとして扱うことが可能になります。
時間とともに変化するソースで「正解」を見つける。 ホスト名を求めるためにIPアドレスのようなフィールドを解決する場合、クエリ時ではなく、インデックス時のログで解決する必要があります。後から解決しても、トランザクションが行われた(より早い)時点で有効ではなかった可能性があるからです。そのIPアドレスも、1週間後には完全に異なるホスト名にリンクされているかもしれません。このメリットが当てはまるのは、マッピングにおいて最新のスナップショットのみ提供する外部ソースを参照する場合です。たとえばID管理システムに対するユーザー名解決や、CMDBに対するアセットタグなどが該当します。
リアルタイムな異常検知とアラートを可能にする。 アグリゲーションと同様、大規模なデータでのリアルタイムな異常検知と通知は、構造化されたフィールドを使用するとき最も効率的に動作します。事前に構造化しない場合、クラスター上で継続的な処理を実施する要件は非常にややこしくなります。「検索時のフィールド抽出を必要なアラート数の規模に拡張させることができず、アラートの作成と異常検知を導入できていない」というお客様も多くいらっしゃいます。こうなると、収集しているログデータが大規模にリアクティブなユースケースにしか適さず、プロジェクトの投資利益率を押し下げているということになります。
可視性の取り組みにログを活用できる。 可視性の向上に取り組んでいる方は、「ログの収集と検索だけでは不十分」であることにすでにお気づきかもしれません。本来ログデータはメトリック(例:リソース使用状況)やアプリケーション追跡データと関連付けられるべきものです。関連付けることで、データポイントを問わず、運用者はサービスで何が起きているか包括的に把握することが可能になります。このような関連付けも、構造化されたフィールドで最適に行うことができます。構造化されていない場合、大規模なデータではルックアップが遅くなり、実用的ではありません。
データの質を確保できる。 事前の処理を前提とするイベントでは、無効、重複、不足しているデータを確認し、問題のデータを訂正する機会があります。一方、schema on readアプローチを使用すると、データ自体の有効性や完全性を事前に検証していないため、正しく返された結果なのかがわかりません。有効でないデータから、不正確な結果や誤った結論を導いてしまう可能性があります。
アクセスを細やかに制御できる。 構造化されていないログデータに、フィールドレベルの制限といった細かなセキュリティルールを適用することは簡単ではありません。検索でアクセスするデータを制限するフィルターは役立つかもしれません。しかし、フィールドのサブセットからなる部分的な結果を返すことができないなど、検索に大きな制約を課すことになってしまいます。Elastic Stackが提供するフィールドレベルのセキュリティ機能では、一部のフィールドのみ閲覧でき、データセット全体のほかの部分を閲覧できないようにユーザーの権限を制限することができます。これにより、ログ中の個人情報データを保護しながら多数のユーザーに他の情報データの操作を許可するといった設定も、柔軟かつ簡単に行うことができます。
ハードウェア要件
“schema on write”アプローチに関する一般的な認識の1つに、「ログをパースしたり、パースしていないフォーマットとパースされた(あるいはインデックスされた)フォーマットの両方を保存することになり、クラスターがより多くのリソースを必要とする」というものがあります。この認識が正しいかどうかは、状況によります。ここでは、ユースケースごとに検討してみます。
一度限りのパースvs継続的なフィールド抽出: ログを構造化したフォーマットにパースして保存する処理は、Ingest側の容量を消費します。しかし、構造化されていないログで継続的にクエリを実行し、フィールドを抽出するために複雑なregexステートメントを実行すれば、長期的にはその方がはるかにRAMとCPUを消費します。保存するログの検索はごくたまにしか行わないというユースケースを予定している場合、事前の構造化に容量を消費する必要はないと言えます。一方、頻繁にログをクエリしたり、ログデータをアグリゲーションすることが予測されるユースケースでは、投入時の一度限り投資することで、長期的には運用コストを節約できる可能性が高くなります。
投入要件: 何もしない場合に比べ、事前に追加処理を行うことで投入のスループットが下がる可能性があります。そこで、ElasticsearchのIngestノード、またはLogstashインスタンスを独立にスケールさせて、負荷を管理する投入インフラストラクチャーを追加することができます。最適なリソースも揃っており、具体的なアプローチもブログ記事で紹介されています。またElastic CloudでElasticsearch Serviceをご利用の場合は、"投入対応"ノードを追加するだけでスケールさせることができるので非常に簡単です。
ストレージ要件: すぐにはピンとこないかもしれません。実はログの構造を事前に把握するために何らかの作業を行う場合、ストレージ要件はより低くなります。これは、ログが冗長で、多くのノイズを含む傾向があるためです。こうしたログを事前に調査することにより(すべてのフィールドを完全にパースしない場合でも)、どのログ行や抽出済みフィールドを検索用に一元化したログクラスターに入れるか、何をアーカイブするか決定することができます。この作業が、ログを保存するディスク要件を引き下げることにつながります。Filebeatにはこうした目的に最適なdissectプロセッサーやdropプロセッサーがあります。
「法令や規制に準拠するためすべてのログ行を保存する必要がある」という場合も、“schema on write”でストレージコストを最適化する複数の方法があります。まず、ログの構造化はユーザーが自由に制御できるもので、必ずしも完全に構造化する必要はありません。重要な部分にだけ構造化したメタデータを追加し、残りのログ行はパースしないでおく、ということも可能です。一方、ログを完全に構造化すれば、ストレージ上でも重要なデータのあらゆる部分が構造化されます。したがってログをインデックスした同じクラスターに“source”フィールドを保つ必要がなく、安価なストレージにアーカイブすることが可能になります。
それでもストレージについて懸念がある場合、デフォルトのElasticsearchをさまざまな方法で最適化することができます。わずかな作業で、圧縮比を確認することができるようになります。また、保存期間が長く、アクセス頻度が乏しいデータを分離してストレージの効率を高めるHot-Warmアーキテクチャーやフローズンインデックスを活用することもできます。Hotデータに関しては、必要なクエリの結果を数分も待つことを考えれば、高速なストレージを使用する費用は決して高くありません。その点も心に留めておきましょう。
事前に構造を定義する
もう1つ、schema on writeアプローチに関する一般的な認識に「ログの事前構造化は難しくて大変」というものがあります。この認識は果たして正しいでしょうか?検証してみましょう。
すでに構造化されたログ: 多くのログがすでに構造化されたフォーマットで生成されています。多くの一般的なアプリケーションはJSONへのロギングを直にサポートしています。この場合、ログを一切パースせずElasticsearchに直接投入するだけで、構造化されたフォーマットで保存できるということになります。
プリビルトのパースルール: Elasticがオフィシャルにサポートするプリビルトのパースルールは多数存在します。たとえば一般的なベンダーのログを構造化するFilebeatモジュールや、Logstashに含まれる拡張可能なgrokパターンライブラリなどがあります。コミュニティが開発・提供するプリビルトのパースルールも日々増えています。
自動生成のパースルール: カスタムログからフィールドを抽出するルールを定義する際、パースの方法を自動で提案するKibana Data Visualizerなどのツールが役立ちます。ログサンプルをコピーペーストしてgrokパターンを取得し、IngestノードやLogstashで使うことができます。
ログフォーマットの変更に対応する
schema on writeアプローチに関するよくある認識として、最後に「schema on writeアプローチではログフォーマットの変更の際に大変になる」というものを取り上げたいと思います。平たく言って、この認識は誤りです。ログを使用して単なる全文検索以上のインテリジェンスを取得するには、どのアプローチを使う場合でも誰かがログフォーマットの変更に対応する必要があります。インデックス時にログをgrokするIngestノードパイプラインを使用している場合でも、検索時に同じ処理を行うKibanaスクリプテッドフィールドを使用している場合でも、ログフォーマットが変更になればフィールドを抽出するロジックにも修正が必要です。Elasticが公開するFilebeatモジュールについて、Elasticはアップストリームのログベンダーが公開する新しいバージョンを確認し、互換性テスト済みモジュールを更新しています。
書き込み時に、ログ構造の変更に対応する方法は複数あります。
パースロジックを事前修正する: ログフォーマットの変更があらかじめわかっている場合は、並列な処理パイプラインを作成して両方のログバージョンをサポートできるようにし、移行の期間中はそれらを使用するようにします。通常、ログのフォーマットを社内で制御できる場合に用いる方法です。
パースのフェイルでは、ミニマルスキーマを書き出す: 事前に変更を把握できるケースばかりではありません。ログを外部で制御している場合、変更の事前通知がないこともあります。その場合、早いタイミングでログパイプラインから変更を把握することができます。grokパースがフェイルした場合、タイムスタンプとパースされていないメッセージのミニマルスキーマを書き出し、運用者にアラートを送信します。その時点で、新しいログフォーマット用にスクリプテッドフィールドを作成することが可能になります。これにより、分析ワークフローの障害を回避し、その後のパイプラインを修正することができます。さらに、パースロジックに障害が生じていた短い期間のために、フィールドの再インデキシングを検討します。
パースがフェイルしたイベントの書き出しを遅らせる: ミニマルスキーマを書き出す方法が使えない場合、パースロジックでエラーが生じている間はログ行の書き出しを行わないというやり方もあります。イベントを一時的に“dead letter queue”(Logstashですぐに使いはじめることができる機能です)に入れ、運用者にアラートを送ります。その後運用者がロジックを修正し、新しいパースパイプラインでdead letter queueのイベントを再実行するという方法です。分析には障害が起きますが、スクリプテッドフィールドや再インデックスを扱う必要がありません。
うまい喩えで学ぶ
この記事も長くなってきました。ここまで読んでくださった方に... ありがとうございます!さて、新しいコンセプトを学ぶとき"ぴったりの比喩"が役立つことがよくあります。最近、Elasticの同僚でセキュリティスペシャリストのネイル・デサリのスピーチに“schema on read”と“schema on write”に関する素晴らしい喩えがあったのでご紹介しましょう。

おわりに – 最適解はユースケース次第
冒頭でもご説明しましたが、一元的なロギングのデプロイで“schema on write” vs “schema on read”を考えるとき、「あらゆるユースケースににフィットする正解」を考える必要はありません。実際のところ、“schema on write”と“schema on read”の中間のようなデプロイも多くあります。たとえば一部のログは高度に構造化し、ほかの部分は最も基本的なスキーマ(@timestampとmessage)のままにする、といったことです。ログで何をするかや、構造化したクエリのスピードや効率をどの程度重視するか、あるいは事前に何も設定せずできるだけ早くディスクに書き出しはじめることにどの程度価値を見出すかによって最適な解は変わります。Elastic Stackはどちらのアプローチもサポートしています。
Elastic Stackを使ったログの保存は、Elasticsearch Serviceでクラスターを設定するか、ローカルにダウンロードしてすぐにはじめることができます。またあらゆるタイプやフォーマット(構造化・非構造化の双方)でログ処理のワークフローを最適化するKibanaのLogsアプリケーションもチェックしてみてください。