Elastic Common Schema 소개
Elasticsearch에서 일관되고 사용자 정의가 가능한 데이터 구조화 방법을 제공하여 다양한 소스로부터 데이터 분석을 쉽고 빠르게 실행할 수 있는 새로운 사양인 Elastic Common Schema(ECS)를 소개합니다. ECS를 사용하면 대시보드와 머신 러닝 작업과 같은 분석 콘텐츠를 좀더 폭넓게 적용할 수 있고, 검색을 한결 세부적으로 조정할 수 있으며, 필드 이름을 더욱 쉽게 기억할 수 있습니다.
공통 스키마를 사용해야 하는 이유
대화형 분석(검색, 드릴다운, 피봇팅, 시각화 등)을 수행하든 자동화 분석(알림, 머신 러닝에 기반한 이상 징후 탐색 등)을 수행하든, 데이터를 일관되게 분석할 수 있어야 합니다. 그러나 데이터가 오직 하나의 소스로부터 비롯되는 경우가 아니라면, 다음과 같은 이유로 형식상의 불일치에 직면하게 됩니다.
- 서로 다른 데이터 유형(로그, 메트릭, APM, 흐름, 상황 자료 등)
- 다양한 협력업체 기준에 따른 이질형 환경
- 비슷하지만 다른 데이터 소스(Auditbeat, Cylance, Tanium 같은 여러 끝점 데이터 소스)
여러 소스로부터 비롯된 데이터 내에서 특정 사용자를 검색한다고 생각해 봅시다. 이 필드 하나를 검색하기 위해서도 user, username, nginx.access.user_name, login과 같은 여러 필드 이름을 참조해야 할 가능성이 높습니다. 해당 데이터를 드릴링하고 피봇팅하는 것은 훨씬 더 어려운 일이 될 것입니다. 이제 시각화, 알림, 머신 러닝 작업 같은 분석 콘텐츠를 개발한다고 상상해 봅시다. 각각의 새로운 데이터 소스가 더해질 때마다 복잡성이나 중복성이 증가하게 될 것입니다.
Elastic Common Schema란?
ECS는 Elasticsearch로 수집되는 데이터에 대해 공통된 문서 필드 세트를 정의하는 오픈 소스 사양입니다. ECS는 균일한 데이터 모델링을 지원하기 위해 마련되었으며, 사용자가 대화형 기술과 자동화 기술을 둘다 사용해 다양한 소스에서 비롯된 데이터를 중앙에서 분석할 수 있게 해줍니다.
ECS는 목적을 위해 만들어진 분류의 예측 가능성과 사용자 정의된 사용 사례에 맞춘 포괄적인 사양의 융통성을 모두 제공합니다. ECS의 분류는 다음 세 가지 레벨로 구성되는 필드에서 데이터 요소를 배포합니다.
| 레벨 | 설명 | 추천 |
| ECS 핵심 필드 | 정의된 ECS 최상위 수준 개체 세트 하에 존재하는 완전히 정의된 필드 이름 세트 | 이 필드는 대부분의 사용 사례에서 공통되기 때문에 여기서 작업을 시작해야 합니다. |
| ECS 확장 필드 | 동일한 ECS 최상위 수준 개체 세트 하에 존재하는 부분적으로 정의된 필드 이름 세트 | 확장 필드는 보다 좁은 사용 사례에 적용될 수 있으며 사용 사례에 따라 좀더 열린 해석이 가능합니다. |
| 사용자 정의 필드 | ECS 필드 또는 개체와 상충되지 않아야 하는 사용자 제공 비-ECS 최상위 수준 개체 세트 하에 존재하는 정의되지 않고 명명되지 않은 필드 세트 | 이 필드 위치에 ECS에서 상응하는 필드가 없는 필드를 추가할 수 있으며, 또한 데이터를 ECS로 전환할 때와 같은 경우에 여기에 원래 이벤트 필드의 복사본을 유지할 수 있습니다. |
Elastic Common Schema 실행
사례 1: 구문 분석
ECS를 다음 Apache 로그에서 실행해 봅시다.
10.42.42.42 - - [07/Dec/2018:11:05:07 +0100] "GET /blog HTTP/1.1" 200 2571 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
이 메시지를 ECS로 매핑하여 다음과 같은 방식으로 로그의 필드를 구성합니다.
| 필드 이름 | 값 | 참고 |
| @timestamp | 2018-12-07T11:05:07.000Z
| |
| ecs.version | 1.0.0
| |
| event.dataset | apache.access
| |
| event.original | 10.42.42.42 - - [07/Dec ...
| 수정되지 않은 감사 로그 전체 |
| http.request.method | get
| |
| http.response.body.bytes | 2571
| |
| http.response.status_code | 200
| |
| http.version | 1.1
| |
| host.hostname | webserver-blog-prod
| |
| message | "GET /blog HTTP/1.1" 200 2571
| 로그 뷰어에서 간결하게 표시하기 위한 이벤트 중요 정보의 텍스트 표현 |
| service.name | Company blog
| 이 서비스에 대해 사용자가 정의한 이름 |
| service.type | apache
| |
| source.geo.* | 지리적 위치를 위한 필드 | |
| source.ip | 10.42.42.42
| |
| url.original | /blog
| |
| user.name | -
| |
| user_agent.* | 사용자 에이전트를 설명하는 필드 |
위에 나와 있듯이, 원시 로그는 감사 사용 사례를 지원하기 위해 ECS의 event.original 필드에 보존됩니다. 편의상, 이 사례에서는 모니터링 에이전트에 대한 세부사항(agent.* 하에 있음)과 호스트에 대한 일부 세부사항(host.* 하에 있음), 그리고 좀더 많은 필드를 생략합니다. 좀더 완전한 표현은, 이 JSON의 사례 이벤트를 검토해 보세요.
사례 2: 검색
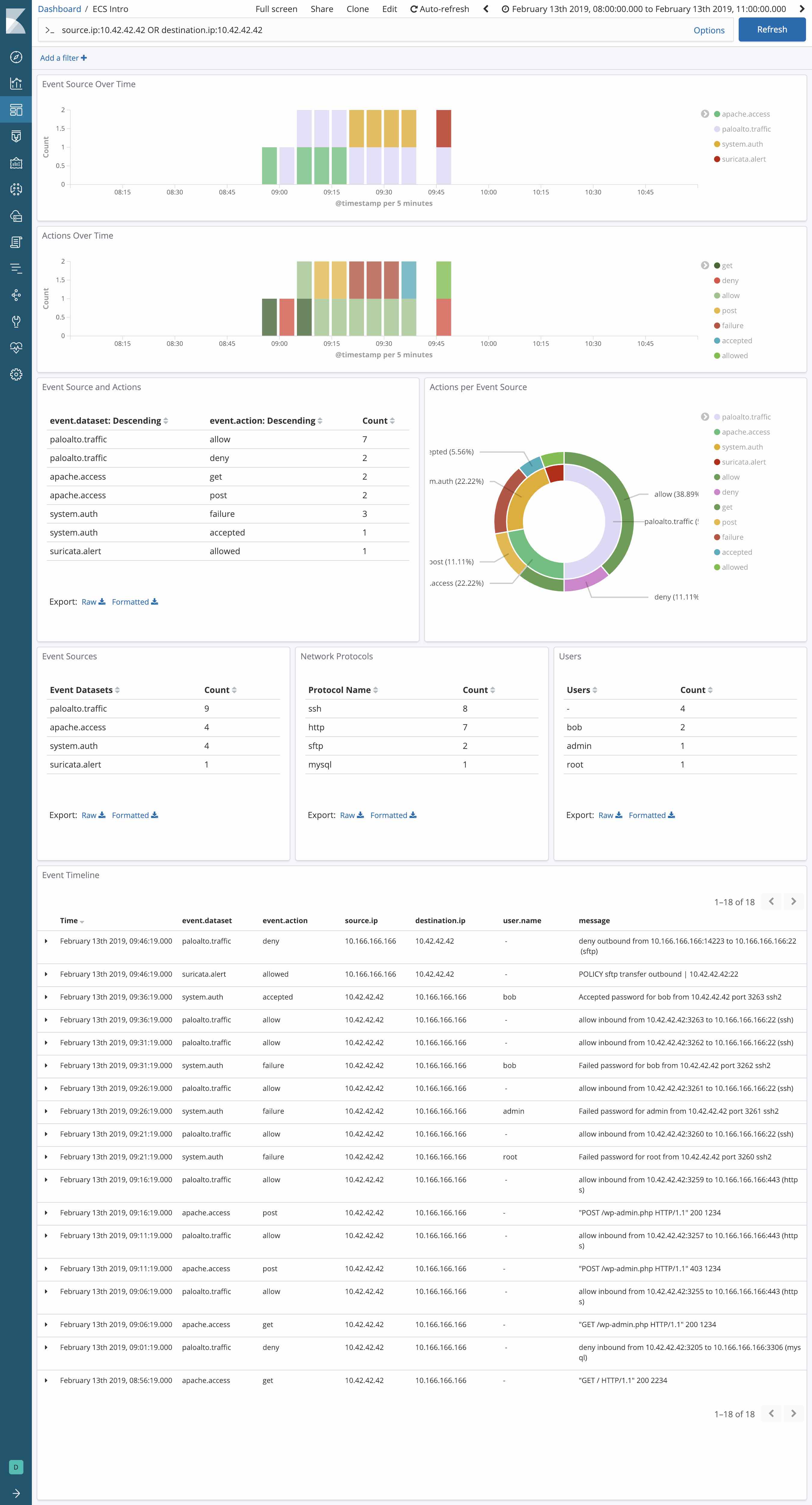
Palo Alto Networks Firewall, HAProxy(Logstash에서 처리된 대로), Apache(Beats 모듈 사용), Elastic APM, 그리고 추가로 Suricata IDS(사용자 정의, EVE JSON 형식 사용) 등의 전체적인 웹 스택에서 특정 IP의 활동에 대해 조사한다고 생각해 봅시다.
ECS를 사용하기 전이라면, 이 IP에 대한 검색은 이렇게 보였을 것입니다.
src:10.42.42.42 OR client_ip:10.42.42.42 OR apache2.access.remote_ip:10.42.42.42 OR context.user.ip:10.42.42.42 OR src_ip:10.42.42.42
그러나 ECS로 모든 소스를 매핑한 경우, 쿼리가 다음과 같이 훨씬 간단해집니다.
source.ip:10.42.42.42
사례 3: 시각화
여러 다른 데이터 소스로부터 균일하게 정규화된 데이터에 어떻게 적용될 수 있는지를 보면 ECS의 강력함이 훨씬 더 쉽게 드러납니다. 사용자는 위협 감지를 위해 경계선에 있는 Palo Alto Next-Gen Firewall 및 Suricata IDS가 생성하는 이벤트와 알림 등 여러 네트워크 데이터 소스를 이용해 웹 스택을 모니터링하고 있을 수 있습니다. 어떻게 각 메시지로부터 source.ip와 network.direction 필드를 추출하여 Kibana에서 중앙화된 시각화를 활성화하고, 협력업체를 불문하고 드릴다운 및 피봇팅을 활성화할 수 있을까요? ECS를 이용하면 물론 사용자가 그 어느 때보다도 쉽게 중앙화된 모니터링을 수행할 수 있습니다.
Elastic Common Schema의 장점
ECS 실행은 검색, 드릴다운, 피봇팅, 데이터 시각화, 머신 러닝 기반의 이상 징후 탐색, 알림 등 Elastic Stack에서 이용할 수 있는 모든 모델 분석을 통합합니다. 완전히 적용되면, 사용자는 구조적 및 비구조적 쿼리 매개 변수 양쪽 모두의 성능을 이용해 검색할 수 있습니다. 또한 ECS를 통해 단일 협력업체의 여러 다른 장치든 또는 완전히 다른 데이터 소스 유형이든, 여러 다른 데이터 소스에서 비롯된 데이터의 상관 관계를 간편하게 자동으로 지정할 수 있습니다.
ECS는 또한 팀이 분석 콘텐츠 개발에 들이는 시간을 단축시켜 줍니다. 조직에서 새 데이터 소스를 추가할 때마다 매번 새로운 검색과 대시보드를 만드는 대신, 기존의 검색과 대시보드를 계속 활용할 수 있게 됩니다. ECS는 또한 사용자의 환경에 맞춰 Elastic이든, 파트너이든, 오픈소스 프로젝트이든, ECS를 사용하는 다른 당사자들로부터 훨씬 더 쉽게 직접 분석 콘텐츠를 채택할 수 있게 해줍니다.
대화형 분석을 수행할 때는 각 데이터 소스마다 여러 다른 세트가 있는 게 아니라 단 하나의 세트만 있기 때문에 ECS가 흔히 사용되는 필드 이름을 더 쉽게 기억합니다. 잊혀진 필드 이름을 추론하는 것 또한 ECS를 사용하면 더 쉽습니다. (몇 가지 예외만 제외하고) 사양이 간단한 표준 명명 규칙을 따르기 때문입니다.
ECS 사용을 시작하고 싶지 않으세요? 걱정하실 필요 없습니다. 필요할 때 사용하실 수 있고 원치 않으실 때는 꼭 사용하지 않으셔도 됩니다.
Elastic Common Schema 시작하기
ECS는 public GitHub repo를 통해 검토해 보실 수 있습니다. 사양은 현재 베타2 상태이며 곧 정식 출시될 예정입니다. Apache 2.0 오픈 소스 라이선스에 따라 게시되어 있으므로 더 광범위한 Elastic 커뮤니티에서 보편적으로 채택할 수 있습니다.
정말 편리하고 환상적이지 않나요? 모든 스키마가 그렇듯이, ECS 실행은 간단한 일이 아닙니다. 그러나 이미 Elasticsearch 인덱스 템플릿을 구성하셨고 Logstash나 Elasticsearch 수집 노드로 변환 함수 몇 개를 작성하셨다면, 여기에 어떤 작업이 수반되는지 금방 알아차리실 것입니다. Elastic Beats 모듈의 향후 버전은 기본적으로 ECS 형식 이벤트가 제공되므로 이 부분을 더욱 원활하게 전환할 수 있습니다. 여러 가지 중에서 첫 번째로 새로운 Auditbeat 시스템 모듈이 소개될 예정입니다.
Elastic Common Schema(ECS) 웨비나를 보시면 ECS에서 대해 더 자세히 알아보실 수 있습니다. 나중에 블로그 포스팅을 통해 데이터를 ECS에 매핑하는 방법(스키마에서 정의되지 않은 필드 포함)과 ECS로 마이그레이션하는 방법에 대해 다루어 보겠습니다.