You have more ways to bake this cake: Bring your own Enterprise Search connector


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
The Elastic Enterprise Search team is working on an exciting new project: Elastic Enterprise Search Connectors framework. It appeared in version 8.2 as a Technical Preview, and it has been significantly expanded in 8.3.
Elastic Enterprise Search, and specifically Workplace Search, is a solution that helps harness the power of Elasticsearch to search over company documents. The documents may come from a variety of sources, and the primary means of ingesting data into Workplace Search are connectors, which are easy-to-use, no-code, GUI-driven features that makes ingesting data a breeze.
Before we dive into the details, here’s an important vocabulary to be familiar with:
- Content source - data indexed into Elastic Enterprise Search and backed by a third-party service like GitHub, GoogleDrive, Salesforce and others
- Connector - code that connects to a third-party service and facilitates the ingestion of data into a content source
The Connector configures the content source. The content source has the actual data.
[Related article: Search, observe, and protect everything, across any environment with Elastic 8.3]
While Workplace Search provides a robust connector catalog for many of the popular third-party data services that house company documents (like GitHub, Confluence, SharePoint, and many others), it doesn't have connectors for everything. So, the Elastic Enterprise Search Connectors framework was created to help users bring their own connectors, or customize the ones that already exist.
How does one use the Elastic Enterprise Search Connectors framework? The framework provides the boilerplate, along with connector packages to accelerate your development. You need to implement several methods to complete the interface. This post walks you through how to do that, using GitLab as an example.
Find all source code for the example GitLab connector shown in this tutorial, plus source code for the entire Connectors framework, in the Connectors framework repository.
The connector
If you've been using Workplace Search, which is a part of Elastic Enterprise Search, you probably know what a connector is, right? It's this thing:
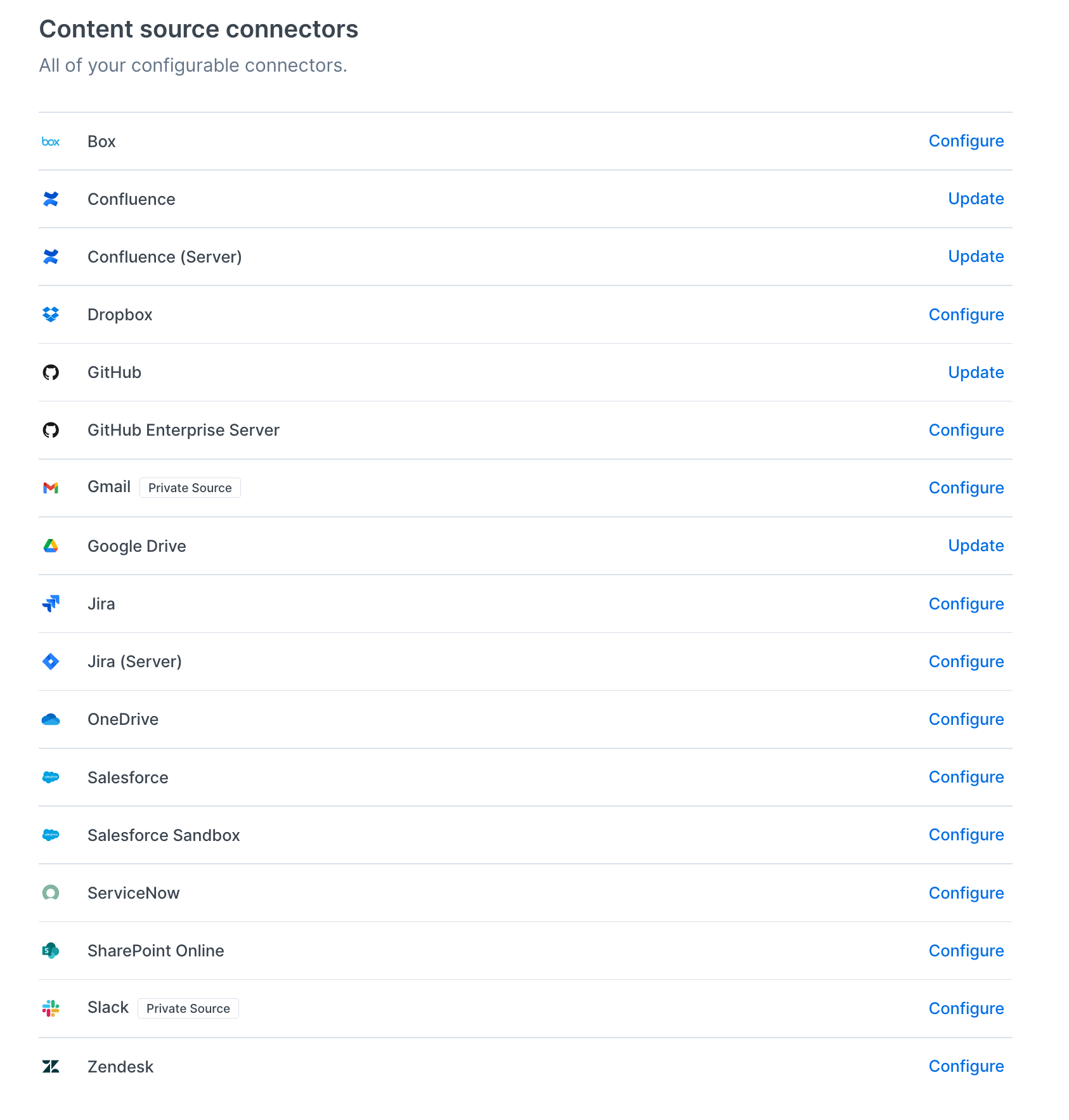
In the simplest words, a connector is a way to connect — in our case, to a third-party source of data. Why? Well, to ingest it by creating content sources, of course! Why? So that the power of Enterprise Search, and specifically Workplace Search, can be fully yours.
Let's talk about Workplace Search. The idea is great: having all your data in one place, right at your fingertips, and a unified search facade to find exactly what you want. It allows you to stop wasting a lot of time trying to recall where that specific thing was discussed. Was it a ticket in the support system? Or an email? Perhaps a wiki page? Or maybe something in Google Docs? Workplace Search allows you to create a single UI to allow for searching over all of these. It's a great solution… until it's not.
So what's less than great?
The most common questions users have for Workplace Search are:
- What if my specific data source isn't covered in out-of-the-box connectors catalog?
- What if it is covered, but some object types aren't indexed?
- What if you index the types of objects I don't need?
- What if the standard connector does index the things I want, but not the way I want?
- What if I have a custom authentication mechanism I need to use for my connector?
Some of these questions can be resolved by custom sources and their APIs. However, some users find a custom source to be more heavy weight than they need. It's a clean slate that a developer can use to build their own custom solution, but it means that the whole synchronization part needs to be addressed on the custom source side. When developing a custom source, you are responsible for handling questions like:
- How often do I sync the data?
- What types of sync operations do I need?
- What if something breaks? How do I restart the data synchronization process?
- … and so on.
And it's all well and good, with the exception of the fact that Enterprise Search already does it for you. With the standard sources, that is. So why should the developer reinvent the wheel, when there's something already implemented?
The answer is, they might if they want to. For customers who need that type of control, there's the custom sources mechanism mentioned above, and there are also open code connector packages available that utilize that mechanism and can be copied and reworked as needed.
But if they want to simplify the development process, then the Connectors framework comes in handy. While a custom source leaves those questions to the developer to try and resolve on their own, in the Connectors framework, the assumption is that the same synchronization model of Enterprise Search that applies to out-of-the-box connectors will be reused. So, Enterprise Search will be initiating the connection and pulling the content at scheduled times.
Open Code Software — get the synergy
The new Elastic Enterprise Search Connectors framework provides free and open tools to get your data into Elastic. The code repository is public, and the contributions that you make to it may be seen by other developers, and improved, and iterated upon. Because the framework is a tech preview feature and will keep evolving to better support building a connector, your contributions will help shape its future! Take a look at the code and get engaged in the project — and sign up for user feedback sessions, or give us earlier feedback on what you wish you could customize.
Synchronization model
To quickly summarize, Enterprise Search runs the following recurring sync jobs to keep first-party connectors current:
- Full sync (every 72 hours): get all the documents.
- Incremental sync (every 2 hours): sync updates to the data.
- Deletion sync (every 6 hours): for document deletions from the content source.
- Permissions sync (every 5 minutes, when document-level permissions are enabled): synchronizes document permissions from the content sources.
These are the defaults, but the synchronization schedule can be changed, provided one has a Platinum-level license (or higher). You can find more information about the synchronization model in the Workplace Search documentation.
Step 1. Look at the GitLab Connector
For this step, we assume that you already have a local deployment of Enterprise Search to tinker with. If not, please use this installation instruction to run it in Docker. The local installation will allow us to connect to the also-local connector deployment — if your Enterprise Search ran in Cloud, you'd have to provide a public-facing connector URL for it.
Let's use a data source that doesn't yet have an out-of-the-box connector. Since we're developers, it's logical to take a look at something dev-related, like a version control system. From the list of first-party content sources, we can see that Workplace Search does have a connector for GitHub. But not for Gitlab or Bitbucket! Guess what — those are the most standard asks from developer users.
So, let's be ambitious and go through building one of these: the GitLab connector. I already have the code for it prepared in a branch, so we’ll walk through the created code and see what exactly is in it and how it all ties together.
First, we’ll check out the GitHub repository for Connectors framework.
git clone git@github.com:elastic/connectors.git
cd connectors
git fetch
# make sure you're on a release branch and not on the main!
git checkout 8.3Let's get the code and look at the app.rb file in the root directory. There are two lines of code that draw attention to what's going on there.
set :connector_class, ConnectorsSdk::Base::REGISTRY.connector_class(settings.connector_name)and:
connector = settings.connector_class.newLet's see what the ConnectorsSdk::Base::REGISTRY holds, then.
require_relative '../gitlab/connector'
REGISTRY.register(ConnectorsSdk::GitLab::Connector::SERVICE_TYPE, ConnectorsSdk::GitLab::Connector)This is where we register our GitlabConnector — the main class that holds the connector code and ties together several other classes. And this is how it begins.
module ConnectorsSdk
module GitLab
class Connector < ConnectorsSdk::Base::Connector
SERVICE_TYPE = 'gitlab'
def display_name
'GitLab Connector'
endFirst of all, we see that it inherits from class Connector < ConnectorsSdk::Base::Connector, so there's some wiring being done there. But also, the connector implements or overrides several things.
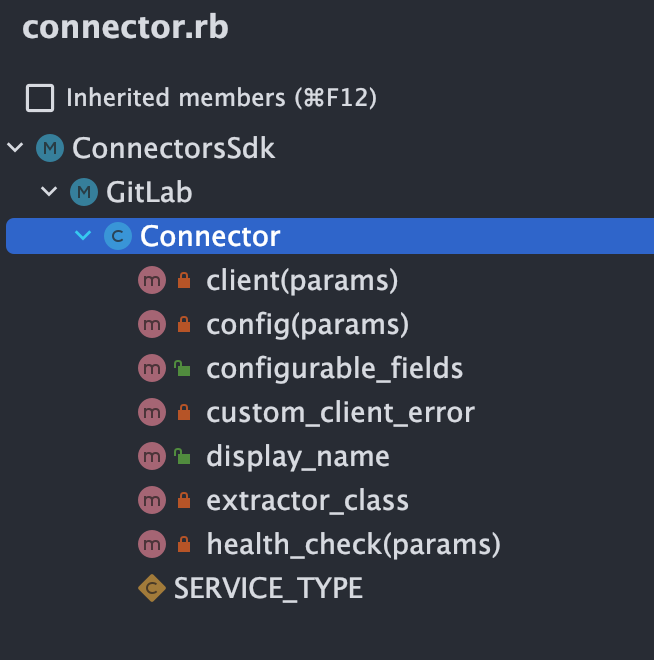
We can see that there's a client(params) and config(params) and extractor_class. These methods reference other classes that we created specifically for this connector:
- ConnectorsSdk::GitLab::CustomClient
- ConnectorsSdk::GitLab::Config
- ConnectorsSdk::GitLab::Extractor
We will explore those, too. But now, we need to jump back a bit and think about our needs on the other side — that is, what we need from GitLab.
Step 2. Setting up GitLab
We need to use its REST APIs to get the data. There seem to be a lot of APIs in there! But no worries, we'll start simple. First of all, we need to look at the authentication options for the third-party API, and fortunately, there are a few. Rather than setting up a full OAuth flow though, I will go with a personal API token. Let's create one.
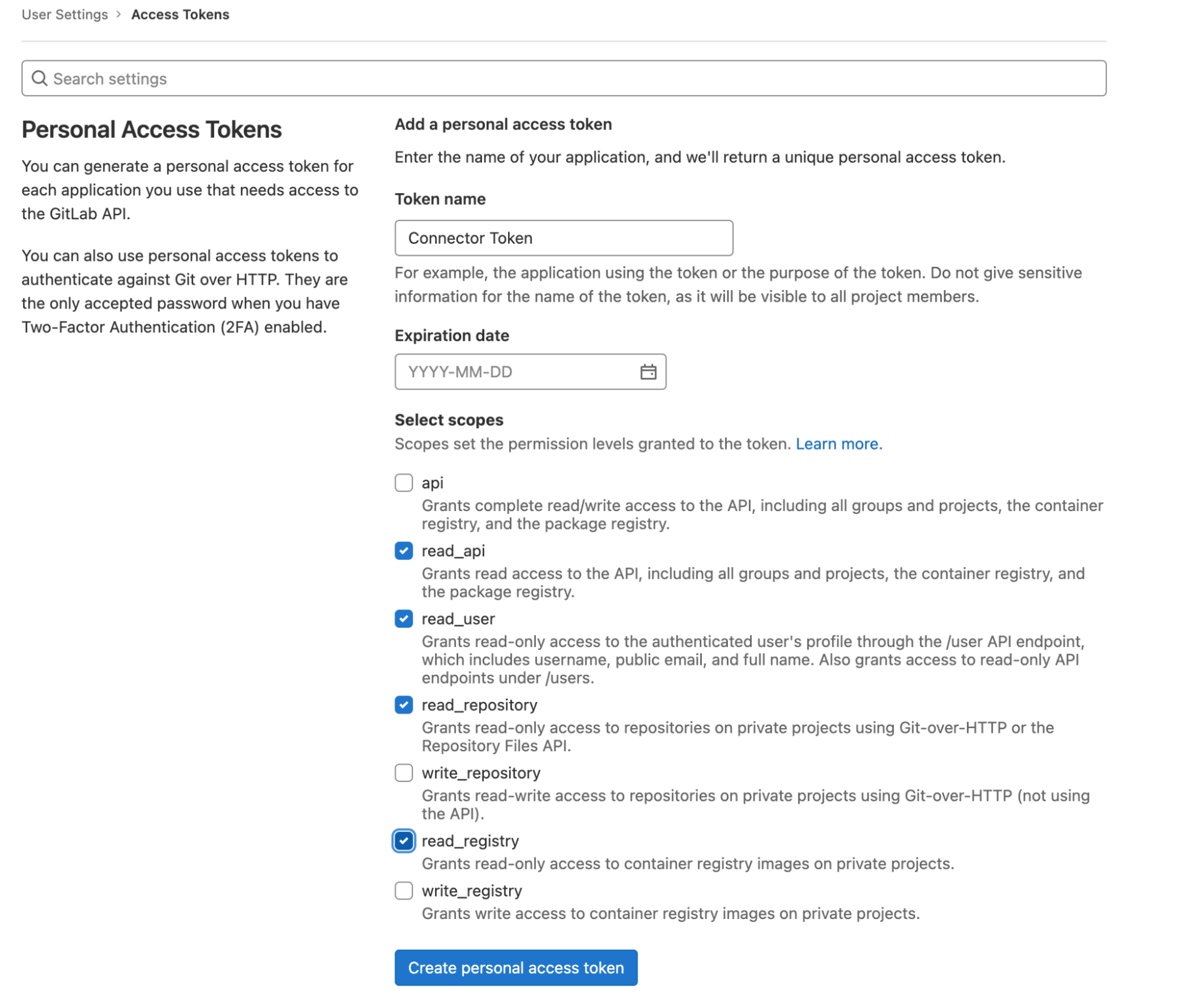
When you have the token, copy it (or download) and store it somewhere — you won't be able to read it again, so if it's lost, you'll have to re-create it. It's not difficult, but you'll need to reconfigure the application with it, too.
Let's see if it works, now. The personal token that we created should be used in request headers like this:
curl --header "Authorization: Bearer <your_gitlab_access_token>" 'https://gitlab.com/api/v4/projects?pagination=keyset&per_page=100&order_by=id&sort=desc'So, what's the first thing we'll want to get into the Enterprise Search? It's probably projects. One can query for a list of projects (repositories) in the following way.
curl -X GET 'https://gitlab.com/api/v4/projects?pagination=keyset&per_page=100&order_by=id&sort=desc' --header 'PRIVATE-TOKEN: <your_gitlab_access_token>'By default, the list of returned projects is huge, because it lists everything that's public on gitlab.com. It's possible to only list the projects we own by adding owned=true to the URL.
We set the pagination=keyset, which means that we'll get the link to the next page in response headers, like this:
* Connection state changed (MAX_CONCURRENT_STREAMS == 256)!
< HTTP/2 200
< date: Mon, 23 May 2022 15:10:57 GMT
< content-type: application/json
< cache-control: max-age=0, private, must-revalidate
< etag: W/"e84e2270f5ee6c6ef57af71d0dbe0b91"
< link: <https://gitlab.com/api/v4/projects?id_before=36413769&imported=false&membership=false&order_by=id&owned=false&page=1&pagination=keyset&per_page=1&repository_checksum_failed=false&simple=false&sort=desc&starred=false&statistics=false&wiki_checksum_failed=false&with_custom_attributes=false&with_issues_enabled=false&with_merge_requests_enabled=false>; rel="next"To do the full sync, we need to just page, and page, and page… until link header is no longer returned (meaning there are no more remaining pages).
Step 3. Back to the connector
Connector configuration
In the ConnectorsSdk::GitLab::Connector, there's this code:
def configurable_fields
[
{
'key' => 'api_token',
'label' => 'API Token'
},
{
'key' => 'base_url',
'label' => 'Base URL'
}
]
endThe configurable fields here are pretty important. They determine our authentication, and they will be used later to create an input form on the Enterprise Search side, so that the values for these fields could be stored in configuration settings.
From exploring the GitLab REST API, we know that our client needs the API token — our personal token for GitLab that will be used for authentication. Also, there's a base URL — a URL for the APIs we'll be querying. At the moment, we're not aware of any other configuration parameters, so it's just these two.
Exploring the Gitlab::CustomClient
The base/custom_client.rb contains a ConnectorsSdk::Base::CustomClient class — it's a thin wrapper around the Faraday client library. Our ConnectorsSdk::GitLab::CustomClient is based on it and is pretty simple.
require 'connectors_sdk/base/custom_client'
module ConnectorsSdk
module GitLab
API_BASE_URL = 'https://gitlab.com/api/v4'
class CustomClient < ConnectorsSdk::Base::CustomClient
def initialize(base_url:, api_token:, ensure_fresh_auth: nil)
@api_token = api_token
super(:base_url => base_url, :ensure_fresh_auth => ensure_fresh_auth)
end
def additional_middleware
[
::FaradayMiddleware::FollowRedirects,
[ConnectorsShared::Middleware::RestrictHostnames, { :allowed_hosts => [base_url, API_BASE_URL] }],
[ConnectorsShared::Middleware::BearerAuth, { :bearer_auth_token => @api_token }]
]
end
end
end
endThe ConnectorsShared::Middleware::BearerAuth is a class that we provide to simplify Bearer: TOKEN authentication. So, here we can just add it to additional_middleware, which is a base class method we override, and use it to pass our token. That class will take care of adding the proper authorization headers.
To use this class in our ConnectorsSdk::GitLab::Connector, we have overridden a creator method from the ConnectorsSdk::Base::Connector.
def client(params)
ConnectorsSdk::GitLab::CustomClient.new(
:base_url => params[:base_url] || ConnectorsSdk::GitLab::API_BASE_URL,
:api_token => params[:api_token]
)
endBefore we deal with the methods that get our content, let's have a look at the heath_check, just because it's simpler and we can check that our third-party API works with the token we created. The implementation for GitLab looks like this:
def health_check(params)
# let's do a simple call
response = client(params).get('user')
unless response.present? && response.status == 200
raise "Health check failed with response status #{response.status} and body #{response.body}"
end
endNow, before starting up the project, run these commands in a root directory:
make install
make api_keyNote: If you're on a Mac and don't have Apple Command Line Tools installed, you might need to also run this command first.
xcode-select --installThe commands above will install the ruby gems. The API key one will create a config/connectors.yml file with the configuration options and generate the new API key for the connector application. You need to change the configuration file to make it look approximately like this.
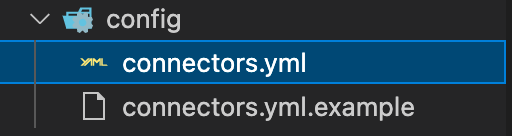
# general metadata
version: "8.3.gitlab"
repository: "git@github.com:elastic/connectors.git"
revision: "main"
# web service
http:
host: 0.0.0.0
port: 9292
api_key: 11971A1B5B6D454F9793842536BD7081
deactivate_auth: false
connector: gitlab
worker:
max_thread_count: 4
log_level: infoI've changed just two lines in this file. It tells the application which connector should be run. We're running the gitlab connector, the one that we have just created. The other line is the version; I set it to 8.3.gitlab but it can be anything — it's only needed so you can tell the connectors apart on the Enterprise Search side.
Now, run another command to start the application:
make runMoment of truth! Let's check if the /status endpoint, the one using our health_check from above, is working:
curl -X POST -s -u elastic:<your_connectors_search_api_key> "http://localhost:9292/status" -d \
'
{
"api_token": "<your_gitlab_access_token>"
}
' | jqThis should provide the following response:
{
"extractor": {
"name": "GitLab Connector"
},
"contentProvider": {
"status": "OK",
"statusCode": 200,
"message": "Connected to GitLab Connector"
}
}Since our health_check calls for the user data, we had to pass in the api_token for the GitLab to be able to authenticate to the third-party service. So, this method not only shows that our service is up, but also proves that the personal token we created works fine with the GitLab REST API.
Now, how do we get the data?
Getting the content via GitLab::Extractor
When we got the documents, we used the following request:
curl -X GET 'https://gitlab.com/api/v4/projects?pagination=keyset&per_page=100&order_by=id&sort=desc' --header 'PRIVATE-TOKEN: <your_gitlab_access_token>'So, we need a method that would call the same endpoint and bring us the documents. And that method lives in the ConnectorsSdk::GitLab::Extractor that we're referring to in our connector class.
def extractor_class
ConnectorsSdk::GitLab::Extractor
endThe ConnectorsSdk::GitLab::Extractor inherits from the base class called ConnectorsSdk::Base::Extractor. So, what's in the ConnectorsSdk::Base::Extractor and why do we, in fact, want it?
That class actually has a lot of wiring that we could definitely use. The purpose of it is to make the content extraction more generic and take care of the following things so that the children classes don't have to:
- Exporting statistics (metrics) about how much time methods take
- Providing error handling in a standardized way
- Taking care of refreshing authorization data as needed
- Handling cursors in a generic way
For getting the documents, we are implementing the method on the extractor called yield_document_changes. This is how it looks:
def yield_document_changes(modified_since: nil)
query_params = {
:pagination => :keyset,
:per_page => PAGE_SIZE,
:order_by => :id,
:sort => :desc
}
# looks like it's an incremental sync
if modified_since.present?
date_since = modified_since.is_a?(Time) ? modified_since : Time.new(modified_since)
query_params[:last_activity_after] = date_since.iso8601
end
next_page_link = nil
loop do
if next_page_link.present?
if (matcher = /(https?:[^>]*)/.match(next_page_link))
clean_query = URI.parse(matcher.captures[0]).query
query_params = Rack::Utils.parse_query(clean_query)
else
raise "Next page link has unexpected format: #{next_page_link}"
end
end
response = client.get('projects', query_params)
JSON.parse(response.body).map do |doc|
doc = doc.with_indifferent_access
if config.index_permissions
doc = doc.merge(project_permissions(doc[:id], doc[:visibility]))
end
yield :create_or_update, ConnectorsSdk::GitLab::Adapter.to_es_document(:project, doc), nil
end
next_page_link = response.headers['Link'] || nil
break unless next_page_link.present?
end
endAs mentioned above, we are using the next page link from the response headers to get each following page. However, this means that yield_document_changes method is performing the whole synchronization process; what if it takes forever? Will the endpoint just block and timeout? I am glad you asked. We're going to see how this method works now.
Let's start the synchronization process!
❯ curl -X POST -s -u elastic:<your_connectors_api_key> "http://localhost:9292/start_sync" -d \
'
{
"api_token": "<your_gitlab_access_token>"
}
' | jqWhat comes back is this:
{
"job_id": "6b78ecb5-255b-4d9d-ae44-0b1319df4a98",
"status": "created"
}The response is returned immediately. But where are the results? Actually, they are in a queue. The process is asynchronous, which means that it creates a job, and to get the documents, we should run another query for them and include the job_id we just got.
curl -X POST -s -u elastic:<your_connectors_api_key> "http://localhost:9292/documents" -d \
'{
"api_token": "<your_gitlab_access_token>",
"job_id": "6b78ecb5-255b-4d9d-ae44-0b1319df4a98"
}' | jqThis should yield a response similar to the following (for brevity, I am just leaving one result, but there will be many more):
{
"status": "running",
"docs": [
{
"action": "create_or_update",
"document": {
"id": "gitlab_36884975",
"type": "project",
"url": "https://gitlab.com/henixdevelopment/open-source/code-samples/howto-bdd-cumcumber-01",
"body": "Source code (version 01) of the example used in the AUTOM/DEVOPS' HOW BDD + Cucumber",
"title": "HOWTO-BDD-Cumcumber-01",
"created_at": "2022-06-09T12:24:42.261Z",
"last_modified_at": "2022-06-09T12:24:42.261Z",
"visibility": null,
"namespace": "code-samples"
},
"download": null
}
]
}The code for getting the documents also reveals another class that I had to create: ConnectorsSdk::GitLab::Adapter. It is a mapper, or an Adapter — something that will map the data and whip it into the desired shape. But which shape exactly are we talking about?
Formatting results with a GitLab::Adapter
If you look at the documented example for indexing documents into a custom source, you will see the following document structure being proposed (skipping the permissions because we'll not aim for document-level permissions, or DLP for short, just yet):
{
"id" : 1234,
"title" : "The Meaning of Time",
"body" : "Not much. It is a made up thing.",
"url" : "https://example.com/meaning/of/time",
"created_at": "2019-06-01T12:00:00+00:00",
"type": "list"
}So, we want to map our projects to something similar to this structure. For that, we extend the ConnectorsSdk::Base::Adapter class that's found in the lib/connectors_sdk/base/adapter.rb to create a ConnectorsSdk::GitLab::Adapter that contains the following code:
require 'hashie/mash'
require 'connectors_sdk/base/adapter'
module ConnectorsSdk
module GitLab
class Adapter < ConnectorsSdk::Base::Adapter
# it's important to have this to generate ID converters between the GitLab ID and the
# Enterprise Search document ID. The Enterprise Search document ID will be prefixed with the service type,
# in our case - `gitlab`.
generate_id_helpers :gitlab, 'gitlab'
def self.to_es_document(type, source_doc)
{
:id => self.gitlab_id_to_es_id(source_doc[:id]),
:type => type,
:url => source_doc[:web_url],
:body => source_doc[:description],
:title => source_doc[:name],
:created_at => source_doc[:created_at],
:last_modified_at => source_doc[:last_activity_at],
:namespace => if source_doc[:namespace].nil?
nil
else
source_doc[:namespace][:name]
end
}
end
end
end
endI've added the last_modified_at because I think we might want to use that one, too, same as the namespace.
Performing incremental synchronization
Incremental synchronization is intended to update the documents that were changed or added since the previous full or incremental synchronization, which means that it should receive the last synchronization date in input parameters and use it in a query.
Looking at the Gitlab projects API, however, we can see that while projects can be ordered by created or updated date, they can't be searched by that date. The search parameter that the /projects endpoint provides what seems to be just the text search. Looking at the Advanced search parameters, we can see that there's actually some inbuilt DSL, but nothing that would allow us to specify a "greater than" or "less than" expression.
How… disappointing.

The API however does provide the last_activity_after and last_activity_before as possible parameters. So it is our poor man's solution for getting the latest changes.
query_params = {
:pagination => :keyset,
:per_page => 100, # max
:order_by => :id,
:sort => :desc
}
# # looks like it's an incremental sync
if modified_since.present?
date_since = modified_since.is_a?(Time) ? modified_since : Time.new(modified_since)
query_params[:last_activity_after] = date_since.iso8601
endThis is the only code in the yield_document_changes method that's responsible for getting the added or updated documents. We're just adding the modified_since to the query parameters. One tiny detail is, we need a specific format so that the GitLab API recognizes it as a date.
So, we covered the full sync and the additions/modifications. Now what?
Synchronizing deleted items
There's a method on the ConnectorsSdk::GitLab::Extractor we haven't looked into yet.
def yield_deleted_ids(ids)
if ids.present?
ids.each do |id|
response = client.get("projects/#{id}")
if response.status == 404
# not found - assume deleted
yield id
else
unless response.success?
raise "Could not get a project by ID: #{id}, response code: #{response.status}, response: #{response.body}"
end
end
end
end
endWhat does it mean?
The idea of connectors is to provide a synchronization mechanism between a third-party API and Enterprise Search, so that in the end, the data ends up in Elasticsearch. We already discussed the synchronization types: full sync, incremental sync, deleted documents, document permissions. However, the third-party APIs are rarely so thoughtful and obliging as to provide an API that directly matches this model.
This means that most times, there's no method that would allow one to say "get me all the documents that have been deleted since X." In fact, many third-party providers just "forget" the deleted documents or files; they have no idea of a "recycled bin," no operation to "restore." This is why in Elastic Enterprise Search, the deletion sync goes off of the assumption that we can just iterate over all the indexed documents, and send their IDs in batches to the third-party system to check if they exist. If they don't, the document has been deleted. It's as simple as that.
The GitLab API doesn't provide an option to search by the list of IDs, however. But it does have the API endpoint to get one project by ID. Again, it's rather a poor man's solution, but it will have to do. We'll just have to hit that endpoint several times and be careful there not to get API request rate limits.
We don't even check what's there in the response; we just assume that if it's not a 404, we're successful — as in, the project is there.
Getting user permissions
Actually, not all connectors need or can implement permissions. The strategies for defining document permissions are well described in this guide. Permissions for external connectors are similar to permissions for Custom sources, and the idea is simple:
- The document can have either or both of the special fields: _allow_permissions and _deny_permissions
- These fields may contain a list of strings.
- The users can also have permissions, and when the document-level permissions are enabled on the content source, the permissions of a user are matched against the permissions stored with the documents
- Example 1: document has _allow_permissions = [ "Administrators", "Managers" ]. User has permissions = "User". The document won't appear on their list while searching.
- Example 2: document has _allow_permissions = [ "Administrators", "Managers" ]. User has permissions = "Manager". The document will appear on their list while searching.
- Example 3: document has _allow_permissions = nil and _deny_permissions = nil. It's visible to all and everyone.
- Example 4: document has _allow_permissions = nil and _deny_permissions = ["Managers"]. A user with permissions ["Users"] will see it, a user with permissions ["Managers"] won't.
NOTE: For permissions to work, Enterprise Search users should be mapped to permissions. There's a special REST API for doing that.
The permissions sync uses the permissions method that's defined in ConnectorsSdk::Base::Extractor as follows:
def yield_permissions(source_user_id)
# no-op for content source without DLP support
endThe parameter name here shows that these permissions are user permissions. Document permissions don't have a separate sync process; they are synchronized at the same time that documents are. For user permissions, the method should expect a user_id parameter and go off of it.
Let's see what GitLab API has to offer here.
The documentation about project membership says the following:
- Members are the users and groups who have access to your project.
- Each members gets a role, which determines what they can do in the project.
Project members can:
- Be direct members of the project
- Inherit membership of the project from the project’s group
- Be a member of a group that was shared with the project
- Be a member of a group that was shared with the project’s group
The projects can also be private, public, or internal (which means they are visible to all the internal — as in, non-external — users). Since we're authenticated and therefore acting as a logged-in user, we can access both the internal and public projects; but there might be a case where the users we map to Enterprise Search would be external and would have fewer permissions.
For the private projects, we need to check the permissions as a matter of course. Luckily enough, there's an endpoint that allows to list all the users of a project, including inherited ones (via groups, etc.).
Whew. That's a lot of information. But it allows us to propose a path:
- The _allow_permissions on a private project will be transformed into a list of user IDs converted to strings (perhaps we can use a prefix to signify that it's a user).
- The _allow_permissions on a public or internal project will also contain ["type:internal"].
- Public projects should not specify permissions at all since they're visible to all.
- The permissions for the user therefore are just a list of: User ID, converted into a string (with a prefix) and "type:internal" to signify that we can see internal projects
The GitLab API is a bit limited for non-admins, and we can't get information about a user being external or not (unless it's for a current user), but we can use the search by username and external status to get this information. This means we'll have to do two calls instead of one, but oh well.
¯\_(ツ)_/¯
So, this is our permissions sync method in ConnectorsSdk::GitLab::Extractor.
def yield_permissions(source_user_id)
result = []
if source_user_id.present?
result.push("user:#{source_user_id}")
user_response = client.get("users/#{source_user_id}")
if user_response.success?
username = JSON.parse(user_response.body).with_indifferent_access[:username]
query = { :external => true, :username => username }
external_response = client.get('users', query)
if external_response.success?
external_users = Hashie::Array.new(JSON.parse(external_response.body))
if external_users.empty?
# the user is not external
result.push('type:internal')
end
else
raise "Could not check external user status by ID: #{source_user_id}"
end
else
raise "User isn't found by ID: #{source_user_id}"
end
end
yield result
endThat's it.
But it's not the end of it.
We also need to augment the documents with permissions, right? Otherwise, what are we matching against? No worries, we're almost there.
Augmenting document permissions
Documents permissions, as we have specified above, will be:
- Unset for public projects
- Mapped to all project members for private projects
- For internal projects, it'll be project members plus the special "type:internal" constant that will allow the projects to be seen by the internal users who haven't been specifically added as members
This is why there is a helper method to get the permissions per project.
def project_permissions(id, visibility)
result = []
if visibility.to_sym == :public || !config.index_permissions
# visible-to-all
return {}
end
if visibility.to_sym == :internal
result.push('type:internal')
end
response = client.get("projects/#{id}/members/all")
if response.success?
members = Hashie::Array.new(JSON.parse(response.body))
result = result.concat(members.map { |user| "user:#{user[:id]}" })
else
raise "Could not get project members by project ID: #{id}, response code: #{response.status}, response: #{response.body}"
end
{ :_allow_permissions => result }
endAnd this is how it is used in our yield_document_changes:
JSON.parse(response.body).map do |doc|
doc = doc.with_indifferent_access
if config.index_permissions
doc = doc.merge(project_permissions(doc[:id], doc[:visibility]))
end
yield :create_or_update, ConnectorsSdk::GitLab::Adapter.to_es_document(:project, doc), nil
endNote that a parameter called index_permissions is expected in the config object to tell the connector that it needs to get the permissions. We don't want to do all that work if document-level permissions are not enabled. Also, it's important to not set that field at all, if the permissions are disabled; otherwise, the document will just not be indexed, as this field will not be allowed.
This is what ConnectorsSdk::GitLab::Config is created for. We're storing that flag there.
module ConnectorsSdk
module GitLab
class Config < ConnectorsSdk::Base::Config
attr_reader :index_permissions
def initialize(cursors:, index_permissions: false)
super(:cursors => cursors)
@index_permissions = index_permissions
end
def to_h
super.merge(:index_permissions => index_permissions)
end
end
end
endAnd of course the code that creates the config object in the ConnectorsSdk::GitLab::Connector needs to pass that flag in.
def config(params)
ConnectorsSdk::GitLab::Config.new(
:cursors => params.fetch(:cursors, {}) || {},
:index_permissions => params.fetch(:index_permissions, {}) || false
)
endOh, and last but not least. There's something in the ConnectorsSdk::GitLab::Adapter to make sure that the field containing permissions is added to the response data. It's a three-line addition in that adapter code, after the other mapped fields.
if :source_doc[:_allow_permissions].present?
result[:_allow_permissions] = source_doc[:_allow_permissions]
endSo. We looked at a lot of stuff. Let's finally see if it really works with Enterprise Search! But… How?
Step 4. Connecting the dots… that is, the connector
Prerequisites
- Enterprise Search should be installed and configured.
- In case of a cloud-based deployment, the connector application should be deployed somewhere to have a publicly accessible URL. It could be Heroku or another similar platform that allows the deployment of a Ruby application.
- Before doing that, you need to check that the flag deactivate_auth in the config/connectors.yml is set to false.
- Since the config/connectors.yml contains API keys, it's not safe to put under source control. So if you're deploying from the repository, you should keep it in mind and provide for it accordingly.
Connecting the connector
Let's assume that you have the Enterprise Search instance set up and running, and that you're logged in to Workplace Search. Now we need to configure our connector in Settings → Connectors. It comes before all the standard connectors, in a separate call-out panel.
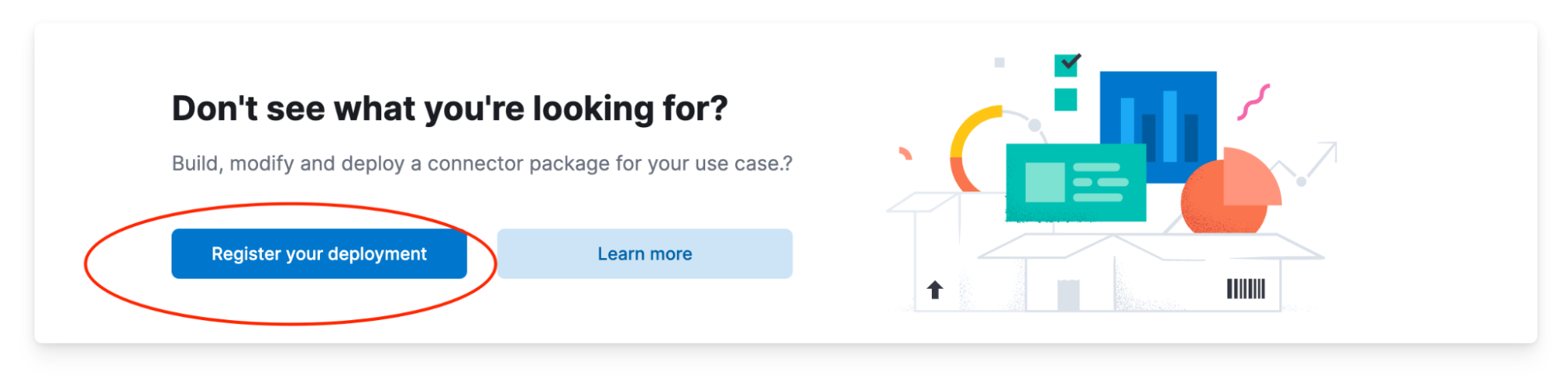
When you click the Register your deployment button, you have a screen allowing you to configure the URL for the external service and also, the API key:
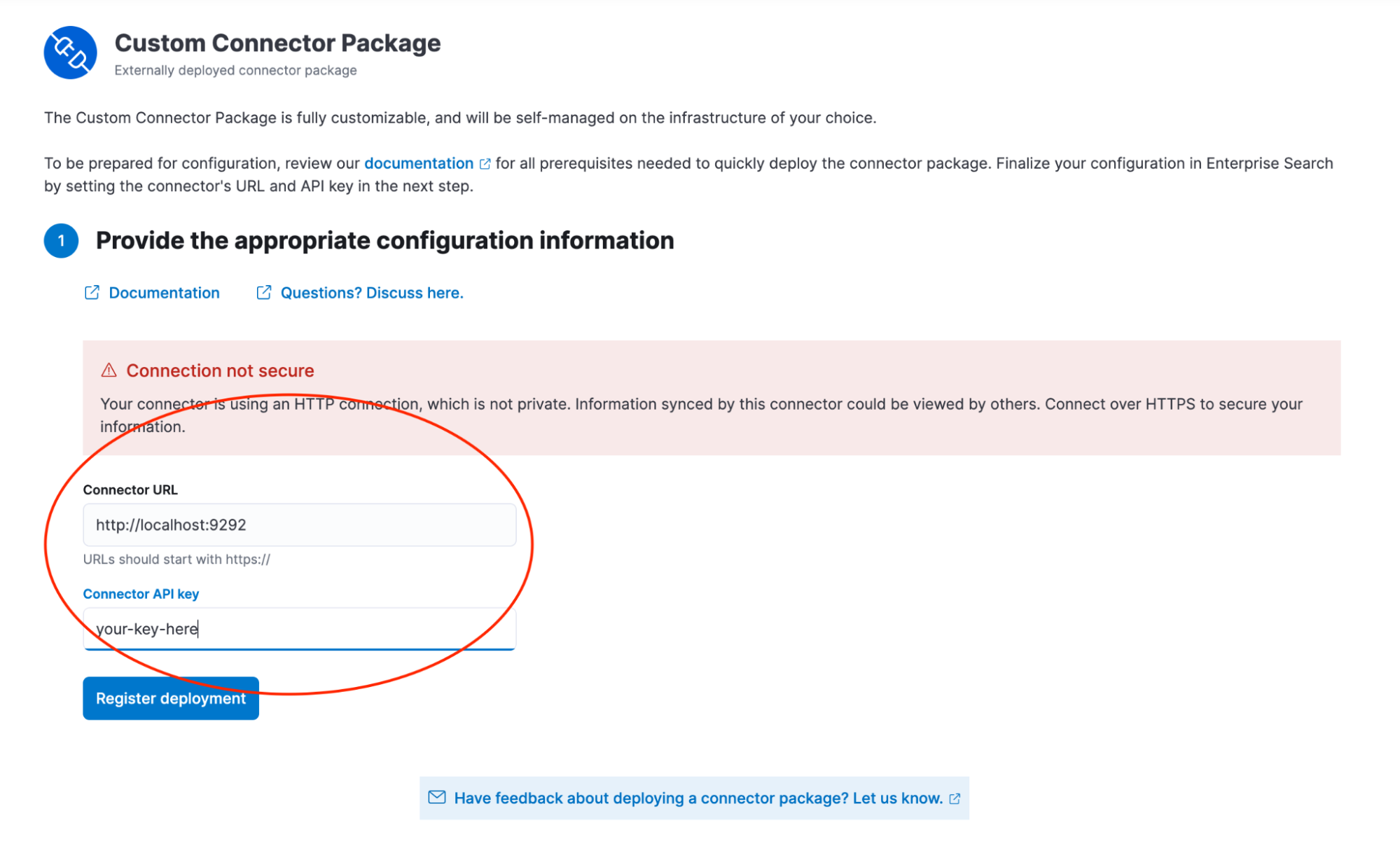
After entering the URL and the API key, Elastic Enterprise Search makes a request to the connector URL and based on the response, updates the UI to allow for entering the connector-specific configuration parameters that we specified in our configurable_fields method in the ConnectorsSdk::GitLab::Connector - base URL for a third-party service, and the third-party API token.
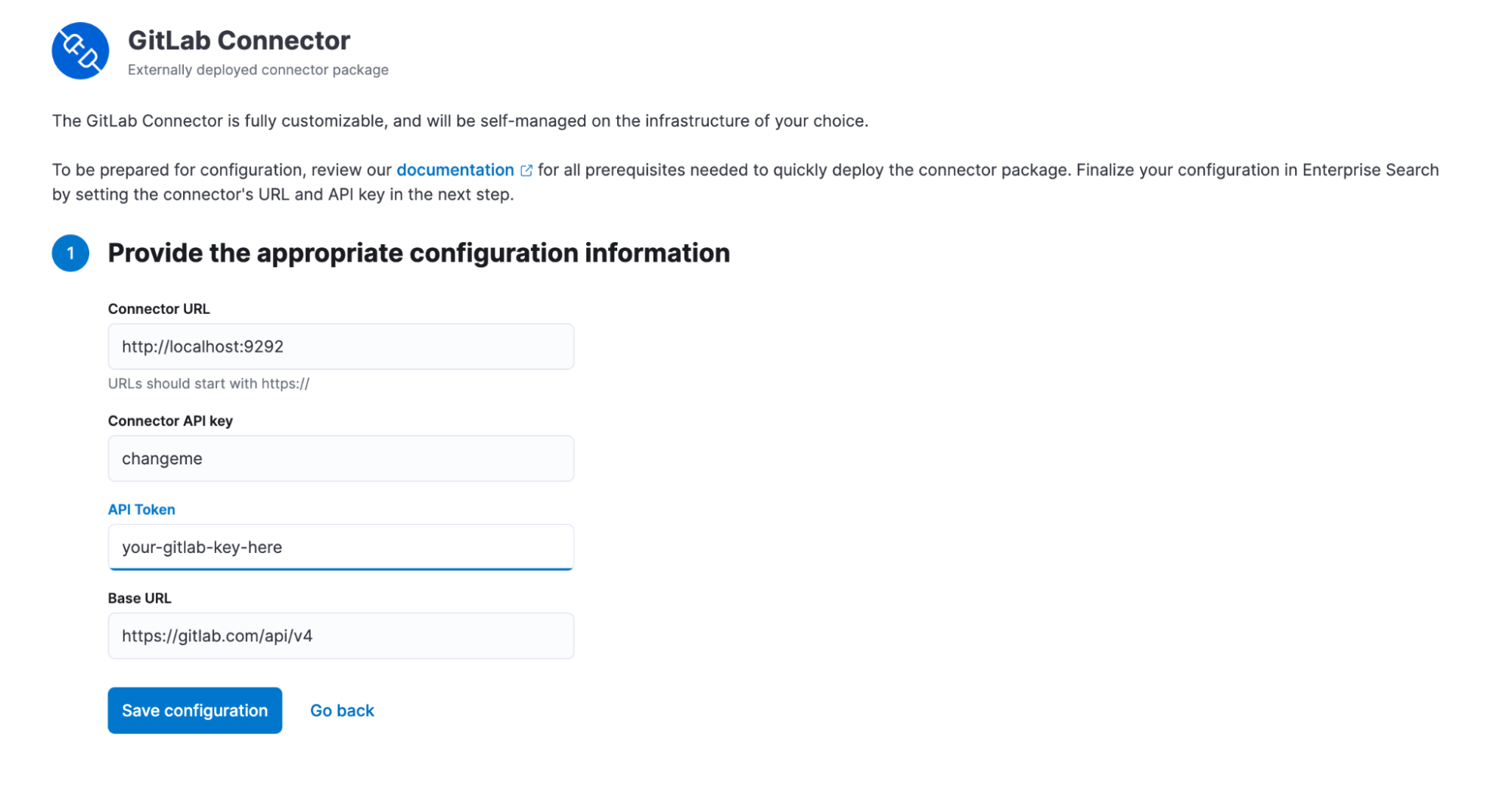
After providing these, you will be able to configure a content source based on this connector.
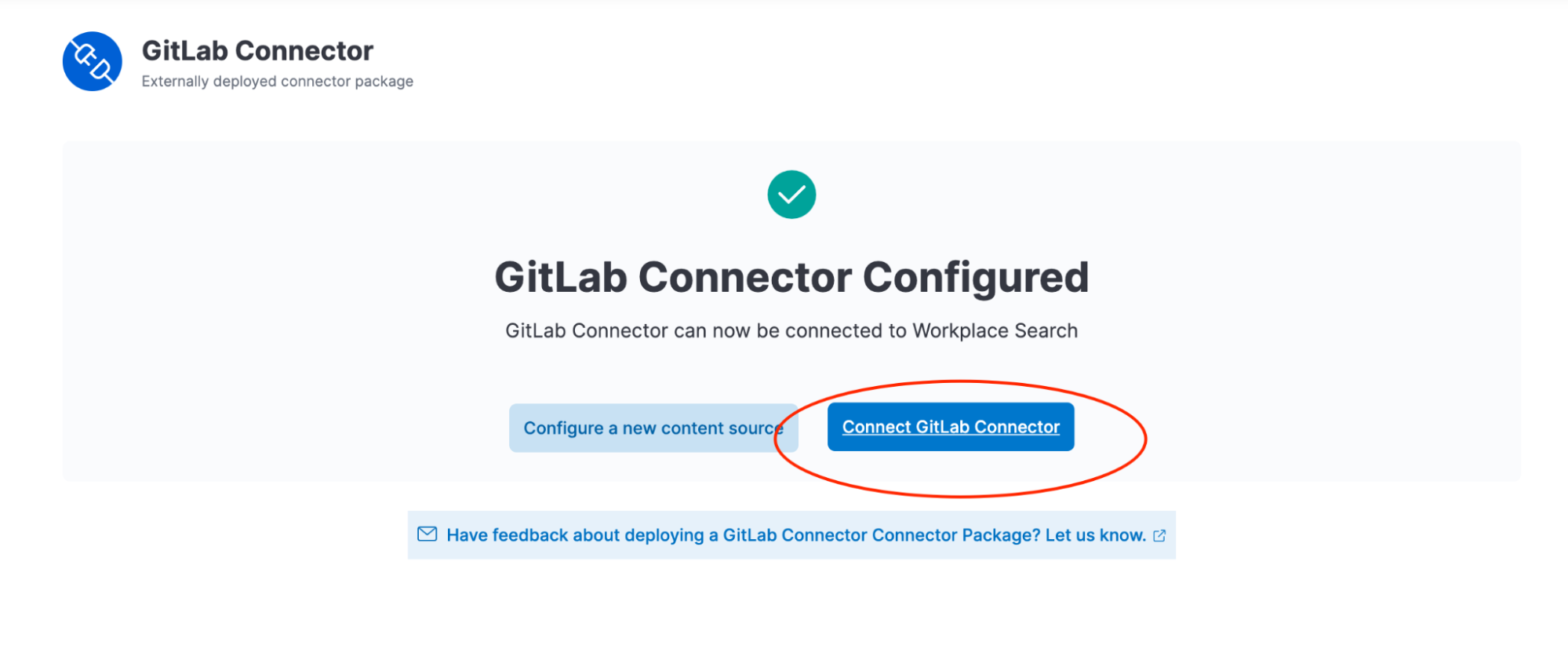
After the configuration is saved, the source is directly connected and starts the indexing process right away. The initial synchronization can take a while. Fair warning: in our case, it will take a long while indeed. Why? Because GitLab has a huge amount of public repositories which are all returned by the REST APIs, and the whole lot is being indexed now. It wouldn't be the case for an in-house GitLab installation, however.
Checking that the content is indexed
Now that the synchronization is underway, we can go to the Sources → GitLab Connector → Content page and check that the content is there.
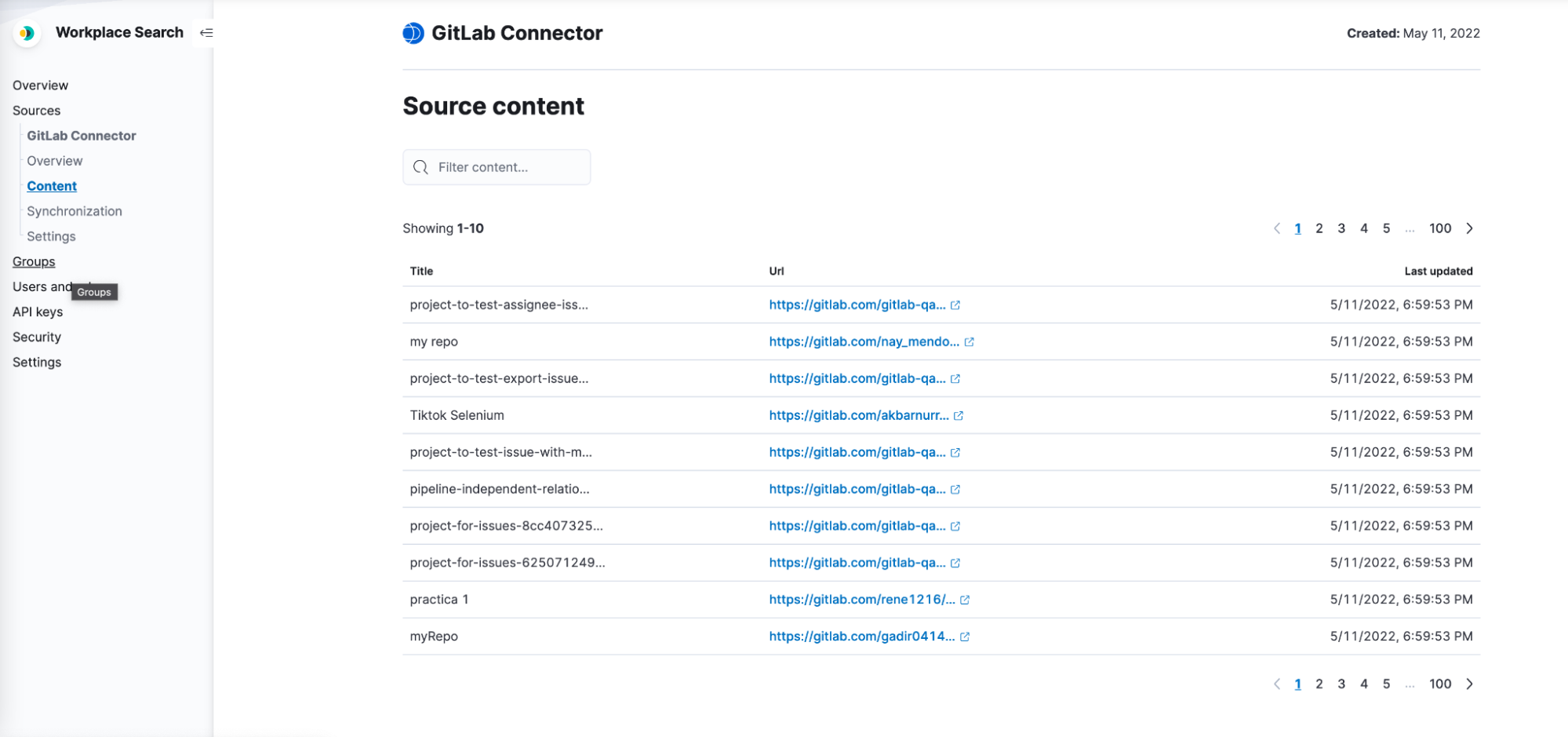
Yay! It's working, it's working! Are we done?
Yes. We did a lot of things in this step-by-step manual.
- Investigated the third-party API
- Went through creating the connector
- Found out how to bring in the data (GitLab projects in our case)
- Massaged the data into the desired shape
- Discovered how to implement synchronization of deletions
- Worked out the permissions strategy and its implementation
- Augmented the documents with permissions, too
- Connected the connector to our Enterprise Search installation and made sure that the content was indeed there
Can we do better?
The application is working, and getting the content into the index! But while it's a great starting point, there are definitely things one would want for a real life application:
- We're only indexing one type of content: projects. We would definitely want to also index users, files, etc., for this data to be of real use.
- Even for the projects, we don't bring much in. The data we're indexing is a good start, but for the real implementation we'd probably want to get visibility, icons, branches, and much more data.
- Also, if the project has a README file, we might want to get that content and index it to provide an extended description, since the description field in the response is short and often comes empty.
- Data cleanup! When you do bring the content, a lot of it will probably be in raw HTML or Markdown format (like the READMEs or other files). If the intention is to search over it, then the cleanup is a necessary prerequisite.
- File download. Often, text content has attachments. They are media files like images and videos, or they might be PDFs. In some cases, this data can also be useful for search purposes.
- PDF or RTF or other binary files with text content. The extraction of such data is a whole other topic, well deserving a separate article.
- Rate limits. We haven't implemented any handling for them, but in a production application we could not avoid it.
These, and all the other ideas you might have on your own, will be a great exercise, should you want to continue and bring your own connector.
Note: The connector framework is a tech preview feature. Tech preview features are subject to change and are not covered by the support SLA of general release (GA) features. Elastic plans to promote this feature to GA in a future release.
Get in touch with us
We’d love for you to try out Connectors framework and give us feedback as we work on adding new capabilities to it. If you run into any issues during the process, please reach out to us on our community Slack channel, discussion forums, or just create an issue — it's Open Code!
Useful links
- Connectors framework GitHub repository
- Workplace Search product page
- Workplace Search guide for version 8.3
- Enterprise Search guide for version 8.3
- Custom connector package documentation for version 8.3
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print