Enriching Your Postal Addresses With the Elastic Stack - Part 1
This blog post is part 1 of a series of 3:
- Importing BANO dataset with Logstash
- Using Logstash to lookup for addresses in BANO index
- Using Logstash to enrich an existing dataset with BANO
I'm not really sure why, but I love the postal address use case.
Often in my career, I have to deal with that information. Unfortunately, real world address data is often poorly formatted or missing some important attributes.
Let's take a simple use case. I have a user in my database:
{
"name": "Joe Smith",
"address": {
"number": "23",
"street_name": "r verdiere",
"city": "rochelle",
"country": "France"
}
}
If you live in France, you might notice that this address is fairly incomplete. If we’d wish to send a letter to Joe, it would be hard.
In addition, I'd really like to display on a map where my customers are located in France — but this information makes that impossible.
Let's say I'm collecting data from a mobile application where I'm meeting friends and I'd like to programmatically retrieve the address of the location we last met. Basically, I have data like:
{
"name": "Joe Smith",
"location": {
"lat": 46.15735,
"lon": -1.1551
}
}
And I would like to get back the postal address matching this location.
What can we do for that?
We need something to enrich the existing data to either fix the address and provide actual coordinates, or the other way around. We could use something like the Google Map API for that and do an external call anytime we need, but I see 2 major pain points with that option:
- We would need to communicate with an external service and maybe your company policy does not allow sending a customer’s data to an internet service.
- You might suffer from some latency whenever you call that external service on which you can't really have any knob to make it faster. The speed of light is the speed of light and crossing the ocean may be will always include some latency.
We need something local then. In France, we are super lucky because we have a public dataset known as Base d'Adresses Nationale - BANO or National Address Database which is provided under the Open Street Map umbrella.
Bano
Every day the BANO project exports the list of known addresses anywhere in France. Here is an extraction of what you can have:
-rw-r--r--@ 1 dpilato staff 11183891 27 nov 02:03 bano-88.csv -rw-r--r--@ 1 dpilato staff 25014545 27 nov 02:04 bano-85.csv -rw-r--r--@ 1 dpilato staff 3888078 27 nov 02:04 bano-971.csv -rw-r--r--@ 1 dpilato staff 12107391 27 nov 02:04 bano-92.csv -rw-r--r--@ 1 dpilato staff 3443396 27 nov 02:04 bano-972.csv -rw-r--r--@ 1 dpilato staff 1218424 27 nov 02:05 bano-973.csv -rw-r--r--@ 1 dpilato staff 455986 27 nov 02:05 bano-976.csv -rw-r--r--@ 1 dpilato staff 21634994 27 nov 02:05 bano-91.csv -rw-r--r--@ 1 dpilato staff 15848802 27 nov 02:05 bano-93.csv -rw-r--r--@ 1 dpilato staff 14779208 27 nov 02:05 bano-94.csv -rw-r--r--@ 1 dpilato staff 17515805 27 nov 02:06 bano-95.csv -rw-r--r--@ 1 dpilato staff 17713007 27 nov 02:07 bano-974.csv -rw-r--r--@ 1 dpilato staff 71133336 27 nov 02:08 bano-59.csv
Each CSV file corresponds to a subdivision of France that we call a department. It's like a region, but smaller. Bigger than a city though. Like a US county.
Download Bano CSV Files
I wrote a simple shell script to download all the files I needed locally, but you can directly consume one CSV file with a http_poller plugin using Logstash.
#!/bin/bash
set -e
download () {
wget http://bano.openstreetmap.fr/data/$1 --timestamping --directory-prefix=bano-data -c --no-verbose --show-progress
}
DEPTS=95
for i in {01..19} $(seq 21 $DEPTS) {971..974} {976..976} ; do
DEPT=$(printf %02d $i)
echo Downloading bano department $DEPT
download bano-$DEPT.csv
done
What is happening with the numbers here?
Well, France is a moving country. Sometimes the departments are merged together, which probably explains why we don't have a department “20” anymore.
Some departments of France are also located far far away from the French metropolitan area. Those are labelled as 97x.
Nothing can be simple in France :)
Loading Elasticsearch
Let's now parse the data and load that in Elasticsearch, so we will be able to search for addresses.
If we look at one of the CSV file, we can see:
976030950H-26,26,RUE DISMA,97660,Bandrélé,CAD,-12.891701,45.202652
976030950H-28,28,RUE DISMA,97660,Bandrélé,CAD,-12.891900,45.202700
976030950H-30,30,RUE DISMA,97660,Bandrélé,CAD,-12.891781,45.202535
976030950H-32,32,RUE DISMA,97660,Bandrélé,CAD,-12.892005,45.202564
976030950H-3,3,RUE DISMA,97660,Bandrélé,CAD,-12.892444,45.202135
976030950H-34,34,RUE DISMA,97660,Bandrélé,CAD,-12.892068,45.202450
976030950H-4,4,RUE DISMA,97660,Bandrélé,CAD,-12.892446,45.202367
976030950H-5,5,RUE DISMA,97660,Bandrélé,CAD,-12.892461,45.202248
976030950H-6,6,RUE DISMA,97660,Bandrélé,CAD,-12.892383,45.202456
976030950H-8,8,RUE DISMA,97660,Bandrélé,CAD,-12.892300,45.202555
976030950H-9,9,RUE DISMA,97660,Bandrélé,CAD,-12.892355,45.202387
976030951J-103,103,RTE NATIONALE 3,97660,Bandrélé,CAD,-12.893639,45.201696
\_ ID | \_ Street Name | \ \_ Source \_ Geo point
| | \
|_ Street Number |_ Zipcode \_ City Name
Writing The Logstash Pipeline
Like all Logstash pipelines I write, I like to start out with a basic configuration and then slowly build it out. Let's call it bano-data.conf:
input {
stdin { }
}
filter {
}
output {
stdout { codec => json }
}
Let's run it:
head -1 | logstash-6.2.3/bin/logstash -f bano-data.conf
This gives something like:
{
"message":"976030951J-103,103,RTE NATIONALE 3,97660,Bandrélé,CAD,-12.893639,45.201696",
"@timestamp":"2017-12-05T16:00:00.000PST",
"@version":1,
"host":"MacBook-Pro-David.local"
}
Let's add our csv-filter plugin as we already saw in Exploring Capitaine Train Dataset:
csv {
separator => ","
columns => [
"id","number","street_name","zipcode","city","source","latitude","longitude"
]
remove_field => [ "message", "@version", "@timestamp", "host" ]
}
That's now producing:
{
"source":"CAD",
"id":"976030951J-103",
"number":"103",
"street_name":"RTE NATIONALE 3",
"zipcode":"97660",
"city":"Bandrélé",
"latitude":"-12.893639",
"longitude":"45.201696"
}
Let's rename and convert some fields with the mutate-filter plugin:
mutate {
convert => { "longitude" => "float" }
convert => { "latitude" => "float" }
rename => {
"longitude" => "[location][lon]"
"latitude" => "[location][lat]"
"number" => "[address][number]"
"street_name" => "[address][street_name]"
"zipcode" => "[address][zipcode]"
"city" => "[address][city]"
}
replace => {
"region" => "${REGION}"
}
}
I'll explain a bit later where this ${REGION} value is coming from. But basically, I want to store here the department number the address is coming from.
This now gives:
{
"source":"CAD",
"id":"976030951J-103",
"region":"976",
"address":{
"number":"103",
"street_name":"RTE NATIONALE 3",
"zipcode":"97660",
"city":"Bandrélé"
},
"location":{
"lat":-12.893639,
"lon":45.201696
}
}
We are almost done. Let's load Elasticsearch now by adding our elasticsearch-output plugin:
elasticsearch {
"template_name" => "bano"
"template_overwrite" => true
"template" => "bano.json"
"index" => ".bano-${REGION}"
"document_id" => "%{[id]}"
}
There are a few things to explore in that last code sample:
- We are providing an index template for Elasticsearch.
- We are setting the
_indexname to.bano-${REGION}. Again, we will explain later where this value is coming from. - We are setting the document
_idto theidprovided within the bano dataset.
BANO Index Template
As you may have noticed, we are using an index template here named bano which is loaded by Logstash anytime the Elasticsearch plugin starts. Using template_overwrite helps to overwrite the template anytime you want to change some rules. Of course, overwriting an index template does not update the existing indices. So basically, you will need to drop the existing indices and parse the BANO data again with Logstash.
Let's describe what this index template contains:
{
"template": ".bano-*",
"settings": { /* ... */ },
"mappings": { /* ... */ },
"aliases" : { /* ... */ }
}
This template will be applied anytime we have an index which name starts with .bano-. We will then apply the 3 following parts:
settings: for index settingsmappings: for document mappingaliases: for virtual indices (aka aliases)
The settings part is the following:
{
"template": ".bano-*",
"settings": {
"index.number_of_shards": 1,
"index.number_of_replicas": 0,
"index.analysis": {
"analyzer": {
"bano_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter" : [ "lowercase", "asciifolding" ]
},
"bano_street_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter" : [ "lowercase", "asciifolding", "bano_synonym" ]
}
},
"filter": {
"bano_synonym": {
"type": "synonym",
"synonyms": [
"bd => boulevard",
"av => avenue",
"r => rue",
"rte => route"
]
}
}
}
},
"mappings": { /* ... */ },
"aliases" : { /* ... */ }
}
Here, we want one single shard per index (per department), which is more than enough. We don't want replicas since we will be running that on a single node. Note that the number of replicas can be set dynamically, so after the ingestion of the BANO data, we can always increase this value if we decide to have a bigger cluster.
We are then defining two analyzers. The first one, bano_analyzer, is a kind of a standard analyzer but with addition of an asciifolding token filter which will transform all the French diatrics like, for example é, è, ê to their ascii equivalent value: e at index time and search time.
The second analyzer named bano_street_analyzer also adds some synonyms. Indeed, when I looked at some values we have in the BANO dataset, I found that sometimes the same type of street has different type names. Like av for avenue.
The synonym token filter will definitely help to normalize that.
As it will be used also at search time, it will help if, for example, a call center operator type bd instead of boulevard as it will be also normalized to the right value.
The mappings part is the following:
{
"template": ".bano-*",
"settings": { /* ... */ },
"mappings": {
"doc": {
"properties" : {
"address": {
"properties" : {
"city": {
"type": "text",
"analyzer": "bano_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"number": {
"type": "keyword"
},
"street_name": {
"type": "text",
"analyzer": "bano_street_analyzer"
},
"zipcode": {
"type": "keyword"
}
}
},
"region": {
"type": "keyword"
},
"id": {
"type": "keyword"
},
"source": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
},
"aliases" : { /* ... */ }
}
Everything is pretty much obvious here. For some fields, we are using a keyword data type since we just want to run exact match or aggregations. The street_name is using the bano_street_analyze we saw before. location is a geo_point type and finally city is indexed twice:
- As
cityfield to perform full text search on it. - As
city.keywordfield to perform a terms aggregation on it.
The aliases part is the following:
{
"template": ".bano-*",
"settings": { /* ... */ },
"mappings": { /* ... */ },
"aliases" : {
".bano" : {}
}
}
It means that if we don't know the department when we have to search, we can search in .bano virtual index, which will span our query against all the BANO indices. Of course, we could also use a wildcard when searching, such as:
GET .bano-*/_search
Loading Data
To launch our importation, let's write a shell script:
import_region () {
export REGION=$1
FILE=bano-data/bano-$REGION.csv
curl -XDELETE localhost:9200/.bano-$REGION?pretty
cat $FILE | logstash-6.2.3/bin/logstash -f bano-data.conf
}
DEPTS=95
for i in {01..19} $(seq 21 $DEPTS) {971..974} {976..976} ; do
DEPT=$(printf %02d $i)
import_region $DEPT
done
Here we are using the same tricks for the strange department numbers.
In import_region we are exporting the department number as REGION system property which Logstash is then able to use.
For each CSV file, we basically:
- Remove the existing index, if any
- cat the content of the file and send the content to Logstash
We could have been a bit smarter and used an http input plugin, which waits for documents coming on port 8080. We will cover that in another section.
It took something like 2 hours and a half to inject the data on my laptop but I now have data ready ...
BANO Statistics
So what do we have now? Let’s compute some statistics and use Kibana to display it all with fancy visualizations.
GET _cat/indices/.bano*?v&h=index,docs.count,store.size
Gives (only the first lines are shown here):
index docs.count store.size .bano-80 204930 20.7mb .bano-50 160820 16.4mb .bano-60 241276 24.6mb .bano-34 308056 30.9mb
How many addresses do we have?
GET .bano/_search
{
"size": 0
}
Gives:
{
"took": 24,
"timed_out": false,
"_shards": {
"total": 99,
"successful": 99,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 16402853,
"max_score": 0,
"hits": []
}
}
So we have 16.402.853 addresses.
Let's look at that in Kibana. Here I built some really simple visualizations.
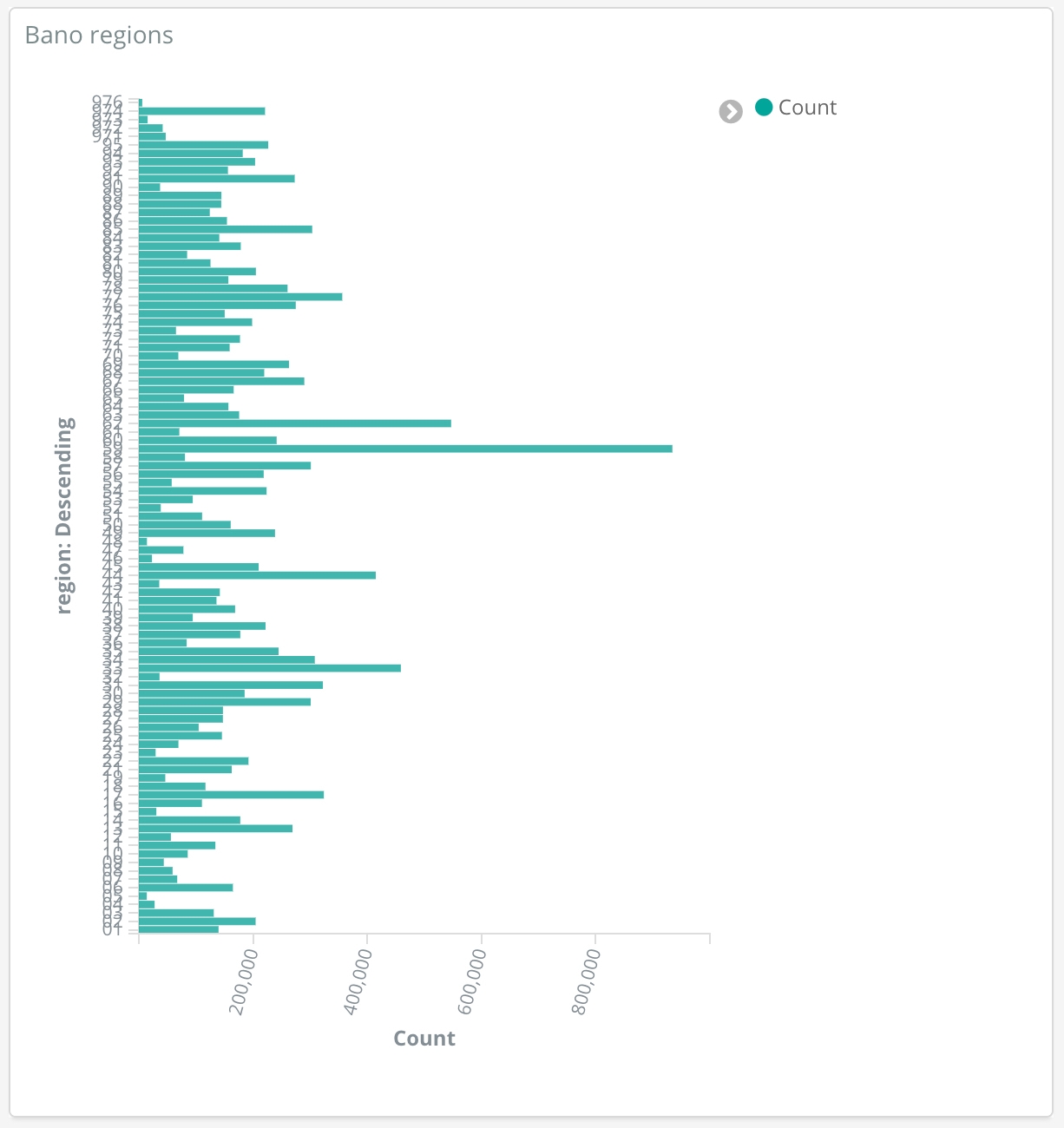
Distribution of BANO addresses by department number:
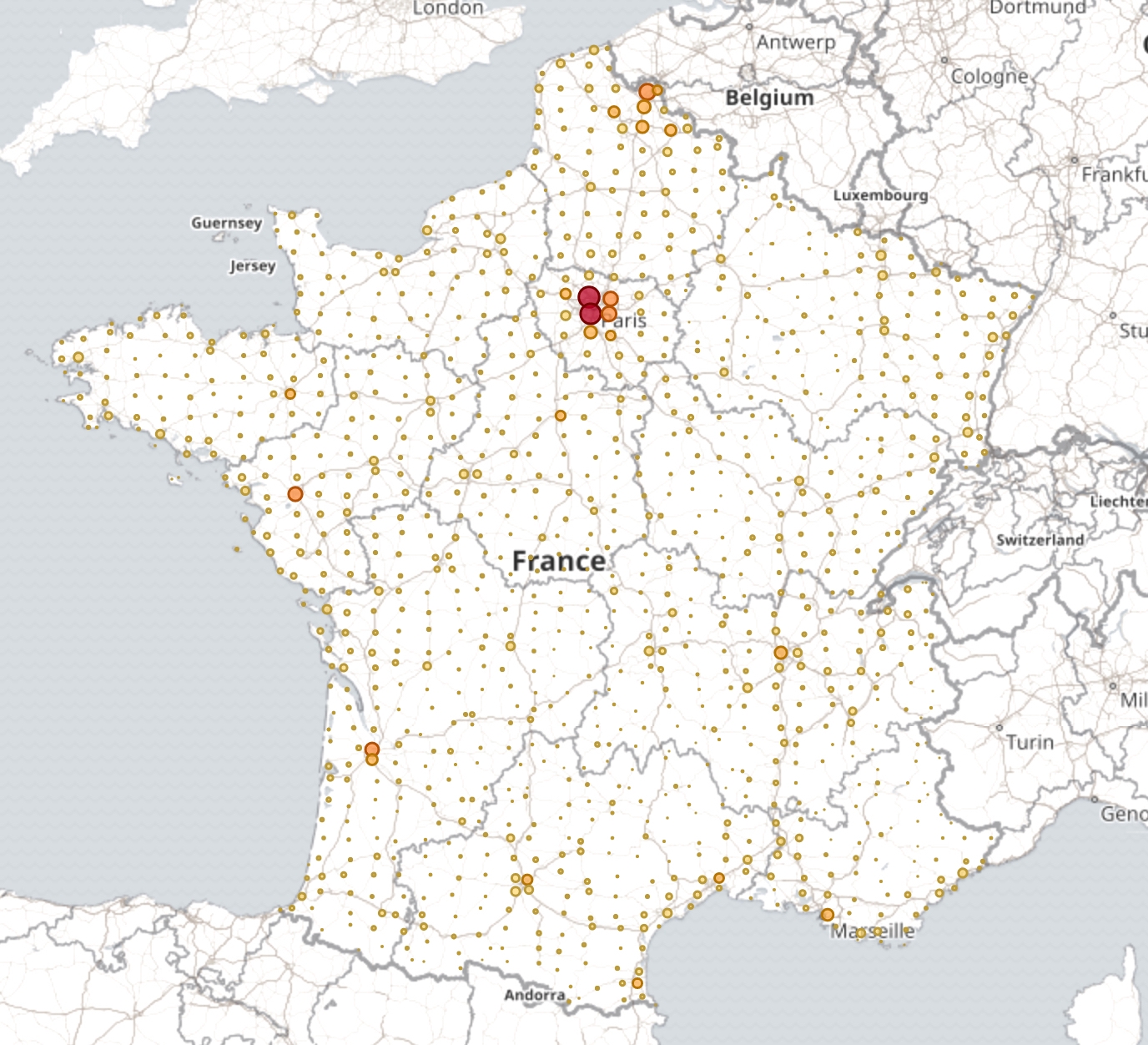
Map of BANO addresses for France Metropolitan:
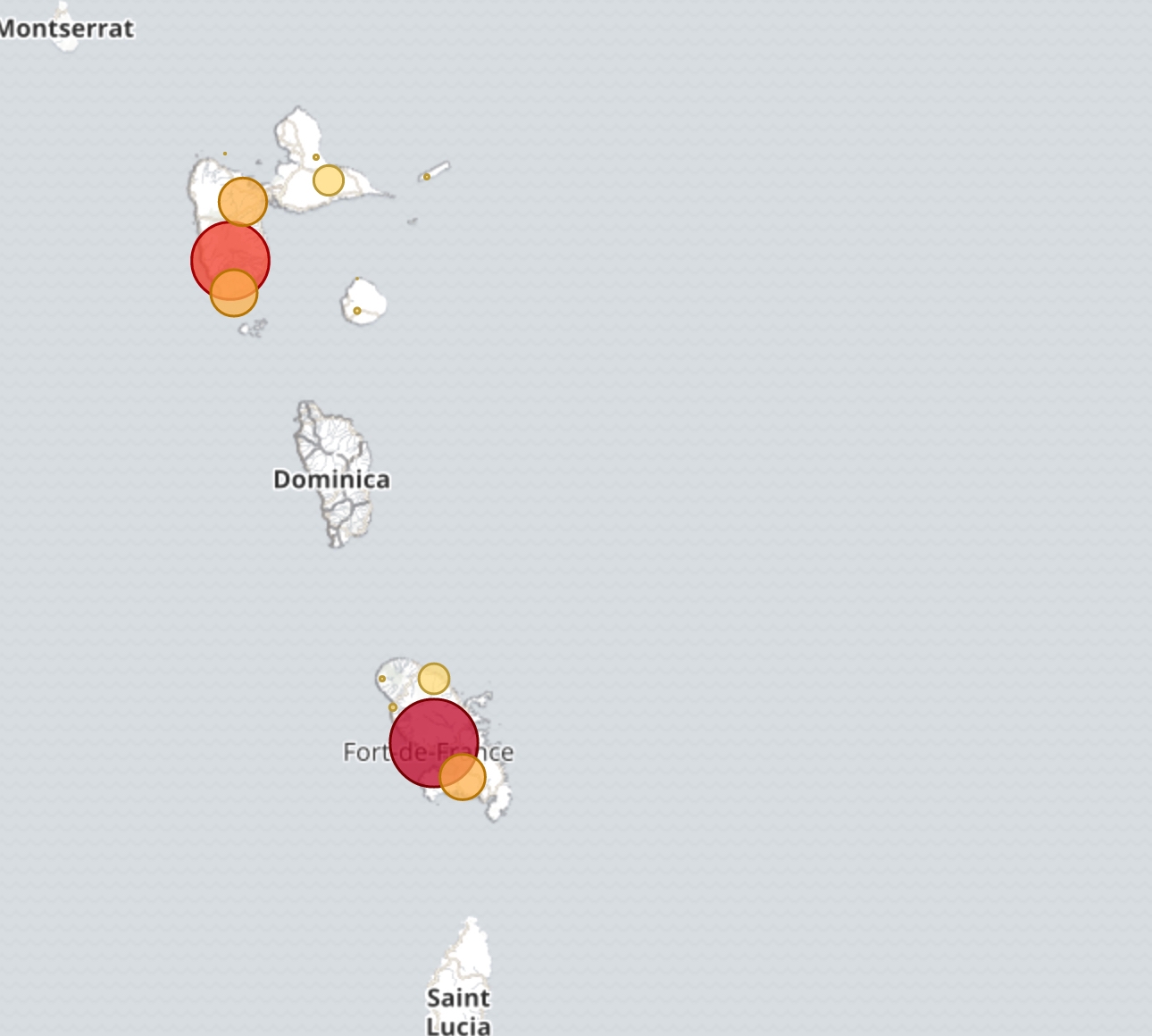
Map of BANO addresses for some France Overseas Departments:
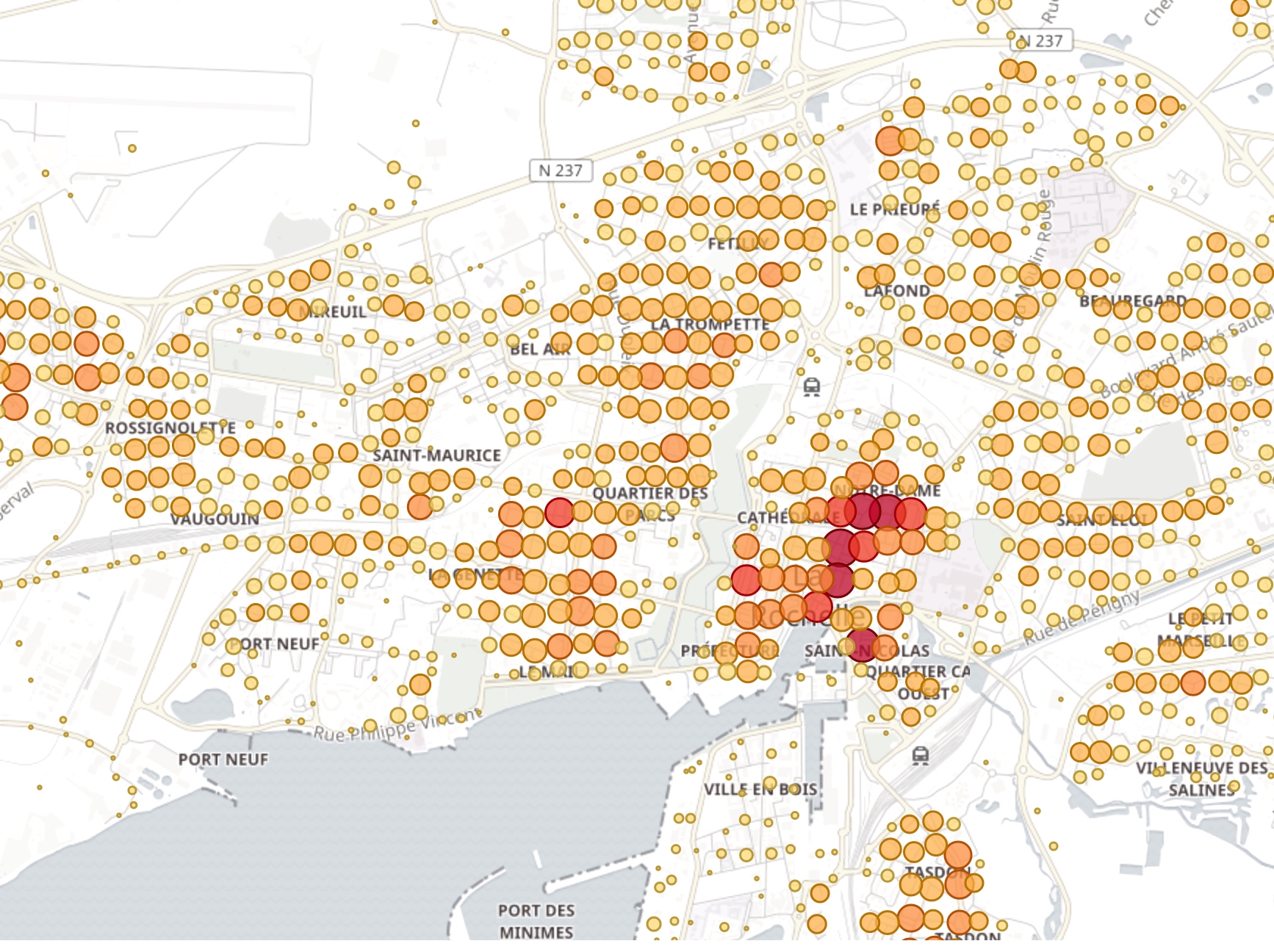
Map of BANO addresses near by La Rochelle:
Top cities (in number of known addresses):
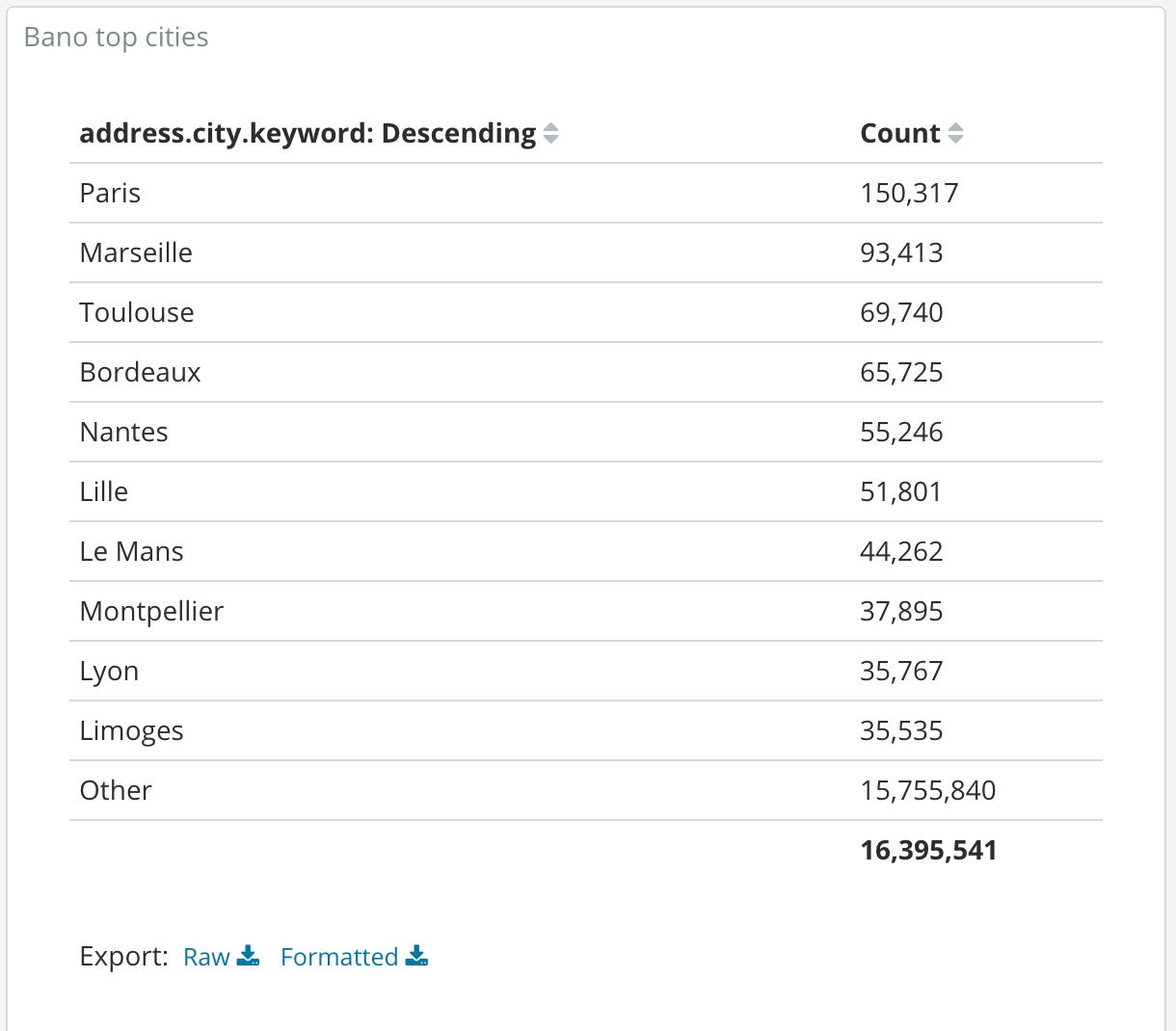
No surprises in this list. It's obvious that the biggest cities in term of population are:
- Paris
- Marseille
- Toulouse
- Bordeaux
- Nantes
Next steps
Have a look at the next post to see how you can now use that dataset to perform address correction and transformation.