Acompanhe o líder: introdução à replicação entre clusters no Elasticsearch
Atendendo a pedidos
A possibilidade de replicar dados de forma nativa de um cluster Elasticsearch para outro é o recurso mais pedido pelos nossos usuários há muito tempo. Depois de anos de trabalho criando as bases, [construindo tecnologias fundamentais no Lucene](https://issues.apache.org/jira/browse/LUCENE-8198] e melhorando e refinando nosso design inicial, temos o prazer de anunciar que a replicação entre clusters (CCR) está disponível e pronta para a produção no Elasticsearch 6.7.0. Neste post, o primeiro de uma série, vamos fazer uma breve introdução ao novo recurso e dar algumas informações técnicas sobre o CCR. Nos próximos posts, vamos mergulhar em alguns casos de uso mais específicos.
A replicação entre clusters no Elasticsearch permite uma série de casos de uso importantes dentro do Elasticsearch e do Elastic Stack:
- Recuperação pós-desastres (DR) / Alta disponibilidade (HA): Tolerância para suportar o apagão de um banco de dados ou de uma região é uma exigência para diversos aplicativos de missão crítica. Essa exigência já estava resolvida no Elasticsearch com tecnologias adicionais, que geravam mais complexidade e necessidade de gerenciamento. As exigências de DR e HA entre centros de dados agora podem ser resolvidas de forma nativa com o Elasticsearch, utilizando o código CCR, sem tecnologias adicionais.
- Localidade dos dados: Replique dados no Elasticsearch para se aproximar do usuário ou servidor do aplicativo e reduzir latências que custam dinheiro. Por exemplo, um catálogo de produto ou conjunto de dados de referência pode ser replicado para 20 ou mais centros de dados no mundo todo, para minimizar a distância entre os dados e o servidor do aplicativo. Um outro caso de uso pode ser uma empresa de trading com escritórios em Londres e Nova York, por exemplo. Os negócios do escritório de Londres são escritos de forma local e replicados para o de Nova York e vice-versa. Os dois escritórios têm uma visão global de todos os negócios.
- Relatórios centralizados: replique dados de uma série de clusters menores para um cluster de relatório centralizado. Esse recurso será muito útil quando não for eficiente fazer consultas em uma rede grande. Por exemplo, um grande banco global pode ter 100 clusters Elasticsearch no mundo todo, cada um dentro de uma agência do banco. Podemos usar o CCR para replicar eventos de todos os 100 bancos para um cluster central onde analisaremos e agregaremos os eventos em nível local.
Antes do Elasticsearch 6.7.0, esses casos de uso poderiam ser parcialmente resolvidos com tecnologias de terceiros, o que é complicado, exige muito trabalho administrativo e pode causar atrasos. Com a replicação entre clusters integrada de forma nativa no Elasticsearch, nossos usuários ficam livres dos atrasos de gerenciar soluções complicadas e podemos oferecer vantagens em cima das soluções existentes (por exemplo, gestão de erros abrangentes) e oferecer APIs no Elasticsearch e UIs no Kibana para gerenciar e monitorar CCR.
Fique de olho nos próximos posts para saber mais sobre esses casos de uso em detalhe.
Como começar com a replicação entre clusters
Entre na nossa página de downloads para baixar as versões mais recentes do Elasticsearch e do Kibana e ver o nosso guia para iniciantes.
O CCR é um recurso platinum e está disponível através de uma licença de uso gratuito por 30 dias que pode ser ativada através de API de iniciar teste ou diretamente do KIbana.
Introdução técnica à replicação entre clusters no Elasticsearch
O CCR foi criado em um modelo de indexação ativo-passivo. Um índice em um cluster Elasticsearch pode ser configurado para replicar alterações de um índice em outro cluster. O índice que está replicando as alterações é chamado de “índice seguidor” e o índice que está sendo replicado é chamado “índice líder” O índice seguidor é passivo porque pode servir para solicitações de leitura e buscas, mas não pode aceitar escritos diretamente. Só o índice líder está ativo para escrita diretamente. Um CCR é gerenciado no nível do índice, um cluster pode conter tanto os índices líderes quanto seguidores. Dessa forma, você pode resolver alguns casos de uso ativo-ativo replicando alguns índices em uma direção (por exemplo, de um cluster nos EUA para um na Europa) e outros índices no outro sentido (de um europeu para um norte-americano).
A replicação é feita nos fragmentos. Cada fragmento do índice seguidor puxa as alterações do fragmento correspondente no índice líder, o que significa que um índice seguidor tem o mesmo número de fragmentos que o líder. Todas as operações são replicadas pelo seguidor, para que as operações de criar, atualizar ou excluir um documento sejam replicadas. A replicação acontece quase em tempo real, assim que um ponto global em um fragmento avança uma operação e está qualificado para ser replicado pelo fragmento seguinte. As operações tiveram o pull realizado e foram são indexadas de forma eficiente em lote pelo fragmento seguinte e podem ocorrer solicitações para efetuar pull das alterações concomitantemente. Essas solicitações de leitura podem acontecer pelo principal e suas réplicas e, além de ler a partir do fragmento, não colocar mais carga sobre o líder. Esse design permite que o CCR aumente sua carga de produção para que você possa continuar a aproveitar as taxas de indexação altas que tanto gosta (e espera) no Elasticsearch.
O CCR aceita tanto índices novos quanto antigos. Quando um seguidor for configurado inicialmente, ele fará um bootstrap a partir do índice líder copiando os arquivos do índice líder em um processo parecido com o de uma réplica recuperando dados do principal. Depois desse processo de recuperação, o CCR replicará qualquer operação adicional a partir do líder. Alterações de mapa e configurações são replicadas automaticamente conforme necessário a partir do índice líder.
De tempos em tempos, o CCR pode encontrar cenários de erros (por exemplo, uma falha de rede). O CCR consegue classificar automaticamente esses erros em erros recuperáveis e erros fatais. Quando ocorre um erro recuperável, o CCR insere um loop de tentar novamente para que assim que a situação que levou à falha se resolva, o CCR consiga voltar com a replicação.
O status da replicação pode ser monitorado com uma API dedicada. Através dessa API, você consegue monitorar a distância a que o seguidor está do líder, ver estatísticas detalhadas sobre o desempenho do CCR e monitorar erros que exijam a sua atenção.
Integramos o CCR com os aplicativos de monitoramento e gerenciamento dentro do Kibana. A IU de monitoramento nos dá insights sobre o progresso do CCR e relatórios de error.

IU de monitoramento de CCR Elasticsearch no Kibana
A IU de gerenciamento permite que você configure clusters remotos, índices de seguidores e gerencie padrões de seguimento automáticos para a replicação automática de índice.
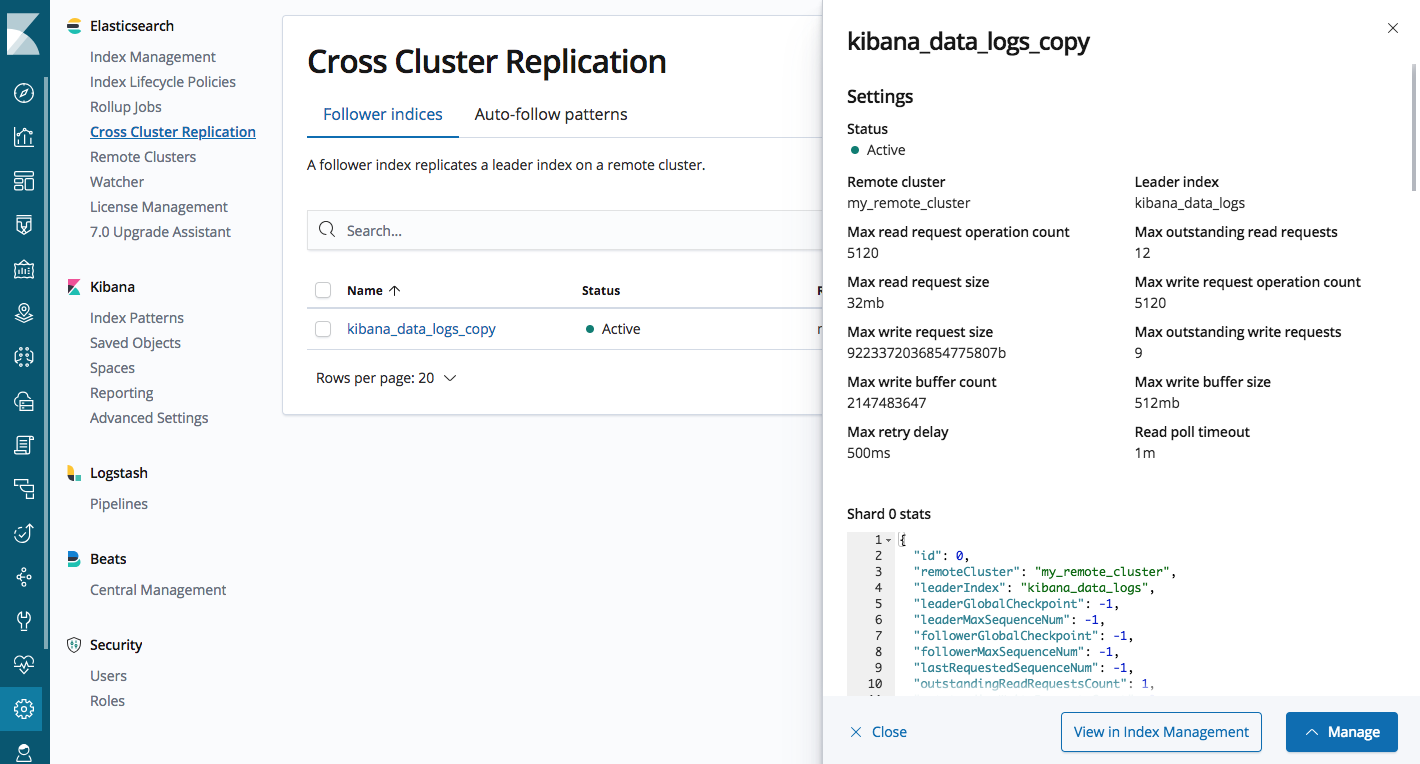
IU de gerenciamento de CCR Elasticsearch no Kibana
O mestre mandou seguir os índices de hoje
Muitos de nossos usuários têm cargas de trabalho que criam novos índices periodicamente. Por exemplo, índices diários de arquivos de registro que o Filebeat está empurrando ou índices que são virados automaticamente pelo gerenciamento de ciclo de vida do índice. Em vez de ter que criar manualmente índices seguidores para replicar esses índices de um cluster, criamos a função de seguimento automático diretamente no CCR. Essa funcionalidade permite configurar padrões de índices para serem replicados automaticamente de um cluster de origem. O CCR vai monitorar clusters de origem em busca de índices que correspondam a esses padrões e vai configurar índices de seguidores para replicar esses índices líderes.
Também integramos o CCR e o ILM para que os índices baseados em tempo possam ser replicados pelo CCR e gerenciados nos clusters de origem e de destino pelo ILM. Por exemplo, o ILM entende quando um índice líder está sendo replicado pelo CCR e gerencia com cuidado as operações destrutivas como encolhimento e exclusão de índices até que o CCR tenha acabado a replicação.
Quem não conhece a história...
Para que o CCR consiga replicar as alterações, exigimos um histórico de operações nos fragmentos do índice líder e indicadores em cada fragmento para saber quais operações são seguras para replicação. Esse histórico de operações é governado por ID sequenciais e o indicador é conhecido como checkpoint global. Mas existe uma complicação. Quando um documento é atualizado ou excluído no Lucene, o Lucene marca um bit para registrar que aquele documento foi excluído. O documento é retido em disco até que uma operação de transformação exclua de vez os documentos. Se o CCR replicar essa operação antes que o documento excluído seja transformado, tudo bem. No entanto, a transformação ocorre em um ciclo de vida próprio e isso significa que um documento excluído poderia ser transformado antes do CCR ter a oportunidade de replicar a operação. Sem alguma habilidade para controlar quando os documentos excluídos são transformados, o CCR poderia perder operações e não conseguir replicar o histórico de operações do índice seguidor completamente. Quando começamos a criar o CCR, pretendíamos usar o translog Elasticsearch como fonte para o histórico dessas operações. Isso contornaria o problema. Percebemos logo que o translog não era feito para os padrões de acesso que o CCR necessitava para ter bom desempenho. Pensamos em colocar estruturas de dados adicionais além do translog para alcançar o desempenho de que precisávamos, mas essa abordagem também tem algumas limitações. A primeira era o aumento de complexidade em um dos componentes mais críticos do nosso sistema, o que não está alinhado com a nossa filosofia de engenharia. Além disso, ia nos deixar de mãos atadas para alterações futuras que temos a intenção de criar no histórico de operações porque seríamos forçados a limitar os tipos de buscas no histórico ou reimplementar o Lucene sobre o translog. Com isso em mente, nós percebemos que precisávamos criar o recurso de forma nativa no Lucene para ter algum controle sobre quando um documento excluído seria transformado, colocando o histórico de operações de forma eficiente no Lucene. Chamamos essa tecnologia de “exclusões leves”. Este investimento no Lucene valerá a pena durante muitos anos, não só porque o CCR está construído sobre ele, mas também porque estamos recriando nosso modelo de replicação em cima de exclusões leves e a API de alterações que está por vir será baseada neles também. Exclusões leves precisam estar habilitadas nos índices líderes.
O que sobra então é para o seguidor conseguir influenciar quando os documentos com exclusão leve são transformados no líder. Para isso, introduzimos os leases de retenção de histórico do fragmento. Com um lease de retenção de histórico do fragmento, um seguidor pode marcar no histórico de operações do líder onde naquele histórico o seguidor está. Os fragmentos do líder sabem que operações abaixo desse marcador podem ser transformadas de forma segura, mas quaisquer operações acima dele precisam ser retidas até que o seguidor tenha a oportunidade de replicá-la. Com esses marcadores, se um seguidor ficar offline temporariamente, o líder reterá operações que ainda não foram replicadas. Como reter esse histórico exige mais armazenamento no líder, esses marcadores só são válidos por um período limitado, após o qual o marcador expirará e os fragmentos do líder serão liberados para transformar o histórico. Você pode ajustar a duração desse período com base na quantidade de armazenamento adicional que você está disposto a reter caso um seguidor fique offline e quanto tempo você está disposto a aceitar um seguidor ficar offline antes que ele tenha feito bootstrap no líder.
Resumo
Será um prazer ver você experimentar o CCR e compartilhar conosco o que achou da funcionalidade. Esperamos que você aproveite esta funcionalidade tanto quanto nós gostamos de desenvolvê-la. Fique de olho nos próximos posts da série em que vamos arregaçar as mangas e explicar em mais detalhes algumas das funcionalidades no CCT e os casos de uso para os quais o CCR serve. E se você tiver perguntas sobre o CCR, entre no fórum de Discussão.
A imagem miniatura associada a este post é de propriedade da NASA licenciada na licença CC BY-NC 2.0. A imagem associada a este post é de propriedade da Rawpixel Ltd, está licenciada pela licença CC BY 2.0 e foi cortada do original.