Schema em escrita ou schema em leitura
O Elastic Stack (ou ELK, como ele é conhecido) é um local muito popular para se armazenar registros.
Muitos usuários começam armazenando registros sem estrutura além de fazer parse no timestamp e talvez adicionar algumas tags para filtrar mais fácil. O Filebeat faz exatamente isso por padrão. Segue os registros e os envia para o Elasticsearch o mais rápido que pode sem extrair nenhuma estrutura. O Logs UI do Kibana também não presume nada sobre a estrutura dos registros. Um schema simples de @timestamp e “message” é suficiente. Isso é o que chamamos de abordagem de minimal schema para os registros. É mais fácil para o disco, mas não é muito útil para além de uma busca de palavras-chaves básicas e filtragem com base em tags.
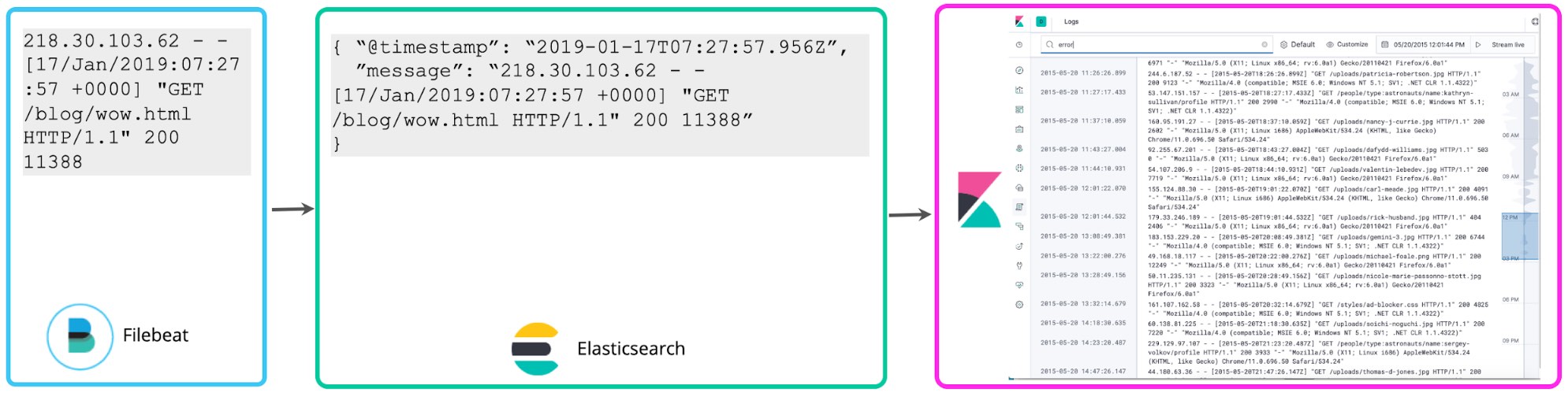
Depois que você se ambienta com seus registros, é normal querer fazer mais com eles. Se você notar que os números nos registros se relacionam com códigos de status, poderá querer contá-los para saber quantos códigos de status de nível 5xx você teve na última hora. Os campos criptografados do Kibana permitem que você aplique o schema nos registros na hora da busca para extrair esses códigos de status e realizar agregações, visualizações e outros tipos de ações. Essa abordagem costuma ser chamada de schema em leitura.
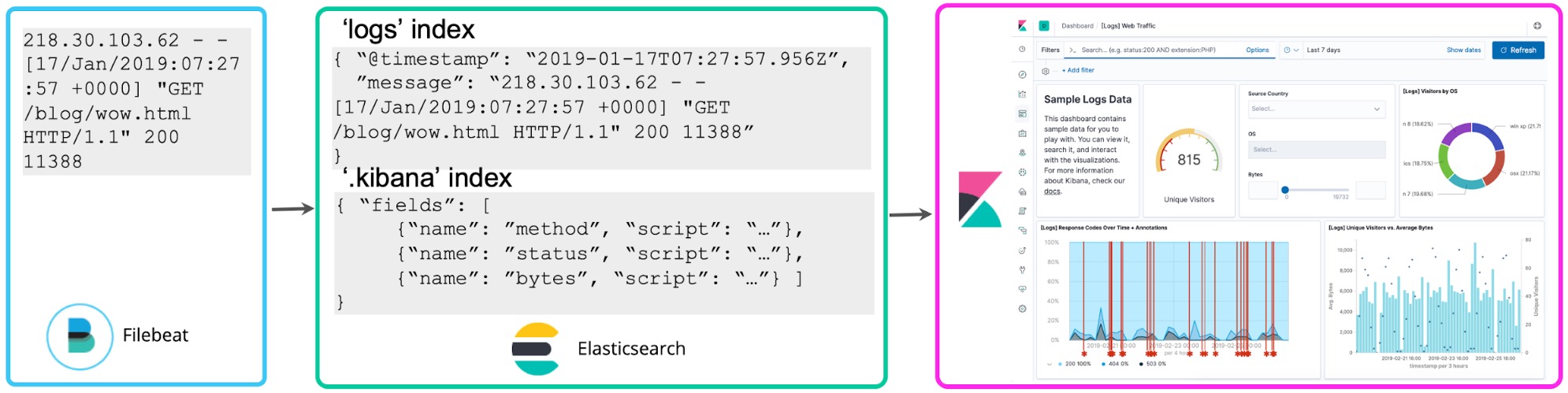
Embora seja conveniente para exploração ad hoc, o lado ruim dessa abordagem é que se você adotá-la para fins de relatórios e painéis contínuos, terá que reexecutar o campo extraction cada vez que fizer uma busca ou renderizar novamente a visualização. Em vez disso, depois que você tiver decidido quais campos estruturados quer usar, um processo de reindexação pode ser feito no fundo para “manter” esses campos criptografados em campos estruturados em um índice permanente do Elasticsearch. E para os dados que entram no Elasticsearch, você pode configurar um Logstash ou um pipeline de nós de ingestão para extrair esses campos de forma proativa usando os processadores dissect ou grok.
O que nos leva a uma terceira abordagem, que é fazer parse com os registros na hora de escrever para extrair os campos mencionados acima de forma proativa. Esses registros estruturados são muito interessantes para os analistas, pois eles não precisam descobrir como extrair os campos depois do fato, o que acelera as consultas e aumenta de forma dramática o valor que eles obtêm com os dados dos registros. Essa abordagem “schema em escrita” para centralizar as análises de registros é a escolha de muitos usuários do ELK.
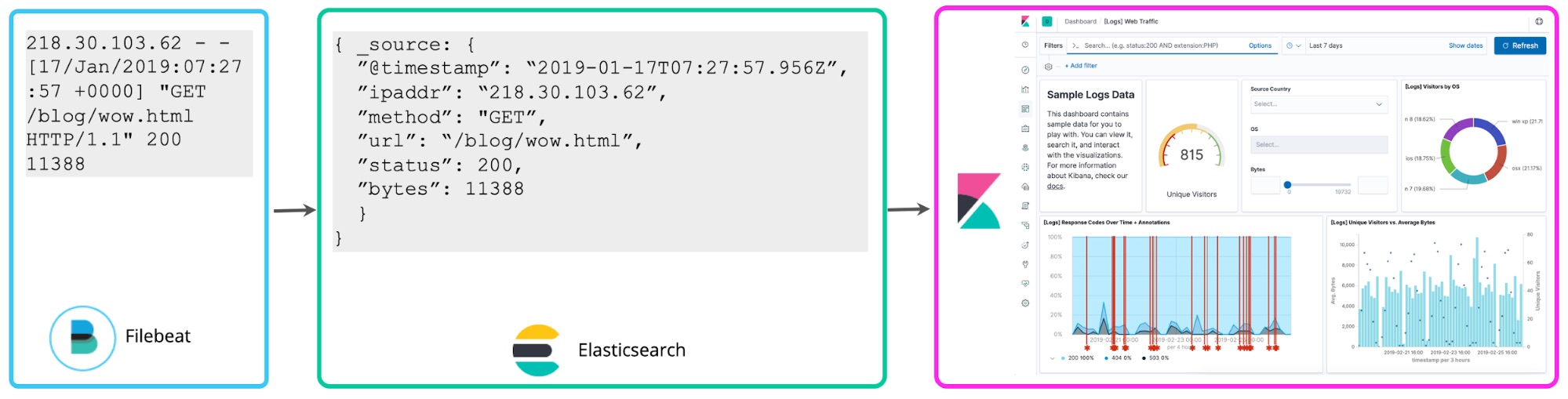
Neste post, vou falar sobre as diferenças entre essas abordagens e como pensar nelas dentro do seu planejamento. Vou falar sobre por que estruturar os registros de antemão é importante e por que eu acho que é recomendável para todos conforme a implementação dos registros centralizados amadurece, mesmo que você comece com uma pequena estrutura.
Benefícios do schema em escrita (e esclarecendo os mitos)
Vamos começar falando sobre por que você deveria estruturar registros na hora que os escreve em um cluster centralizado.
Melhor experiência de consulta. Quando você busca informações valiosas, é natural começar simplesmente buscando uma palavra-chave como “erro”. Mas os resultados de uma busca dessas podem ser conseguidos tratando cada linha do registro como um documento em um índice invertido e realizando uma pesquisa de texto completo. Mas o que acontece quando você quer fazer consultas mais complexas como “Quero todas as linhas do registro com my_field igual a N”. Se você não tiver o campo my_field definido, não conseguirá fazer essa pergunta diretamente (sem autocompletar). E mesmo que você perceba que seu registro tem essas informações, sabe que precisa escrever a regra de parse na sua consulta para extrair o campo e compará-lo com o valor esperado. No Elastic Stack, quando você estrutura seus registros de antemão, o recurso de autocompletar do Kibana vai sugerir campos e valores para construir suas consultas. É um salto em produtividade para os analistas. Agora, você e seus colegas podem fazer perguntas diretamente, sem ter que descobrir o que são os campos e sem ter que escrever regras de parsing complexas na hora da busca para extrair os campos.
Consultas históricas e agregações mais rápidas. Consultas em campos estruturados no Elastic Stack, mesmo as que são executadas em grandes quantidade de dados históricos, terão resultados em milissegundos. Compare isso aos minutos e horas necessários nos sistemas schema em leitura típicos. Isso acontece porque filtrar e executar agregações estatísticas em campos estruturados extraídos e indexados de antemão é muito mais rápido do que executar um regex em cada linha de registro para extrair o campo e operá-lo matematicamente. Isso é particularmente importante para consultas ad hoc, resultados que não podem ser acelerados de antemão, já que você não sabe quais consultas executará durante a investigação.
Registros para métricas. Ainda sobre a questão acima, o resultado de extrair valores numéricos de registros estruturados se parece muito com séries numéricas de tempo ou métricas. Executar agregações em cima desses pontos de dados valiosos de forma rápida é muito importante de uma perspectiva operacional. Os campos estruturados permitem que você trate os pontos de dados numéricos dos registros como métricas em escala.
A verdade no tempo certo. Quando você precisa resolver campos como endereço IP para hostname, é necessário fazer isso na hora do índice em vez de mais tarde na hora da consulta, porque mais tarde a resolução pode não ser válida para a transação anterior. Uma semana mais tarde, aquele IP pode estar ligado a um hostname completamente diferente. Isso se aplica a pesquisas em qualquer fonte externa, que só oferecem a situação mais recente do mapeamento, como resolução de nome de usuário para sistema de gestão de identidade, tag de ativo para CMDB e etc.
Detecção de anomalias e alerta em tempo real Assim como as agregações, a detecção de anomalia e alerta em tempo real funciona de forma mais eficiente em escala com campos estruturados. Caso contrário, as exigências de processamento contínuas em seu cluster serão muito grandes. Falamos com muitos clientes com dificuldade para criar alertas e trabalhos de detecção de anomalias para explicar porque extrair os campos na hora da busca simplesmente não dá conta da quantidade de alertas de que precisam. Isso significa que os dados do registro que eles coletam só é adequado para casos de uso altamente reativos e limitam o retorno sobre o investimento naquele projeto.
Registros em iniciativas de observabilidade. Se você tem uma iniciativa de observabilidade, sabe que não é suficiente simplesmente coletar e pesquisar os registros. Os dados de registro devem estar correlacionados de forma ideal com as métricas (ex.: uso de recursos) e rastros do aplicativo para contar ao operador uma história holística sobre o que está acontecendo no serviço, não importa de onde venham os pontos de dados. Essas correlações funcionam melhor em campos estruturados, senão a busca é lenta e a análise não é usável em situações práticas em escala.
Qualidade de dados. Ao fazer o processamento de seus eventos de antemão, você tem a oportunidade de verificar dados inválidos, duplicados ou faltantes e corrigir esses problemas. Se você confiar no schema em leitura, não saberá se os seus resultados estão sendo precisos porque a validade e a completude desses dados não foi verificada de antemão. Isso pode levar a resultados imprecisos e conclusões incorretas com base nos dados que estão voltando.
Controle de acesso granular. Aplicar regras de segurança granular, como restrições em nível de campo, em dados de registro não estruturados é complicado. Filtros para restringir o acesso aos dados no momento da busca podem ajudar, mas eles têm limitações significativas como a incapacidade de trazer resultados parciais que consistem em um subconjunto desses campos. No Elastic Stack, a segurança em nível de campo permite que os usuários com um conjunto menor de privilégios vejam alguns campos e não outros por todo o conjunto de dados. Por isso, proteger dados PII nos registros e permitir que um conjunto maior de usuários opere em outras informações se torna muito mais fácil e flexível.
Exigências de hardware
Um mito comum com relação ao “schema em escrita” é que usá-lo significa que seu cluster exigirá mais recursos para fazer parse com os registros e armazenará tanto os formatos com parse como sem parse (ou indexados). Vamos ver alguns detalhes importantes que você deve considerar de acordo com o seu uso, porque a resposta é que, de fato, depende.
Parsing único ou extração de campos contínua. Fazer parsing e armazenar seus registros em um formato estruturado consome muita capacidade de processamento no lado da ingestão. No entanto, realizar repetidas consultas em registros não estruturados que executam um regex complexo para extrair campos consume muito mais RAM e recursos do CPU. Se você concluir que o caso de uso comum para seus registros é só uma busca ocasional, talvez estruturá-las de antemão seja um desperdício. Mas, se você prever que consultar seus registros de forma ativa e executar agregações em dados de registro é algo esperado, o custo único da ingestão pode ser menos oneroso do que os custos contínuos de executar as mesmas operações no momento da consulta.
Exigências de ingestão. Com o processamento adicional de antemão, o resultado da sua ingestão pode ser mais baixo em comparação com o que seria se você não fizesse nada. Você pode introduzir infraestruturas de ingestão adicionais para lidar com essa carga, escalonando de forma independente seus nós de ingestão do Elasticsearch ou instâncias do Logstash. Existem bons recursos e blogs sobre como abordar isso e, se você estiver usando o Serviço Elasticsearch no Elastic Cloud, escalonar a ingestão é tão fácil quanto inserir mais nós capazes de ingestão.
Exigências de armazenamento. A verdade, por mais que não pareça, é que as exigências de armazenamento podem diminuir quando você dedica um tempo a entender a estrutura dos seus registros de antemão. Os registros podem ser muito longos e confusos. Ao examiná-los de antemão (mesmo que você não faça o parsing completo em cada campo), você pode decidir quais linhas do registro e quais campos extraídos quer manter online para a busca em seu cluster de registro centralizado e o que arquivar logo de cara. Essa abordagem pode reduzir as exigências gerais do disco ao armazenar registros longos e confusos. O Filebeat tem processadores dissect e drop leves exatamente para isso.
Mesmo que você tenha que manter cada linha de registro por conta das exigências regulamentares, existem formas de otimizar os custos de armazenagem com o “schema em escrita". Primeiro, o controle é seu. Você não precisa estruturar seus registros de forma completa. Se o caso de uso pedir, adicione somente algumas peças importantes de metadados estruturados e deixe o resto da linha do registro sem parsing. O lado bom é que, se você estruturar completamente os registros, onde cada dado importante fique em um armazenamento estruturado, não precisará manter o campo “source” no mesmo cluster que tem os registros indexados. Pode armazená-lo para economizar espaço.
Também há diversas formas de otimizar os padrões do Elasticsearch se o armazenamento for um problema. Você pode fazer alguns ajustes para comprimir mais os dados. Também é possível utilizar arquiteturas hot/warm e índices congelados para aproveitar ao máximo o armazenamento para dados que você acessa com menos frequência e retenções mais longas. Mas lembre-se, que, quando falamos em dados hot, o armazenamento é relativamente barato se comparado aos minutos de espera para se obter uma resposta à sua consulta quando você mais precisa.
Definir a estrutura de antemão
Outro mito que ouvimos é que estruturar os registros antes de armazená-los é difícil. Vamos desmistificar isso um pouco.
Registros estruturados. Muitos registros já são produzidos em formato estruturado. Os aplicativos mais comuns são compatíveis com registros diretamente no JSON. Isso significa que você pode começar a fazer a ingestão de seus registros diretamente no Elasticsearch e armazená-los em formatos estruturados sem a necessidade de fazer parsing.
Regras de parsing pré-construídas. Existem uma série de regras de parsing pré-construídas compatíveis com a Elastic. Por exemplo, os módulos do Filebeat estruturam registros de prestadores conhecidos para você e o Logstash contém um ampla biblioteca de padrão grok. Muitas outras regras de parsing pré-construídas estão disponíveis na comunidade.
Regras de parsing geradas automaticamente Para definir regras para extrair campos de registros personalizados, você pode usar ferramentas como o Visualizador de Dados do Kibana, que dá sugestões de como fazer parse automaticamente. Basta colar uma amostra do registro e obter um padrão grok que você possa usar no nó ingest ou no Logstash.
O que acontece quando o formato do seu registro muda
O último mito que ouvimos muito é que o schema em escrita torna mais difícil lidar com formatos de registro que mudam. Isso simplesmente não é verdade. Alguém terá que lidar com os formatos de registro que mudam, independentemente da abordagem que você usar para extrair inteligência dos seus registros (de antemão ou depois do fato), já que você vai fazer mais do que uma busca de texto completo. Seja com um pipeline de nó de ingestão no registro como se estivesse indexado ou com o campo criptografado do Kibana que faz a mesma coisa na hora da busca, quando o formato do registro muda, a lógica de extrair os campos precisará ser modificada também. Observe que para os módulos do Filebeat que mantemos, monitoramos quando os fornecedores de registros upstream lançam novas versões e atualizamos a compatibilidade depois de fazer testes.
Existem diferentes abordagens para se lidar com as estruturas de registros que mudam no momento da escrita.
Modificar a lógica de parsing de antemão. Se você souber que o formato do registro vai mudar, poderá criar um pipeline de processamento paralelo e dar suporte a ambas as versões do registro por um período da transição. Isso costuma se aplicar a formatos dos registros que você consegue controlar.
Escreva um schema mínimo em caso de falha de parsing. Nem sempre se sabe das mudanças com antecedência e, às vezes, os registros que não estão sob o seu controle mudam também. Você pode levar isso em conta no pipeline do registro desde o primeiro momento. No grok parse fail, escreva um schema mínimo de timestamp e mensagem sem parse e envie um alerta para o operador. Nesse momento, é possível criar um campo criptografado para um novo formato de registro para evitar disrupção do fluxo de trabalho do analista, modificar o pipeline dali para frente e considerar indexar novamente os campos para a duração curta da disrupção na lógica de parsing.
Atraso no evento de escrita na falha de parsing. Se o schema em escrita mínimo não ajudar, você pode falhar na hora de escrever a linha de registro, se a lógica de parsing falhar, e deixar o evento de lado em uma “dead letter queue” (o Logstash oferece essa funcionalidade) e enviar o alerta para o operador, que poderá corrigir a lógica e reexecutar os eventos da fila no novo pipeline de parsing. Isso cria uma disrupção na análise, mas você não precisa lidar com os campos criptografados e a reindexação.
Uma analogia apta
Este artigo está ficando grande e, se você chegou até aqui, meus parabéns! Uma coisa que me ajuda a internalizar conceitos é uma boa analogia. E ao falar desse assunto com Neil Desai, Especialista em Segurança do Elasticsearch, conheci uma analogia muito interessante para falar do schema em leitura e do schema em escrita. Espero que goste também.

Na hora do encerramento: a escolha é sua
Como falei no começo, não existe uma resposta que vá servir para todas as implementações de registros centralizados quando se fala em schema em escrita ou schema em leitura. Na realidade, a maioria das implementações que vemos estão no meio termo. Estruturam alguns registros até um certo ponto e deixam outros em um schema básico (@timestamp e message). Tudo depende do que você está tentando fazer com os registros e se é mais importante a velocidade e a eficiência das consultas estruturadas ou escrever os dados no disco assim que possível sem ter trabalho de antemão. O Elastic Stack funciona das duas formas.
Para começar com os registros no Elastic Stack, use um cluster no Elasticsearch Service ou baixe-o para trabalhar de forma local. E veja o novo aplicativo de Logs do Kibana que otimiza seu fluxo de trabalho para trabalhar com registros de qualquer tamanho ou forma, estruturados ou não.