Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
This blog series reveals how our Field Engineering team used the Elastic stack with generative AI to develop a lovable and effective customer support chatbot. If you missed other installments in the series, be sure to check out:
- Part 1: Building our proof of concept
- Part 2: Building a knowledge library
- Part 3: Designing a chat interface for chatbots... for humans
- Part 4: Tuning RAG search for relevance
- Launch blog: GenAI for customer support - Explore the Elastic Support Assistant
What I find compelling about observability is that it has utility in both good times and bad. When everything is going great, your observability is what provides you the metrics to show off the impact your work is having. When your system is a rough day, your observability is what will help you find the root cause and stabilize things as quickly as possible. It's how we noticed a bug causing us to load the same data over and over again from our server. We saw in the APM data that the throughput for one of our endpoints was well over 100 transactions per minute, which was unreasonably large for the size of our user base. We could confirm the fix when we saw the throughput reduce to a much more reasonable 1 TPM. It's also how I know we served up our 100th chat completion 21 hours post launch (you love to see it folks). This post will discuss the observability needs for a successful launch, and then some unique observability considerations for a chatbot use case such as our Support Assistant.
Critical GenAI observability components
You're going to want three main pieces in place. A status dashboard, alerting, and a milestones dashboard, in that order. We’ll dig more into what that means, and what I put into place for the Support Assistant launch as it pertains to each. There is one requirement that all three of those components requires; data. So before we can dive into how to crunch the data for actionable insights, let’s take a look at how we collect that data for the Support Assistant (and generally for the Support Portal).
Observability data collection
We have an Elastic Cloud cluster dedicated to monitoring purposes. This is where all of the observability data I am going to discuss gets stored and analyzed. It is separate from our production and staging data Elastic clusters which are where we manage the application data (e.g. knowledge articles, crawled documentation).
We run Elastic’s Node APM client within our Node application that serves the API, and have Filebeat running to capture logs. We have a wrapper function for our console.log and console.error calls that appends APM trace information at the end of each message, which allows Elastic APM to correlate logs data to transaction data. Additional details about this feature are available on the Logs page for APM. The key piece of information you'll find there is that apm.currentTraceIds exists to provide exactly what you need. From there it's nothing complicated, just a pinch of string formatting. Copy ours. A small gift; from my team, to yours.
We use the Elastic Synthetics Monitoring feature to check on the liveliness of our application and critical upstream services (e.g. Salesforce, our data clusters). At the moment we use the HTTP monitor type, but we're looking at how we might want to use Journey monitors in the future. The beauty of the basic HTTP monitor is that all you need to configure is a URL to ping, how often you want to ping it, and from where. When choosing which locations to check from, we know for the app itself we want to check from locations around the world, and because there are some calls directly from our user's browsers to the data clusters, we also check that from all of the available locations. However, for our Salesforce dependency, we know we only connect to that from our servers, so we only monitor that from locations where the Support Portal app is being hosted.
We also ship Stack Monitoring data from the application data Elastic clusters, and have the Azure OpenAI integration shipping logs and metrics from that service via an Elastic Agent running on a GCP Virtual Machine.
Setting up Elastic APM
Getting started with Elastic APM is really easy. Let's go over the APM configuration for our Support Portal's API service as an example.
Let's unpack a few things going on there. The first is that we've allowed ourselves to inject a mock APM instance in testing scenarios, and also added a layer of protection to prevent the start function from being called more than once. Next, you'll see that we are using environment variables to power most of our configuration options. APM will automatically read the ELASTIC_APM_ENVIRONMENT environment variable to fill in the environment setting, ELASTIC_APM_SERVER_URL for the serverUrl setting, and ELASTIC_APM_SECRET_TOKEN for the secretToken setting.
You can read the full list of configuration options here, which includes the names of the environment variables that can be used to configure many of the options. I want to emphasize the value of setting environment. It allows me to easily distinguish traffic from different environments. Even if you aren't running a staging environment (which you really should), collecting APM when you're developing locally can also come in handy, and you will want to be able to look at production and development data in isolation most of the time. Being able to filter by service.environment is convenient.
If you're running in Elastic Cloud, you can follow these steps to get the values for serverUrl and secretToken to use with your configuration. Visit your Kibana instance, and then navigate to the Integrations page. Find the APM integration. Scroll past the APM Server section to find the APM Agents section and you'll see a Configure the agent subsection that includes the connection info.
Status dashboard
Data is only as useful as your ability to extract meaning from it, and that’s where dashboarding comes in. With Elastic Cloud, it’s default to be running Kibana along with Elasticsearch, so we’ve already got a great visualization layer available within our stack. So what do we want to see? Usage, latency, errors, and capacity are pretty common categories of data, but even within those, your specific needs will dictate what specific visualizations you want to make for your dashboard. Let’s go over the status dashboard I made for the Support Assistant launch to use as an example.
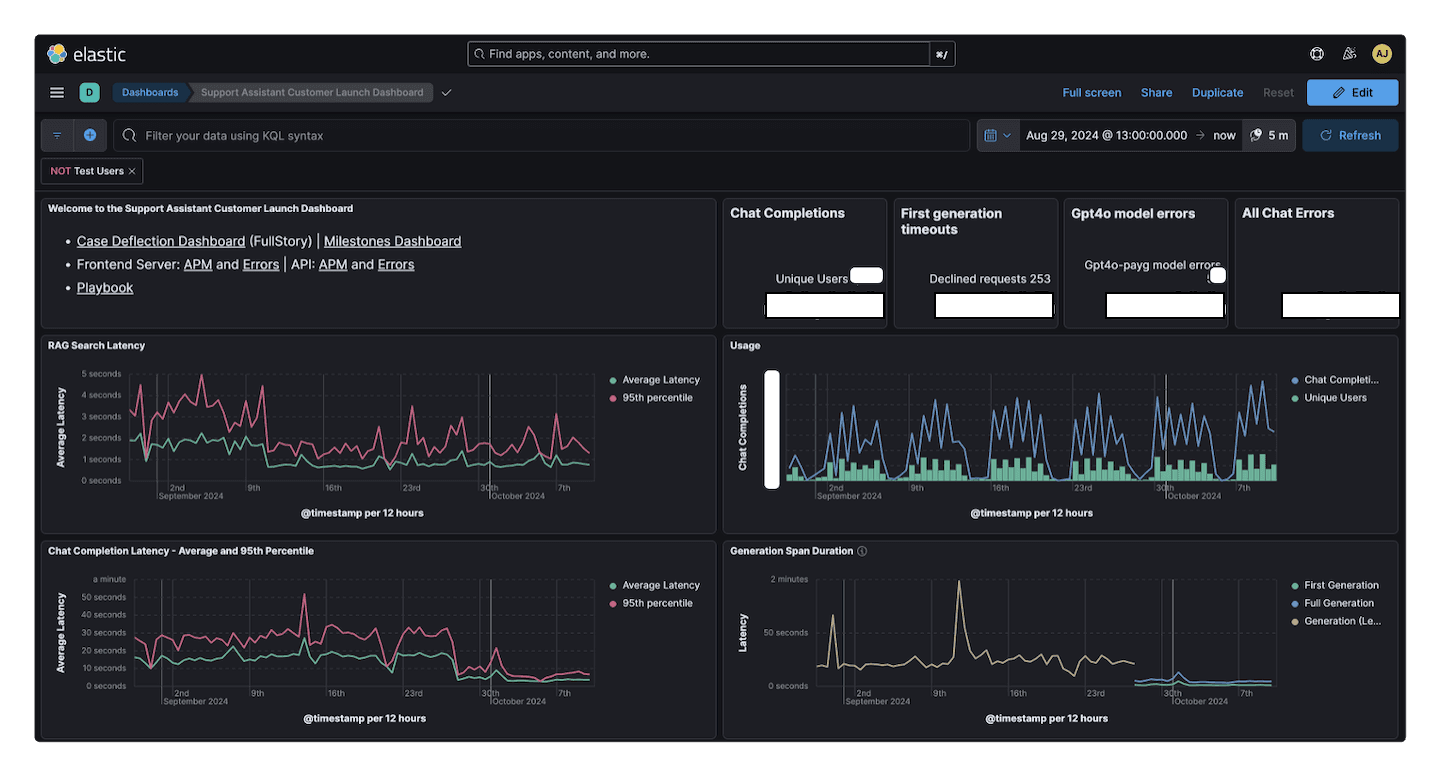
You might be surprised to notice the prime real estate in the upper-left being host to text. Kibana has a markdown visualization you can use to add instructions, or in my case a bunch of convenient links to other places where we might want to follow up on something seen in the dashboard. The rest of the top row displays some summary stats like the total number of chat completions, unique users, and errors for the time range of the dashboard. The next set of visualizations are time series charts to examine latency, and usage over time. For our Support Assistant use case, we are specifically looking at latency of our RAG searches and our chat completions. For usage, I’m interested in the number of chat completions, unique users, returning users, and a comparison of assistant users to all Support Portal users. Those last two I've left below the fold of the image because they include details we decided not to share.
I like to save a default time range with dashboards. It anchors other users to a default view that should be generally useful to see when they first load the dashboard. I pinned the start timestamp to approximately when the release went live, and the end is pinned to now. During the launch window, it's great to see the entire life of the feature. At some point it will probably make more sense to update that stored time to be a recent window like “last 30 days.”
Bonus challenge: Can you tell when we upgraded our model from GPT-4 to the more powerful GPT-4o?
I have additional areas of the status dashboard focused on users who are using the most or experiencing the most errors, and then also some time series views of HTTP status and errors over time. Your status dashboard will be different, and it should be. This type of dashboard also has the tendency to evolve over time (mine did noticably during the time I was drafting this post). Its purpose is to be the answer key to the series of questions that are most important to be able to answer about the feature or system you’re observing. You will discover new questions that are important, and that might add some new visualizations to the dashboard. Sometimes a question becomes less relevant or you come to understand it was less meaningful than you expected, and so you could remove or rearrange it below other items. Before we move on from this dashboard, let's take a couple of detours to take a look at an APM trace for our chat completions, and then how I used ES|QL to create that returning users visualization.
APM traces
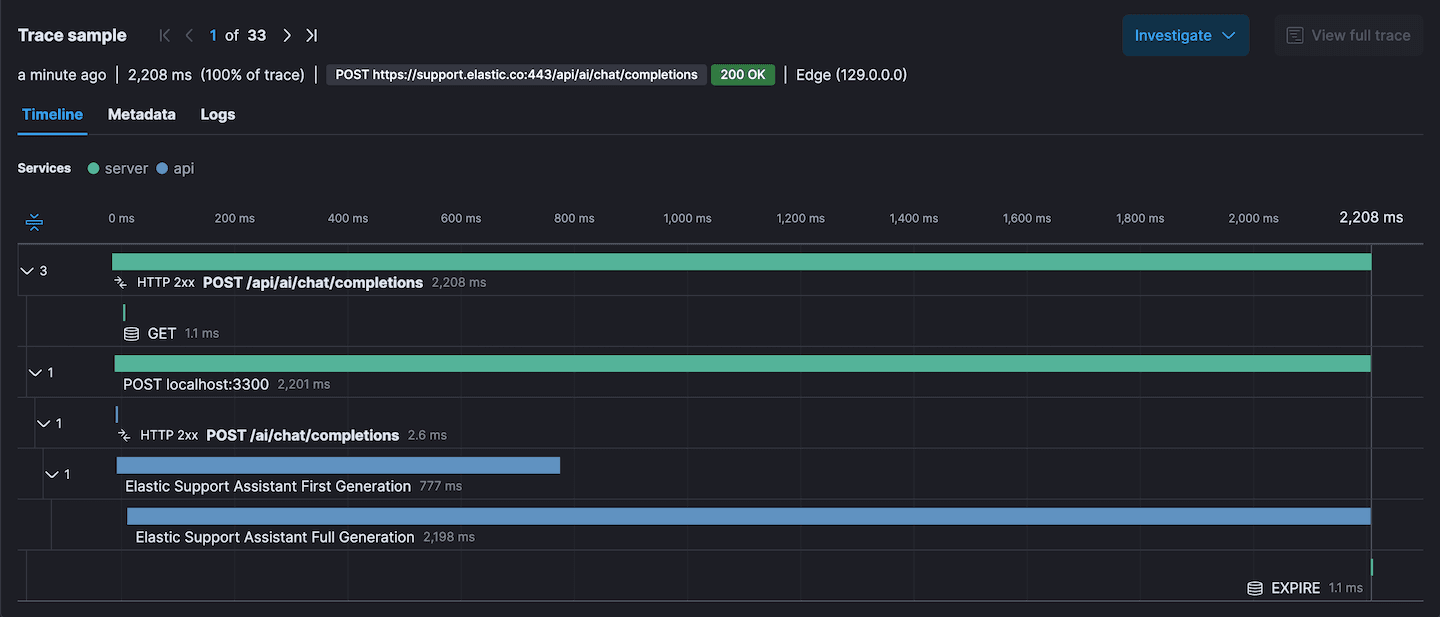
If you've never seen an Elastic APM trace there is probably a ton of really compelling things going on in that image. The header shows request URL, response status, duration, which browser was used. Then when we get into the waterfall chart we can see the breakdown of which services were involved and some custom spans. APM understands that this trace traveled through our frontend server (green spans), and our API service (blue spans).
Custom spans are a great way to monitor performance of specific tasks. In this case where we are streaming chat completions, I want to know how long until the first tokens of generation arrive, and also how long the entire completion process takes. The average duration of these spans is charted on the dashboard. Here's a trimmed down snippet of the chat completion endpoint that focusses on starting and ending the custom spans.
Using ES|QL to visualize returning users
When I first started trying to visualize repeat users, my original goal was to end up with something like a stacked bar chart per day where the total size of the bar should be the number of unique users that day, and the break down would be net new users vs. returning users. The challenge here is that to compute this requires overlapping windows, and that's not compatible with how histograms work in Kibana visualizations. A colleague mentioned that ES|QL might have some tools to help. While I didn't end up with the visualization I originally described, I was able to use it to help me process a dataset where I could generate the unique combinations of user email and request date, which then enabled counting how many unqiue days each user had visited. From there, I could visualize the distribution of quantity of visits. Here's the ES|QL query that powers my chart.
Alerting
With the status dashboard in place, you have a way to quickly understand the state of the system both at the present and over time. The metrics being displayed in the visualizations are inherently metrics that you care about, but you can’t nor would you want to be glued to your dashboard all day (well maybe the excitement of the first couple days after launch left me glued to my dashboard, but it’s definitely not a sustainable strategy). So let’s talk about how alerting can untether us from the dashboard, while letting us sleep well, knowing that if something starts going wrong, we’ll get notified instead of finding out the next time you chase the sweet sensation of staring at that beautiful dahsboard.
A very convenient thing about Elastic Observability is that the details you need to know to make the alerting rules, you already figured out in making the visualizations for the dashboard. Any filters you were applying, and the specific fields from the specific indices that you visualized are the main configuration details you need to configure alerting rules. You’re essentially taking that metric defined by the visualization and adding a threshold to decide when to trigger the alert.
How should I pick a threshold?
For some alerts it might be about trying to achieve a certain quality of service that is defined by the team. In a lot of cases, you want to use the visualizations to establish some sort of expected baseline, so that you can then choose a threshold based on how much of a deviation from that observed baseline you’re willing to tolerate.
This is a good time to mention that you might be planning to hold off integrating APM until the end of the development process, but I would encourage you to do it sooner. For starters, it’s not a big lift (as I showed you above). The big bonus for doing it early is that during development you are capturing APM information. It might help you debug something during development by capturing details you can investigate during an expected error, and then it’s also capturing sample data. That can be useful for both verifying your visualizations (for metrics involving counts), and then also for establishing baseline values for metric categories like latency.
How should I get alerted?
That will really depend on the urgency of the alert. For that matter, there are some alerts where you may want to configure multiple alerts at different thresholds. For example, at a warning level, you might just send an email, but then there could also be a critical level that sends a Slack message tagging your team. An example of a non-critical alert that is best as email-only are the ones I configured to go along with the milestones dashboard we’ll talk about next. It’s a good idea to test the formatting of your alert outputs by temporarily configuring it such that it will trigger right away.
A best practice for determining which alerts notify in passive ways (e.g. an email) vs. demanding immediate attention (e.g. getting paged) is to ask yourself "is there a defined set of steps to take in response to this alert to resolve it?" If there is not a well-defined path to take to investigate or resolve an alert, then paging someone isn't going to add much value, and instead just add noise. It can be hard to stick to this, and if you've just realized that you've got a bunch of unactionable alerts being noisy, maybe see if you can think of a way to surface those in a less demanding way. What you don't want, is to accidentally train your team to ignore alerts because they are so often inactionable.
Milestones dashboard
The milestones dashboard arguably does not need to be separate from the status dashboard, and could be arranged as an area of the status dashboard, but I like having the separate space focused on highlighting achievements.
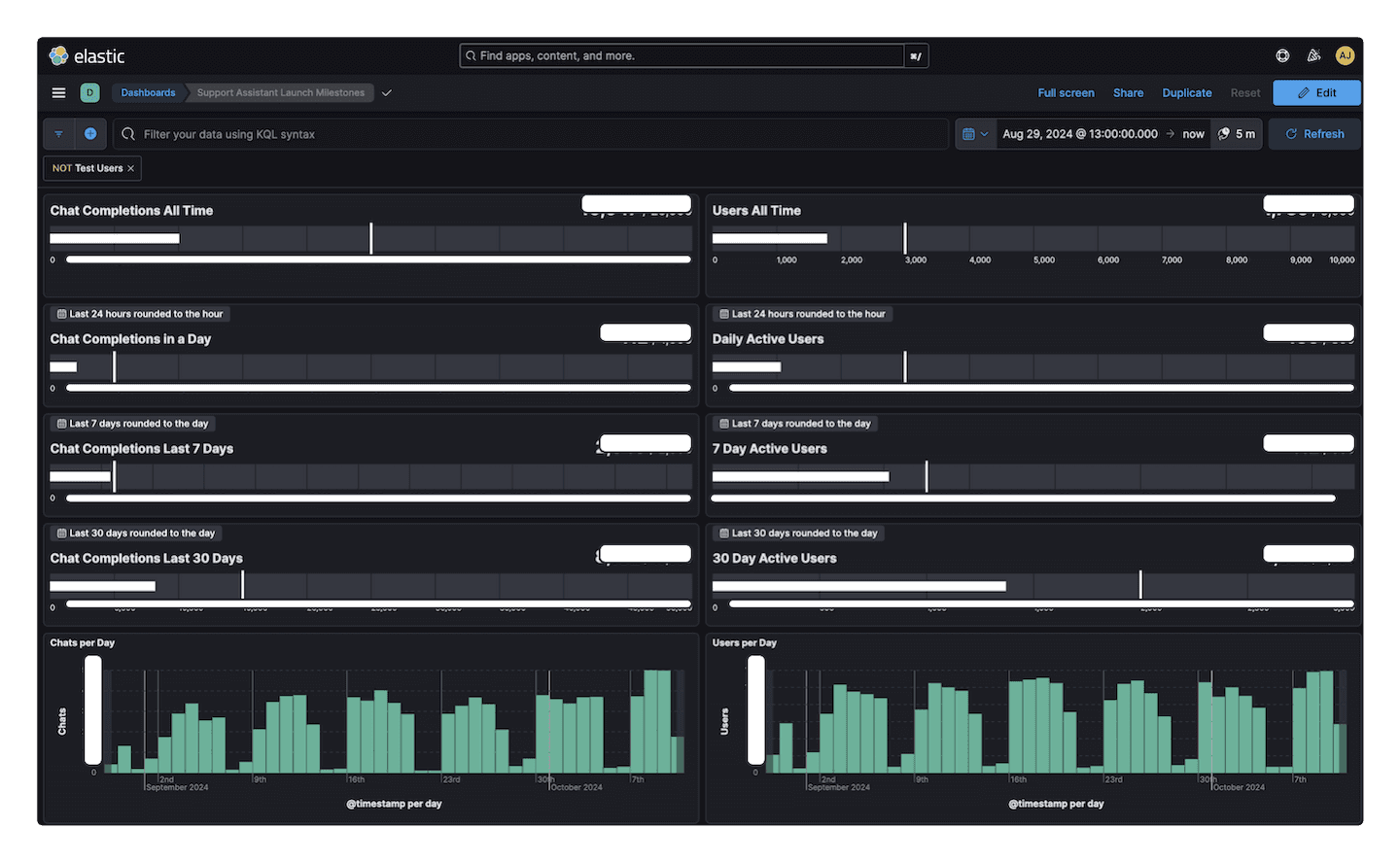
The two metrics I was most interested in highlighting with milestones were unique users, and chat completions. There is a horizontal bullet visualization that I found suitable for displaying a gauge with a set range and an optional goal. I decided that time windows for all time, last 7 days, and last 30 days were standard but interesting to look at and so I have two columns side by side where each row is a different window of time. The bottom row has a bar chart aggregating by day, creating a nice way to look for growth over time.
Special considerations for the Support Assistant & GenAI Observability
We’ve discussed the basics of observing any new feature or system you’re launching, but every project is going to have some unique observability opportunities, so the rest of this blog post will be discussing some of the ones that came up for our team while working on the Support Assistant. If you’re also building a chatbot experience, some of these might apply directly for your use case, but even if your project is very different, maybe these ideas inspire some additional observability options and strategies.
NOTE: Most of the code examples I am about to share come from the chat completion request handler in our API layer where we send a request to the LLM and stream the response back to the client. I am going to show you that same handler a few different times, but editted down to only include the lines relevant to the functionality being described at that time.
First generation timeouts
You may remember from the UX entry in this series that we chose to use streaming responses from the LLM in order to avoid having to wait for the LLM generation to finish before being able to show anything to the user. The other thing we did to try to give our assistant a more responsive experience was to enforce a 10 second timeout on getting the first chunk of generated text back. Being able to see trends in this type of error is critical for us to be able to know if our service is reliable, or overloaded. We've noticed with the launch that these timeouts are more likely to happen when there are more simultaneous users. Sometimes this even leads to retries overloading the provisioned capacity on our LLM service, leading to further errors displayed to the user.
The APM agent runs on our server, and the timeout for first generation was configured in the client code that runs in the user’s browser, so I started experimenting with listening for events on the server to detect when the client had sent the abort signal so that I could send an error to APM with captureError, but what I found was that the server never became aware that the client aborted the request. I listened on the request, I listened on the socket, and then I did some Internet searches, and reached the conclusion that at least for our application stack there was no practical or built-in way for our server to recognize the client had timed out.
To work around this, I moved the timeout and AbortController from the client code to be in our API layer that was talking directly to the LLM. Now when we hit the timeout, we’re on the server where we can send the error to APM and then close the connection early from the server side, which propagates just fine down to the client.
Here's a view of our request handler that shows just the parts related to first generation timeout:
Unfortunately, just closing the connection from the server created an unexpected behavior with the client. Without sending back a proper error signal or any generated response text, the client code was not running the parts of the code where we exited the loading state. To smooth this out, I updated the server side timeout to add an extra step before calling end() on the response. The streaming responses work by sending a series of events related to the generation down to the client. There are 4 flavors; Started, Generation, End, and Error. By adding an extra step to send an Error event before closing the connection, the client code was able to update the UI state to reflect an error.
So let's see the handler again with that included:
The first generation timeout error is a very generic error, and always logs the same message. For the other types of errors, there are many different failures that could result in reaching the error handler. For this, we pass in a parameterized message object, so that APM will group all of the errors captured by the same error handling together, despite the error message varying depending on the actual error that occurred. We have parameters for the error message, error code, and also which LLM we used.
Declining requests
The goal of the Support Assistant is to be helpful, but there are two broad categories of input that we want to avoid engaging with. The first is questions unrelated to getting technical support for Elastic products. We think it’s pretty fair to insist that since we pay the bills for the LLM service, that we don’t want folks using the Support Assistant to draft emails or write song lyrics. The second broad category we avoid are topics we know it cannot answer well. The prime example of this is billing questions. We know the Support Assistant does not have access to the data needed to help answer billing questions accurately, and certainly for a topic like billing, an inaccurate answer is worse than none at all (and the Sales team, finance team, and lawyers all breathed a sigh of relief 😉). Our approach was to add instructions to the prompt before the user's input as opposed to using a separate call to a 3rd party service. As our hardening needs evolve we may consider adding a service, or at least splitting the task of deciding whether or not to attempt to respond into a separate LLM request dedicated to making that determination.
Standardized response
I’m not going to share a lot of details about our prompt hardening methods and what rules we put in the prompt because this blog is about observability, and I also feel that the state of prompt engineering is not at a place where you can share your prompt without helping a malicious user get around it. That said, I do want to talk about something I noticed while I was developing our prompting strategy to avoid the two categories mentioned above.
I was having some success with getting it to politely decline to answer certain questions, but it wasn’t very consistent with how it replied. And the quality of the response varied. To help with this, I started including a standardized response to use for declining requests as part of the prompt. With a predefined response in hand, the chatbot reliably used the standard response when declining a request. The predefined response is stored as its own variable that is then used when building the payload to send to the LLM. Let's take a look at why that comes in handy.
Monitoring declined requests
Bringing this back to observability, by having a predefined response for declining requests, it created an opportunity for me to examine the response coming from the LLM, and compare it to the variable containing the standardized decline message. When I see a match, I use captureError to keep a record of it. It’s important for us to keep an eye on declined requests because we want to be sure that these rejections are happening for the right reasons. A spike in rejections could indicate that a user or group of users is trying to get around our restrictions to keep the chat on the topic of Elastic product technical support.
The strategy shown above collects all the tokens in a string[] and then joins then when the response is complete to make the comparison. I heard a great optimization suggestion from a colleague. Instead of collecting the tokens during streaming, just track an index into the DECLINED_REQUEST_MESSAGE, and then as each token comes in, see if it matches the next expected characters of the message. If so, keep tracking, but if there ever isn't a match, you know it's not a declined request. That way you don't have to consume extra memory buffering the whole response. We aren't seeing performance or memory issues, so I didn't update my strategy, but it was too clever of an idea to not mention here.
Mitigating abuse
Closely related to the previous section on declining requests, we know that these chatbot systems backed by LLMs can be a target for folks who want free access to an LLM service. Because you have to be logged in and have a technical support subscription (included with Elastic Cloud) to get access to the Support Assistant, this was a bit less of a concern for our particular launch, but we wanted to be prepared just in case, and maybe your use case doesn’t have the same gating upfront. Our two prongs of abuse mitigation are a reduced rate limit for the chat completion endpoint, and a feature flag system with the flexibility to allow us to configure flags that block access to a particular feature for a given user or organization.
Rate limit
Our application already had a general rate limit across all of our endpoints, however that rate limit is meant to be a very generous rate that should really only get triggered if something was actually going wrong and causing a significant amount of spam traffic. For a rate limit to be meaningful as applied to the Support Assistant chat completion endpoint, it was going to have to be a much lower limit. It was also important to leave the limit generous enough that we wouldn’t be penalizing enthusiastic users either. In addition to usage data from beta test we did with customers, we’ve had an internally-facing version of the Support Assistant available to our Support Engineers to help streamline their workflows in answering cases. This gave us something to anchor our usage expectation to.
I looked at the previous week's data, and saw that our heaviest internal users had sent 10-20 chat messages per day on average with the top user sending over 70 in a single day. I also had latency metrics to tell me that the average completion time was 20 seconds. Without opening multiple windows or tabs, a single user asking rapid fire questions one after another, would not be able to send more than about 3 chat messages in a minute. Our app sessions expire after an hour, so I decided that it would be best to align our rate limit window with that hour long session window. That means the theoretical max chats for a single user in an hour where they use a single tab is 180 chats in an hour. The team agreed on imposing a limit of 20 chat completions in a one hour window. This is as many chats for our customer users in an hour as our heaviest internal users send in a whole day, while limiting any malicious users to ~11% of that theoretical max based on latency for a full completion.
I then configured an alert looking for HTTP 429 responses on the chat completion endpoint, and there is also a table in the status dashboard listing users that triggered the limit, how many times, and when the most recent example was. I am very happy to report that we have not had anyone hit the limit in these first couple of weeks since launch. The next section discusses an option we gave ourselves for how to react if we did see certain individuals that seemed to be trying to abuse the system.
Ban flags
In rolling out the Support Assistant, we did a limited beta test with some hand-selected customers. To enable the Support Assistant for a subset of users during development, we set up a feature flag system to enable features. As we got closer to the launch we realized that our feature flags needed a couple of upgrades. The first was that we wanted to have the concept of features that were on by default (i.e. already fully launched), and the second was to allow flags to be configured such that they blocked access to a feature. The driving factor behind this one was that we heard some customer organizations might be interested in blocking their employees from engaging with the Support Assistant, but we also recognized that it could also come in handy if we ever reached a conclusion that some particular user was consistently not playing nice, we could cut off the feature while an appropriate Elastic representative tried to reach out and have a conversation.
Context creates large payloads
This last section is part special consideration for a chatbot, and part observability success story. In studying our status dashboard we started seeing HTTP 413 status codes coming back for a small, but non-negligible amount of traffic. That meant we were sending payloads from the browser that were above the configured size that our server would accept. Then one of our developers stumbled upon a reliable chat input that reproduced it so that we could confirm that the issue was the amount of context generated from our RAG search, combined with the user’s input was exceeding the default limits. We increased the size of the payloads accepted by the chat completion endpoint, and ever since we released the fix, we haven’t seen any more transactions with 413 response status.
It’s worth noting that our fix to expand the accepted payload size is really more of a short-term bandage than a long-term solution. The way we plan to solve this problem in a more holistic way is to refactor the way we orchestrate our RAG searches and chat completions such that instead of sending the full content of the RAG results back to the client to include in the completion payload, instead we’d rather only return limited metadata like ID and title for the RAG results to the client, and then include that in the request with the user’s input to the completion endpoint. The completion endpoint would fetch the content of the search results by ID, and combine it with our prompt, and the user’s input to make the request to the LLM service.
Here's a snippet where we configure the Express route for the chat completion endpoint. It touches on the rate limit, flags, and the boosted payload size:
Conclusion
Ideally, observability is more than one thing. It's multi-faceted to provide multiple angles and viewpoints for creating a more complete understanding. It can and should evolve over time to fill gaps or bring deeper understanding.
What I hope you can take away from this blog is a framework for how to get started with observability for your application or feature, how the Elastic stack provides a full platform for achieving those monitoring goals, and a discussion of how this fits into the Support Assistant use case. Engage with this advice, and Bob's your mother's brother, you've got a successful launch!
Related Content

February 18, 2026
Better text analysis for complex languages with Elasticsearch and neural models
Using neural models and the Elasticsearch inference API to improve search in Hebrew, German, Arabic, and other morphologically complex languages.

February 12, 2026
Entity resolution with Elasticsearch & LLMs, Part 1: Preparing for intelligent entity matching
Learn what entity resolution is and how to prepare both sides of the entity resolution equation: your watch list and the articles you want to search.

February 3, 2026
Building automation with Elastic Workflows
A practical introduction to workflow automation in Elastic. Learn what workflows look like, how they work, and how to build one.

February 3, 2026
Skip MLOps: Managed cloud inference for self-managed Elasticsearch with EIS via Cloud Connect
Introducing Elastic Inference Service (EIS) via Cloud Connect, which provides a hybrid architecture for self-managed Elasticsearch users and removes MLOps and CPU hardware barriers for semantic search and RAG.
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.