From vector search to powerful REST APIs, Elasticsearch offers developers the most extensive search toolkit. Dive into our sample notebooks in the Elasticsearch Labs repo to try something new. You can also start your free trial or run Elasticsearch locally today.
This guide explains how to search through documents with multiple kNN fields and how to score the resulting documents based on multiple kNN vector fields. Before diving into the details, let's take a few minutes to introduce kNN and semantic search and explain the mechanics of kNN.
Introduction to kNN search and semantic search
Elasticsearch is more than just a lexical (textual) search engine. Elasticsearch is a scalable data store and vector database that supports k-Nearest Neighbors (kNN) search as well as Semantic Search in addition to the traditional textual matching.
kNN search in Elasticsearch is primarily used for finding the "nearest neighbors" of a given point in a multi-dimensional space. Documents are represented as a set of numbers (vectors) that when searched, the kNN feature fetches relevant documents that are closer to the query vector. The kNN search is commonly applied in scenarios involving vectors, where vectors are created from text, images or audio by employing a process called "embeddings" using deep neural networks.
Semantic search, on the other hand is a search that is powered by natural language processing characteristics - which helps search for relevant results based on intent and meaning rather than just textual match.
kNN mechanics
The kNN (k-nearest neighbors) fetches the search results that are pretty much k-number of nearest documents to the given user's query, measured using an algorithm.
The way it works is by calculating the distance - usually Euclidean or Cosine similarity - between the vectors. When we perform a query a dataset using kNN, Elasticsearch finds the top 'k' entries that are closest to our query vector.
Before performing search related activities on the data to fetch the results, the index must be primed with appropriate embeddings - embedding is a fancy name for vectorized data. The fields are of type dense_vector holding numerical data.Let's take an example:
If you have an image dataset and you've converted these images into vectors using a neural network, you can use kNN search to find images most similar to your query image. If you provide the vector representation of a "pizza" image, kNN can help you find other images that are visually similar, such as pancakes and perhaps pasta :)
kNN search is about finding the nearest data points in a vector space, thus suitable for similarity searches for text or image embeddings. In contrast, Semantic Search is about understanding the meaning and context of words in a search query, making it powerful for text-based searches where intent and context matter.
Scoring documents
Scoring documents based on the closest document when you have multiple k-nearest neighbor (kNN) fields involves leveraging Elasticsearch's ability to handle vector similarity to rank documents. This approach is particularly beneficial in scenarios such as semantic search and recommendation engines. Or cases where we are dealing with multi-dimensional data and need to find the "closest" or most similar items based on multiple aspects (fields).
How to search and score documents with multiple kNN fields
Text embedding and vector fields
Let's take an example of the movies index that consists of a few files such as title, synopsis and others. We will represent them using the common data types, like text data type. In addition to these normal fields, we would create two more fields: title_vector and synopsis_vector field - as the name indicates - they are dense_vector data type fields. That means, the data will be vectorized using a process called "text embedding".
The embedding model is a Natural Language Processing Neural Network, which will convert the inputs to an array of numbers. The vectorized data will then be stored in a dense_vector type field. The data documents can have multiple fields, including a few dense_vector fields to store vector data.
So, in the following section, we'll create the index with a mix of normal and kNN fields.
Creating an Index with kNN Fields
Let's create an index called movies that holds sample movie documents. Our documents will have multiple fields, including a couple of kNN fields to store the vector data. The following snippet demonstrates the index mapping code:
The notable thing is that the title field which is of type text has an equivalent vector type field: title_vector.predicted_value. Similarly the vector field for synopsis is the synopsis_vector.predicted_value field. Also, the dense vector fields have dimention (384) mentioned in the above code as dims. This is to indicate the model will produce 384 dimensions for each of the ingested field. The maximum dimensions we can request to be produced on a dense_vector field is 2048.
Executing this script creates a new index named movies with two vector fields: title_vector and synopsis_vector.
Indexing sample docs
Now that we have an index, we can index some movies and search. In addition to the title and synopsis fields, the document will also have vector fields. Before we index the documents, we need to fill in the document with the respective vectors. The following code demonstrates a movie document sample once the vectors were generated:
As you can see, the vector data needs to be prepared for the document to get ingested. There are a couple of ways you can do this:
- one calling the inference API on the
text_embeddingmodel outside of Elasticsearch to get the data vectorized, as shown above (I've mentioned it here as a reference, though we'd want to go instead using an inference processor pipeline) and - the other is to set up and use the inference pipeline.
Setting up an inference processor
We can set up an ingestion pipeline that would apply the embedding function on the relevant field to produce the vectorized data. For example, the following code creates the movie_embedding_pipeline processor that would generate the embeddings for each field and add them to the document:
The ingesting pipeline may require a bit of explanation:
- Two fields - the
title_vectorandsynopsis_vector- which are mentioned as target fields - are thedense_vectorfield types. Hence, they store vectorized data produced by themultilingual-e5-smallembedding model - The
field_mapmentions the field from the document (titleand thesynopsisfields in this case) gets mapped to atext_fieldfield of the model - The
model_iddeclares the embedding model that was used for embedding the data - The
target_fieldis the name of the field where the vectorized data will be copied to
Executing the above code will create a movie_embedding_pipeline ingest pipeline. That is - a document with just title and synopsis will be enhanced with additional fields (title_vector and synopsis_vector) that will have a vectorized version of the content.
Indexing the documents
The movie document will consist of title and synopsis fields as expected - so we can index it as shown below. Note that the document undergoes enhancement through the pipeline processor as enabled in the url. The following code snippet shows indexing a handful of movies:
We can surely use _bulk API to index the documents in one go - do checkout this Bulk API documentation for futher details.Once these documents were indexed, you can fetch the movies to check if the vectorized contents were added by executing a search query:
This will result in the movies with two additional fields consisting of the vectorized content, as shown in the image below:

Now that we have indexed the documents, let's jump searching through these using the kNN search feature.
kNN search
The k-Nearest Neighbors search in Elasticsearch fetches vectors (documents) that are closest to the given (query) vector. Elasticsearch supports two types of kNN search:
- Approximate kNN search
- Brute Force (or Exact) KNN Search
While both searches produce the results, brute force finds the accurate results at a cost of maximum resource utilization and time to query. Approximate kNN is good enough for the majority of search cases as it offers near accurate results.
Elasticsearch provides knn query for approximate search while we should be using script_score query for exact kNN search.
Approximate search
Let's run an approximate search on the movies as shown below. Elasticsearch provides a kNN query with a query_build_vector block which consists of our query requirements. Let's write the code snippet first and discuss its constituents afterward:
The traditional search queries support the query function, however, Elasticsearch introduced knn search function as a first class citizen to query vectors.
The knn block consists of a field we are searching against - in this instance, it is the title vector - the title_vector.predicted_value field. Remember, this is the name of the field we had mentioned in the mapping earlier.
The query_vector_builder is where we need to provide our query along with the model that we need to use to embed the query. In this case, we set multilingual-e5-small as our model and the text is simply "Good". The query in question will be vectorized by Elasticsearch using the text embedding model (multilingual-e5-small). It then compares the vector query against the available title vectors.
The k value indicates how many documents need to be brought back as a result.
This query should get us the top three documents:
The top movie scored was "The Good, The Bad and the Ugly" when we searched for "Good" against the titles. Do note that kNN search yields results always even if the resultant movies are not a match - the inherent characteristic of a kNN match.
Take note of the relevancy score (_score) for each of the documents - as expected the documents are sorted based on this score.
Searching with multiple kNN fields
We have two vector fields - the title_vector and synopsis_vector fields in the movie document - we can surely search against these two fields and expect the resultant documents based on the combined scores.
Let's just say we want to search for "Good" in the title but "orders" in the synopsis field. Remember from the previous single title-field search using "Good", we retrieved the "The Good, The Bad and the Ugly" movie. Let's see which movie will be fetched given the "orders" part of the synopsis as our search.
The following code declares our multi-kNN field search:
As you can imagine, the knn query can accept multiple search fields as an array - here we provided search criteria from both fields. The answer is "A Few Good Men" as the synopsis vector that consists the "order" vector was this movie.
When to search with multi-kNN fields
There are a few instances where we can be searching using multiple kNN fields:
- Searching for "tweets" based on image similarity (visual kNN field) and a tweet similarity (text kNN field).
- Recommend similar songs based on both audio features (audio as the kNN field) like tempo and rhythm; And probably title/artist/genre information (text kNN field).
- Recommend movies or products based on the user's behavior (kNN field for user interactions) and movie/product attributes (kNN field based on these attributes).
Conclusion
That's a wrap. In this article, we looked at the mechanics of kNN search and how we can find the closest document when we have multiple vectorized fields.
Related Content
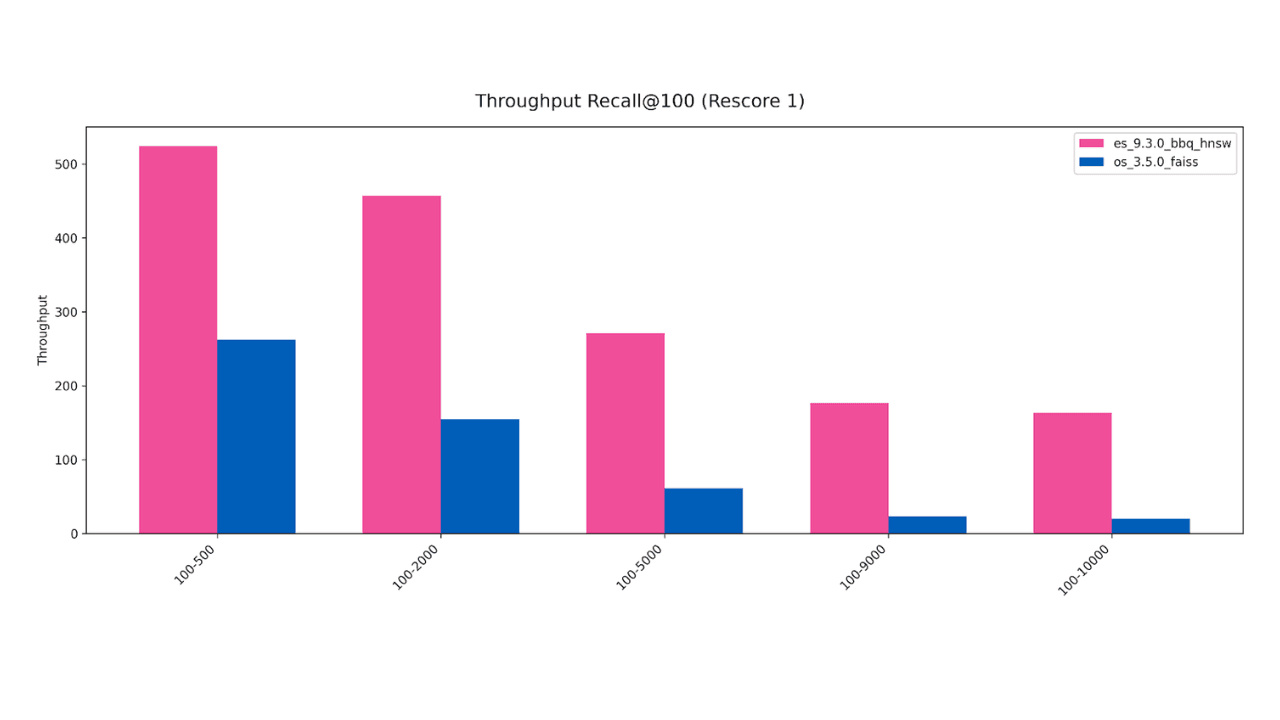
February 25, 2026
Elasticsearch vector search is up to 8x faster than OpenSearch
Exploring filtered vector search benchmarks of OpenSearch vs. Elasticsearch and why vector search performance is critical for context-engineered systems.

February 16, 2026
Elasticsearch 9.3 adds bfloat16 vector support
Exploring the new Elasticsearch element_type: bfloat16, which can halve your vector data storage.

February 10, 2026
How to defend your RAG system from context poisoning
How context engineering techniques prevent context poisoning in LLM responses.
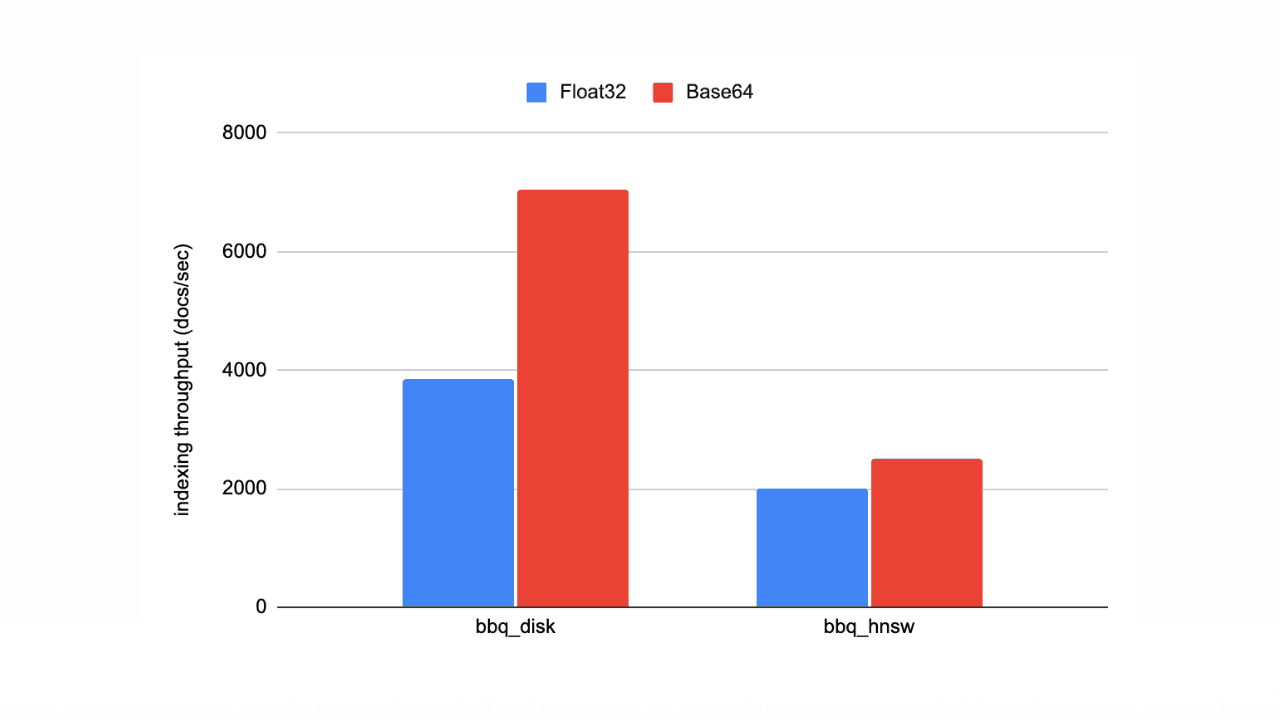
February 4, 2026
Speed up vector ingestion using Base64-encoded strings
Introducing Base64-encoded strings to speed up vector ingestion in Elasticsearch.

February 5, 2026
ES|QL dense vector search support
Using ES|QL for vector search on your dense_vector data.