Elasticsearch 7.6.0 released
We are pleased to announce the release of Elasticsearch 7.6.0, based on Lucene 8.4.0. Version 7.6 is the latest stable release of Elasticsearch, and is now available for download or deployment via Elasticsearch Service on Elastic Cloud.
Elasticsearch 7.6 packs a punch and we’re excited to share the big news with you: Elasticsearch 7.6 is faster than ever before. We’ve also made some enhancements to cluster management and administration that should make for less stress and more high fives. And, what would an Elasticsearch release be without a few new features and a whole lot of machine learning love?
If you're ready to roll up your sleeves and get started right off the bat, we have the links you need:
- Start Elasticsearch on Elastic Cloud
- Download Elasticsearch
- Elasticsearch 7.6.0 release notes
- Elasticsearch 7.6.0 breaking changes
Elasticsearch and Kibana are the workhorses behind our Enterprise Search, Observability, and Security solutions. To this end, all of the new features and enhancements you read about here will immediately be available for use within each of them. In addition, with today’s release, all three of our primary solution areas received some significant updates of their own. To learn more about these updates you might consider giving our other release blogs a read.
Performance optimizations
Sort dates and numbers faster than ever before
We have significantly improved the performance of queries that sort by dates, or numbers (read: anything that is stored as a signed 64-bit integer or 'long'). Performance is influenced by many parameters, but just to give a representative benchmark, our standard nightly performance test for which this improvement applies showed an improvement of between several times faster to 35(!) times faster for certain tests. Your mileage may vary, but expect it to be really good.
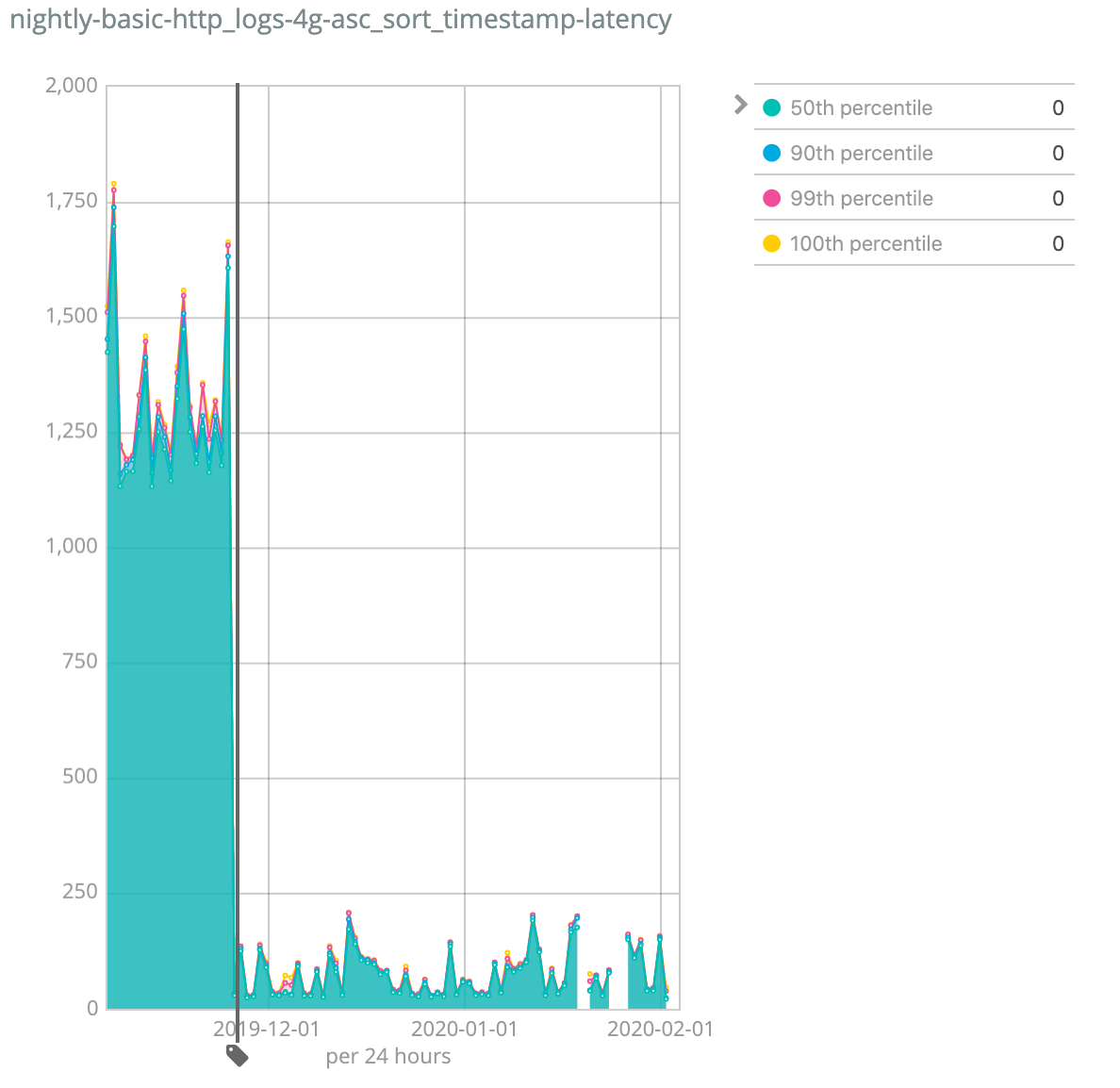
One of our nightly benchmarks — can you guess when we merged this optimization?
Those of you that follow our blogs and releases may recall the Block-Max WAND development. This started as an idea from the Elastic community and resulted in contributions to both Lucene and Elasticsearch. The core concept — which we introduced with the release of Elasticsearch 7.0 for relevance ranking — is that the algorithm skips non-competitive documents.
With the release of Elasticsearch 7.6, we have now introduced the same algorithm for sorting by dates and numbers. A lot of the larger Elasticsearch clusters contain machine generated data, and frequently these use cases rely on sorting documents by dates, so the impact of such improvements in the real world is immense, not only on the performance end users experience, but also, potentially, on hardware requirements. It’s a great reason to use the latest and greatest Elasticsearch release!
We plan to continue to introduce performance improvements based on this algorithm to address additional use cases (e.g., queries in which ‘search_after’ is used). One particularly interesting use case that we plan to improve in a future release is when there are many shards and each shard contains documents from different date ranges. This scenario will enable us to skip searching shards that do not contain competitive documents.
The enhancement to sort on long is being released under the Apache 2.0 license.
Faster composite aggregations on sorted indices
Sorting indices can have many benefits. Not only can it save space paired with compression, but keeping an index sorted helps to improve the performance of queries.
With the release of Elasticsearch 7.6, you now have one more reason to sort those indices. In situations where a given index is sorted and a composite aggregation is performed on the sorted field, it is now possible to terminate the aggregation early when it becomes clear that there are no additional competitive candidates. And, as with the aforementioned performance optimization, users of the composite aggregation on sorted indices will thus enjoy a significant improvement in performance simply by updating their cluster to the latest release.
The enhancement to composite aggregations is being released under the Apache 2.0 license.
Geospatial performance optimizations
When we released Elasticsearch 7.4, we noted how previous investments in infrastructure for geospatial data — namely, the introduction of BKD trees — allowed us to introduce bkd-backed geopoints in Elasticsearch. Once again we are building upon this foundation to improve performance.
With the release of Elasticsearch 7.6, the geo_shape query has been enhanced to use a BKD tree (instead of a quadtree) when finding shapes that are contained by (other) shapes (as defined via a given query). As BKD trees are superior to quadtrees by just about any relevant measurement, indices can be smaller and queries will be faster.
And while we’re covering geospatial news, it’s worth noting that we have included some optimizations to improve the performance of the GeoTile Grid aggregation.
Both the enhancement to geo_shape query and GeoTile Grid aggregation are being released under the Apache 2.0 license.
Simplifying and operationalizing machine learning
With the release of 7.6 the Elastic Stack delivers an end-to-end machine learning pipeline providing the path from raw data to building, testing, and deploying machine learning models in production. Up to this point machine learning in the Elastic Stack had primarily focused on unsupervised techniques by using sophisticated pattern recognition that builds time series models used for anomaly detection. With the new data frame analytics in Elastic’s machine learning you can now use labelled data to train and test your own models, store those models as Elasticsearch indices, and use inference to add predicted values to the indices based on your trained models.
Several machine learning features released in the 7.x branch have been building up to this release. In 7.2 Elasticsearch released the ability to transform raw indices into a feature index to use for building a model around. Then 7.3 released outlier detection, 7.4 brought regression, and 7.5 included classification for building machine learning models. Finally with the release of 7.6 you can use those models with the new inference processor to add fields to documents during ingest. All these features together close the loop for an end-to-end machine learning pipeline within Elasticsearch.
There are many reasons you would want to create your own trained machine learning models. If you would like to supply recommendations for your customers based on what other customers have done historically in your application you can use classification and provide a recommended path. Prediction models can be built for price predictions, capacity planning, fraud detection, and many more uses.
One packaged model that we are releasing in 7.6 is language identification. If you have documents or sources that come in a variety of languages, language identification can be used to determine the language of text so you can improve the overall search relevance. Language identification is a trained model that can provide a prediction of the language of any text field. Language identification is available with our free Basic tier (or higher).
Finally, transforms can now use cross-cluster search (CCS) for the source index. Now you can have separate clusters (e.g., project clusters) build entity-centric or feature indices against a primary cluster. Both Elasticsearch transforms and CCS functionality are available in the free Basic tier (or higher).
Enhanced cluster management & administration
Better together: index & snapshot lifecycle management
Many Elasticsearch users have requested improved integration between index lifecycle management (ILM) and snapshot lifecycle management (SLM).
Specifically, users were seeking to remove the guesswork involved with deleting an index, as ILM was not aware of any SLM errors or if a given snapshot was fully processed. Before today, the typical “workflow” was to manually ensure that a snapshot was able to fully process before deleting.
Good news: the wait is over. With the release of Elasticsearch 7.6, ILM users now have the ability to utilize a `wait_for_snapshot` action. This action tells ILM to wait for the named policy to finish taking a snapshot before deleting an index. We’re guessing that many of our ILM users will rest easier tonight knowing that their indices are safe and sound with SLM.
This enhancement to ILM is being released under Elastic’s free Basic tier.
Snapshots are now more efficient and faster to restore
With Elasticsearch 7.6, we've made major improvements to how snapshot metadata is stored within a snapshot repository to reduce API requests. Elasticsearch now uses cluster state to store pointers for valid snapshot metadata — saving on cloud provider requests and improving resiliency.
We've also made snapshot restores faster by parallelizing restore operations for each shard.
These enhancements to snapshot and restore are being released under the Apache 2.0 license.
TLS made simple
Ever since the release of Elasticsearch 6.8, we’ve included a rich set of Elastic Stack security features for free. This means that anyone using our default distribution can configure security for their Elasticsearch cluster to keep their data safe.
Part of configuring security involves establishing secure communications between a cluster’s various nodes with TLS. Piggybacking on work that started with the release of Elasticsearch 7.4 (work to make TLS errors more human readable), Elasticsearch 7.6 adds improved diagnostics for TLS trust failures to help make logs friendlier to read. No more scrolling through pages of errors — these new messages are straightforward and “to the point.”
In addition to making TLS errors easier to diagnose (and solve for) we’ve added a new ‘http’ flag to the elasticsearch-certutil command-line certificate utility. When set, this flag makes TLS certificate creation easy by walking users through the creation of certificates for secure client communications. Users can use the certificate utility to create a signing request, change the details of the certification authority, and get configuration options (that can be copied and pasted into Elasticsearch and Kibana configuration files).
These enhancements to cluster security configuration are being released under Elastic’s free Basic tier.
Proxy mode for cross-cluster replication and cross-cluster search
Cross-cluster replication (CCR) allows indices to be replicated from one Elasticsearch cluster to another — enabling use cases such as cross datacenter replication and bi-directional replication architectures. Cross-cluster search (CCS) allows multiple Elasticsearch clusters to be searched from a single endpoint. Both of these features relied on sniffing nodes within a remote cluster and creating connections directly to the applicable nodes.
With Elasticsearch 7.6, a proxy can now be used between clusters for both CCR and CCS. This means fewer ports need to be opened between Elasticsearch clusters when a proxy is used for managing all connections between the clusters. This simplifies the setup for IT professionals and helps keep your security team happy.
Proxy mode for CCR and CCS is being released under the Apache 2.0 license.
New capabilities
We’re always looking for new ways to help our users build and maintain search-powered solutions. With Elasticsearch 7.6, we’ve made some improvements to how users are able to create and edit index templates in Kibana, added a new (more efficient) field type, introduced a handy new metrics aggregation, and promoted our vector field type and vector distance functions to general availability.
Creating index template mappings is easier than ever
Managing index templates is an important part of index health. This requires users to configure index settings, mappings, and index patterns. Mapping, in many cases, is the most complex part of this process. To make this process more straightforward and easy for our users, we are introducing a visual mapping editor for index templates in Elasticsearch 7.6.
This new editor makes creating and editing index template mappings easier and more visual. Previously, users only had a JSON editor available to them for setting up index template mappings within the UI. Now it’s easy to see what field data types (and related parameters) are available and users are provided with a search box for quick and easy search of field types or names.
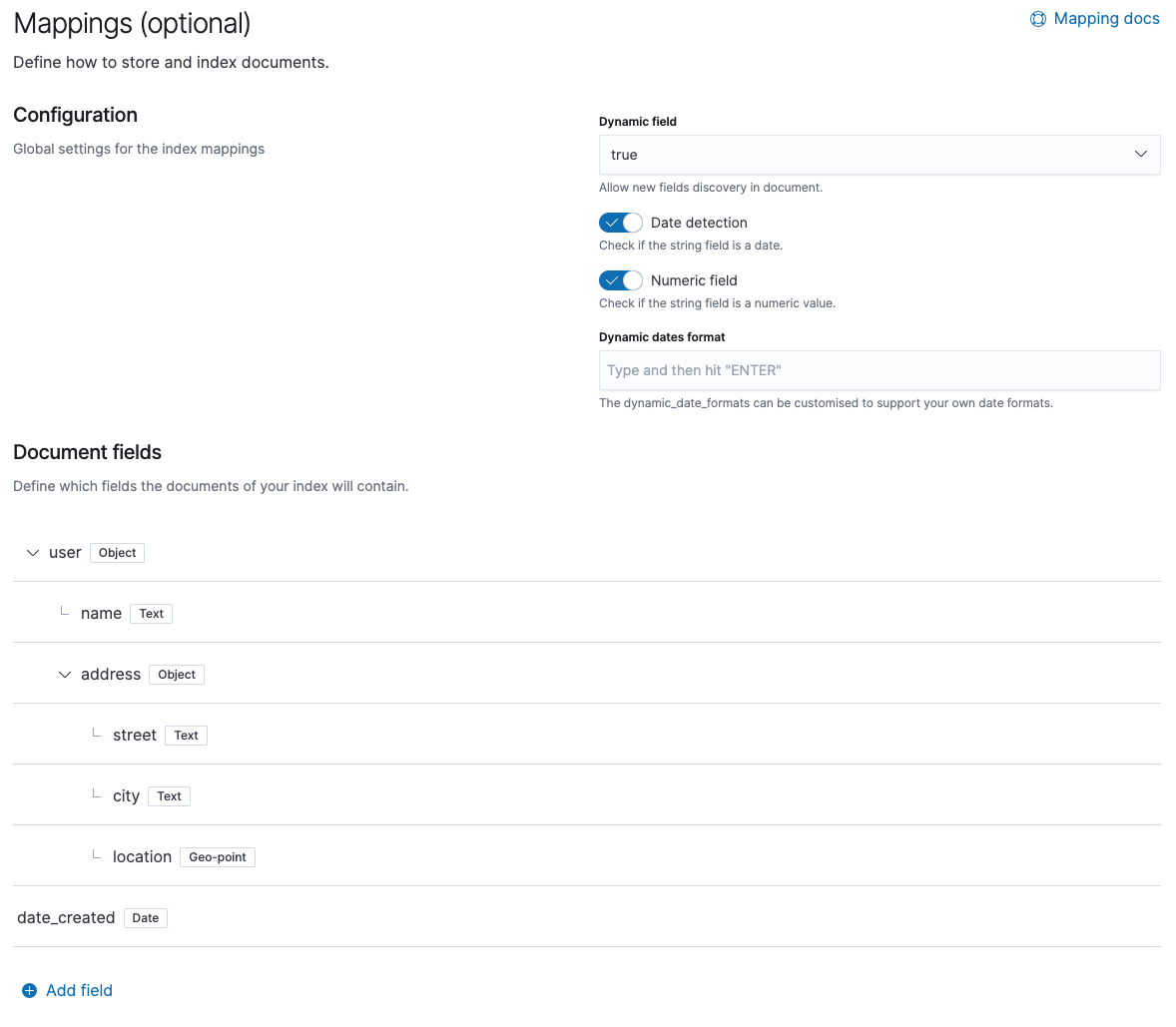
Index templates have been around for a long time and help users add and configure new indices quickly and easily. Now users can set up mapping for their index templates in a visually guided way.
This enhancement to the index template mappings editor is being released under Elastic’s free Basic tier.
New histogram data type
Users can often be faced with such high data throughput that the best way to handle it is to aggregate the useful information where it is produced. This can save valuable space while still getting the most from your data. This means the whole infrastructure — network, indexing, etc. — is not burdened with a very large number of documents, and instead deals with a statistical representation of each subset of documents. In addition, this method means the Elasticsearch index is smaller, which is beneficial in itself.
Such bucketing is frequently made per time interval. While this strategy can be very economical when used for high data volume use cases, there is, of course, a tradeoff. If it is too coarse-grained, you lose on accuracy. If it is too fine-grained, you end up with a lot of (read: too much) data. Because pre-aggregation is used in high-volume scenarios, it is vital that Elasticsearch will handle the pre-aggregated data efficiently.
To facilitate such scenarios, Elasticsearch 7.6 introduces the new histogram data type as a more efficient way to handle data that can be represented in a histogram. Not only does this new data type consume less space (as compared to the raw data stored previously) — the histogram data type can be processed more efficiently by aggregations.
The histogram data type is being released under Elastic’s free Basic tier.
New string stats aggregation
Certain sophisticated use cases rely on a statistical analysis of the strings in the documents. To this end, Elasticsearch 7.6 introduces the string stats aggregation, which calculates the count, Shannon entropy, and the minimum/maximum and average length of the strings. There are many fields in which such information is vital (e.g., machine learning and security).
A concrete example within the security realm, for which Shannon entropy is instrumental, is identification of DNS tunneling, a tactic used by adversaries for data exfiltration and command and control communications. When malware tries to ‘smuggle’ information out of a network, it often uses a variety of randomly generated domain names or subdomain strings. In contrast, the domain names that humans create tend to be constructed of words (i.e., they tend to fall into patterns). This distinction allows security software to identify suspected DNS tunneling by monitoring the extent to which the domain names and subdomain strings represent random use of the alphabet or use of a (relatively) small number of words. An effective statistical indicator for that is Shannon entropy of the strings.
The string stats aggregation is being released under Elastic’s free Basic tier.
Vector distance functions are now generally available
High-dimensional vector similarity is increasingly used for relevance ranking. Image search and natural language processing are probably the two areas that benefit the most from use of high-dimensional vectors. We dedicated a separate blog to text similarity search with vector fields in Elasticsearch, and judging by its popularity, it is safe to say many users are considering using vectors for relevance ranking.
Our support for using vectors to improve the relevance of search results has been steadily building over the last 12 months. In Elasticsearch 7.0, we introduced experimental field types for high-dimensional vectors. With the release of Elasticsearch 7.3, we added two predefined functions (cosine similarity and dot product similarity) for use when calculating vector similarity between a given query vector and document vectors. Elasticsearch 7.4 introduced an additional two vector similarity measurements — namely, Manhattan distance and Euclidean distance.
The big news today: with the release of Elasticsearch 7.6, we’re promoting all dense vector similarity functions from experimental to generally available. They’re ready for prime time and we look forward to seeing how our users put them to work.
That’s not all, folks!
While the above listed features might have taken the spotlight, there were many more features included with the release of Elasticsearch 7.6. Be sure to check out the release highlights and the release notes for additional information.
Ready to get your hands dirty? Spin up an Elasticsearch cluster on Elastic Cloud or download Elasticsearch today. Try it out. And be sure to let us know what you think on Twitter (@elastic) or in our forum. You can report any problems on the GitHub issues page.