Introducing Index Sorting in Elasticsearch 6.0
In Elasticsearch 6.0 we’re introducing a new feature called Index Sorting. Users can now optimize Elasticsearch indexes to store documents on disk in a specific order. We’re very excited for Index Sorting, as it’s another useful tool in optimizing Elasticsearch performance!
Through this article, we’ll dive into a number of areas:
- Lucene’s Index Sorting functionality
- Examples where Index Sorting will improve query performance
- Caveats to consider in using Index Sorting for time series data
- Performance considerations
Index Sorting in Lucene
Lucene’s IndexSorter
Many years ago, Lucene introduced an offline tool known as the IndexSorter. The IndexSorter copied a source index to a new destination index, and ordered the documents on disk based on a user specified order. At that time, because it was not possible to update the destination index directly, users of this feature had to re-build a sorted view every time new documents were added to the source index. The IndexSorter was the first attempt to provide a way to sort documents on disk, not at search time, but at index time.
With index sorting, a new concept called “early termination” was introduced. Suppose for instance that you want to retrieve N documents sorted by date (date being a field in the index). If the index is sorted on disk by this date field it would be possible to “stop” the request after visiting the first N documents that match the query (since they are already in the order the user specified). This is what we call “early termination”. Early termination of a query can bring significant improvement to search response times, especially for sort-based queries, and led to the increased popularity of the IndexSorter tool among Lucene users. The static nature of the tool prevented its usage for indices with a lot of updates, which is why it was eventually replaced with a solution that allows incremental updates. Instead of doing a one-time sort of a static index, a new solution was proposed to sort documents at merge time.
Lucene improvements
Originally, Lucene indexed documents in the order they were received, and assigned each document an incremental (and internal) document id (assigned on a per segment basis). The first document indexed in a segment had a document id of 0, and so on. At search time, each segment is visited in document id order, to retrieve documents that match a user query. In order to retrieve the best N documents for a query, Lucene needs to visit every document matching the query across all segments. If the query matches millions of documents, retrieving only the best N would still require millions of documents to be visited.
A Lucene index creates a new segment whenever a refresh is triggered. This new segment contains all the documents that were added after the last refresh. When the segment is flushed it becomes visible to the searcher and new documents can appear in search results. Because refreshes occur constantly, the number of segments can easily explode in an index. Segment merges happen in the background to limit the number of segments from growing too large. Merges are triggered based on a policy that selects segments eligible for merging, the selected segments are then merged in a new segment that replaces the old segments. By default, the segment merge process copies documents from different segments to a new segment based on their internal document ids. In order to replace the static tool (the IndexSorter mentioned above), a new merge policy was introduced to allow index sorting for dynamic indices that reorders documents during the merge process based on a configurable order (the value of a field for instance). This new design was a huge step in the right direction, and allowed an index to be sorted on the fly and to use this information on a per-segment basis. Some segments are sorted (segments created by a merge) and some are not (the newly flushed segments). At merge time, the unsorted segments are first “sorted” and then merged with other sorted segments.
This merge policy that lived in a module was then moved to a top-level option on the IndexWriterConfig to make index sorting a first class citizen in Lucene.
Though some benchmarks showed that the cost of sorting at merge time can divide the total throughput of indexation by a factor of 2:
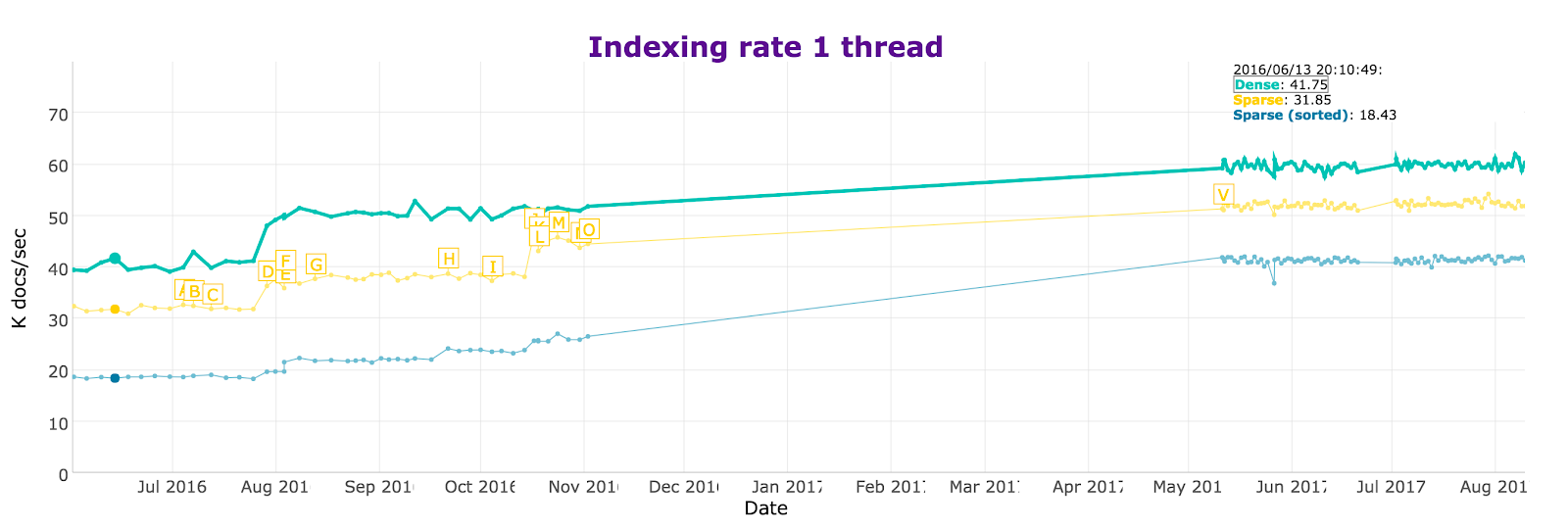
https://home.apache.org/~mikemccand/lucenebench/sp...
The reason for the reduction in indexing performance is simple: re-sorting segments has a cost, causing merge time and memory consumption for these indices to increase by a large factor.
Since re-sorting multiple segments at a time is costly, we decided to sort documents earlier in the indexation process. Instead of waiting for merge times to sort multiple segments, we’ve moved the sorting to flush time (when the segments are first created): LUCENE-7579. If all segments are already sorted, merging can occur using a simple merge-sort strategy, which is much faster. This new strategy was first introduced in Lucene 6.5 and increased the throughput benchmarks by almost 65% (see annotation V).
As you can see in this story index sorting had a lot of history in Lucene but until now it was not available in Elasticsearch. Thanks to all these optimizations, we’ve decided to unlock this feature in Elasticsearch 6.0 and we’re really excited to show how this feature can help you to optimize your use case with this new release!
Index Sorting in Action
Early termination of search queries
It’s very common in applications to query for the top X results, sorted by value Y (top player scores, new users, latest events, etc.). In most cases, Elasticsearch will not have enough information to quickly gather the first X results and sort them until the entire data set has been examined. Doc values make this process more efficient, however, in the cases where the dataset is extremely large, a lot more values will be examined and compared than are needed by the user.
With the introduction of index sorting in Elasticsearch 6.0, we can now specify the ordering of documents on disk, allowing Elasticsearch to short circuit and return queries more efficiently. For instance, if we’re creating a leaderboard for a video game company to track the top 3 player scores (and we have a very large number of players!), we can instruct Elasticsearch to store documents in the order of their player score, allowing us to compute the leaderboard much more efficiently.

// Get the top 3 player scores (based on the number of points)
GET scores/score/_search
{
"size": 3,
"sort": [
{ "points": "desc" }
]
}
Depending on the version of Elasticsearch, and on usage of index sorting, we can store the documents on disk very efficiently for the query above:
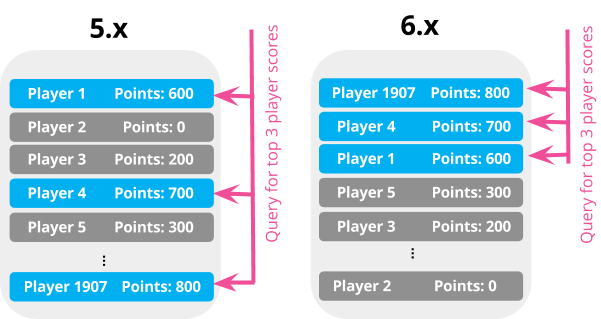
The query above will still need to return a count for the number of results (and requires a little extra work). We can remove this requirement with the new option "track_total_hits" set to false:
// Get the top 3 player scores (based on the number of points)
GET scores/score/_search
{
"size": 3,
"track_total_hits" : false,
"sort": [
{ "points": "desc" }
]
}
We now have a very efficient leaderboard query for top player scores, using a sorted index.
Specifying an index sorting order in Elasticsearch 6.0
To continue with our example above (creating a leaderboard of top player scores), we will need to tell Elasticsearch how to order the documents on disk. We can do this by providing a definition in the settings for the index:
PUT scores
{
"settings" : {
"index" : {
"sort.field" : "points",
"sort.order" : "desc"
}
},
"mappings": {
"score": {
"properties": {
"points": {
"type": "long"
},
"playerid": {
"type": "keyword"
},
"game" : {
"type" : "keyword"
}
}
}
}
}
The example above will sort documents on disk by the points field (in descending order). This is helpful for the simple query above (for top 3 player scores).
Grouping documents within an index by similar structure
There are many advantages to storing documents sorted by a similar type. For instance, if there is an index named “scores”, some scores may come from the game “Joust”, and include specific fields such as “top-speed” and “farthest-jump”, a score for a different game, such as “Dragon’s Lair” may include fields for “sword-fight-score” and “goblins-killed”:
// Score for the game "Joust"
{
"game" : "joust",
"playerid" : "1234",
"top-speed" : 212,
"farthest-jump" : 49
}
// Score for the game "Dragon’s Lair"
{
"game" : "dragons-lair",
"playerid" : "5678",
"sword-fight-score" : 89,
"goblins-killed" : 3
}
Storing the documents on disk sorted by game will help place similar documents (with similar field names) together. The advantages to this are query speed (although it’s important to remember this really depends on the query) and compression. Storing similar fields closer together may lead to better compression, and Elasticsearch (and in turn Lucene) is able to store the deltas more efficiently:
PUT scores
{
"settings" : {
"index" : {
"sort.field" : "game",
"sort.order" : "desc"
}
}
}
More efficient AND conjunctions
Using index sorting to locate documents on disk in a specific order can also improve AND conjunctions, complex queries with many conditions.
Let’s continue with our video game example, when a player joins a game, they must be paired up with another player in the same region, skill level, and course. A sample query to find similar players for starting a new match may look similar to the following (get 10 players within the "EU" region, playing "Dragon’s Lair", with a skill rating of 9, and at the "Castle" map):
GET players/player/_search
{
"size": 3,
"track_total_hits" : false,
"query" : {
"bool" : {
"filter" : [
{ "term" : { "region" : "eu" } },
{ "term" : { "game" : "dragons-lair" } },
{ "term" : { "skill-rating" : 9 } },
{ "term" : { "map" : "castle" } }
]
}
}
}
Let's look at how the Elasticsearch may gather the results needed for the query:

Now, let's specify the ordering of the documents on disk to improve our query above:
PUT players
{
"settings" : {
"index" : {
"sort.field" : ["region", "game", "skill-rating", "map"],
"sort.order" : ["asc", "asc", "asc", "asc"]
}
},
"mappings": {
"player": {
"properties": {
"playerid": {
"type": "keyword"
},
"region": {
"type": "keyword"
},
"skill-rating" : {
"type" : "integer"
},
"game" : {
"type" : "keyword"
},
"map" : {
"type" : "keyword"
}
}
}
}
}
We can now see the documents are placed closer together:
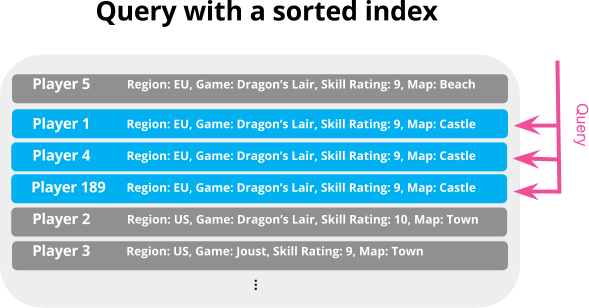
By using a sorted index, we can locate the documents with similar field values closer together, making our query to find players for a given match more efficient.
When index sorting isn't a good fit
Storing sorted values on disk requires a lot more work at index time from Elasticsearch than storing unsorted values. In some cases the performance overhead of index sorting can decrease write performance by as much as 40-50%. For this reason it is very important to determine if the application should be optimized for query performance or write performance. Optimizing an application for write performance (and taking the hit on query performance) will most likely mean index sorting is not a good option.
You can check the throughput for indexation with and without index sorting. As mentioned above, the performance hit will vary widely and depend on your use case. For example, the geonames Elasticsearch benchmark shows a very small performance hit for Index Sorting (the blue line labeled “Append Sorted”):
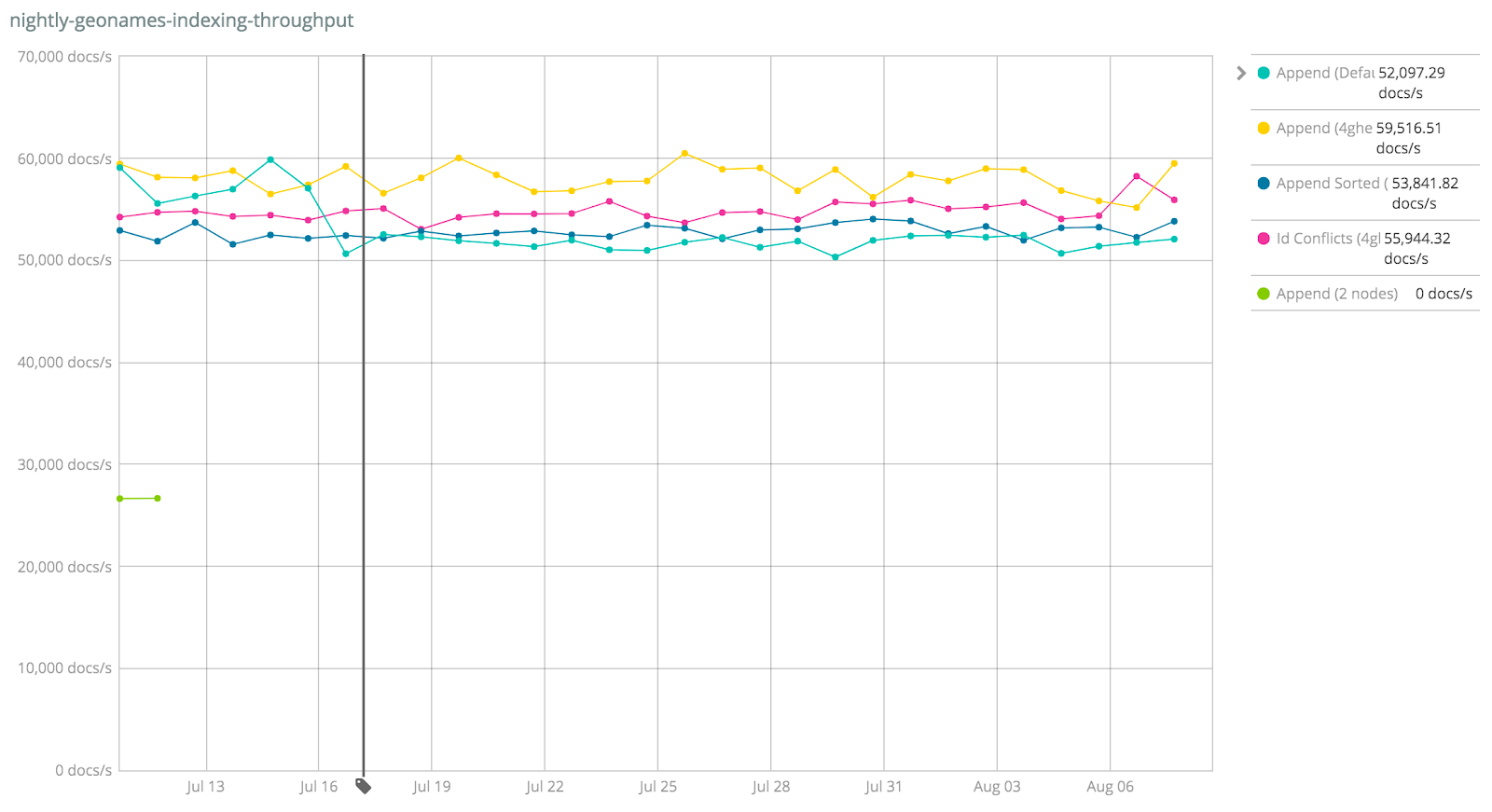
https://elasticsearch-benchmarks.elastic.co/index....
Alternatively, the “NYC Taxis” benchmark shows a large drop in indexing performance with index sorting:
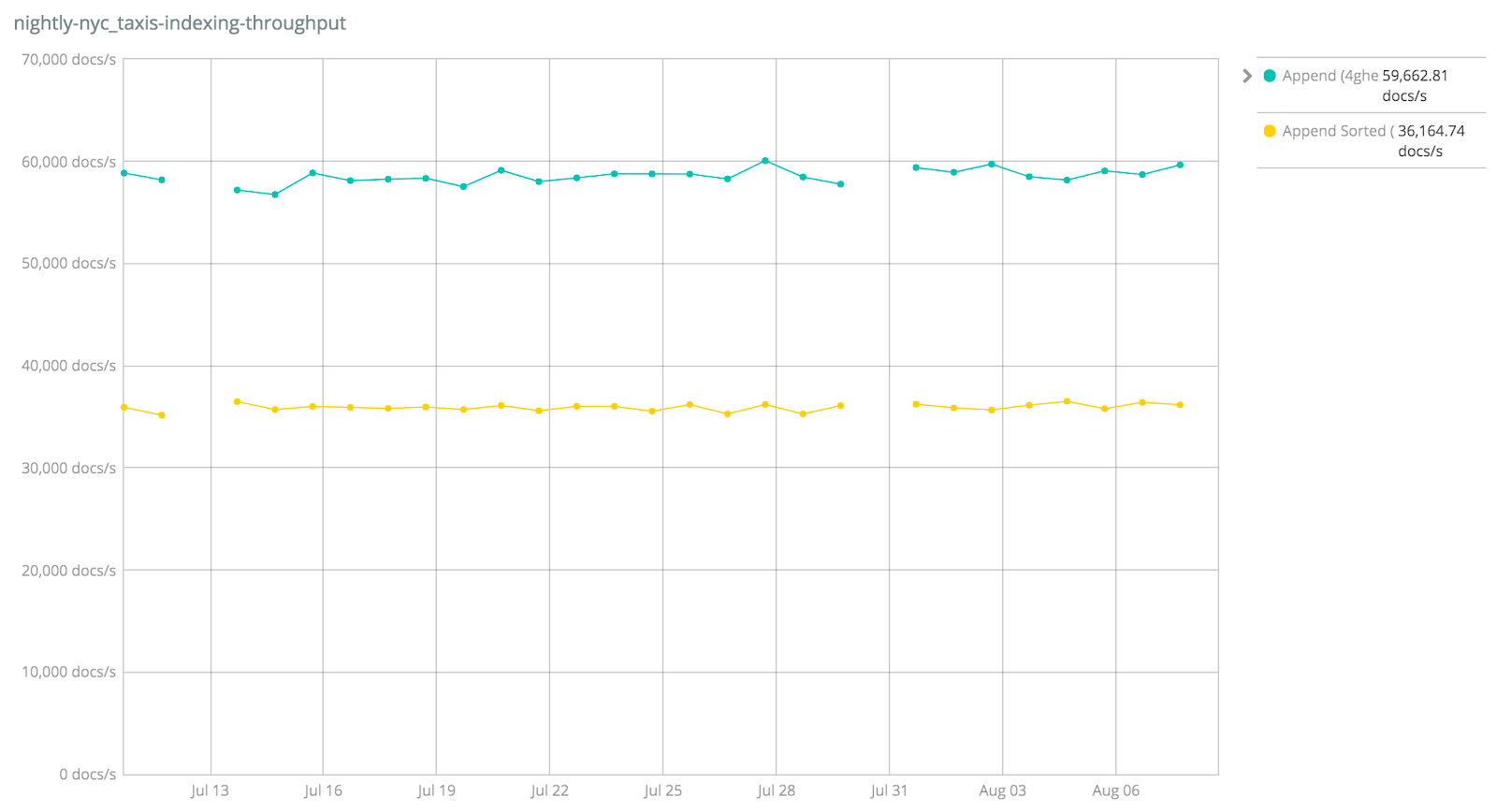
https://elasticsearch-benchmarks.elastic.co/index....
In system design, there are tradeoffs at almost every level, with index sorting, the tradeoff we’re considering is less efficient writes (as the document must be sorted) for faster queries (in specific scenarios) vs more efficient writes and slower queries (as the results must be sorted at query time).
Similar to any new feature, it is very important to test index sorting with your specific use case and dataset.
We’re not finished
This is only the beginning, we’ll continue to improve index sorting for a larger range of use cases!
Hopefully this article gives you a good overview of index sorting as a great new tool to consider in your Elasticsearch 6.0 toolbox. In addition to this blog post, the documentation on Index Sorting can be a great resource to bookmark. If you want to try out the new index sorting functionality, download 6.0.0-beta1 and become a pioneer!