Accessing machine learning models in Elastic


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by email

 Print this page
Print this pagePrint
Elastic supports the machine learning models you need
Elastic® lets you apply the machine learning (ML) that’s appropriate for your use case and level of ML expertise. You have multiple options:
- Leverage the models that come built-in. Aside from models targeting specific security threats and types of system issues in our observability and security solution, you can use our proprietary Elastic Learned Sparse Encoder model out of the box, as well as a language identification — useful if you’re working with non-English text data.
- Access third-party PyTorch models from anywhere including the HuggingFace model hub.
- Load a model you trained yourself — primarily NLP transformers at this point.
Using built-in models gets you value out of the box, without requiring any ML expertise from you, yet you have the flexibility to try out different models and determine what performs best on your data
We designed our model management to be scalable across multiple nodes in a cluster, while also ensuring good inference performance for both high throughput and low latency workloads. That’s in part by empowering ingest pipelines to run inference and by using dedicated nodes for the computationally demanding model inference — during the ingestion phase, as well as data analysis and search.
Read on to learn more about the Eland library that lets you load models into Elastic and how that plays out for the various types of machine learning you might use within Elasticsearch® — from the latest transformer and natural language processing (NLP) models to boosted tree models for regression.
Eland lets you load ML models into Elastic
Our Eland library provides an easy interface to load ML models into Elasticsearch — provided they were trained using PyTorch. Using the native library libtorch, and expecting models that have been exported or saved as a TorchScript representation, Elasticsearch avoids running a Python interpreter while performing model inference.
By integrating with one of the most popular formats for building NLP models in PyTorch, Elasticsearch can provide a platform that works with a large variety of NLP tasks and use cases. We'll get more into that in the section on transformers that follows.
You have three options for using Eland to upload a model: command-line, Docker, and from within your own Python code. Docker is less complex because it does not require a local installation of Eland and all of its dependencies. Once you have access to Eland, the code sample below shows how to upload a DistilBERT NER model, as an example:

Further below we'll walk through each of the arguments of eland_import_hub_model. And you can issue the same command from a Docker container.
Once uploaded, Kibana's ML Model Management user interface lets you manage the models on an Elasticsearch cluster, including increasing allocations for additional throughput, and stop/resume models while (re)configuring your system.
Which models are supported?
Elastic supports a variety of transformer models, as well as the most popular supervised learning libraries:
- NLP and embedding models: All transformers that conform to the standard BERT model interface and use the WordPiece tokenization algorithm. View a complete list of supported model architectures.
- Supervised learning: Trained models from scikit-learn, XGBoost, and LightGBM libraries to be serialized and used as an inference model in Elasticsearch. Our documentation provides an example for training an XGBoost classify on data in Elastic. You can also export and import supervised models trained in Elastic with our data frame analytics.
- Generative AI: You can use the API provided for the LLM to pass queries — potentially enriched with context retrieved from Elastic — and process the results returned. For further instructions, refer to this blog, which links to a GitHub repository with example code for communicating via ChatGPT's API.
Below we provide more information for the type of model you're most likely to use in the context of search applications: NLP transformers.
How to apply transformers and NLP in Elastic, with ease!
Let us walk you through the steps to load and use an NLP model, for example a popular NER model from Hugging Face, going over the arguments identified in below code snippet.

- Specify the Elastic Cloud identifier. Alternatively, use --url.
- Provide authentication details to access your cluster. You can look up available authentication methods.
- Specify the identifier for the model in the Hugging Face model hub.
- Specify the type of NLP task. Supported values are fill_mask, ner, text_classification, text_embedding, and zero_shot_classification.
Once you've loaded the model, next you need to deploy it. You accomplish this on the Model Management screen of the Machine Learning tab in Kibana. Then you'd typically test the model to ensure it's working properly.
Now you're ready to use the deployed model for inference. For example to extract named entities, you call the _infer endpoint on the loaded NER model:
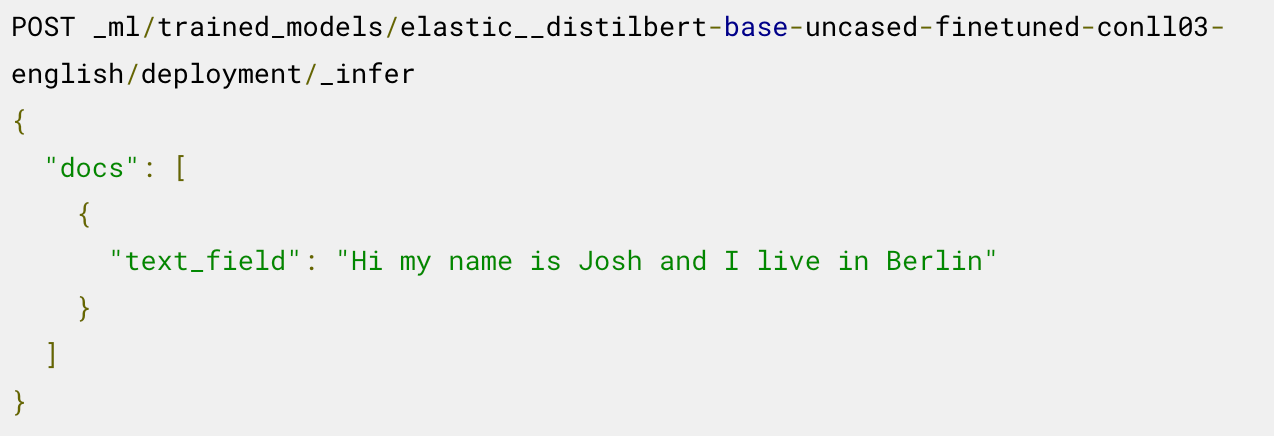
The model identifies two entities: the person "Josh" and the location "Berlin."

For additional steps, like using this model in an inference pipeline and tuning the deployment, read the blog that describes this example.
Want to see how to apply semantic search — for example, how to create embeddings for text and then apply vector search to find related documents? This blog lays that out step-by-step, including validating model performance.
Don't know which type of task for which model? This table should help you get started.
Hugging Face Model | task-type |
|---|---|
ner | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| Question answering | question_answering |
Elastic also supports comparing how similar two pieces of text are to each other as text_similarity task-type — this is useful for ranking document text when comparing it to another provided text input, and it's sometimes referred to as cross-encoding.
Check these resources for more details
- Support for PyTorch transformers, including design considerations for Eland
- Steps for loading transformers into Elastic and using them in inference
- Blog describing how to query your proprietary data using ChatGPT
- Adapt a pre trained transformer to a text classification task, and load the custom model into Elastic
- Built-in language identification that lets you identify non-English text before passing into models that support only English
Elastic, Elasticsearch and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by email
- Print this page
Print

