

What are word embeddings?
Word embedding definition
Word embedding is a technique used in natural language processing (NLP) that represents words as numbers so that a computer can work with them. It is a popular approach for learned numeric representations of text.
Because machines need assistance with how to deal with words, each word needs to be assigned a number format so it can be processed. This can be done via a few different approaches:
- One-hot encoding gives each word in a body of text a unique number. This number is turned into a binary vector (using 0s and 1s) that represents the word.
- Count-based representation counts the number of times a word appears in a body of text and assigns a corresponding vector to it.
- SLIM combination utilizes both these methods so that a computer can understand both the meaning of the words and how often they appear in the text.
Word embedding creates a high-dimensional space where each word is assigned a dense vector (more on this below) of numbers. A computer can then use these vectors to understand the relationships between words and make predictions.
How does word embedding work in natural language processing?
Word embedding works in natural language processing by representing words as dense vectors of real numbers in a high-dimensional space, potentially up to 1000 dimensions. Vectorization is the process of turning words into numerical vectors. A dense vector is a vector where most of the entries are not zero. It is the opposite of a sparse vector such as one-hot encoding, which has many zero entries. This high-dimensional space is called the embedding space.
Words that have similar meanings or are used in similar contexts are assigned similar vectors, which means they are located close to each other in the embedding space. For example, “tea” and “coffee” are similar words that would be located close to each other, whereas “tea” and “sea” would be farther apart because they have dissimilar meanings and are not used together often, even though they have similar spelling.
While there are different methods of creating word embeddings in natural language processing, they all involve training on a large amount of text data called a corpus. The corpus can vary; Wikipedia and Google News are two common examples used for pre-trained embedding corpora.
The corpus can also be a custom embedding layer, which is specifically designed for the use case when other pre-trained corpora cannot supply sufficient data. During training, the model learns to associate each word with a unique vector based on the patterns of word usage in that data. These models can be used to transform words in any new text data into dense vectors.
How are word embeddings made?
Word embeddings can be made using a variety of techniques. Choosing a technique depends on the specific requirements of the task. You have to consider the size of the dataset, the domain of the data, and the complexity of the language. Here is how some of the more popular word embedding techniques work:
- Word2vec is a two-layer neural network-based algorithm that inputs a text corpus and outputs a set of vectors (hence the name). A commonly used Word2vec example is "King – Man + Woman = Queen." By deducing the relationship between "King" and "Man," and between "Man" and "Woman," the algorithm can identify "Queen" as the appropriate corresponding word to "King." Word2vec is trained using either Skip-Gram or Continuous Bag of Words (CBOW) algorithms. Skip-Gram tries to predict context words from a target word. Continuous Bag of Words functions the opposite way, predicting the target word using the context of the words around it.
- GloVe (Global Vectors) is based on the idea that the meaning of a word can be inferred from its co-occurrence with other words in a corpus of text. The algorithm creates a co-occurrence matrix that captures how frequently words appear together in the corpus.
- fasText is an extension of the Word2vec model and is based on the idea of representing words as a bag of character n-grams, or sub-word units, instead of just as individual words. Using a model similar to Skip-Gram, fasText captures information about the internal structure of words that helps it process new and unfamiliar vocabulary.
- ELMo (Embeddings from Language Models) differs from word embeddings like the ones mentioned above because it uses a deep neural network that analyzes the entire context in which the word appears. This allows it to pick up on subtle nuances in meaning that other embedding techniques may not catch.
- TF-IDF (Term Frequency - Inverse Document Frequency) is a mathematical value determined by multiplying the Term Frequency (TF) with the Inverse Document Frequency (IDF). The TF refers to the ratio of the target terms in the document compared to the total terms in the document. The IDF is a logarithm of the ratio of the total documents to the number of documents containing the target term.
What are the advantages of word embeddings?
Word embeddings offer several advantages over traditional approaches to representing words in natural language processing. Word embedding has become a standard approach in NLP, with many pre-trained embeddings available for use in various applications. This wide availability has made it easier for researchers and developers to incorporate them into their models without having to train them from scratch.
Word embedding has been used to improve language modeling, which is the task of predicting the next word in a sequence of text. By representing words as vectors, models can better capture the context in which a word appears and make more accurate predictions.
Building word embeddings can be faster than traditional engineering techniques because the process of training a neural network on a large corpus of text data is unsupervised, saving time and effort. Once the embedding is trained, it can be used as input features for a wide range of NLP tasks without the need for additional feature engineering.
Word embeddings typically have a much lower dimensionality than one-hot encoded vectors. This means that they require less memory and computational resources to store and manipulate. Because a word embedding is a dense vector representation of words, it represents words more efficiently than sparse vector techniques. This also allows it to capture the semantic relationships between words better.
What are the disadvantages of word embeddings?
While word embeddings have many advantages, there are also some disadvantages worth considering.
Training word embeddings can be computationally expensive, particularly when using large datasets or complex models. Pre-trained embeddings may also require significant storage space, which can be a problem for applications with limited resources. Word embeddings are trained on a finite vocabulary, which means that they may not be able to represent words that are not in that vocabulary. This can be a problem for languages with a large vocabulary or for terminology that is specific to the application.
If the data inputs for a word embedding contain biases, the word embedding may reflect those biases. For example, word embeddings can encode biases in gender, race, or other stereotypes, which can have implications for the real-world situations in which they are used.
Word embeddings are often considered a black box because their underlying models, such as the neural networks of GloVe or Word2Vec, are complex and difficult to interpret.
A word embedding is only as good as its training data. It is important to make sure that the data is sufficient for the word embedding to use in practice. While word embeddings grasp the general relationship between words, they may miss certain human nuances, such as sarcasm, that are more difficult to recognize.
Because a word embedding assigns one vector to each word, it can struggle with homographs, which are words that have the same spelling but different meanings. (For example, the word "park," which can mean an outdoor space or parking your car.)
Why are word embeddings used?
Word embeddings are used to enable vector search. They are foundational for natural language processing tasks such as sentiment analysis, text classification, and language translation. Word embeddings provide an effective path for machines to recognize and capture the semantic relationships between words. This makes NLP models more accurate and efficient than with manual feature engineering. Thus, the end result is more accessible and effective to users.
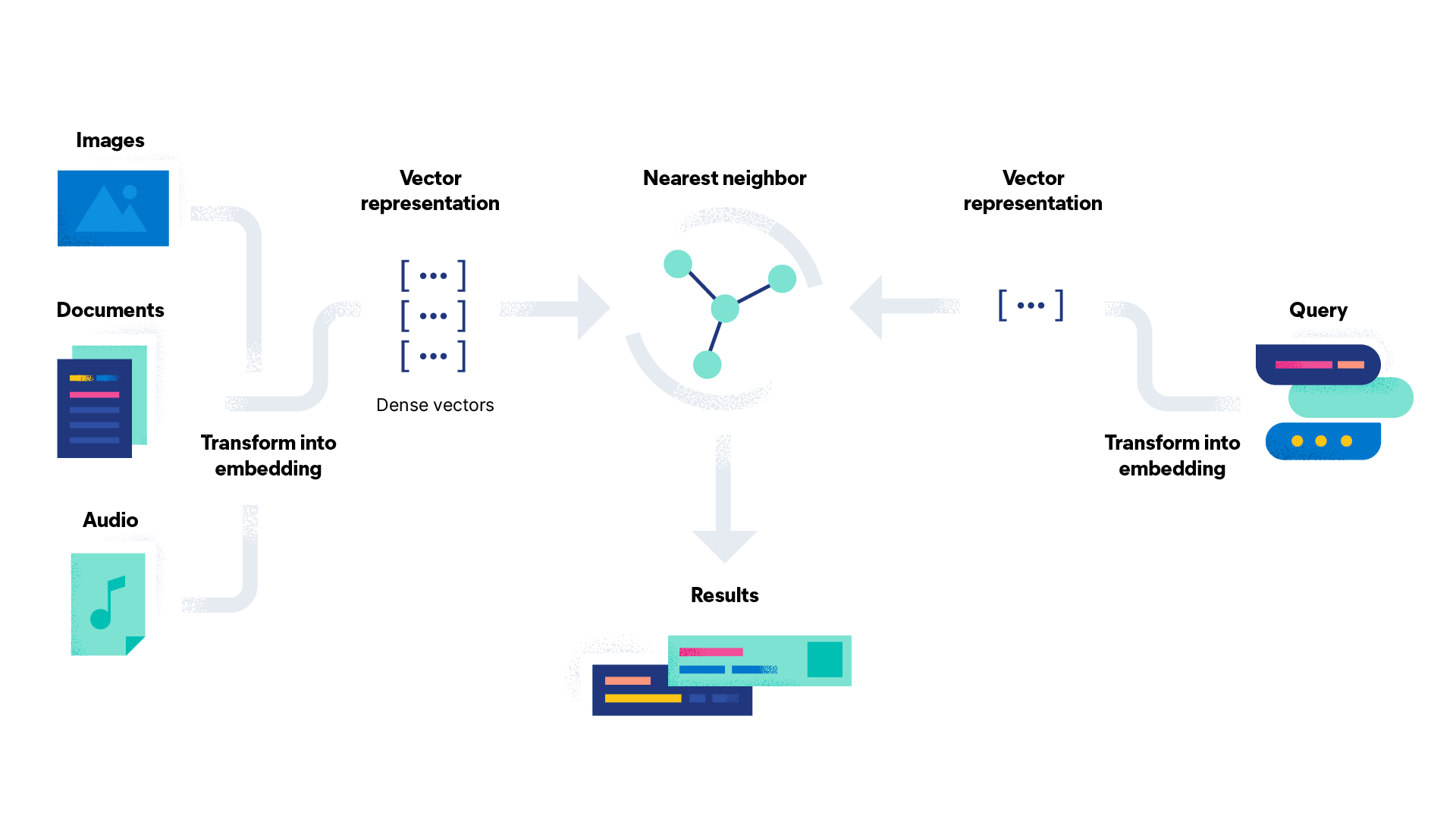
Word embedding can be used for a variety of tasks. Here are some word embedding use cases:
- Sentiment analysis: Sentiment analysis categorizes a piece of text as positive, negative, or neutral using word embedding. Sentiment analysis is often used by businesses to analyze feedback on their products from reviews and social media posts.
- Recommendation systems: Recommendation systems suggest products or services to users based on their previous interactions. For example, a streaming service can use word embeddings to recommend new titles based on a user's viewing history.
- Chatbots: Chatbots communicate with customers using natural language processing to generate appropriate responses to user inquiries.
- Search engines: Vector search is used by search engines to improve the accuracy of results. It uses word embeddings to analyze user queries compared to the content of web pages to create better matches.
- Original content: Original content is created by transforming data into readable natural language. Word embedding can be applied to a wide range of content types, from product descriptions to postgame sports reports.
Get started with word embeddings and vector search with Elasticsearch
Elasticsearch is a distributed, free, and open search and analytics engine for all types of data, including structured and unstructured text analysis. It securely stores your data for fast search, fine‑tuned relevance, and powerful analytics that scale efficiently. Elasticsearch is the central component of the Elastic Stack, a set of open source tools for data ingestion, enrichment, storage, analysis, and visualization.
Elasticsearch helps you to:
- Improve user experiences and increase conversions
- Enable new insights, automation, analytics, and reporting
- Increase employee productivity across internal docs and applications