Wie kommen meine Daten in den Elasticsearch Service?
Wenn es um das Suchen nach Daten und um Datenanalysen geht, ist Elasticsearch allgegenwärtig. Entwickler und Communities nutzen Elasticsearch für die unterschiedlichsten Anwendungsfälle, von der Suche in Anwendungen und der Suche auf Websites über das Logging und die Infrastrukturüberwachung bis hin zu APM und Security Analytics. Für diese Anwendungsfälle gibt es mittlerweile frei erhältliche Lösungen, denen aber allen gemein ist, dass Entwickler ihre Daten zunächst irgendwie in Elasticsearch hineinbekommen müssen.
In diesem Artikel werden einige der gängigsten Wege beschrieben, wie Daten in den Elasticsearch Service eingespeist („ingestiert“) werden können. Dabei kann es sich um einen Cluster handeln, der entweder auf Elastic Cloud oder auf der On-Premise-Variante Elastic Cloud Enterprise gehostet ist. Wenngleich wir uns hier auf diese Dienste konzentrieren, ist die Vorgehensweise beim Ingestieren in einen selbstverwalteten Elasticsearch-Cluster fast identisch. Der einzige Unterschied besteht darin, wie der Cluster angesprochen wird.
Bevor wir uns gleich den technischen Details widmen, noch dieser Hinweis: Sollten bei Ihnen beim Lesen dieses Artikels irgendwelche Fragen aufkommen, erhalten Sie bei discuss.elastic.co bestimmt hilfreiche Antworten. Die Community dort ist äußerst lebendig und hilft gern.
Jetzt aber zum Thema. Im Folgenden wird es um das Ingestieren von Daten mit den folgenden Methoden gehen:
- Elastic Beats
- Logstash
- Sprachclients
- Kibana Dev Tools
Ingestieren von Daten in den Elasticsearch Service
Elasticsearch stellt für die Kommunikation mit Client-Anwendungen eine flexible RESTful-API bereit. Diese API erlaubt es, REST-Aufrufe zu verwenden, um Daten zu ingestieren, Suchen und Datenanalysen durchzuführen sowie die Cluster und ihre Indizes zu verwalten. Alle der hier beschriebenen Methoden stützen sich für das Ingestieren von Daten in Elasticsearch letztlich auf diese API.
Wir gehen im Folgenden davon aus, dass Sie bereits einen Elasticsearch Service-Cluster erstellt haben. Sollte dies nicht der Fall sein, nutzen Sie die Möglichkeit, die Elastic-Cloud kostenlos auszuprobieren. Nachdem Sie einen Cluster erstellt haben, erhalten Sie sowohl eine Cloud-ID als auch ein Passwort für das Superuser-Konto „elastic“. Die Cloud-ID hat die folgende Form: cluster_name:ZXVy...Q2Zg==. Sie verschlüsselt die URL Ihres Clusters und vereinfacht das Ingestieren von Daten in den Cluster, wie wir später noch sehen werden.
Elastic Beats
Elastic Beats ist eine Sammelbezeichnung für eine Gruppe leichtgewichtiger Daten-Shipper, mit denen Sie ganz bequem Daten an den Elasticsearch Service senden können. „Leichgewichtig“ bedeutet dabei, dass Beats keinen großen Laufzeit-Overhead haben. So können sie gut auf Geräten mit begrenzten Hardwareressourcen, wie IoT-Geräten, Edge-Geräten oder eingebetteten Geräten, laufen und dort Daten erfassen. Beats eignen sich hervorragend, wenn Sie Daten erfassen möchten, es Ihnen aber an den Ressourcen für ressourcenintensive Datenerfassungs-Tools mangelt. Diese Art der ubiquitären Datenerfassung auf allen Geräten im Netzwerk erlaubt es Ihnen unter anderem, schnell systemweite Probleme und Sicherheitsvorfälle zu erkennen und entsprechend zu reagieren.
Die Verwendung von Beats ist natürlich nicht auf Systeme mit begrenzten Ressourcen beschränkt – sie können auch auf Systemen eingesetzt werden, auf denen mehr Hardware-Ressourcen zur Verfügung stehen.
Die Beats-Familie im Überblick
Es gibt unterschiedliche Beats für unterschiedliche Daten:
- Filebeat ermöglicht das Einlesen, Vorbereiten und Senden von Daten aus Quellen, die in Dateiform vorliegen. Die meisten Nutzer nutzen Filebeat zwar zum Einlesen von Logdateien, aber es werden alle Dateiformate unterstützt, solange sie nicht binär sind. Filebeat unterstützt darüber hinaus auch eine Reihe anderer Datenquellen, einschließlich TCP/UDP, Containern, Redis und Syslog. Durch ein reichhaltiges Angebot an Modulen wird das Erfassen und Parsen von Logformaten für häufige Anwendungen, wie Apache, MySQL und Kafka, weiter vereinfacht.
- Metricbeat erfasst System- und Dienstmetriken und nimmt erste Verarbeitungsschritte vor. Zu den Systemmetriken gehören Informationen über laufende Prozesse sowie Angaben zur Nutzung der CPU, des Arbeitsspeichers, der Festplatte(n) und des Netzwerks. Dank verschiedener Module können Daten aus einer Vielzahl von Diensten erfasst werden, wie Kafka, Palo Alto Networks, Redis und vielen anderen mehr.
- Packetbeat erfasst Live-Netzwerkdaten und führt erste Verarbeitungsschritte durch. So werden die Grundlagen für die Überwachung von Anwendungen und für die Analyse der Sicherheit und der Netzwerkleistung geschaffen. Zu den Protokollen, die von Packetbeat unterstützt werden, gehören unter anderem DHCP, DNS, HTTP, MongoDB, NFS und TLS.
- Winlogbeat kümmert sich um das Erfassen von Ereignisprotokollen aus Windows-Betriebssystemen. Es erfasst Anwendungsereignisse, Hardware-Ereignisse und Sicherheits- sowie Systemereignisse. Die umfangreichen Informationen, die Windows-Ereignisprotokolle zur Verfügung stellen, sind für zahlreiche Anwendungsfälle von großem Interesse.
- Auditbeat erkennt Veränderungen an wichtigen Dateien und erfasst Ereignisdaten aus dem Linux Audit Framework. Die Bereitstellung von Auditbeat, das in erster Linie in Security-Analytics-Anwendungsfällen zum Einsatz kommt, wird durch verschiedene Module erleichtert.
- Heartbeat überwacht durch aktives Testen die Verfügbarkeit von Systemen und Diensten. Das ist in vielen Szenarien hilfreich, so zum Beispiel bei der Infrastrukturüberwachung und bei Security-Analytics-Anwendungsfällen. Unterstützt werden die Protokolle ICMP, TCP und HTTP.
- Functionbeat erfasst Logdaten und Metriken aus serverlosen Umgebungen, wie zum Beispiel AWS Lambda.
Wenn Sie sich erst einmal entschieden haben, welchen dieser Beats Sie in Ihrem konkreten Szenario verwenden möchten, sind die nächsten Schritte ganz einfach, wie der nächste Abschnitt zeigt.
Erste Schritte mit Beats
In diesem Abschnitt sehen wir uns anhand von Metricbeat an, wie Sie die ersten Schritte mit Beats gehen können. Die Vorgehensweise bei den anderen Beats ist sehr ähnlich. Lesen Sie bitte die Dokumentation und befolgen Sie die dort für Ihren Beat und Ihr Betriebssystem beschriebenen Schritte.
- Laden Sie den gewünschten Beat herunter und installieren Sie ihn. Beats können auf verschiedene Weise installiert werden, aber die meisten Nutzer verwenden die von Elastic bereitgestellten Repositorys für den Package Manager des Betriebssystems (DEB/RPM) oder laden einfach die bereitgestellten tgz/zip-Pakete herunter und entpacken sie.
- Konfigurieren Sie den Beat und aktivieren Sie die gewünschten Module.
- Wenn Sie beispielsweise Metriken zu den auf Ihrem System laufenden Docker-Containern erfassen möchten, aktivieren Sie das Docker-Modul. Falls Sie das Paket mit dem Package Manager installiert haben, geht dies mit
sudo metricbeat modules enable docker. Sollten Sie stattdessen die tgz/zip-Datei verwendet haben, geben Sie Folgendes ein:/metricbeat modules enable docker. - Über die Cloud-ID lässt sich bequem festlegen, an welchen Elasticsearch Service die erfassten Daten gesendet werden sollen. Fügen Sie der Metricbeat-Konfigurationsdatei (metricbeat.yml) die Cloud-ID und die nötigen Authentifizierungsinformationen hinzu:
cloud.id: cluster_name:ZXVy...Q2Zg== cloud.auth: "elastic:YOUR_PASSWORD"
- Wie bereits erwähnt, haben Sie den
cloud.id-Wert bei der Erstellung Ihres Clusters erhalten. Fürcloud.authist der Benutzername und das Passwort (durch einen Doppelpunkt voneinander getrennt) für einen Benutzer einzugeben, der über ausreichende Berechtigungen innerhalb des Elasticsearch-Clusters verfügt. - Am schnellsten geht es, wenn Sie den Superuser „elastic“ mit dem Passwort verwenden, das Ihnen bei der Cluster-Erstellung mitgeteilt wurde. Die Konfigurationsdatei finden Sie im Verzeichnis
/etc/metricbeat(bei Installation mithilfe des Package Managers) beziehungsweise in dem Verzeichnis, in das Sie die tgz/zip-Datei entpackt haben.
- Laden Sie vorgefertigte Dashboards in Kibana. Die meisten Beats und ihre Module werden mit vordefinierten Kibana-Dashboards ausgeliefert. Wenn Sie Ihr Beat mit dem Package Manager installiert haben, können Sie sie mit
sudo metricbeat setupladen. Haben Sie stattdessen das tgz/zip-Paket genutzt, verwenden Sie./metricbeat setupin dem Verzeichnis, in das Sie die tgz/zip-Datei entpackt haben.
- Starten Sie den Beat. Wenn Sie Metricbeat auf einem systemd-basierten Linux-System mit dem Packet Manager installiert haben, verwenden Sie
sudo systemctl start metricbeat. Bei Installation über die tgz/zip-Datei geben Sie./metricbeat -eein.
Falls alles glatt gelaufen ist, wird Ihr Elasticsearch Service jetzt mit Daten befüllt.
Erkunden Sie die vorgefertigten Dashboards
Gehen Sie im Elasticsearch Service zu Kibana, um sich die Daten anzusehen:
- Wählen Sie in Kibana Discover das Indexmuster
metricbeat-*. Jetzt können Sie sich die einzelnen Dokumente ansehen, die ingestiert wurden. - Auf dem Kibana-Tab „Infrastructure“ werden Ihnen Ihre System- und Docker-Metriken grafisch aufbereitet in Form von Diagrammen zur Nutzung der Systemressourcen (CPU, Arbeitsspeicher, Netzwerk) angezeigt.
- Sie können in Kibana Dashboards eines der Dashboards mit dem Präfix „[Metricbeat System]“ auswählen, um sich die entsprechenden Daten in interaktiver Form präsentieren zu lassen.
Logstash
Logstash ist ein leistungsfähiges und flexibles Tool zum Lesen, Verarbeiten und Senden von Daten jeder Art. Logstash bietet eine Reihe von Funktionen, die mit Beats derzeit nicht verfügbar oder in der Umsetzung zu teuer sind, wie das Anreichern von Dokumenten mittels Lookups in externen Datenquellen. Die Funktionalität und Flexibilität, die Logstash bietet, ist aber kostspielig. Zudem benötigt Logstash deutlich leistungsfähigere Hardware als Beats. Das heißt, dass Logstash generell nicht auf Geräten mit geringen Ressourcen bereitgestellt werden sollte. Daher ist Logstash eine geeignete Alternative zu Beats, wenn Beats für einen bestimmten Anwendungsfall nicht ausreichen.
Es ist gängige Architekturpraxis, dass Beats und Logstash miteinander kombiniert werden: Die Beats erfassen die Daten und Logstash übernimmt die Datenverarbeitungsaufgaben, zu denen die Beats nicht in der Lage sind.
Logstash im Überblick
Logstash führt Ereignisverarbeitungs-Pipelines aus, wobei jede Pipeline mindestens aus einem der folgenden Elemente besteht:
- Inputs lesen Daten aus Datenquellen. Zu den offiziell unterstützten Datenquellen gehören Dateien, HTTP, IMAP, JDBC, Kafka, Syslog, TCP und UDP.
- Filter verarbeiten die Daten auf verschiedene Art und Weise und reichern sie an. In vielen Fällen müssen unstrukturierte Logzeilen erst in ein strukturiertes Format geparst werden. Zu diesem Zweck stellt Logstash unter anderem Filter für das Parsen von CSV- und JSON-Dateien, von Schlüssel/Wert-Paaren, von unstrukturierten Daten mit Trennzeichen und von komplexen unstrukturierten Daten auf der Basis regulärer Ausdrücke (Grok-Filter) bereit. Außerdem stehen Filter zum Anreichern von Daten mittels DNS-Lookups, zum Hinzufügen von Geoinformationen über IP-Adressen oder zum Durchführen von Lookups in benutzerdefinierten Wörterbüchern oder Elasticsearch-Indizes zur Verfügung. Zusätzliche Filter ermöglichen verschiedene Transformationen der Daten; so können Datenfelder und Werte umbenannt, entfernt und kopiert werden (Filter „mutate“).
- Outputs schreiben die geparsten und angereicherten Daten in Datensenken und stellen damit die letzte Etappe der Logstash-Verarbeitungs-Pipeline dar. Die Zahl der Output-Plugins ist groß. Wir werden uns im Folgenden auf das Ingestieren von Daten in den Elasticsearch Service mit dem Output-Plugin „elasticsearch“ konzentrieren.
Beispiel für eine Logstash-Pipeline
Jeder Anwendungsfall ist anders. Daher werden Sie wahrscheinlich eigene Logstash-Pipelines für Ihre konkreten Dateneingaben und Anforderungen entwickeln müssen.
Wir zeigen Ihnen hier ein Beispiel für eine Logstash-Pipeline, die
- den Elastic Blogs-RSS-Feed liest,
- einige leichte Verarbeitungsschritte durchführt, indem Felder kopiert und umbenannt sowie Sonderzeichen und HTML-Tags entfernt werden, und
- die Dokumente in Elasticsearch ingestiert.
Gehen Sie wie folgt vor:
- Installieren Sie Logstash über Ihren Package Manager oder durch Herunterladen und Entpacken der tgz/zip-Datei.
- Installieren Sie das Logstash-RSS-Input-Plugin, mit dem RSS-Datenquellen gelesen werden können:
./bin/logstash-plugin install logstash-input-rss - Kopieren Sie die folgende Logstash-Pipeline-Definition in eine neue Datei, wie z. B. ~/elastic-rss.conf:
input { rss { url => "/blog/feed" interval => 120 } } filter { mutate { rename => [ "message", "blog_html" ] copy => { "blog_html" => "blog_text" } copy => { "published" => "@timestamp" } } mutate { gsub => [ "blog_text", "<.*?>", "", "blog_text", "[\n\t]", " " ] remove_field => [ "published", "author" ] } } output { stdout { codec => dots } elasticsearch { hosts => [ "https://<your-elsaticsearch-url>" ] index => "elastic_blog" user => "elastic" password => "<your-elasticsearch-password>" } }
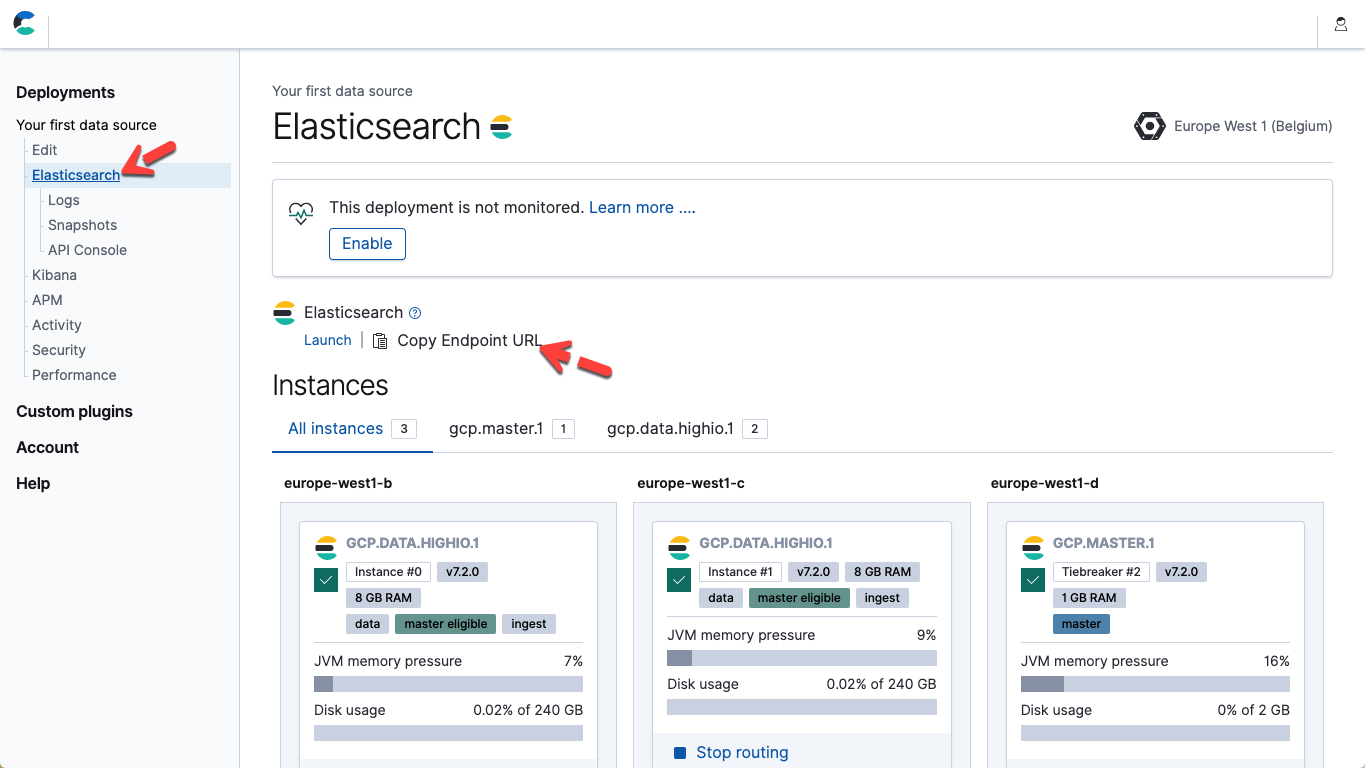
- Ändern Sie in der Datei oben die Parameter „hosts“ und „password“ entsprechend Ihrem Elasticsearch Service-Endpunkt und dem Passwort für den Nutzer „elastic“. In Elastic Cloud finden Sie die URL des Elasticsearch-Endpunkts auf der Seite mit den Deployment-Details („Copy Endpoint URL“).
- Führen Sie die Pipeline aus, indem Sie Logstash starten: ./bin/logstash -f ~/elastic-rss.conf
Das Starten von Logstash dauert mehrere Sekunden. Auf der Konsole erscheinen Punkte (.....). Jeder Punkt steht für ein Dokument, das in Elasticsearch ingestiert wurde.
- Öffnen Sie Kibana. Führen Sie in der Kibana Dev Tools-Konsole Folgendes aus, um zu bestätigen, dass 20 Dokumente ingestiert wurden: POST elastic_blog/_search
Sprachclients
Es gibt Situationen, in denen es sinnvoll ist, das Ingestieren von Daten in den benutzerdefinierten Anwendungscode zu integrieren. Dazu empfehlen wir die Verwendung eines der offiziell unterstützten Elasticsearch-Clients. Bei diesen Clients handelt es sich um Bibliotheken, die die genauen technischen Details der Dateningestion verbergen, sodass Sie sich auf die Aspekte konzentrieren können, die für Ihre Anwendung spezifisch sind und an denen gearbeitet werden muss. Es gibt offizielle Clients für Java, JavaScript, Go, .NET, PHP, Perl, Python und Ruby. Alle Einzelheiten und Codebeispiele finden Sie in der Dokumentation für die jeweilige Sprache. Wenn Ihre Anwendung in einer anderen als den oben aufgeführten Sprachen geschrieben wurde, stehen die Chancen nicht schlecht, dass es einen von der Community bereitgestellten Client gibt.Kibana Dev Tools
Für das Entwickeln und Debugging von Elasticsearch-Anfragen empfehlen wir die Verwendung der Kibana Dev Tools-Konsole. Mit Dev Tools profitieren Sie vom gesamten Potenzial und der Flexibilität der generischen Elasticsearch-REST-API, ohne sich über die technischen Details der zugrunde liegenden HTTP-Anfragen kümmern zu müssen. Es überrascht daher auch nicht, dass die Dev Tools-Konsole dazu verwendet werden kann, rohe JSON-Dokumente per PUT in Elasticsearch zu bringen:PUT my_first_index/_doc/1 { "title" : "How to Ingest Into Elasticsearch Service", "date" : "2019-08-15T14:12:12", "description" : "This is an overview article about the various ways to ingest into Elasticsearch Service" }