Universal Profiling
Mehr Optimierung und Nachhaltigkeit durch kontinuierliches Profiling
Dank uneingeschränkten Einblicken in Ihre komplexen, cloudnativen Umgebungen können Sie Ihren ökologischen Fußabdruck deutlich verringern. Optimieren Sie durch reibungsloses und kontinuierliches Profiling auf OpenTelemetry-Basis die Performance auf allen Ebenen Ihrer Anwendungen, Dienste und Infrastrukturelemente, ohne dass es dazu einer Instrumentierung bedarf.
Elastic Universal Profiling jetzt allgemein verfügbar – Performance Engineering trifft auf Nachhaltigkeit
Mehr erfahrenErfahren Sie, was es mit der kürzlichen Spende des Universal Profiling-Agents von Elastic an OpenTelemetry auf sich hat.
Blogpost lesenLesen Sie, warum Elastic im „Gartner Magic Quadrant for Application Performance Monitoring“ 2023 als „Visionary“ aufgeführt wird.
Mehr erfahrenAlways-On-Profiling, das einfach funktioniert
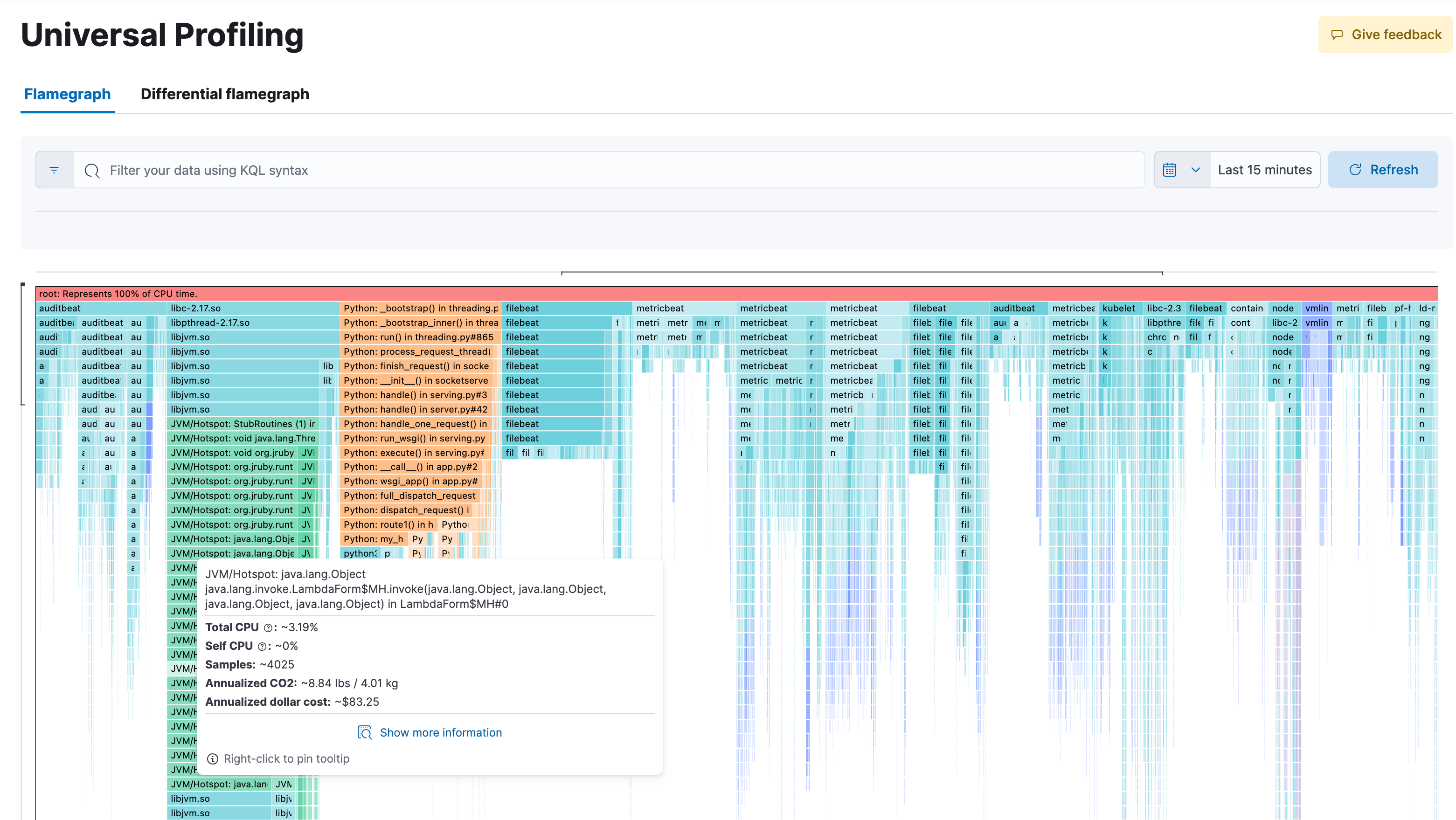
Mit kontinuierlichem Profiling des gesamten Systems erhalten Sie beispiellose Einblicke auf allen Ebenen. Unter Nutzung der eBPF-Technologie und mithilfe von OpenTelemetry erstellt Universal Profiling für jede Codezeile, die auf dem Rechner ausgeführt wird, ein Profil – nicht nur für den Anwendungscode, sondern auch für den Kernel und für Bibliotheken von Drittanbietern. Da nur die notwendigen Daten erfasst und die Abläufe dabei nicht gestört werden, kann Universal Profiling ohne spürbare Auswirkungen kontinuierlich auf Produktionssystemen laufen (der CPU-Overhead liegt bei unter 1 %). Das erfordert weder störende Codeänderungen noch irgendwelchen Instrumentierungsaufwand.
Leistungsoptimierung jederzeit verfügbar
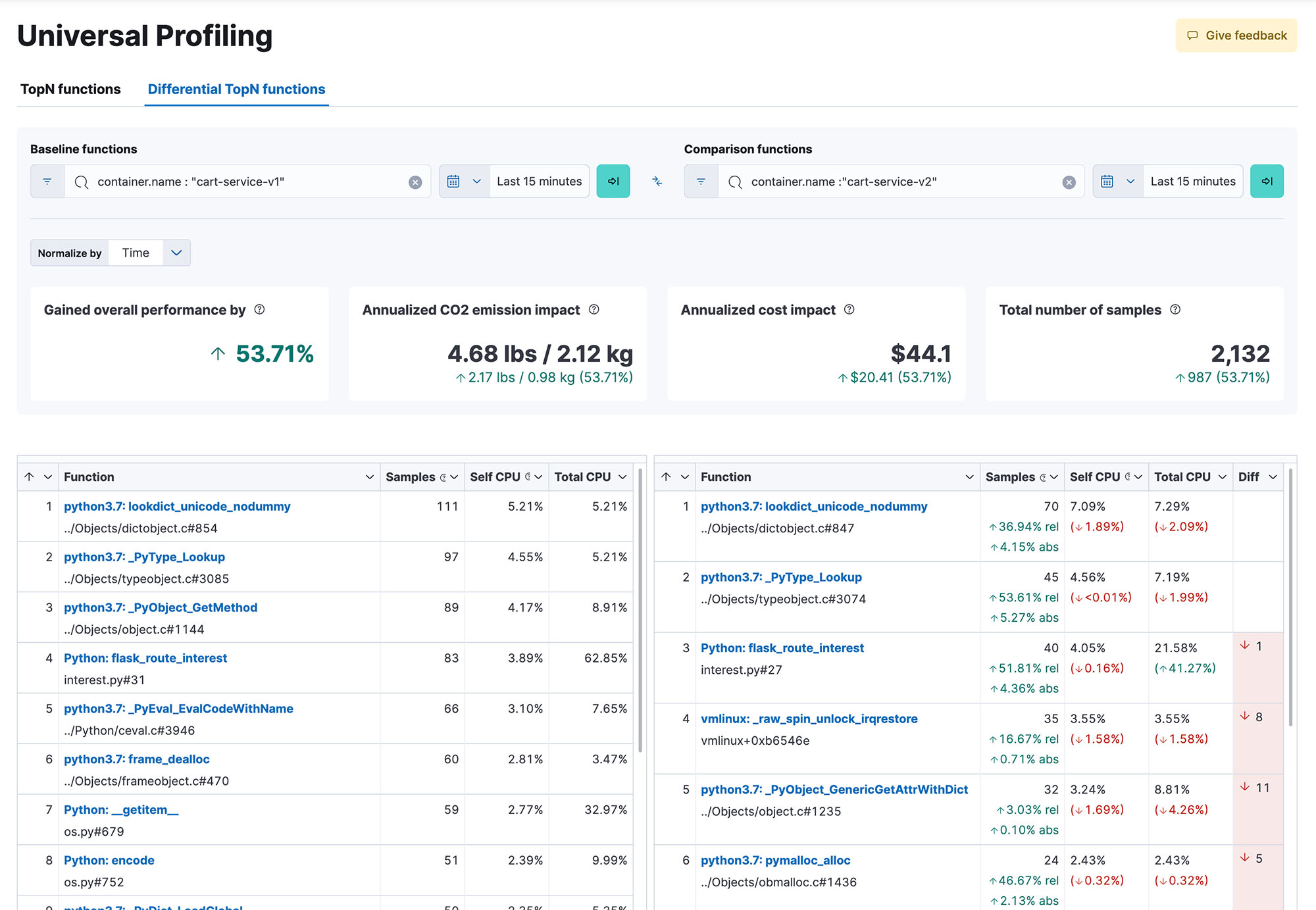
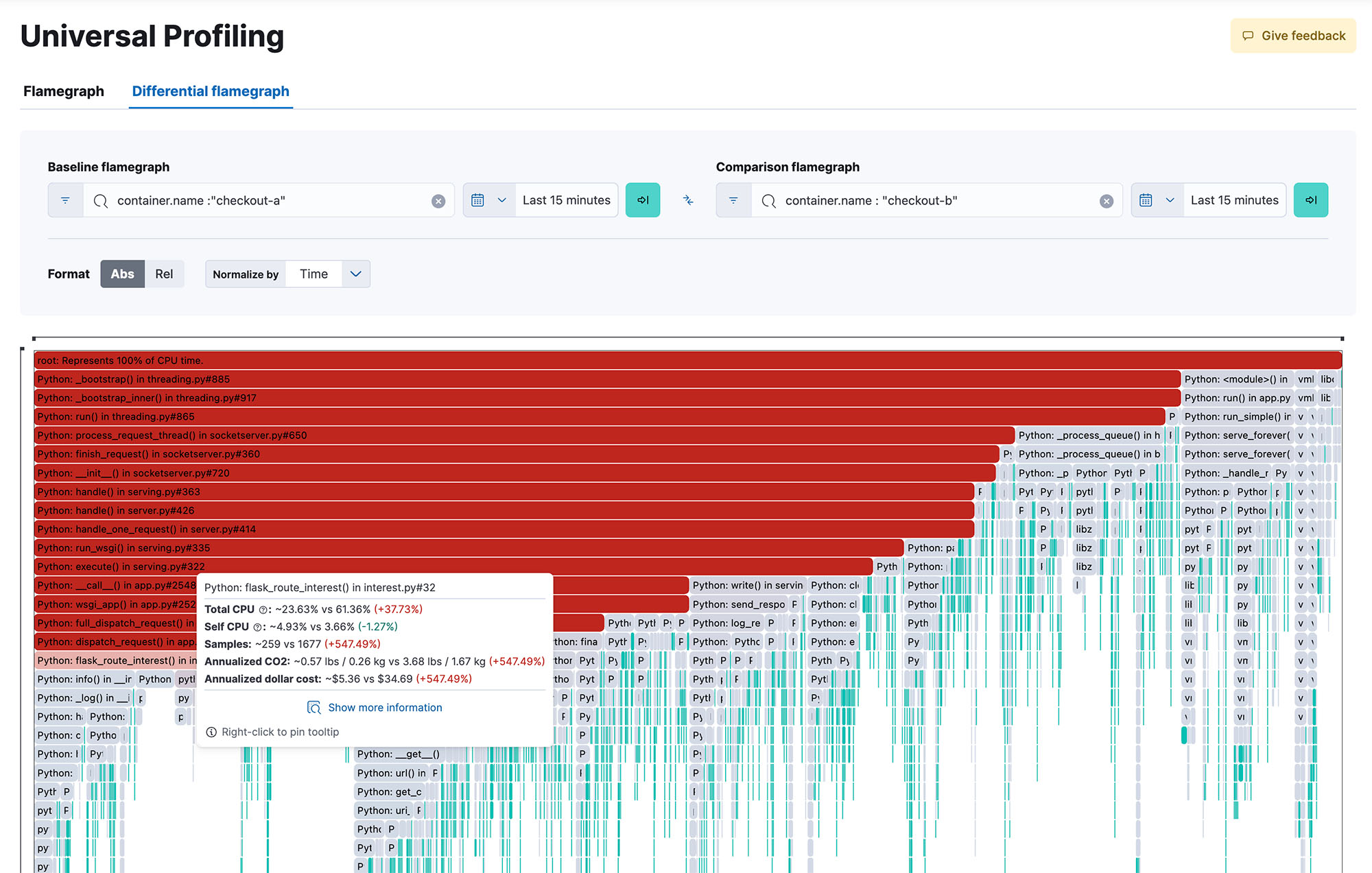
Verschaffen Sie sich einen systemweiten Einblick in 100 % Ihres Codes während der Ausführung, über Methoden, Klassen, Threads und Container hinweg, und eröffnen Sie sich die Möglichkeit, verschiedene Builds zu vergleichen, um Performance-Rückgänge zu erkennen. Dynamische und intuitive Flamegraphs in einer zentralen Ansicht helfen Ihnen, den Überblick über die Performance Ihres gesamten Systems zu behalten. Ermitteln Sie, welche Codepassagen die meisten Ressourcen beanspruchen, um Performance-Engpässe zu identifizieren und zu beheben, die Cloud-Ausgaben zu optimieren und den CO2-Fußabdruck Ihrer Infrastruktur zu verringern.
Flexible und reibungslose Bereitstellung
Für Elastic Universal Profiling sind weder Änderungen am Quellcode der Anwendung noch Instrumentierungsarbeiten oder andere problematische Operationen erforderlich. Stellen Sie einfach den Agent bereit – und innerhalb weniger Minuten stehen Ihnen Ihre Profiling-Daten zur Verfügung. Der Agent kann mithilfe von Elastic Agent bereitgestellt werden, manuell als native Binärdatei oder als privilegierter Docker-Container ausgeführt oder automatisch mithilfe des Orchestrierungs-Frameworks Ihres Clusters bereitgestellt werden.
Breite Ökosystemunterstützung
Die Profiling-Lösung unterstützt Ablaufverfolgungen in gemischten Sprachen für praktisch alle verbreiteten Laufzeitumgebungen, inklusive PHP, Python, Java (oder jede beliebige JVM-Sprache), Go, Rust, C/C++, Node.js/V8, Ruby, Perl und Zig. Dazu erhalten Sie erstklassige Unterstützung für alle wichtigen Containerisierungs- und Orchestrierungs-Frameworks, egal ob Ihre Lösung lokal oder in einer verwalteten Kubernetes-Plattform wie GKE, AKS oder EKS ausgeführt wird.

Das kontinuierliche Profiling des gesamten Systems ist eine der verschiedenen Möglichkeiten, wie Sie Ihre Apps überwachen können.
Elastic Observability bietet eine zentrale Lösung für die Überwachung Ihrer gesamten Infrastruktur.