Une observabilité et une sécurité modernes sur Kubernetes avec Elastic et OpenTelemetry


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
En raison de sa nature structurée, Kubernetes permet de déployer et de gérer des services et des applications de manière réitérable et scalable. C'est ce qui a favorisé la démocratisation de cette solution sur les marchés verticaux aussi bien pour les modèles de déploiement sur site que dans le cloud. Néanmoins, l'autonomie de fonctionnement de Kubernetes implique d'avoir une observabilité et une sécurité exhaustives et pleinement convergées. Aujourd'hui, seule l'utilisation de la plateforme Elastic permet d'y parvenir.
Dans cet article, nous aborderons les bonnes pratiques pour observer et sécuriser les workflows des applications et des services sur Kubernetes avec Elasticsearch et OpenTelemetry. Vous apprendrez notamment à :
- déployer et configurer Elastic Agent dans votre cluster Kubernetes ;
- ingérer les traces d'applications, les indicateurs et les événements d'OpenTelemetry avec Elastic Agent ;
- ingérer les logs de conteneurs, les indicateurs de cluster et les schémas du trafic réseau avec Elastic Agent ;
- utiliser Elastic Defend pour ajouter un monitoring axé sur la sécurité et une protection contre les menaces à votre cluster Kubernetes ;
- vous familiariser avec les tableaux de bord Elastic prêts à l'emploi pour observer, mettre en corrélation et réaliser une analyse de la cause première des problèmes opérationnels.
Le cloisonnement des données comme frein à la résolution des problèmes de déploiement Kubernetes
Historiquement, le secteur considère l'observabilité des applications, l'observabilité de l'infrastructure et la sécurité de l'infrastructure comme des domaines distincts, chacun pris en charge par des outils distincts gérés par des équipes distinctes. Or cette approche, bien qu'elle soit souvent pratique d'un point de vue organisationnel, met en lumière un point problématique et bloquant :
Les analystes (qu'il s'agisse d'hommes ou de machines) doivent s'appuyer sur les données collectées à partir de l'observabilité des applications, de l'observabilité de l'infrastructure et de la sécurité de l'infrastructure s'ils veulent pouvoir déterminer l'origine d'un problème opérationnel spécifique, c'est-à-dire si celui-ci vient de l'infrastructure, d'un défaut d'une application ou d'une violation de sécurité. Et ce n'est pas tout. Les spécialistes ont également besoin de données d'une précision extrême venant de ces trois sources pour pouvoir identifier la cause première d'un problème donné.
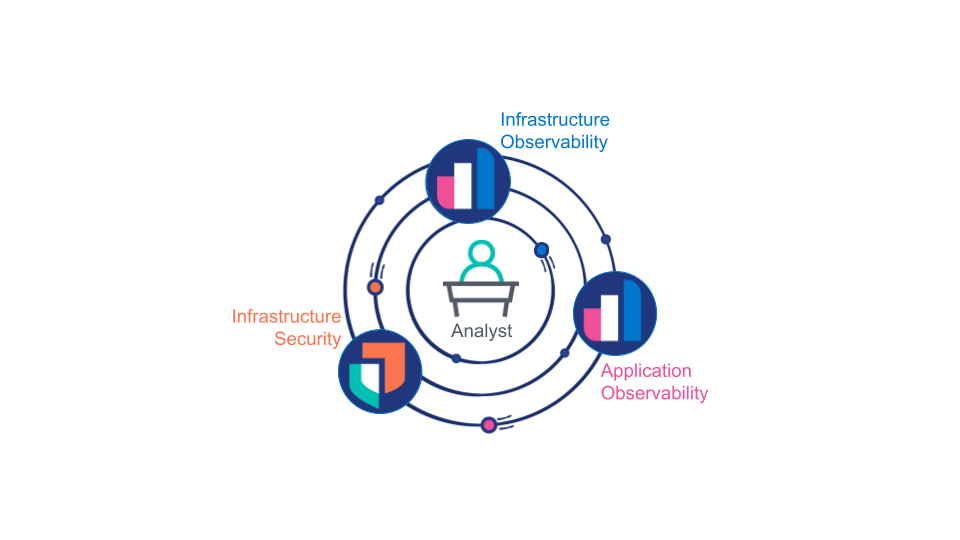
Pour contourner cette difficulté, les clients se retrouvent souvent obligés de dupliquer des données d'observabilité spécifiques sur plusieurs plateformes de données. Dans le meilleur des cas, cette pratique ne fait "que" doubler ou tripler les coûts de stockage des données, de support technique et de formation. Mais dans le pire des scénarios, les analystes passent à côté de certaines données essentielles pour déterminer correctement la cause première d'un problème, faute d'accès. Or cette difficulté est exacerbée par la nature dynamique et scalable de Kubernetes. En effet, la distinction entre plateformes d'observabilité et de sécurité est contreproductive si l'on se réfère au modèle intégré de déploiement de services que Kubernetes offre.
L'observabilité, un élément incontournable
Au final, les développeurs, les opérateurs et les analystes en sécurité ont tous besoin d'une vue unifiée de bout en bout sur leur système englobant à la fois les applications et l'infrastructure. Pour bénéficier de cette visibilité et sécuriser leurs clusters, un schéma de déploiement natif de Kubernetes est nécessaire pour les équipes de déploiement de l'infrastructure.
Dans cette optique, trois conditions entrent en jeu :
- Toutes les données d'observabilité et de sécurité, notamment les logs, traces, événements et indicateurs d'applications, de services et d'infrastructure, doivent être stockées dans une plateforme de données unifiée d'une manière qui soit optimisée aussi bien pour la recherche (corrélation et latence) que pour le stockage (coût).
- La plateforme de données unifiée doit être également capable de mettre les données en corrélation et de les présenter de façon appropriée en fonction des rôles : par exemple, si un analyste essaye de déterminer la cause première d'un problème, la plateforme devrait le guider vers le problème potentiel et lui permettre d'interagir avec les données sans qu'il ait à se préoccuper de leur forme ou de leur source sous-jacente.
- L'instrumentation des applications et de l'infrastructure devrait se faire selon le mantra de Kubernetes, c'est-à-dire avec des déploiements réitérables et scalables sans configuration sur mesure.
Elastic : le duo gagnant avec Kubernetes
Une combinaison de technologies proposée par Elastic, OpenTelemetry, Kubernetes et un matériel informatique moderne a permis de mettre en place une observabilité et une sécurité natives de Kubernetes à grande échelle :
- OpenTelemetry est un catalyseur pour les développeurs (à la fois internes et tiers) qui permet d'instrumenter pleinement les applications et les services en dissociant la sélection de fournisseurs APM et la mise en œuvre APM.
- Un matériel informatique moderne doté de grandes ressources de processeur et de RAM permet un traçage continu pratique qui n'interfère pas avec les performances, même pour les applications en temps réel.
- Grâce à l'architecture Elastic la plus récente, qui inclut des snapshots interrogeables et le nouveau flux de données temporelles, ainsi qu'à l'échantillonnage intelligent en aval d'Elastic APM, le stockage en ligne des données d'observabilité et de sécurité collectées au fil des ans devient pratique et économique.
- Avec le déploiement d'une instance Elastic Agent dans le DaemonSet de chaque nœud Kubernetes, il est possible de déployer un collecteur de données unifiées contrôlé à distance de façon réitérable et scalable. Une fois déployées, les différentes instances Elastic Agent peuvent être gérées comme une flotte pour tout simplement ajouter, configurer ou supprimer des intégrations de données.
- La plateforme Elastic fournit une solution de sécurité Kubernetes totalement intégrée, qui assure la protection, l'observation et la gestion de la posture.
- Avec des tableaux de bord prêts à l'emploi, la détection des anomalies et l'alerting, Elasticsearch permet de mettre en corrélation toutes les sources de données collectées et de guider les décisions.
Modèle de collecte de données
Comme vous pouvez le voir dans le diagramme ci-dessous, nous recommandons d'utiliser un modèle hybride pour la collecte de données d'observabilité et de sécurité. Ce modèle s'appuie sur Elastic Agent pour obtenir des indicateurs d'infrastructure Kubernetes et des logs de conteneurs d'applications, ainsi que sur l'agent APM d'OpenTelemetry pour avoir des traces d'applications, des événements de traces et des indicateurs. Le contexte de cette approche est décrit en détail ci-dessous.
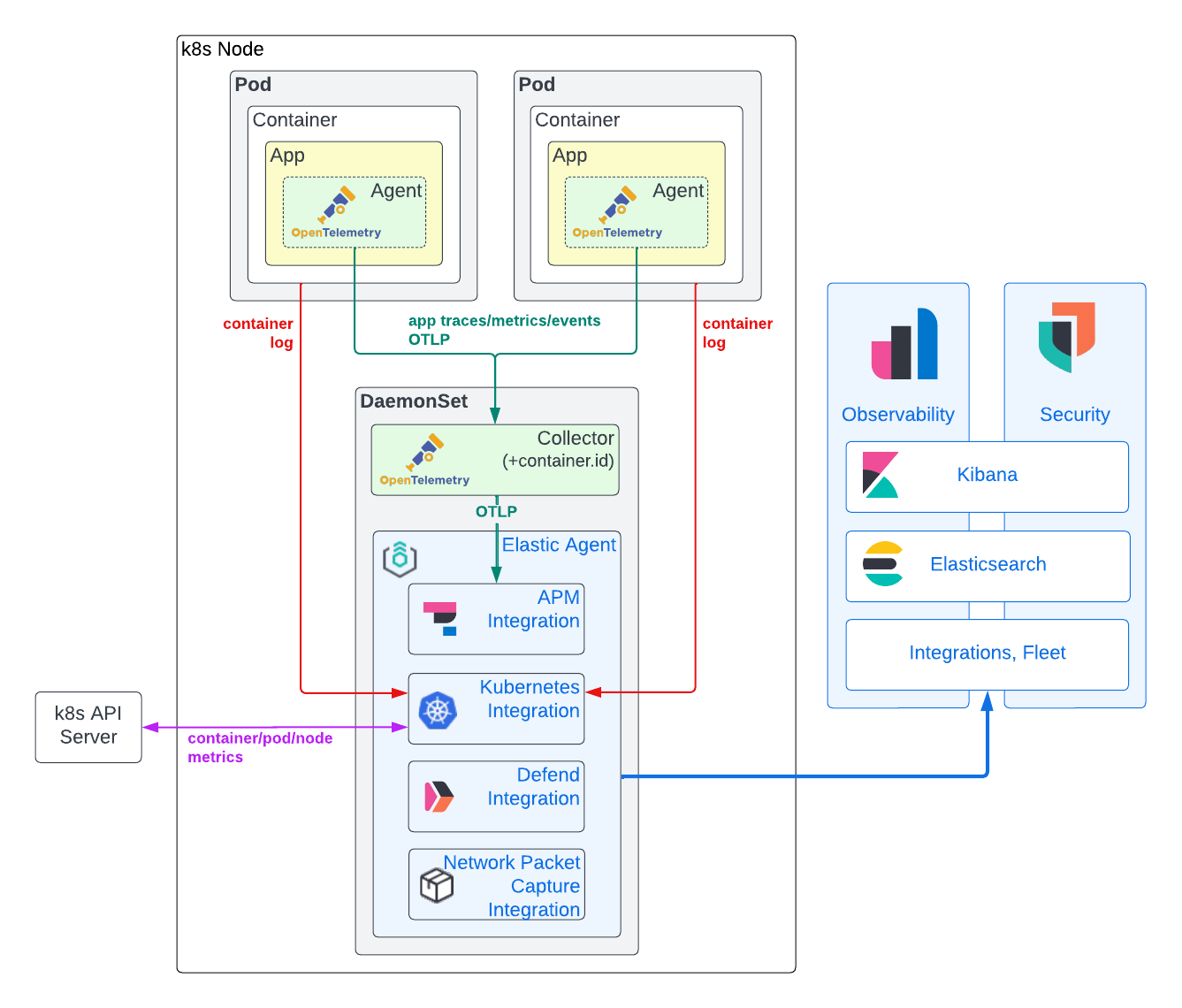
Données venant des traces d'applications, des événements et des indicateurs
Pour que des traces d'applications et des indicateurs soient générés, il faut généralement qu'une bibliothèque APM soit directement intégrée dans le code de l'application. Nous pouvons nous affranchir de la dépendance à un fournisseur, laquelle vient freiner l'adoption de l'APM, en utilisant les agents APM d'OpenTelemetry. Jusqu'à présent, OpenTelemetry a surtout orienté une grande partie de ses efforts vers des mises en œuvre robustes et normalisées d'agents pour capturer les traces d'applications et les événements de trace, avec une prise en charge progressive des indicateurs d'applications. Des agents raisonnablement matures existent aujourd'hui pour presque chaque langage de programmation prisé. Dans de nombreux cas, vous pouvez vous servir d'une auto-instrumentation pour instrumenter vos applications en utilisant peu, voire pas de code. Si vos applications sont écrites en .NET, Java, NodeJS ou Python, et qu'elles se servent de frameworks types, vous pouvez même injecter des bibliothèques APM au moment de l'exécution à l'aide de l'opérateur Kubernetes OpenTelemetry !
Pour réaliser une analyse de la cause première, les données APM doivent être mises en corrélation avec les logs d'applications et les indicateurs d'infrastructure. Pour que cette mise en corrélation soit possible, il faut des métadonnées d'identification ou des attributs de ressources communs dans le traçage de l'application, ainsi que dans les logs et les indicateurs de l'infrastructure. La plateforme Elastic utilise service.name, pod.uid et container.id pour relier les données d'observabilité venant d'applications s'exécutant sur Kubernetes. Par le passé, les bibliothèques APM "jetaient un œil" au-delà de leurs murs pour obtenir ces métadonnées. Certaines des bibliothèques APM d'OpenTelemetry prennent actuellement en charge cette fonctionnalité (par exemple, Java), tandis que d'autres non (Rust). Même si elle simplifie le déploiement, il est communément admis que cette approche est loin d'être idéale : Les agents APM (qui s'exécutent dans le contexte d'une application) doivent non seulement déterminer leur environnement d'exécution (docker, Kubernetes, etc.), mais aussi détenir suffisamment de permissions pour accéder à ces identificateurs (par exemple, accès à /proc/self/cgroup ou aux API Kubernetes). Ce deuxième aspect représente bien évidemment une préoccupation en matière de sécurité. De ce fait, nous souhaitons dans l'idéal nous appuyer sur des entités externes soit pour faire passer ces métadonnées (comme des variables d'environnement), soit pour ajouter ces métadonnées après la création des données de trace. Pour ajouter container.id de façon fiable aux données de trace quelle que soit la bibliothèque APM d'OpenTelemetry utilisée, nous déployons un collecteur OpenTelemetry configuré avec le processeur k8sattribute s'exécutant dans le DaemonSet du nœud.
Une fois les données APM étiquetées avec les métadonnées Kubernetes correspondantes, elles sont transférées du collecteur OpenTelemetry vers une instance Elastic Agent s'exécutant elle aussi dans le DaemonSet du nœud. Cette instance Elastic Agent a été configurée via Fleet avec l'intégration APM. Le fait de distribuer l'intégration APM dans le DaemonSet de chaque nœud aide à répartir la charge d'ingestion APM et de lier plus étroitement sa disponibilité aux applications qu'elle prend en charge. De plus, cela permet de maintenir le trafic GRPC/HTTP2 en local dans le DaemonSet et ainsi de contourner les complexités liées à l'équilibrage des charges GRPC/HTTP2. Au final, la sécurité s'en retrouve simplifiée : Le protocole OTLP peut rester non sécurisé dans le nœud, tandis que la sécurité TLS des instances Elastic Agent gérées par Fleet est appliquée entre le nœud et le cluster Elasticsearch. L'intégration Elastic APM convertit les données de traces, d'indicateurs et d'événements d'OpenTelemetry au format Elasticsearch Common Schema (ECS). Les documents qui en découlent sont ensuite envoyés à Elasticsearch afin qu'ils soient ingérés et indexés.
Logs de conteneurs et indicateurs d'infrastructure Kubernetes
Même si la norme OpenTelemetry prend en charge le logging, les mises en œuvre en sont encore au stade de l'ébauche. De ce fait, la plupart des agents disponibles ne sont pas encore capables de gérer les frameworks de logging. En pratique, l'ingestion des logs de conteneurs est le seul moyen simple de capturer les données des logs d'applications. Même si cela est possible avec le collecteur OpenTelemetry filelogreceiver, elle est de qualité "alpha" et n'est pas encore recommandée pour les cas d'utilisation de la production. Le même argument s'applique à k8sclusterreceiver, qui sert à capturer les indicateurs d'infrastructure Kubernetes.
En comparaison, l'intégration Kubernetes Elastic est robuste et éprouvée, et fournit une collection extrêmement précise de logs d'applications et d'indicateurs d'infrastructure Kubernetes. De plus, notre intégration Kubernetes peut être gérée à distance au niveau de la flotte à partir de Kibana, ce qui simplifie grandement la configuration. Contrairement aux traces d'applications et aux indicateurs, l'intégration Kubernetes Elastic s'exécute hors du code de votre application, ce qui diminue les risques de dépendance à un seul fournisseur.
De plus, la présence d'une instance Elastic Agent dans le DaemonSet de chaque nœud apporte une valeur ajoutée qui va bien au-delà de l'intégration Kubernetes. Comme vous le verrez plus loin dans cet article, nous nous servirons de cette même instance Elastic Agent pour déployer Elastic Defend afin de monitorer et de sécuriser nos nœuds Kubernetes.
Événements de sécurité et données d'hôte
Les workflows modernes d'observabilité et de sécurité Kubernetes doivent aller de pair pour permettre aux analystes de déterminer la cause première d'un problème donné. Les solutions de sécurité d'Elastic comprennent des solutions de SIEM, de SOAR et de XDR, y compris la protection aux points de terminaison, qui sont totalement intégrées, qui sont dotées de nombreuses fonctionnalités et qui sont compatibles avec Kubernetes.
Plus particulièrement, l'intégration Elastic Defend fournit une observabilité Kubernetes considérablement renforcée. Notre intégration de gestion de la posture de sécurité Kubernetes peut avertir vos équipes de développement, de DevOps et de DevSecOps de problèmes de configuration potentiels concernant les applications avant qu'ils ne soient détectés par votre équipe de sécurité. Notre tableau de bord de sécurité Kubernetes permet aux analystes de comprendre avec précision quels processus se sont exécutés sur vos nœuds Kubernetes, à quel moment, avec quels paramètres d'exécution et avec quel compte. Cette visibilité inédite sur l'exécution permet de détecter les menaces de sécurité imprévues qui se sont introduites dans les couches de conteneurs utilisées comme dépendances dans vos applications conteneurisées.
Tout comme l'intégration Elastic APM, ces intégrations de sécurité sont ajoutées, configurées et supprimées via Fleet et s'exécutent à l'intérieur d'Elastic Agent dans le DaemonSet de chaque nœud de votre cluster Kubernetes.
Passons maintenant aux choses sérieuses !
Conditions
Vous aurez besoin d'un cluster Kubernetes sur lequel déployer vos applications, d'une instance Elastic Agent et du collecteur OpenTelemetry. Pour ma part, j'aime utiliser kOps pour créer, gérer et supprimer facilement des clusters de test dans les hyperscalers. À titre indicatif, un AWS EC2 t3.xlarge est suffisant pour déployer la version démo d'OpenTelemetry et notre instance Elastic Agent. Les exemples présentés ici devraient fonctionner avec n'importe quel cluster Kubernetes autogéré ou géré (par exemple, EKS, GKE) dans n'importe quel hyperscaler majeur ou sur site (par exemple, OpenShift). En théorie, ils devraient également fonctionner avec des clusters Kubernetes de bureau (comme MicroK8s ou le moteur Kubernetes intégré de Docker), sous réserve que vous fournissiez suffisamment de RAM ou de processeur à ces environnements (par exemple, 4 processeurs virtuels et 16 Go de RAM). Vous devrez aussi avoir des connaissances de base sur l'administration de Kubernetes (par exemple, déployer un fichier yaml, vérifier l'état d'un pod, consulter le log d'un pod). Avant de commencer, assurez-vous que votre contexte Kubernetes est associé au cluster approprié.
Vous aurez bien entendu besoin d'applications et de services que vous pourrez instrumenter avec OpenTelemetry. Pour démarrer, vous pouvez utiliser notre fork de la version démo d'OpenTelemetry. De là, vous pouvez appliquer nos bonnes pratiques pour instrumenter vos propres applications et services.
Pour finir, vous aurez besoin d'un accès à un déploiement Elasticsearch moderne (version 8.5 ou plus) avec lequel vous pourrez vous exercer (vous pouvez en créer un gratuitement dans notre cloud). Ce déploiement doit être accessible à partir de votre cluster d'application Kubernetes.
Outils
Dans ce tutoriel, on part du principe que vous utilisez un hôte basé sur Linux ou MacOS pour configurer votre cluster Kubernetes. Assurez-vous que les outils suivants sont installés :
Création de votre cluster Elasticsearch
Si vous avez déjà un déploiement Elasticsearch moderne avec lequel vous exercer, c'est super ! Dans le cas contraire, configurons-en un en créant un cluster de test gratuitement sur cloud.elastic.co.
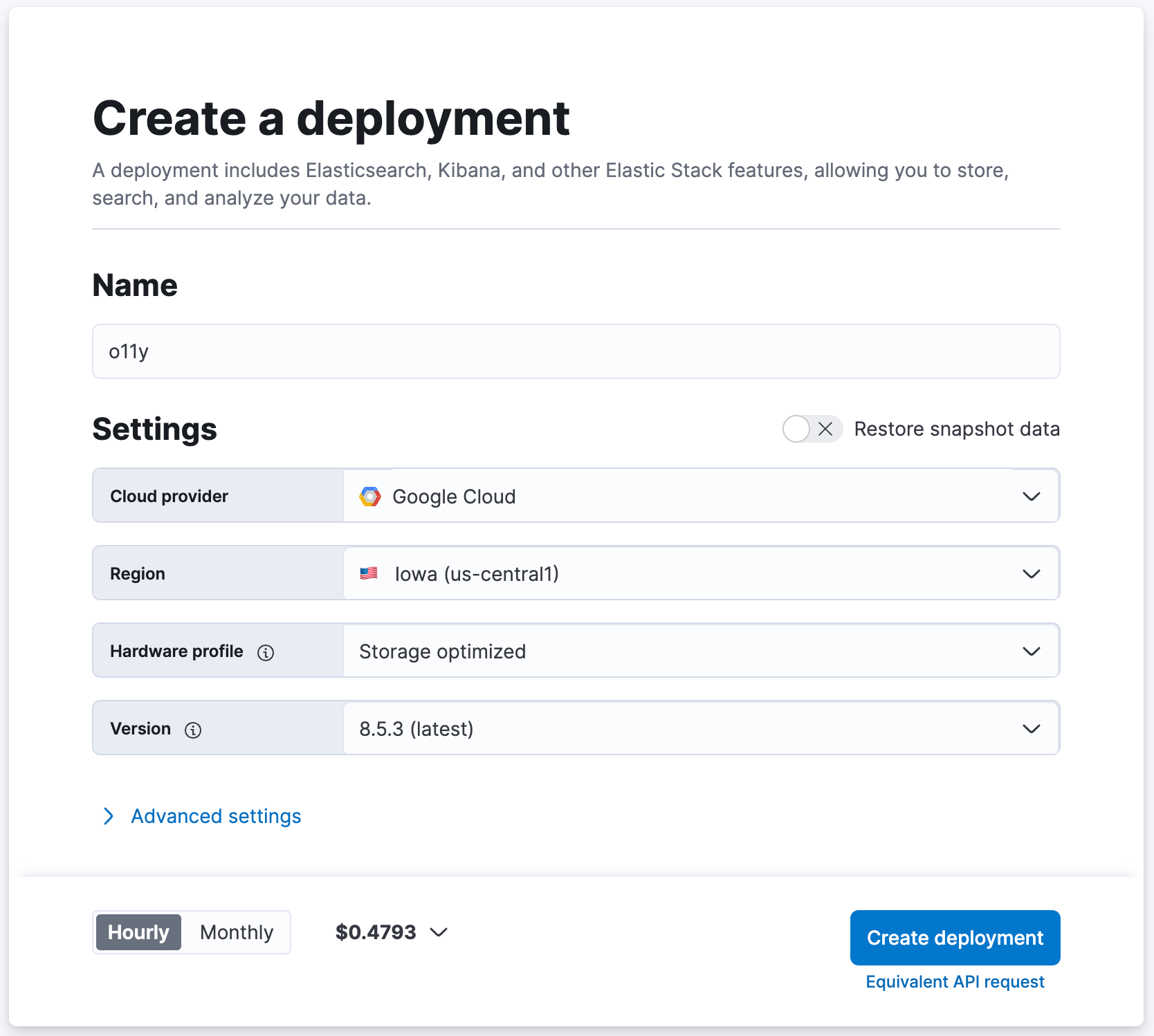
- Accédez à cloud.elastic.co pour vous connecter et bénéficier d'un essai gratuit (pas besoin de carte bancaire).
- Donnez un nom à votre cluster Elasticsearch, "o11y" par exemple, et laissez les autres paramètres sur leurs valeurs par défaut.
- Cliquez sur [Create Deployment] (Créer un déploiement).
- Attendez jusqu'à ce qu'Elasticsearch Cloud vous indique que votre déploiement est prêt.
- Cliquez sur [Continue] (Continuer) pour vous connecter à Kibana.
Déploiement d'Elastic Agent sur le DaemonSet
Nous allons utiliser l'instance Elastic Agent (avec des intégrations) installée sur le DaemonSet de chaque nœud de votre cluster Kubernetes pour ingérer des données dans Elasticsearch.
1. Téléchargez le fichier YAML suivant (mentionné ici) sur votre machine locale. Ce fichier YAML nous permettra de déployer Elastic Agent (avec Elastic Defend) dans le DaemonSet de vos nœuds Kubernetes.
curl -L -O https://raw.githubusercontent.com/elastic/endpoint/main/releases/8.5.0/kubernetes/deploy/elastic-defend.yaml
2. Téléchargez le correctif suivant sur votre machine locale. Ce correctif renforce les allocations par défaut de RAM et de processeur des conteneurs d'Elastic Agent pour prendre confortablement en charge toutes les intégrations que nous allons installer. En production, vous pouvez décider de ne déployer qu'un sous-ensemble des intégrations ci-dessous (cette modification sera alors inutile).
curl -L -O https://raw.githubusercontent.com/ty-elastic/elastic-otel-k8s/main/agent/8.5.0/elastic-defend.yaml.patch
3. Appliquez le correctif.
patch elastic-defend.yaml elastic-defend.yaml.patch
4. Vérifiez que vous êtes bien connecté à Kibana dans votre cluster Elasticsearch.
5. Accédez à [Management/Fleet] (Gestion/Fleet).
6. Cliquez sur [Add agent] (Ajouter un agent).
7. Donnez un nom à la nouvelle règle, "k8s-apps" par exemple.
- La règle "k8s-apps" sera utilisée ici pour déployer les intégrations vers le DaemonSet des nœuds dans le cluster Kubernetes de votre application.
8. Sous [Advanced options] (Options avancées), définissez [Unenrollment timeout] (Expiration de la désinscription) sur "3600" secondes.
- Kubernetes peut créer et supprimer des nœuds de manière dynamique ; ce paramètre garantira que les instances Elastic Agent déployées sur des nœuds supprimés soient automatiquement éliminées.
9. Cliquez sur [Create policy] (Créer une règle).
10. Sous [Install Elastic Agent on your host] (Installer Elastic Agent sur votre hôte), sélectionnez "Kubernetes".
11. Trouvez la valeur de la variable "FLEET_URL" et copiez-la à l'emplacement correspondant dans le fichier "elastic-defend.yaml" que vous avez précédemment téléchargé et auquel vous avez appliqué le correctif.
12. Trouvez la valeur de la variable "FLEET_ENROLLMENT_TOKEN" et copiez-la à l'emplacement correspondant dans le fichier "elastic-defend.yaml" que vous avez précédemment téléchargé et auquel vous avez appliqué le correctif.
13. Appliquez le fichier elastic-defend.yaml à votre cluster via :
kubectl apply -f elastic-defend.yaml
14. Attendez que [Confirm agent enrollment] (Confirmer l'inscription de l'agent) affiche le message : "1 agent has been enrolled" (1 agent a été inscrit).
15. Attendez que [Incoming data confirmed] (Données entrantes confirmées) affiche le message : "Incoming data received from 1 of 1 recently enrolled agent" (Données entrantes reçues de 1 agent récemment inscrit sur 1).
16. Cliquez sur "Fermer".
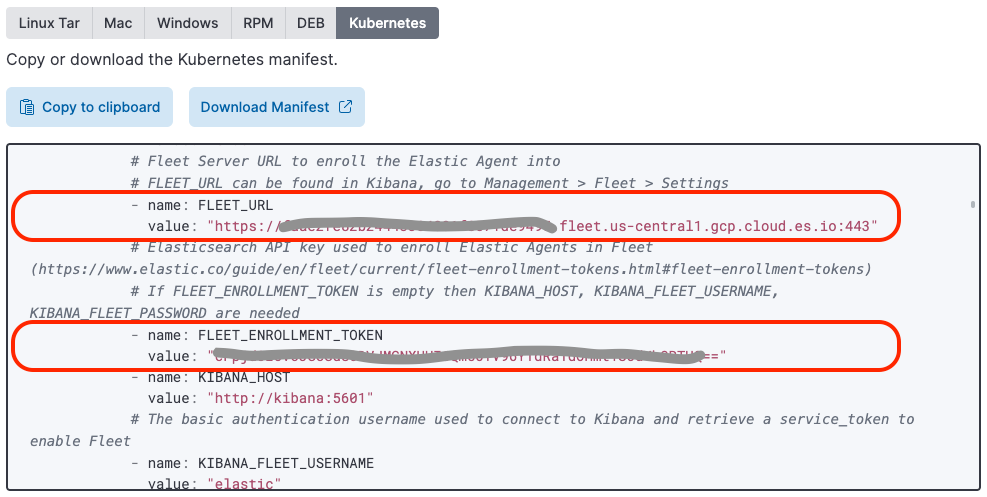
Vous avez peut-être remarqué qu'Elastic fournit un fichier YAML préconfiguré de déploiement d'Elastic Agent lorsque vous sélectionnez l'hôte Kubernetes. Ce fichier YAML de déploiement n'inclut pas encore d'image d'Elastic Defend.
Définition des intégrations d'Elastic Agent
À partir de maintenant, c'est un jeu d'enfants. Avec une instance Elastic Agent gérée par Fleet et déployée sur votre DaemonSet, il est extrêmement simple d'ajouter/configurer/supprimer des intégrations à distance à l'aide de l'interface d'intégrations Kibana.
APM

L'intégration Elastic APM sert à importer les données APM d'OpenTelemetry dans Elastic.
- Dans Kibana, accédez à [Management/Integrations] (Gestion/Intégrations).
- Recherchez "APM".
- Cliquez sur [APM].
- Cliquez sur [Manage APM integration in Fleet] (Gérer l'intégration APM dans Fleet).
- Cliquez sur [Add Elastic APM] (Ajouter Elastic APM).
- Définissez [General/Server configuration/Host] (Général/Configuration de serveur/Hôte) sur "0.0.0.0:8200". Cela permet à l'intégration APM d'ingérer des données d'autres pods du nœud (y compris le collecteur OpenTelemetry, qui s'exécute également dans le DaemonSet).
- Désactivez [Agent authorization/Anonymous Agent access] (Autorisation d'agent/Accès à un agent anonyme). En procédant ainsi, le collecteur OpenTelemetry peut envoyer des données OTEL à l'intégration Elastic APM sans token d'autorisation (plus spécifiquement, l'intégration APM n'est pas exposée en dehors du nœud).
- Si vous le souhaitez, activez [Tail-based sampling] (Échantillonnage en aval). Vous pourrez ainsi procéder à un sous-échantillonnage intelligent des données de trace pour capturer les anomalies et les performances globales tout en réduisant les besoins de stockage.
- Définissez [Where to add this integration] (Où ajouter cette intégration) sur "Existing hosts" (Hôtes existants), puis paramétrez [Agent policy] (Règle d'agent) sur "k8s-apps".
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Cliquez sur [Save and deploy changes] (Enregistrer et déployer les changements).
Kubernetes
Déploiement de kube-state-metrics
L'intégration Kubernetes nécessite que l'agent kube-state-metrics soit disponible dans votre cluster Kubernetes pour que les tableaux de bord Kubernetes prêts à l'emploi soient activés.
1. Ajoutez le référentiel helm kube-state-metrics.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
2. Placez kube-state-metrics sur votre cluster Kubernetes dans le même espace de nom qu'Elastic Agent (qui, à l'aide du fichier yaml de déploiement fourni pour Elastic Agent, est défini par défaut sur "kube-system").
helm install --set namespaceOverride=kube-system kube-state-metrics prometheus-community/kube-state-metrics
Installation de l'intégration Kubernetes
L'intégration Kubernetes Elastic est utilisée pour importer des indicateurs et des logs Kubernetes dans Elasticsearch.
- Dans Kibana, accédez à [Management/Integrations] (Gestion/Intégrations).
- Recherchez "Kubernetes".
- Sélectionnez [Kubernetes].
- Cliquez sur [Add Kubernetes] (Ajouter Kubernetes).
- Activez [Collect Kubernetes metrics from kube-state-metrics] (Collecter des indicateurs Kubernetes à partir de kube-state-metrics) si cela n'est pas déjà fait.
- Définissez [Where to add this integration] (Où ajouter cette intégration) sur "Existing hosts" (Hôtes existants), puis paramétrez [Agent policy] (Règle d'agent) sur "k8s-apps".
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Cliquez sur [Save and deploy changes] (Enregistrer et déployer les changements).
Elastic Defend
L'intégration Elastic Defend sert à protéger vos nœuds Kubernetes et à collecter des données d'observabilité supplémentaires axées sur la sécurité.
- Dans Kibana, accédez à [Management/Integrations] (Gestion/Intégrations).
- Recherchez "Elastic Defend".
- Sélectionnez [Elastic Defend].
- Cliquez sur [Add Elastic Defend] (Ajouter Elastic Defend).
- Définissez [Integration name] (Nom de l'intégration) sur "defend-1".
- Accédez à [Select configuration settings] (Sélectionner les paramètres de configuration), définissez [Select the type of environment you want to protect] (Sélectionner le type d'environnement à protéger) sur "Cloud Workloads (Linux servers or Kubernetes environments)" (Charges de travail cloud (serveurs Linux ou environnements Kubernetes)), puis définissez [To reduce data ingestion volume, select Interactive only] (Pour réduire le volume d'ingestion de données, sélectionner Interactif uniquement) sur "All events" (Tous les événements).
- Définissez [Where to add this integration] (Où ajouter cette intégration) sur "Existing hosts" (Hôtes existants), puis paramétrez [Agent policy] (Règle d'agent) sur "k8s-apps".
- Si votre cluster Kubernetes ne s'exécute pas sur GKE ou EKS, sous [Advanced options] (Options avancées), définissez [Namespace] (Espace de nom) sur "k8sapps" par exemple, où "k8sapps" est le nom de votre cluster Kubernetes d'application (il est nécessaire d'étiqueter les données télémétriques d'Elastic Defend avec le nom du cluster Kubernetes qu'elles concernent).
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Sélectionnez [Settings] (Paramètres).
- Accédez à [Elastic Defend version] (Version d'Elastic Defend) et activez "Keep integration policies up to date automatically" (Mettre automatiquement à jour les règles des intégrations).
- Sélectionnez [Integration policies] (Règles d'intégration) et cliquez sur [defend-1].
- Accédez à [Type: Operating system/Event Collection: Linux] (Type : Système d'exploitation/Collecte d'événements : Linux) et activez [Capture terminal output] (Capturer la sortie du terminal).
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Cliquez sur [Save and deploy changes] (Enregistrer et déployer les changements).
Certains tableaux de bord Elasticsearch Kubernetes ont besoin de connaître le nom de votre cluster Kubernetes et son identifiant. Si votre cluster s'exécute sur GKE ou EKS, Elastic Agent obtiendra automatiquement ces métadonnées. Si vous exécutez un cluster Kubernetes autogéré, vous pouvez créer un pipeline d'ingestion pour ajouter aux événements de sécurité les champs orchestrator.cluster.name et orchestrator.cluster.id, lesquels sont automatiquement définis à partir de l'espace de nom de règle que vous avez défini précédemment.
- Accédez à [Management/Dev Tools] (Gestion/Outils de développement).
- Exécutez la commande suivante :
PUT _ingest/pipeline/logs-endpoint.events.process@custom
{
"processors": [
{
"set": {
"field": "orchestrator.cluster.name",
"copy_from": "data_stream.namespace",
"ignore_empty_value": true,
"ignore_failure": true
}
},
{
"set": {
"field": "orchestrator.cluster.id",
"copy_from": "data_stream.namespace",
"ignore_empty_value": true,
"ignore_failure": true
}
}
]
}Gestion de la posture de sécurité Kubernetes
L'intégration de gestion de la posture de sécurité Kubernetes Elastic sert à valider votre cluster Kubernetes et vos applications par rapport aux bonnes pratiques pour une configuration Kubernetes sécurisée, conformément à la définition du Centre pour la sécurité Internet (CIS). Vos équipes de développement et de déploiement peuvent ainsi repérer les erreurs de configuration avant qu'elles n'entraînent une violation de la sécurité.
- Dans Kibana, accédez à [Management/Integrations] (Gestion/Intégrations).
- Recherchez "Kubernetes Security Posture Management" (Gestion de la posture de sécurité Kubernetes).
- Sélectionnez [Kubernetes Security Posture Management] (Gestion de la posture de sécurité Kubernetes).
- Cliquez sur [Add Kubernetes Security Posture Management] (Ajouter la gestion de la posture de sécurité Kubernetes).
- Définissez [Kubernetes Deployment] (Déploiement Kubernetes) sur "Unmanaged Kubernetes" (Kubernetes non géré) (pour les versions de Kubernetes autogérées) ou "EKS (Elastic Kubernetes Service)" si votre cluster d'application Kubernetes s'exécute spécifiquement sur AWS EKS
- Définissez [Where to add this integration] (Où ajouter cette intégration) sur "Existing hosts" (Hôtes existants), puis paramétrez [Agent policy] (Règle d'agent) sur "k8s-apps".
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Cliquez sur [Save and deploy changes] (Enregistrer et déployer les changements).
Capture de paquets réseau

L'intégration de capture de paquets réseau Elastic permet d'obtenir des informations sur le trafic réseau qui entre et qui sort de vos nœuds Kubernetes.
- Dans Kibana, accédez à [Management/Integrations] (Gestion/Intégrations).
- Recherchez "Network Packet Capture" (Capture de paquets réseau).
- Sélectionnez [Network Packet Capture] (Capture de paquets réseau).
- Cliquez sur [Add Network Packet Capture] (Ajouter la capture de paquets réseau).
- Définissez [Where to add this integration] (Où ajouter cette intégration) sur "Existing hosts" (Hôtes existants), puis paramétrez [Agent policy] (Règle d'agent) sur "k8s-apps".
- Cliquez sur [Save and continue] (Enregistrer et continuer).
- Cliquez sur [Save and deploy changes] (Enregistrer et déployer les changements).
Instrumentation avec OpenTelemetry
J'ai optimisé la version démo d'OpenTelemetry et les charts Helm d'OpenTelemetry pour l'observabilité Elastic (voir la section Instrumentation de vos propres applications pour comprendre ce qui a changé et pourquoi). Si vous souhaitez simplement utiliser les applications proposées dans la version démo d'OpenTelemetry pour comprendre la valeur ajoutée qu'apporte Elastic en ce qui concerne l'observabilité et la sécurité de Kubernetes, lisez la section Configuration de la version démo d'OpenTelemetry. Sinon, si vous souhaitez observer vos propres applications et services, prenez connaissance des conseils indiqués dans la section Instrumentation de vos propres applications.
Configuration de la version démo d'OpenTelemetry
Dans cette section, on part du principe que vous souhaitez déployer et observer les applications déjà instrumentées dans la version démo d'OpenTelemetry. Nous utiliserons un chart Helm modifié d'OpenTelemetry, qui déploie à la fois les applications de démo et une instance du collecteur OpenTelemetry.
1. Ajoutez notre référentiel helm.
helm repo add elastic-open-telemetry https://ty-elastic.github.io/opentelemetry-helm-charts
helm repo update
2. Installez les applications de démo et le collecteur dans votre cluster Kubernetes.
helm install elastic-otel elastic-open-telemetry/opentelemetry-demo
3. Vérifiez l'installation en dressant une liste des pods en cours d'exécution.
kubectl get pods
Vous devriez voir tous les pods de démo d'OpenTelemetry, ainsi qu'une instance du collecteur OpenTelemetry :
> kubectl get pods
NAME READY STATUS RESTARTS AGE
elastic-otel-adservice-86b5b4f779-8lsgf 1/1 Running 0 3h28m
elastic-otel-cartservice-55659bd5f4-lvtjx 1/1 Running 0 3h28m
elastic-otel-checkoutservice-88bfcf745-42nvt 1/1 Running 0 3h28m
elastic-otel-currencyservice-659dd55fc8-pcrrx 1/1 Running 0 3h28m
elastic-otel-emailservice-64df788455-mkb56 1/1 Running 0 3h28m
elastic-otel-featureflagservice-6dcf49d84c-n5jtk 1/1 Running 0 3h28m
elastic-otel-ffspostgres-67dcd7596d-htbpm 1/1 Running 0 3h28m
elastic-otel-frontend-674c8fdc74-zmv8r 1/1 Running 0 3h28m
elastic-otel-frontendproxy-5bd757dc89-r2728 1/1 Running 0 3h28m
elastic-otel-loadgenerator-5b98bd9656-8z8hz 1/1 Running 0 3h28m
elastic-otel-otelcol-agent-kbb54 1/1 Running 0 3h28m
elastic-otel-paymentservice-5c4b5c57bd-wkbqj 1/1 Running 0 3h28m
elastic-otel-productcatalogservice-6995496975-7wm46 1/1 Running 0 3h28m
elastic-otel-quoteservice-849797dfdd-bkj29 1/1 Running 0 3h28m
elastic-otel-recommendationservice-6cb4476f-zpqqv 1/1 Running 0 3h28m
elastic-otel-redis-5698bf675b-dl2xv 1/1 Running 0 3h28m
elastic-otel-shippingservice-6b9fdcc467-knlxb 1/1 Running 0 3h28m4. Passez à l'étape Validation et observation pour confirmer que vos traces d'applications, indicateurs et événements affluent dans Elasticsearch.
Instrumentation de vos propres applications avec OpenTelemetry
Dans cette section, on part du principe que vous allez instrumenter vos propres applications avec OpenTelemetry. Pour que vos applications fonctionnent avec le modèle de déploiement présenté dans cet article, elles devront :
- être instrumentées avec une version stable de l'agent APM d'OpenTelemetry ;
- être instanciées avec des variables d'environnement OpenTelemetry spécifiques ;
- si une instrumentation manuelle est utilisée, avoir des propriétés d'intervalle définies de façon appropriée ;
- ajouter facultativement des métadonnées spécifiques à des lignes de log ;
- émettre les données de log vers stdout et stderr pour qu'elles soient capturées par l'intégration Kubernetes Elastic.
Variables d'environnement de conteneurs
Pour activer les tableaux de bord APM prêts à l'emploi d'Elastic, nous devons nous assurer que les traces d'applications, les indicateurs et les événements sont accompagnés de métadonnées contextuelles appropriées. Nous pouvons obtenir ces métadonnées à partir de l'API Kubernetes Downward, qui les transfère dans l'application via la variable d'environnement OTEL_RESOURCE_ATTRIBUTES.
Nous devons aussi configurer OTEL_EXPORTER_OTLP_ENDPOINT pour ordonner aux applications d'envoyer leurs données OpenTelemetry via OTLP vers l'instance du collecteur OpenTelemetry que nous déploierons ultérieurement dans le DaemonSet du nœud.
L'extrait de configuration de conteneurs Kubernetes ci-dessous définit les variables d'environnement qu'il faudra attribuer à vos applications dans leur fichier YAML de déploiement.
---
apiVersion: apps/v1
kind: Deployment
...
spec:
...
template:
...
spec:
containers:
...
env:
- name: OTEL_K8S_CONTAINER_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: "metadata.labels['app.kubernetes.io/component']"
- name: OTEL_K8S_NODE_IP
valueFrom:
fieldRef:
fieldPath: status.hostIP
- name: OTEL_K8S_POD_UID
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.uid
- name: OTEL_K8S_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: OTEL_SERVICE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: "metadata.labels['app.kubernetes.io/component']"
- name: OTEL_K8S_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: OTEL_K8S_NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: OTEL_K8S_POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: '$(OTEL_K8S_NODE_IP):4317'
- name: OTEL_RESOURCE_ATTRIBUTES
value: service.name=$(OTEL_SERVICE_NAME),k8s.namespace.name=$(OTEL_K8S_NAMESPACE),k8s.node.name=$(OTEL_K8S_NODE_NAME),k8s.pod.name=$(OTEL_K8S_POD_NAME),k8s.pod.uid=$(OTEL_K8S_POD_UID),k8s.pod.ip=$(OTEL_K8S_POD_IP),k8s.container.name=$(OTEL_K8S_CONTAINER_NAME),k8s.container.restart_count=0Vous vous demanderez peut-être pourquoi nous définissons k8s.container.restart_count=0 en tant qu'attribut de ressource. Le processeur k8sattrribute actuel du collecteur OpenTelemetry a recours à cette astuce pour faire correspondre un conteneur (via k8s.container.name) à une instance en cours d'exécution d'un conteneur pour obtenir un container.id. Le fait de paramétrer k8s.container.restart_count=0 facilite les choses : il serait en effet difficile de suivre le nombre de fois où un conteneur donné a été redémarré par Kubernetes dans un pod et d'insérer cette information dans une variable d'environnement. En général, un conteneur est démarré une seule fois au cours de la durée de vie d'un pod. Mais il peut y avoir des cas où un conteneur est redémarré par un pod. Dans cette situation, le paramétrage ci-dessus échouera.
Propriétés d'intervalle
Certaines propriétés d'intervalle doivent être explicitement définies pour qu'Elastic APM puisse caractériser, classer et visualiser correctement les données d'intervalle. La plupart des bibliothèques d'auto-instrumentation APM d'OpenTelemetry configureront ces champs pour vous. En revanche, si vous instrumentez manuellement votre application, vous devrez définir explicitement les propriétés suivantes :SpanKind: Pour qu'Elastic APM puisse classer correctement les intervalles, l'outil a besoin de connaître la valeur de SpanKind (par exemple, INTERNAL, SERVER, CLIENT). La plupart des bibliothèques d'auto-instrumentation APM d'OpenTelemetry configureront ce champ pour vous. En revanche, si vous instrumentez manuellement votre application, vous devrez définir SpanKind sur SERVER pour les intervalles qui acceptent les appels RPC ou REST, sur CLIENT pour les intervalles qui lancent les appels RPC, REST ou de bases de données, et sur INTERNAL (par défaut) pour les appels de fonction au sein d'un service. Dans Java, par exemple, il faudrait définir SpanKind sur SERVER pour un intervalle recevant un appel gRPC, en utilisant une formule similaire à celle qui suit :
Span span = tracer.spanBuilder("testsystem.TestService/TestFunction").setSpanKind(SpanKind.SERVER).startSpan();RpcSystem/DbSystem : Pour qu'Elastic APM puisse classer correctement les intervalles, il doit savoir si l'intervalle représente une transaction RPC ou une transaction de base de données, et de là, connaître le système RPC ou de base de données utilisé. La plupart des bibliothèques d'auto-instrumentation APM d'OpenTelemetry configureront ce champ pour vous. Si vous instrumentez manuellement votre application, vous devrez définir l'attribut d'intervalle RpcSystem ou DbSystem. Dans Rust, par exemple, il faudrait définir RpcSystem sur "grpc" pour un intervalle recevant un appel gRPC, en utilisant une formule similaire à celle qui suit :
span.set_attribute(semcov::trace::RPC_SYSTEM.string("grpc"));NetPeerHost et NetPeerPort : Pour qu'Elastic APM puisse cartographier correctement les dépendances existant entre les services, lorsque SpanKind est défini sur CLIENT (i.e. un appel gRPC ou de base de données sortant), les attributs d'intervalle NetPeerName et NetPeerPort doivent être définis pour indiquer le destinataire prévu de l'appel. Certaines bibliothèques d'auto-instrumentation APM d'OpenTelemetry configureront ce champ pour vous. Si vous instrumentez manuellement votre application, vous devez définir explicitement ces attributs. Dans JavaScript, par exemple, il faudrait définir NetPeerName et NetPeerPort sur un intervalle envoyant un appel gRPC, en utilisant une formule similaire à celle qui suit :
// this => grpcJs.Client, this.getChannel().getTarget() => "dns:elastic-otel-productcatalogservice:8080"
const URI_REGEX = /(?:([A-Za-z0-9+.-]+):(?:\/\/)?)?(?<name>[A-Za-z0-9+.-]+):(?<port>[0-9+.-]+)$/;
const parsedUri = URI_REGEX.exec(this.getChannel().getTarget());
if (parsedUri != null && parsedUri.groups != null) {
span.setAttribute(SemanticAttributes.NET_PEER_NAME, parsedUri.groups['name']);
span.setAttribute(SemanticAttributes.NET_PEER_PORT, parseInt(parsedUri.groups['port']));
}Attributs de log
Elastic APM peut mettre en corrélation des lignes de log spécifiques avec des traces spécifiques. Pour activer cette fonctionnalité, les lignes de log venant de votre application doivent être étiquetées avec des paires clé/valeur span.id et trace.id lorsque cela s'avère nécessaire. Certains des agents Elastic APM (par exemple, l'agent Java) modifieront automatiquement votre modèle de logging pour ajouter ces métadonnées contextuelles.
Déploiement du collecteur OpenTelemetry dans le DaemonSet
Si vous suivez cette procédure avec la version démo d'OpenTelemetry et nos charts Helm d'OpenTelemetry modifiés, un collecteur OpenTelemetry optimisé a déjà été installé pour vous dans le DaemonSet de chaque nœud.
Si vous instrumentez vos propres applications, vous pouvez utiliser le fichier YAML suivant comme base pour configurer et déployer le collecteur OpenTelemetry dans le DaemonSet des nœuds de votre cluster. La configuration idéale (déployée à l'aide d'une ConfigMap) ingère les données de traces OTLP, d'indicateurs et d'événements à partir des applications sur les ports TCP 4317 (grpc) et 4318 (http). Étant donné que le collecteur s'exécute dans le DaemonSet, ce port est accessible à partir d'autres pods s'exécutant sur le même nœud via l'IP du nœud. Les données OTLP entrantes sont revues par le processeur k8attributes pour y ajouter le container.id. Nous écartons toute donnée de log qui pourrait arriver (rappelez-vous que nous obtenons ces données par l'intermédiaire de l'intégration Kubernetes Elastic), et acheminons les traces, événements et indicateurs vers l'intégration Elastic APM qui s'exécute également sur le DaemonSet. Le port d'écoute de l'intégration Elastic APM est le port 8200, qui est également accessible via l'IP du nœud (acheminée ici comme une variable d'environnement obtenue à partir de l'API Kubernetes Downward).
1. Téléchargez ce fichier YAML de déploiement type du collecteur OpenTelemetry.
curl -L -O https://raw.githubusercontent.com/ty-elastic/elastic-otel-k8s/main/collector/otel-collector.yaml
2. Modifiez-le selon vos besoins pour votre déploiement.
3. Appliquez-le à votre cluster Kubernetes.
kubectl apply -f otel-collector.yaml
Validation et observation
Dans cette section, nous allons confirmer que les données d'observabilité et de sécurité que nous avons configurées ci-dessus proviennent de notre cluster Elasticsearch comme prévu. Cet exercice servira aussi à présenter rapidement quelques-uns des tableaux de bord d'observabilité et de sécurité prêts à l'emploi, mis à votre disposition dans Elasticsearch. Nous vous invitons à vous en servir comme un tremplin pour explorer notre vaste gamme d'offres en matière de visualisation et d'analyse.
Carte de service d'APM
La carte de service d'APM propose une visualisation de vos services et de leurs relations les uns avec les autres. Certains types d'erreurs de service et d'alertes seront également mis en évidence sur cette carte le cas échéant. À partir de cette carte, vous pouvez accéder à une vue détaillée de n'importe quel service instrumenté avec OpenTelemetry (ou avec l'agent APM d'Elastic).
- Dans la barre latérale de navigation de Kibana, sous [Observability] (Observabilité), sélectionnez [APM].
- Sous [APM], sélectionnez [Service Map] (Carte de service).
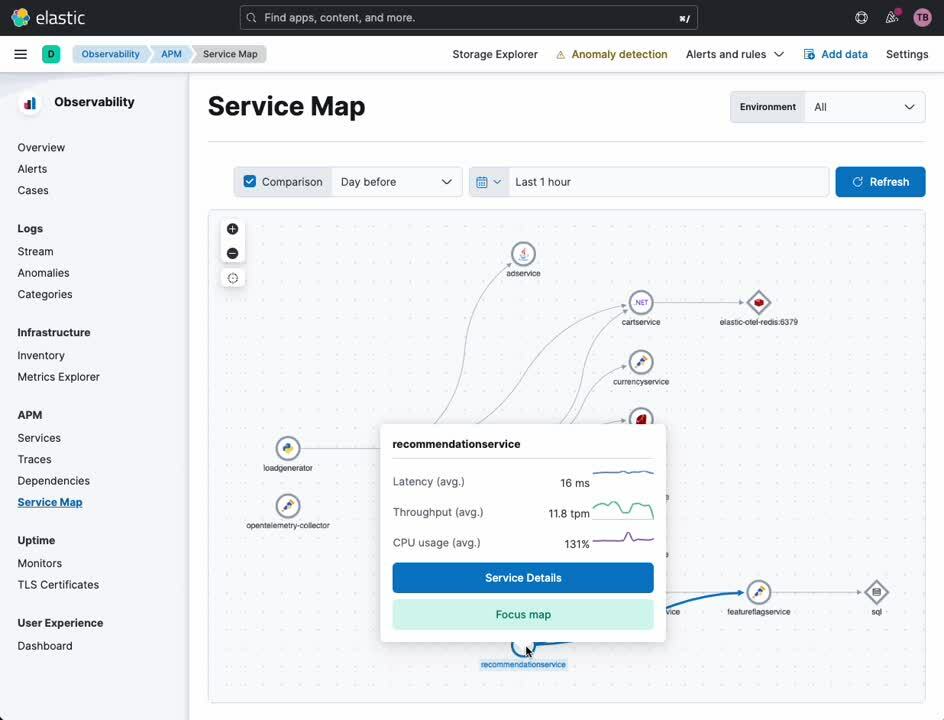
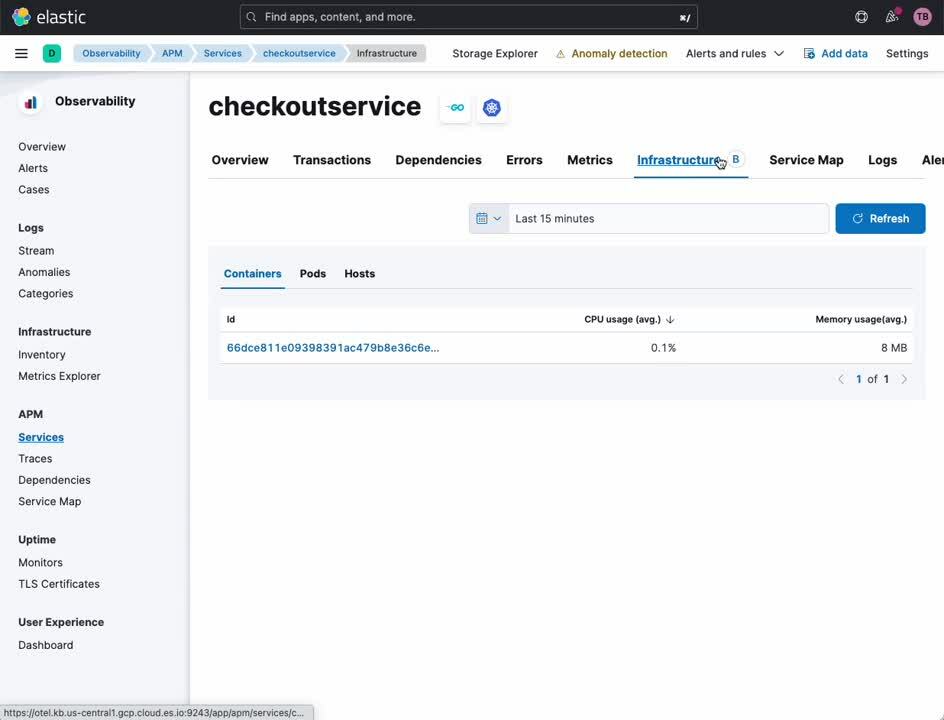
Service d'APM
L'onglet APM Service (Service d'APM) vous donne un aperçu d'un service donné. À partir de ce tableau de bord, vous pouvez facilement examiner les traces, logs et indicateurs d'infrastructure associés. Par le passé, il était nécessaire de convertir manuellement les horodatages et les identifiants de service sur des plateformes d'observabilité cloisonnées si l'on voulait mettre en corrélation ces sources de données de façon sommaire. Désormais, avec Elastic et OpenTelemetry, cette corrélation se fait automatiquement, ce qui permet aux analystes, aux opérateurs et aux développeurs de se concentrer sur l'analyse de la cause première, et non sur les nuances des différents outils d'observabilité.
- Dans la barre latérale de navigation de Kibana, sous [Observability] (Observabilité), sélectionnez [APM].
- Sous [APM], sélectionnez [Service Map] (Carte de service).
- Cliquez avec le bouton droit de la souris sur n'importe quel service de la carte.
- Sélectionnez [Service Details] (Détails du service).
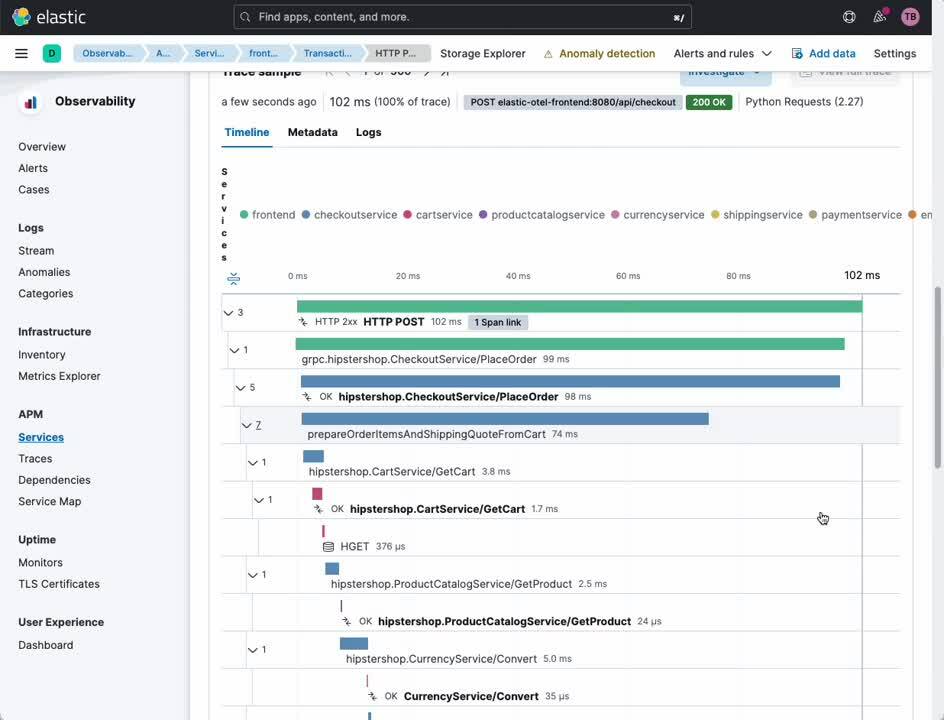
Dans la même vue, vous pouvez facilement passer de l'examen des transactions et intervalles qui connectent vos utilisateurs à vos services, aux relations qu'entretiennent les services les uns avec les autres.
- Sélectionnez [Transactions] dans l'en-tête.
- Sélectionnez une transaction qui vous intéresse dans la sous-section [Transactions].
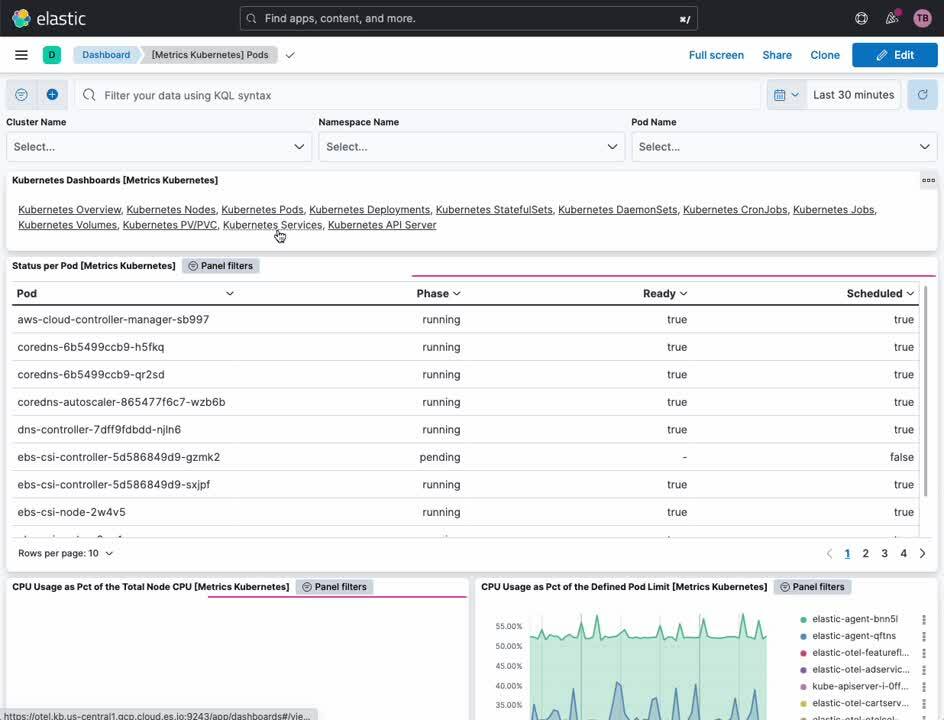
Indicateurs de cluster Kubernetes
Les tableaux de bord Kubernetes fournissent à la fois un aperçu général des opérations de votre cluster Kubernetes et une vue détaillée en la matière. De là, vous pouvez monitorer les indicateurs sur les clusters, les nœuds, les pods, les DaemonSets, les services et bien plus encore.
- Dans la barre latérale de navigation de Kibana, sous [Analytics] (Analytique), sélectionnez [Dashboard] (Tableau de bord).
- Dans le menu [Tags] (Étiquettes), sélectionnez [Kubernetes].
- Sélectionnez le tableau de bord [Cluster Overview] (Aperçu du cluster).
Monitoring des processus Kubernetes
L'intégration Elastic Defend fournit une observabilité axée sur la sécurité sur vos ressources Kubernetes. Le tableau de bord de sécurité Kubernetes permet aux analystes de comprendre avec précision quels processus se sont exécutés sur vos nœuds Kubernetes, à quel moment, avec quels paramètres d'exécution et avec quel compte.
- Dans la barre latérale de navigation de Kibana, sous [Security] (Sécurité), sélectionnez [Dashboards] (Tableaux de bord).
- Sélectionnez [Kubernetes].
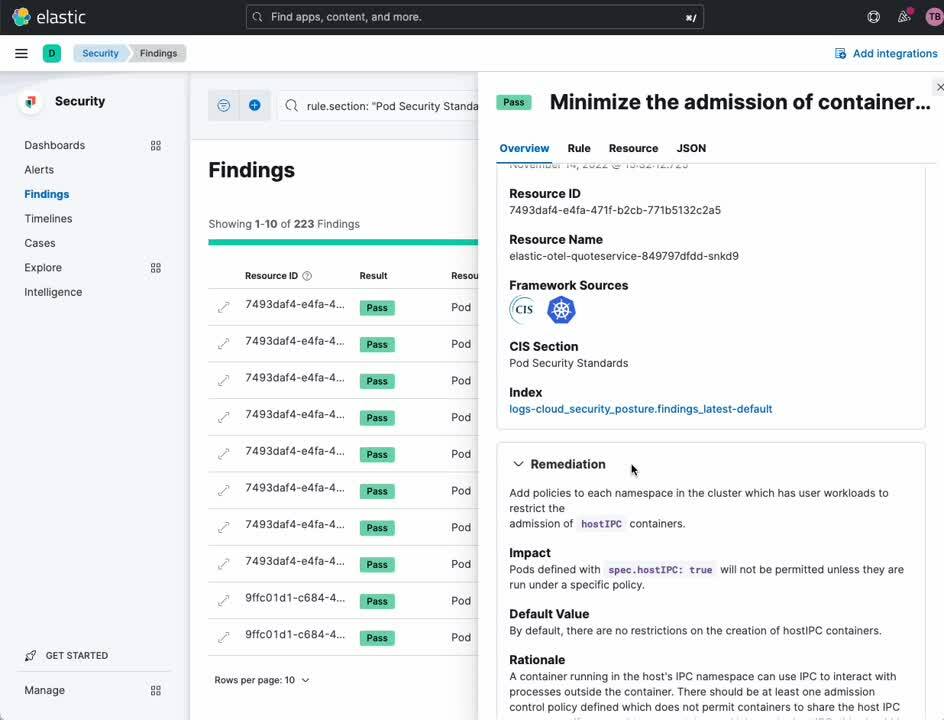
Gestion de la posture de sécurité Kubernetes
Le tableau de bord sur la gestion de la posture de sécurité Kubernetes (KSPM) fournit des recommandations automatisées en matière d'analyse et de résolution sur un éventail de bonnes pratiques Kubernetes en faveur d'un déploiement sécurisé. Pour les développeurs et les équipes DevOps, ce tableau de bord peut fournir une mine précieuse d'informations sur des problèmes de configuration potentiels avant qu'ils ne se concrétisent en production.
- Dans la barre latérale de navigation de Kibana, sous [Security] (Sécurité), sélectionnez [Dashboards] (Tableaux de bord).
- Sélectionnez [Cloud Posture] (Posture du cloud).
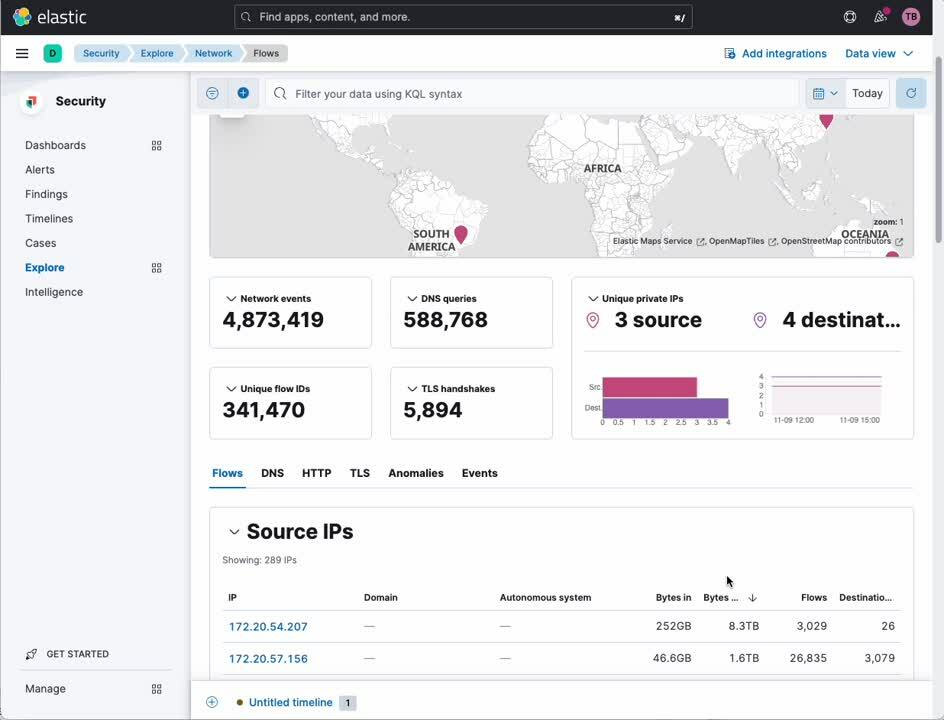
Analyse du trafic réseau
L'intégration de capture des paquets réseau vous permet de plonger dans les détails du trafic IP entrant et sortant de vos nœuds Kubernetes afin de repérer les services qui n'ont pas le comportement attendu ou les violations de sécurité.
- Dans la barre latérale de navigation de Kibana, sous [Security] (Sécurité), sélectionnez [Explore] (Explorer).
- Sélectionnez [Network] (Réseau).
Elastic : l'observabilité et la sécurité conçues pour Kubernetes
Kubernetes représente un modèle de déploiement d'application vierge pour de nombreuses entreprises. Un modèle de déploiement vierge nécessite une approche ouverte, moderne et holistique aussi bien pour l'observabilité que pour la sécurité. Comme nous venons de le voir, la plateforme Elastic occupe une position unique dans le secteur en assurant une observabilité et une sécurité totalement intégrées et extrêmement précises pour Kubernetes.
Envie d'en savoir plus ? Contactez notre équipe commerciale pour faire vos premiers pas avec Elastic !
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer