Elastic App Search passe aux moteurs de recherche multilingues
Vous pouvez optimiser votre moteur Elastic App Search pour une langue donnée en deux temps, trois mouvements. Nous nous lançons avec 13 langues, dont l'allemand, l'anglais, le chinois, le coréen, le danois, l'espagnol, le français, le japonais et le russe.
Très bien, mais quel impact sur la méthodologie sous-jacente ? En quoi cela améliorera-t-il l'expérience de recherche des internautes ? Ces nouveautés demandent-elles une configuration supplémentaire ? Autant de questions auxquelles nous répondons ci-dessous. Vous pouvez aussi jeter un œil à la documentation si vous êtes impatient de vous lancer sans attendre.
À vous de jouer pour analyser et générer des tokens
La recherche est une question d'analyse. La première analyse a lieu au moment de la création de votre index dans votre moteur de recherche. Au cours du processus d'indexation, le texte compris dans vos documents est converti en tokens. Chaque token est ensuite organisé par rapport à l'index et correspond à un terme.
Une fois l'index structuré, chaque requête de recherche est comparée à l'index. Le texte entrant est analysé, converti en tokens, puis comparé aux termes indexés. Plus les termes de la requête en entrée sont proches des termes indexés, plus la recherche sera pertinente.
Si vous utilisez Elasticsearch pour créer votre propre fonction de recherche, vous devrez peut-être configurer un – ou plusieurs – analyseurs personnalisés pour traiter au mieux les nuances de la langue en question. La méthode utilisée pour la création des tokens et de l'index terminologique est directement liée à la façon dont vous avez configuré votre analyseur ou votre ensemble d'analyseurs. Bien que dans la plupart des cas, vous puissiez intégrer un analyseur linguistique efficace à la création d'index assez simples, les configurations plus poussées nécessitent un réglage plus pointu des filtres de caractères, du générateur de tokens et des filtres de tokens.
Mais avec App Search, les choses sont beaucoup plus simples : vous disposez d'une solution optimisée et basée sur une API, qui n'attend plus que d'être intégrée dans votre application. Pour illustrer son fonctionnement, nous allons voir ci-dessous comment les moteurs de recherche App Search peuvent maintenant interpréter les caractères chinois.
Exit, les résultats de recherche sans queue ni tête
Par défaut, un moteur de recherche App Search est défini sur Universal, ce qui est une configuration idéale pour la plupart des recherches. Cependant, lorsque vous spécifiez une langue, le moteur de recherche App Search utilise alors un analyseur personnalisé qui est optimisé pour cette langue.
Par exemple, avec les paramètres Universal, la fonction de recherche est assez intelligente pour rechercher les termes tels qu'ils s'articulent dans un document, plutôt que de lancer une recherche distincte pour chaque terme. Par exemple, si vous lancez une recherche sur raquette``tennis, le moteur ne recherchera pas les termes raquette, puis tennis indépendamment l'un de l'autre. Il recherchera raquette tennis.
Si cela est utile en anglais, en français – ou encore avec les paramètres de recherche Universal – nous voyons dans l'exemple ci-dessous comme cela peut donner des résultats déconcertants dans d'autres langues.
Par exemple, ces deux caractères chinois expriment l'idée de salaire :
工资 : salaire
Cet idéogramme est composé de deux caractères différents, à savoir, travail et argent
工 : travail
资 : argent
Lorsqu'aucune langue n'est spécifiée pour l'analyse, le générateur de tokens sépare les deux caractères, qu'il associe à deux tokens différents, puis recherche des correspondances par rapport à ces deux tokens. Autrement dit, la recherche se fait de manière littérale, sans tenir compte de la syntaxe.
Dans le cas d'un utilisateur chinois qui lance une recherche sur salaire, on peut s'attendre à ce que le résultat obtenu corresponde à travail argent plutôt qu'à salaire. Avouons que cela peut être déconcertant.
En anglais ou en français, la recherche donnera des résultats qui tiennent compte de la relation qui existe entre travail argent, comme dans l'exemple raquette tennis. Mais en chinois, les deux caractères expriment un concept totalement différent.
Si on utilise l'analyseur chinois approprié, le système sait que 工资 est un bigramme (dans ce contexte, un groupe formé de deux mots). Il génère donc un seul token pour les deux termes, créant ainsi le terme correspondant à salaire dans l'index. Ainsi, le bigramme 工资 est maintenant associé à salaire, et non plus à travail argent. Le token combiné est plus significatif que ses différentes parties.
App Search parle votre langue… Et c'est simple comme bonjour
La configuration d'une langue donnée dans App Search est maintenant une étape simplissime de la création du moteur de recherche.
Lorsque vous créez votre moteur App Search via l'API App Search, une requête POST ressemble à ceci. Dans cet exemple, nous créons un nouveau moteur chinois (zh) appelé panda :
curl -X POST 'https://host-xxxxxx.api.swiftype.com/api/as/v1/engines' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer private-xxxxxxxxxxxxxxxxxxxx' \
-d '{
"name": "panda",
"language": "zh"
}'Les langues correspondent à un code de langue. Les codes suivent le standard RFC 5646 de l'IETF, qui correspond aux normes ISO 639-1 et ISO 3166-1.
Si vous préférez créer votre moteur via une interface utilisateur graphique (GUI), vous pouvez accéder au sélecteur de langues dès la première étape de la création du moteur. Vous pouvez aussi y accéder via le tableau de bord :
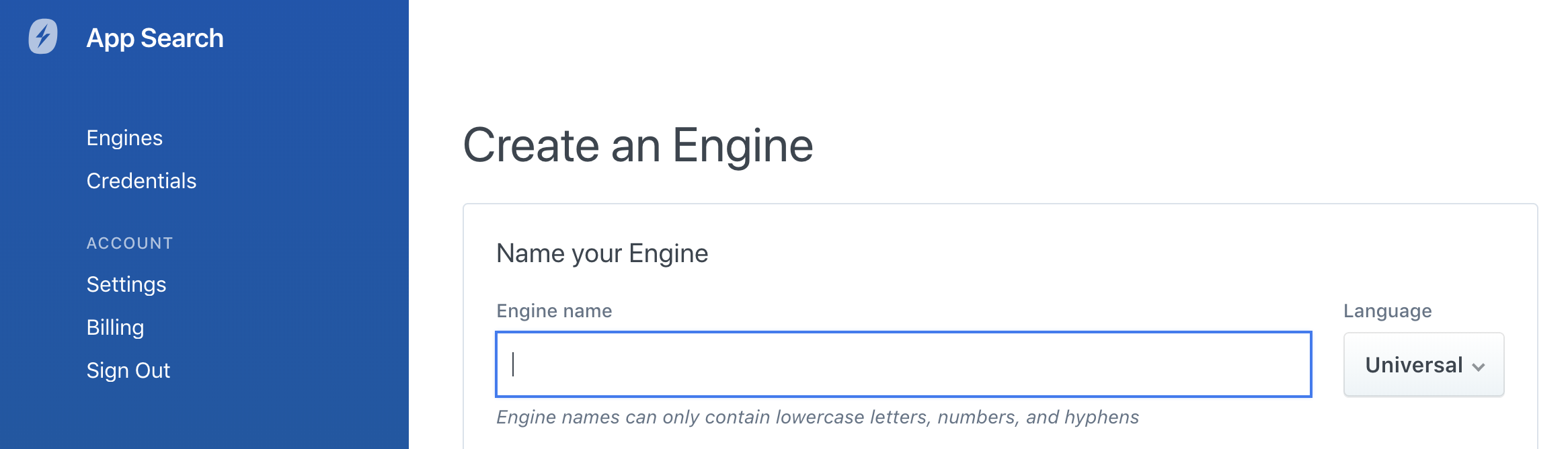
La langue pour laquelle le moteur de recherche est configuré s'affiche en haut à gauche, sous le nom du moteur. Si aucune langue ne s'affiche, c'est que le moteur est configuré sur Universal :
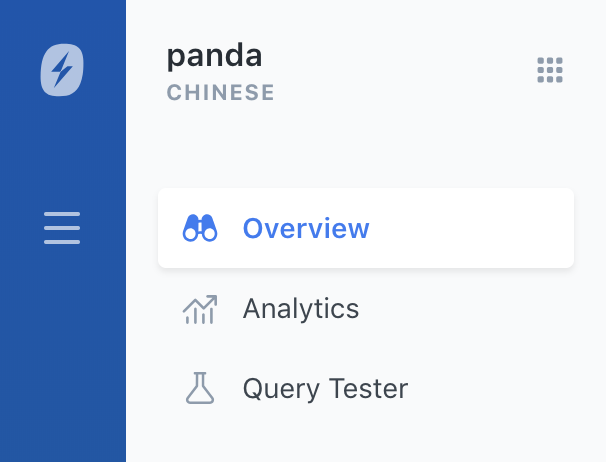
Maintenant que votre moteur de recherche est spécialisé dans une langue, vous vous demandez si vous avez d'autres configurations à faire. La réponse est non. Aucune. L'analyse avancée spécifique à la langue choisie a lieu chaque fois que des données sont indexées dans le moteur. Après quoi, les requêtes de recherche lancées dans cette langue appliqueront le même analyseur linguistique optimisé et pertinent que vous utilisez pour l'indexation.
Récapitulons
Même si nous nous limitions à une seule valeur, un seul type de données et une seule langue, la recherche serait encore un défi technique colossal. En réalité, la recherche est infiniment plus complexe : nous avons de nombreuses valeurs, une foule de types de données et un grand choix de langues à traiter. On se met alors à rêver de la recherche vertigineusement exacte, quels que soient la langue ou le type de données concernés, et d'un contexte prédit par le Machine Learning.
En attendant que ce rêve devienne réalité, Elastic App Search est un moyen efficace de booster la recherche dans vos applications. Avec 13 langues optimisées sous le capot, vous pouvez propulser votre moteur de recherche vers de nouveaux sommets et proposer une expérience de recherche de grande qualité. Le tout, via un tableau de bord intuitif et des API aussi simples que dynamiques. Envie de voir par vous-même si Elastic App Search est fait pour vous ? Vous pouvez vous inscrire pour un essai de 14 jours et voir ce que donnent nos API.
Mise à jour* : Elastic Site Search prend désormais en charge plusieurs langues. Saisissez votre domaine et sélectionnez votre langue. Le robot d'indexation Site Search Crawler se charge ensuite d'indexer vos pages. Une fois cela fait, il suffit d'installer l'extrait de code et de vous offrir une expérience de recherche hors pair.*