Lancement d'Elastic Common Schema
Nous lançons Elastic Common Schema (ECS), une nouvelle spécification permettant de structurer vos données Elasticsearch de manière cohérente et personnalisée, tout en facilitant l'analyse des données provenant de différentes sources. Avec ECS, vous pouvez étendre le champ d'application des contenus analytiques tels que les tableaux de bord et les tâches de machine learning, affiner le ciblage de vos recherches et utiliser des noms de champs bien plus simples à mémoriser.
Pourquoi un schéma commun ?
Que vos analyses soient interactives (recherche, visualisation, opérations de granularité et de restructuration comme "drill-down" et "pivot") ou qu'elles soient automatisées (alerting, détection des anomalies via Machine Learning), vous devez pouvoir examiner vos données de manière homogène. Mais à moins que vos données ne proviennent toutes d'une seule et même source, vous êtes confronté à des incohérences de formats, et ce, pour les raisons suivantes :
- Types de données disparates (logs, indicateurs, APM, flux, données contextuelles...)
- Environnements hétérogènes répondant à différentes normes selon les fournisseurs
- Sources de données comparables, mais néanmoins différentes (données de point de terminaison provenant de différentes sources, comme Auditbeat, Cylance et Tanium)
Imaginez que vous recherchiez un utilisateur parmi des données provenant de différentes sources. La recherche de ce seul champ vous oblige probablement à tenir compte des noms de plusieurs champs, comme user, username, nginx.access.user_name et login. Que dire des opérations de granularité et de restructuration des données comme "drill-down" et "pivot" dans de telles conditions ? Imaginez maintenant que vous ayez à développer un contenu analytique (visualisation, alerting ou tâche de machine learning, par exemple). Chaque nouvelle source de données devient synonyme de complexité ou de duplication.
Qu'est-ce que Elastic Common Schema ?
ECS est une spécification open source qui définit un ensemble commun de champs de documents pour les données ingérées dans Elasticsearch. Conçu pour prendre en charge une modélisation uniforme des données, ECS vous permet de centraliser l'analyse des données provenant de différentes sources, que la méthode employée soit interactive ou automatisée.
ECS vous offre à la fois la prévisibilité d'une taxonomie conçue à cette fin et la polyvalence d'une spécification inclusive, qui s'adapte aux cas d'utilisation personnalisés. La taxonomie d'ECS répartit les éléments de données entre différents champs organisés en trois niveaux :
| Niveau | Description | Recommendation |
| Champs ECS principaux | Ensemble de noms de champs entièrement défini, qui se trouve sous un ensemble défini d'objets ECS de premier niveau. | On rencontre ces champs dans la plupart des cas d'utilisation. C'est donc à ce niveau qu'il faut commencer. |
| Champs ECS étendus | Ensemble de noms de champs partiellement défini, qui se trouve sous le même ensemble d'objets ECS de premier niveau. | Les champs étendus peuvent s'appliquer aux cas d'utilisation restreints. Ils autorisent aussi une plus grande souplesse selon les cas d'utilisation. |
| Champs personnalisés | Ensemble de champs non défini et non nommé, qui se trouve sous un ensemble d'objets de premier niveau n'appartenant pas à ECS, fourni par l'utilisateur, et ne devant pas entrer en conflit avec les champs et objets ECS. | C'est à ce niveau que vous pouvez ajouter des champs pour lesquels ECS ne propose pas de champ correspondant. Vous pouvez aussi conserver ici une copie des champs d'événement d'origine (au moment de faire migrer vos données vers ECS, par exemple). |
Elastic Common Schema en action
1er exemple : Analyse
Voyons ce que peut faire ECS sur le log Apache ci-dessous :
10.42.42.42 - - [07/Dec/2018:11:05:07 +0100] "GET /blog HTTP/1.1" 200 2571 "-" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36"
Lorsqu'on mappe ce message à ECS, les champs du log s'organisent comme suit :
| Nom du champ | Valeur | Remarques |
| @timestamp | 2018-12-07T11:05:07.000Z
| |
| ecs.version | 1.0.0
| |
| event.dataset | apache.access
| |
| event.original | 10.42.42.42 - - [07/Dec ...
| Log complet et non modifié, à utiliser pour les audits |
| http.request.method | get
| |
| http.response.body.bytes | 2571
| |
| http.response.status_code | 200
| |
| http.version | 1.1
| |
| host.hostname | webserver-blog-prod
| |
| message | "GET /blog HTTP/1.1" 200 2571
| Représentation textuelle des informations importantes de l'événement, qui s'affichent sous forme de résumé succinct via une visionneuse de log. |
| service.name | Company blog
| Le nom que vous avez choisi pour ce service. |
| service.type | apache
| |
| source.geo.* | Champs servant à la géolocalisation. | |
| source.ip | 10.42.42.42
| |
| url.original | /blog
| |
| user.name | -
| |
| user_agent.* | Champs décrivant l'agent utilisateur. |
Comme illustré ci-dessus, le log brut est conservé dans le champ event.original d'ECS à des fins d'audit. Remarque : Pour simplifier, cet exemple ne tient pas compte des informations relatives à l'agent Monitoring (qui apparaissent sous agent.*), ni de celles relatives à l'hôte (qui apparaissent sous host.*) et n'affiche pas tous les champs. Pour consulter une représentation plus complète, vous pouvez examiner cet exemple d'événement dans JSON.
2e exemple : Recherche
Imaginons que vous ayez besoin d'étudier l'activité d'une adresse IP dans toute une pile Web : pare-feu Palo Alto Networks, HAProxy (traité par Logstash), Apache (avec le module Beats), Elastic APM, et pour faire bonne mesure, système de détection d'intrusion Suricata (personnalisé et associé au format EVE JSON de Suricata).
Avant ECS, la recherche de cette adresse IP ressemblait plus ou moins à ceci :
src:10.42.42.42 OR client_ip:10.42.42.42 OR apache2.access.remote_ip:10.42.42.42 OR context.user.ip:10.42.42.42 OR src_ip:10.42.42.42
Mais maintenant que vous pouvez mapper toutes vos sources à ECS, votre recherche devient beaucoup plus simple :
source.ip:10.42.42.42
3e exemple : Visualisation
On voit immédiatement la puissance d'ECS lorsqu'on découvre comment elle peut être appliquée à des données normalisées de façon homogène, bien que provenant de différentes sources de données. Pour détecter les menaces, peut-être monitorez-vous votre pile Web via plusieurs sources de données réseau : un pare-feu Palo Alto nouvelle génération sur le réseau de périmètre, associé au système de détection d'intrusion Suricata, qui génère des événements et des alertes. Comment extraire les champs source.ip et network.direction de chaque message, de manière à permettre une visualisation centralisée dans Kibana et des opérations "drill-down" et "pivot" compatibles avec tous les fournisseurs ? Avec ECS, bien sûr. Le monitoring centralisé gagne vraiment en simplicité.
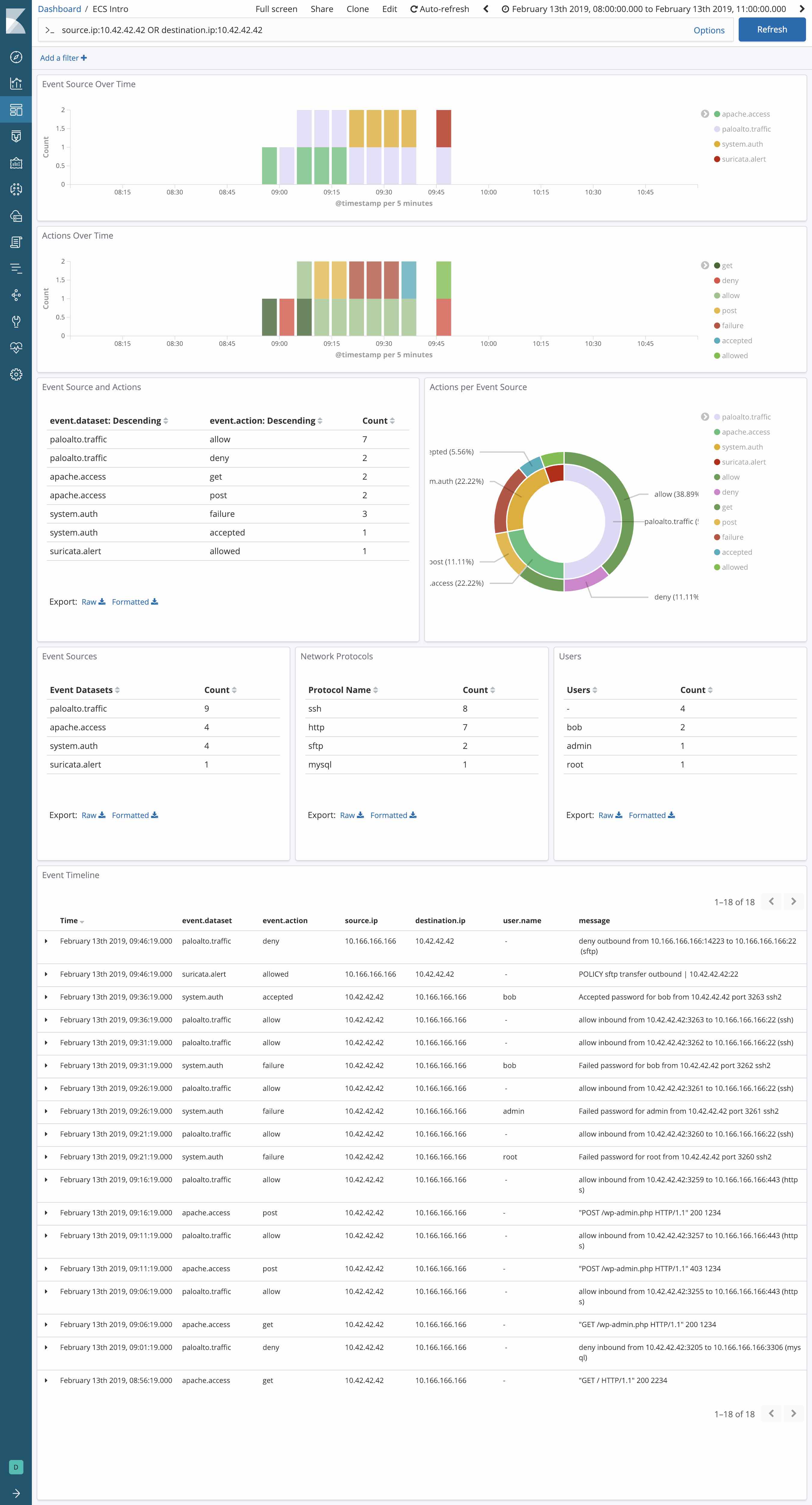
Avantages d'Elastic Common Schema
L'implémentation d'ECS permet d'unifier tous les modes d'analyse disponibles dans la Suite Elastic : recherche, opérations "drill-down" et "pivot", visualisation des données, détection des anomalies basée sur Machine Learning, ou encore alerting. Une fois ECS bien adopté, les utilisateurs peuvent mettre toute la puissance des paramètres de recherche structurée et non structurée au service de leurs requêtes. ECS permet aussi de rationaliser la corrélation automatique des données provenant de différentes sources, qu'il s'agisse des différents appareils d'un même fournisseur ou de types de sources de données totalement hétérogènes.
Autre avantage, vos équipes passent moins de temps à développer du contenu analytique. Et pour cause : au lieu de créer de nouvelles recherches et de nouveaux tableaux de bord chaque fois que vous ajoutez une nouvelle source de données, vous pouvez maintenant continuer d'exploiter vos recherches et tableaux de bord existants. Ajoutons à cela qu'avec ECS, votre environnement adopte bien plus facilement les contenus analytiques fournis par d'autres parties exploitant ECS, qu'il s'agisse d'Elastic, de partenaires ou de projets open source.
Lorsque vous effectuez des analyses interactives, ECS facilite la mémorisation des noms de champs fréquemment utilisés. En effet, il n'existe qu'un seul ensemble de noms de champs, et non un champ par source de données. Quant aux noms de champs dont vous ne parvenez plus à vous souvenir, ils sont faciles à retrouver (à quelques rares exceptions) par simple déduction, puisque notre spécification utilise une convention d'affectation de noms simplifiée et standardisée.
Pas envie d'essayer ECS ? Aucun souci. ECS est là pour le jour où vous en aurez besoin, mais rien ne vous y oblige.
Prise en main d'Elastic Common Schema
ECS est disponible via un référentiel GitHub public. La spécification est actuellement en version bêta 2, mais sa disponibilité générale est prévue pour bientôt. Elle est publiée sous licence open source Apache 2.0, ce qui permet son adoption universelle par la communauté Elastic élargie.
Tout cela a l'air automagique – pardon, automatique et totalement magique. En vérité, comme pour tous les schémas, l'implémentation d'ECS n'a rien d'une tâche anodine. Mais si vous avez déjà configuré un modèle d'index Elasticsearch et écrit quelques fonctions de transformation avec Logstash ou le nœud d'ingestion Elasticsearch, vous avez une idée de ce que cela implique. La bonne nouvelle, c'est que dans de futures versions des modules Beats d'Elastic, nous intégrerons des événements formatés pour ECS par défaut, ce qui permettra de rationaliser cette partie de la transition. Le nouveau module système d'Auditbeat a déjà ouvert la marche, et nous ne nous arrêterons pas là.
Pour en savoir plus sur ECS, n'hésitez pas à consulter notre webinar Elastic Common Schema (ECS). Dans de prochains articles de blog, nous aborderons le mapping des données vers ECS (y compris pour les champs non définis dans le schéma), ainsi que les stratégies de migration vers ECS.