Migration vers Elastic Common Schema (ECS) dans les environnements Beats
En février 2019, nous avons présenté Elastic Common Schema (ECS) dans un article de blog et un webinar. Pour résumer en quelques mots : en définissant un ensemble commun de champs et de types de données, ECS permet une recherche uniforme, la visualisation et l’analyse de sources de données disparates. Il s’agit d’un avantage énorme pour les environnements hétérogènes constitués de différentes normes fournisseur, dans lesquels il est fréquent d’utiliser de façon concomitante des sources de données similaires mais différentes.
Autre point que nous avons souligné : l'implémentation d'ECS n'a rien d'une tâche anodine. Pour pouvoir générer des événements compatibles avec ECS, de nombreux champs émis par les sources des événements doivent être copiés ou renommés lors du processus d’ingestion des données.
Nous avons conclu la présentation d’ECS en indiquant que, si vous avez déjà configuré un modèle d'index Elasticsearch et écrit quelques fonctions de transformation avec Logstash ou les pipelines d'ingestion Elasticsearch, vous aurez une idée assez juste de ce que cela implique. Selon la façon dont vous avez conçu vos pipelines d’ingestion de données de la Suite Elastic, le volume de travail requis pour migrer votre environnement vers ECS sera variable. À l’une des extrémités du spectre, Beats et les modules Beats permettront une migration optimisée vers ECS. Les événements Beats 7 sont déjà au format ECS. La seule tâche qu’il reste à faire, c’est de faire le lien entre le contenu d’analyse existant et les nouvelles données ECS. À l’autre extrémité du spectre, on retrouve les pipelines personnalisés ayant été conçus par les utilisateurs.
En juin, nous avons également présenté un webinar expliquant comment effectuer une migration vers ECS. Dans cet article de blog, nous nous baserons sur les éléments que nous avons abordés dans le webinar et exploreront plus en détail la migration vers ECS au sein des environnements Beats. En ce qui concerne la migration des pipelines personnalisés d’ingestion des données vers ECS, ce sujet sera abordé dans un futur article de blog.
Voici les différents thèmes que nous étudierons aujourd’hui :
- Migration vers ECS avec la Suite Elastic 7
- Présentation conceptuelle d’une migration vers ECS
- Présentation de la migration d’un environnement Beats vers ECS
- Mise en place de votre propre stratégie en matière de migration
- Exemple de migration
- Conclusion
- Références
Migration vers ECS avec la Suite Elastic 7
Ayant réalisé que renommer les champs d’événements utilisés par Beats occasionnerait un certain bouleversement, nous avons lancé les noms de champs ECS dans notre dernière version majeure, c.-à-d. la version 7 de la Suite Elastic.
Dans cet article, nous commencerons par donner un aperçu détaillé de la migration vers ECS avec Beats, dans le cadre d’une mise à niveau de la Suite Elastic de la version 6.8 vers la version 7.2. Nous poursuivrons avec un exemple de migration pas à pas d’une source d’événement Beats.
Attention : cet article de blog n’abordera qu’une partie de la migration vers la version 7. Comme suggéré par nos directives de mise à niveau des stacks, Beats doit être mis à niveau après Elasticsearch et Kibana. Dans l’exemple de migration que nous étudierons ci-dessous, nous présenterons uniquement la mise à niveau de Beats, et partirons donc du principe qu’Elasticsearch et Kibana ont déjà été mis à niveau vers la version 7. Nous pourrons ainsi nous attacher aux spécificités de la mise à niveau de Beats à partir du schéma "avant ECS" vers ECS.
Lorsque vous passerez à la version 7 de la Suite Elastic, n’oubliez pas de lire auparavant les directives susmentionnées, de consulter l’assistant de mise à niveau Kibana, et bien sûr, de prendre connaissance des notes de mise à niveau et des changements majeurs apportés concernant la partie du stack que vous utilisez.
Remarque : si vous envisagez d’adopter Beats, mais que vous n’avez aucune donnée venant de Beats 6, ne vous faites pas de souci concernant la migration. Dans ce cas, commencez tout simplement à utiliser Beats version 7 ou supérieure, qui génère des événements mis en forme pour ECS directement prêts à l’emploi.
Présentation conceptuelle d’une migration vers ECS
Quelle que soit la migration effectuée vers ECS, celle-ci impliquera les étapes suivantes :
- Convertir vos sources de données pour ECS
- Résoudre les différences et les conflits entre les formats d’événement "avant ECS" et les événements ECS
- Régler le contenu d’analyse, les pipelines et les applications pour utiliser les événements ECS
- Rendre les événements "avant ECS" compatibles avec ECS pour fluidifier la transition
- Supprimer les alias de champ une fois que toutes les sources ont été migrées vers ECS
Dans cet article de blog, nous allons nous pencher sur chacune de ces étapes, dans le cadre spécifique d’une migration d’un environnement Beats vers ECS.
Suite à cette présentation des étapes, nous illustrerons la théorie par la pratique avec un exemple de migration d’un module Filebeat de la version 6.8 vers la version 7.2. Cet exemple de migration est extrêmement simple, le but étant que vous puissiez facilement le reproduire sur votre poste de travail, réaliser chaque étape de la migration et faire des tests tout au long du processus.
Présentation de la migration d’un environnement Beats vers ECS
Il existe bien des façons d’appréhender les étapes de migration indiquées ci-dessus. Nous allons les passer en revue une à une dans le cadre de la migration de vos événements Beats vers ECS.
Convertir les sources de données pour ECS
Beats dispose de nombreuses sources d’événement optimisées. À partir de la version 7, ces sources sont déjà converties au format ECS. Les processeurs Beats qui ajoutent des métadonnées à vos événements (comme add_host_metadata) sont aussi convertis vers ECS.
Toutefois, il est important de comprendre que Beats fait parfois office de simple moyen de transport pour vos événements. Par exemple, pour les événements collectés par Winlogbeat et Journalbeat, ainsi que pour les entrées Filebeat via lesquelles vous utilisez des logs et des événements personnalisés (autres que les modules Filebeat eux-mêmes). Vous devrez mapper à ECS chaque source d’événement personnalisée que vous collectez et analysez par vous-même.
Résoudre les différences et les conflits liés aux schémas
Cette migration vers ECS consiste à normaliser les noms de champ sur de nombreuses sources de données. De ce fait, un grand nombre de champs vont être renommés.
Renommages et alias de champ
Il existe plusieurs façons de travailler avec les événements "avant ECS" et les événements ECS au cours de la transition entre les deux formats. Voici les principales :
- Utiliser les alias de champ Elasticsearch afin que les nouveaux index reconnaissent les anciens noms de champ
- Dupliquer les données dans le même événement (pour renseigner aussi bien les anciens champs que les champs ECS)
- Ne rien faire : l’ancien contenu fonctionne uniquement avec les anciennes données, tandis que le nouveau contenu fonctionne uniquement avec les nouvelles données
L’approche la plus simple et la plus économique est d’utiliser les alias de champ Elasticsearch. C’est cette approche que nous avons choisie pour la procédure de mise à niveau de Beats.
Sachez néanmoins que les alias de champ sont soumis à certaines limitations et qu’ils ne constituent pas une solution parfaite. Voyons en quoi ils peuvent nous aider et quelles sont leurs limitations.
Les alias de champ sont de simples champs supplémentaires dans le mappage Elasticsearch de nouveaux index. Ils permettent aux nouveaux index de répondre aux recherches à l’aide des anciens noms de champ. Prenons un exemple. Dans cet exemple, nous utiliserons seulement un champ unique dans un souci de simplicité :
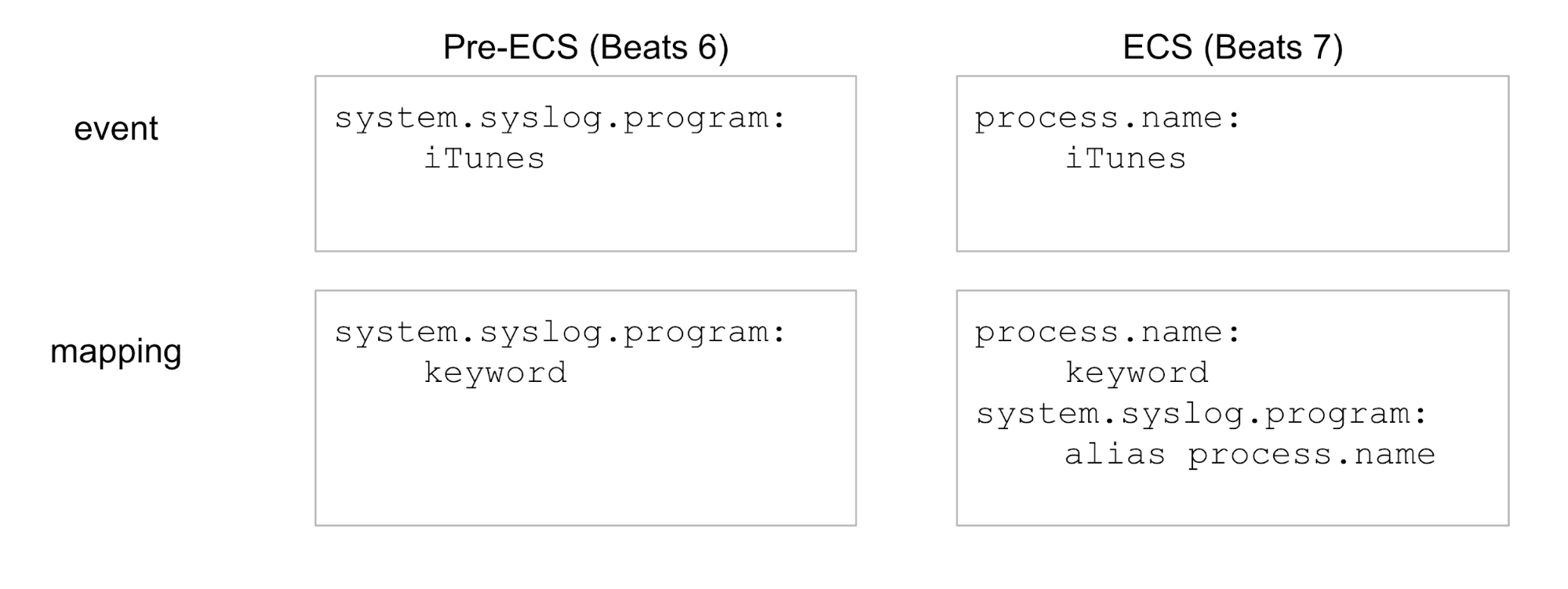
Plus précisément, les alias de champ seront utiles dans les cas suivants :
- Agrégations et visualisations sur le champ d’alias
- Filtrage et recherche sur le champ d’alias
- Saisie semi-automatique dans le champ d’alias
Voici les limitations des alias de champ :
- Les alias sont, par essence, une simple fonctionnalité des mappages Elasticsearch (index de recherche). De ce fait, ils ne modifient pas la source du document, ni les noms des champs. Le document contient soit les anciens noms des champs, soit les nouveaux. Pour illustrer ce propos, voici quelques emplacements où les alias n’ont aucune utilité, étant donné que les champs sont accessibles directement depuis le document.
- Colonnes affichées dans les recherches enregistrées
- Traitement supplémentaire dans votre pipeline d’ingestion de données
- Toute application utilisant vos événements Beats (p. ex. via l’API Elasticsearch)
- Comme les alias de champ sont des entrées de champ en tant que telles, nous ne pouvons pas créer d’alias lorsqu’il y a un nouveau champ ECS portant le même nom.
- Les alias de champ fonctionnement uniquement avec des champs de feuille. Ils ne fonctionnent pas pour les champs complexes comme les champs
object, qui contiennent d’autres champs imbriqués.
Ces alias de champ ne sont pas créés par défaut dans vos index Beats 7. Ils doivent être activés en définissant migration.6_to_7.enabled: true dans chaque fichier de configuration de YAML de Beats avant de procéder à la configuration de Beats. Cette option et les alias correspondants seront disponibles pendant toute la durée de vie de la Suite Elastic 7.x et seront supprimés à partir de la version 8.0.
Conflits
Lors de la migration vers ECS, vous pouvez également être confronté à des conflits de champ, selon les sources que vous utilisez.
Sachez que certains types de conflits sont détectés uniquement pour les champs que vous utilisez réellement. Ce qui signifie que les changements ou les conflits se produisant dans des sources que vous n’utilisez pas ne vous affecteront pas. Mais cela signifie également que, lorsque vous planifiez votre migration, vous devez ingérer des échantillons d’événements de chacune de vos sources de données dans les deux formats (Beats 6 et 7) au sein de votre environnement de test afin de mettre au jour les conflits à résoudre.
Les conflits se divisent en deux catégories :
- Le type des données d’un champ change pour être plus approprié.
- Un nom de champ utilisé avant ECS est également dans ECS mais a un sens différent. C’est ce que nous appelons des champs incompatibles.
Les conséquences exactes impliquées varient selon le type de conflit. Mais en général, lorsqu’un champ change de type de données, ou lorsqu’un champ incompatible change d’imbrication (p. ex. un champ "keyword" devient un champ "object"), vous ne pourrez pas effectuer de recherche simultanée sur les sources "avant ECS" et les sources ECS.
Avec les données qui intègrent vos index Beats 6 et 7, il convient d’actualiser les modèles d'indexation Kibana pour révéler ces conflits. Si, après avoir actualisé votre modèle d'indexation, vous ne voyez aucun avertissement de conflit, c’est qu’il ne vous reste aucun conflit à résoudre. Si, par contre, vous recevez un avertissement, vous pouvez définir le sélecteur de types de données pour afficher uniquement les conflits :

Pour gérer ces conflits, une méthode consiste à réindexer les anciennes données pour les rendre compatibles avec le nouveau schéma. Les conflits provoqués par un changement de type sont plutôt simples à résoudre. Vous pouvez tout simplement écraser vos modèles d'indexation Beats 6 pour utiliser le type de données le plus approprié, faire une réindexation sur un nouvel index (pour que le mappage mis à jour s’applique), puis supprimer l’ancien index.
Si vous vous trouvez en présence de champs incompatibles, vous devrez décider s’il faut les supprimer ou les renommer. Si vous renommez le champ, définissez-le tout d’abord dans votre modèle d'indexation.
Régler l’environnement pour utiliser des événements ECS
Le moins qu’on puisse dire, c’est qu’il y a beaucoup de noms de champs qui changent. Par conséquent, le contenu d’analyse échantillon (p. ex. tableaux de bord) accompagnant Beats a été intégralement modifié afin d’utiliser les nouveaux noms de champs ECS. Le nouveau contenu fonctionnera uniquement sur les données ECS générées par Beats 7.0 et versions supérieures. De ce fait, la configuration de Beats n’écrasera votre contenu Beats 6 existant, mais créera à la place une copie de chaque visualisation Kibana. Chaque nouvelle visualisation Kibana a le même nom que la précédente, auquel est ajouté “ECS” à la fin.
Le contenu échantillon Beats 6 et votre contenu personnalisé basé sur cet ancien schéma continueront en général à fonctionner sur les données Beats 6 et 7 grâce aux alias de champ. Comme nous l’avons cependant souligné, les alias de champ constituent une solution partielle et temporaire pour faciliter la migration vers ECS. Aussi, vous devriez inclure la mise à jour ou la duplication de vos tableaux de bord personnalisés au cours de la migration pour commencer à utiliser les nouveaux noms de champs.
Illustrons notre propose avec un tableau :
|
Avant ECS (Beats 6, vos tableaux de bord personnalisés) |
ECS (Beats 7) |
| Tableau de bord Syslog [Système Filebeat] | Tableau de bord Syslog ECS [Système Filebeat] |
|
|
En plus de la révision et de la modification du contenu d’analyse dans Kibana, vous devrez également réviser les éventuelles sections personnalisées de votre pipeline d’événements, ainsi que les applications accédant aux événements Beats via l’API Elasticsearch.
Rendre les événements "avant ECS" compatibles avec ECS
Nous avons déjà vu comment la réindexation permet de résoudre les conflits liés aux types des données et aux champs incompatibles. Il s’agit d’une approche facultative, mais elle est plutôt simple à mettre en œuvre et elle en vaut généralement la peine. Autre solution : ignorer les conflits. C’est une solution viable pour les cas d'utilisation simples. Attention toutefois : vous pouvez être confronté à des conflits de champ potentiels à partir du moment où vous commencerez à ingérer des données Beats 7 en raison de l’expiration de Beats 6 dans votre cluster.
Réindexation
Si le support fourni par les alias de champ n’est pas suffisant dans votre cas, vous pouvez aussi réindexer les anciennes données pour re-remplir les noms de champs ECS dans vos données Beats 6. Ainsi, le nouveau contenu d’analyse dépendant des champs ECS (nouveau contenu Beats 7 et votre contenu personnalisé mis à jour) pourra interroger vos anciennes données en plus des données Beats 7.
Modification des événements pendant l’ingestion de données
Si vous pensez que le déploiement des agents Beats 7 prendra un certain temps, vous pouvez avancer tout simplement en réindexant les anciens index. Vous pouvez également modifier les événements Beats 6 entrants au cours de l’ingestion de données.
Quelques méthodes permettent d’effectuer la réindexation et de manipuler les documents, telles que la copie, la suppression ou le renommage des champs. La plus simple consiste à utiliser les pipelines d’ingestion d’Elasticsearch. En voici certains avantages :
- Les pipelines sont simples à tester avec _simulate API
- Vous pouvez utiliser le pipeline pour réindexer les anciens index.
- Vous pouvez utiliser le pipeline pour modifier les événements Beats 6 qui continuent à arriver.
Pour modifier les événements au moment où ils arrivent, dans la plupart des cas, il suffit simplement de configurer le paramètre de “pipeline“ de votre sortie Elasticsearch pour qu’ils soient envoyés dans votre pipeline. C’est vrai pour Logstash et Beats.
Remarque : les modules Filebeat se servent déjà de pipelines d’ingestion pour réaliser leurs analyses. Il est également possible de les modifier. Pour cela, vous devez écraser les pipelines Filebeat 6 et ajouter un rappel dans votre pipeline de réglage.
Supprimer les alias de champ
Dès que vous n’avez plus besoin des alias de champ, vous pouvez les supprimer. Pour rappel, ceux-ci prennent moins de place qu’une duplication intégrale des données. Néanmoins, ils consomment tout de même de la mémoire dans l’état de votre cluster, qui est une ressource critique. Ils sont également présents dans la saisie semi-automatique Kibana, ce qui alourdit les choses inutilement.
Pour supprimer vos anciens alias de champ, supprimez tout simplement le paramètre migration.6_to_7.enabled (ou mettez-le sur false) de votre configuration Beats (p. ex. filebeat.yml), réitérez l’opération de "configuration" et écrasez le modèle.
Remarque : une fois que les modèles ont été écrasés pour ne plus inclure les alias, il faut toutefois attendre que les index se déploient pour que la suppression des alias soit effective dans les mappages d’index. Ensuite, une fois les index déployés, vous devez attendre que les données Beats 7 qui contenaient les alias arrivent à expiration dans votre cluster pour que ces alias soient totalement supprimés.
Mise en place de votre propre stratégie en matière de migration
Nous avons vu comment Beats facilitait la migration de vos données Beats vers ECS. Nous avons également abordé les étapes supplémentaires que vous pouvez réaliser pour que votre migration soit encore plus fluide.
Vous devez maintenant évaluer la somme de travail nécessaire pour chacune de vos sources de données de façon indépendante. Vous aurez probablement moins de tâches à accomplir pour les sources moins critiques.
Voici quelques critères à prendre en compte lorsque vous étudiez une source de données :
- Quelle votre période de conservation ? Est-elle définie par un facteur externe ? Avez-vous la possibilité d’écarter des données plus tôt au cours de cette migration ?
- Avez-vous besoin de continuité dans vos données ? Ou peut-il y avoir des transferts ? Cela peut vous aider à déterminer si un re-remplissage, comme décrit ci-dessus, est approprié.
- Combien de temps votre déploiement de Beats 7 prendra-t-il ? Avez-vous besoin de modifier les événements Beats 6 au fur et à mesure qu’ils arrivent ?
Si vous prévoyez de re-remplir de nombreux champs, vous devriez jeter un œil à dev-tools/ecs-migration.yml dans le référentiel Beats. Ce fichier répertorie tous les changements de champs pour la migration de Beats 6 vers Beats 7.
Exemple de migration
Nous allons maintenant étudier pas à pas comment effectuer une migration vers ECS en mettant Beats à niveau de la version 6.8 vers la version 7.2. Nous verrons également en quoi les alias peuvent aider et quelles sont leurs limitations, comment résoudre les conflits, comment réindexer les données précédentes pour faciliter la transition et comment modifier les événements Beats 6 qui continuent d’arriver. Dans cet exemple, nous utiliserons le module Syslog de Filebeat.
Comme nous l’avons déjà indiqué, nous ne verrons qu’une partie de la mise à niveau de la Suite Elastic. Nous partirons du principe qu’Elasticsearch et Kibana ont déjà été mis à niveau vers la version 7, pour nous concentrer sur la réalisation de la mise à niveau du schéma de données vers ECS.
Pour pouvoir reproduire cette procédure, veuillez utiliser les versions les plus récentes d’Elasticsearch 7 et de Kibana 7. Vous pouvez soit passer par un compte d’essai gratuit Elastic Cloud, soit exécuter Elasticsearch et Kibana localement en suivant les instructions d’installation correspondantes.
Exécution de Beats 6.8
Dans cette démo, nous exécuterons Filebeat 6.8 et 7.2 simultanément sur la même machine. Il est donc important d’installer ces versions avec une installation d’archivage (avec zip ou .tar.gz). Les installations d’archivage sont auto-contenues dans leur répertoire et faciliteront la procédure.
Lancez Elasticsearch et Kibana 7, puis installez Filebeat 6.8. Si vous êtes sous Windows, vous pouvez tester en installant Winlogbeat à la place.
Sur la plupart des systèmes, Syslog utilise l’heure locale pour son horodatage sans préciser le fuseau horaire. Nous allons configurer Filebeat pour ajouter le fuseau horaire à chaque événement via le processeur add_locale, puis paramétrer le pipeline du module système pour qu’il interprète l’horodatage en conséquence. Ainsi, nous pourrons valider notre migration ECS à coup sûr lorsque nous rechercherons des événements reçus récemment.
Dans filebeat.yml, repérez la section relative aux processeurs et ajoutez le processeur add_locale. Sous cette section, ajoutez le module de configuration suivant :
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
- add_locale: ~
filebeat.modules:
- module: system
syslog:
var.convert_timezone: true
Si vous exécutez Elasticsearch et Kibana localement, cela devrait être suffisant. Si vous utilisez Elastic Cloud, vous devrez ajouter vos informations d’identification de cloud dans filebeat.yml (accessibles dans Elastic Cloud lors de la création d’un cluster) :
cloud.id: 'my-cluster-name:a-very-long-string....' cloud.auth: 'username:password'
Maintenant, préparons Filebeat 6.8 pour qu’il capture les logs système :
./filebeat setup -e ./filebeat -e
Confirmons que les données entrent bien en regardant le tableau de bord [Système Filebeat] Tableau de bord Syslog. Nous devrions voir les événements Syslog les plus récents générés sur le système sur lequel Filebeat a été installé.
Ce tableau de bord est intéressant car il comprend des visualisations et une recherche enregistrée. Cela nous sera utile pour déterminer ce que peuvent faire les alias de champ et ce qu’ils ne peuvent pas.
Exécution de Beats 7 (ECS)
Soyons clairs : certains environnements ne peuvent pas faire de transfert instantané d’une version de Beats à une autre. Il y aura probablement des événements qui viendront à la fois de Filebeat 6 et de Filebeat 7 pendant une certaine période. C’est ce que nous allons faire aussi dans cet exemple.
Pour cela, nous pouvons tout simplement exécuter Filebeat 7.2 avec Filebeat 6.8 sur le même système. Nous allons extraire Filebeat 7.2 dans un répertoire différent, et appliquer les mêmes changements de configuration que ceux apportés à la version 6.8.
Mais attention : ne faites pas la configuration maintenant ! Pour Beats 7, nous devons également activer le paramètre de migration, qui crée les alias de champ. Supprimez cette ligne à la toute fin du fichier filebeat.yml :
migration.6_to_7.enabled: true
Notre fichier de configuration 7.2 dispose désormais des éléments suivants : l’attribut de migration supplémentaire, le processeur add_locale, la configuration du module système et, si besoin, nos informations d’identification de cloud.
Utilisons Filebeat 7.2 depuis un terminal différent :
./filebeat setup -e ./filebeat -e
Conflits
Avant de nous pencher sur les tableaux de bord, accédons directement à la gestion des index Kibana pour confirmer que le nouvel index a été créé et que des données y entrent. Vous devriez avoir une présentation similaire à celle-ci :
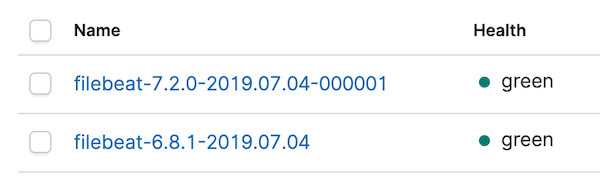
Accédons aussi aux modèles d'indexation et actualisons celui intitulé filebeat-*. Suite à cette actualisation, il peut y avoir quelques conflits. Nous pouvons cibler les conflits en changeant le sélecteur de types de données à droite et en le faisant passer de All field types (Tous les types de champs) à conflict :
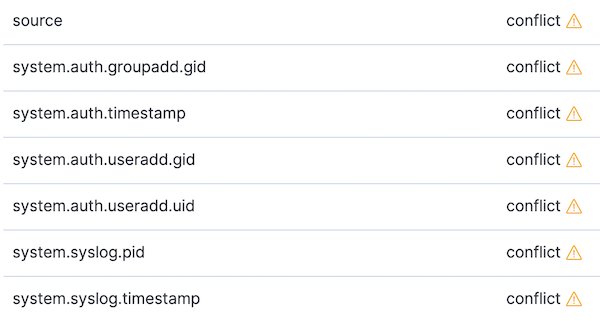
Examinons deux des conflits ci-dessus et déterminons comment les traiter.
Tout d’abord, étudions un conflit propre à syslog : system.syslog.pid. Si nous nous rendons sur la page de gestion des index et que nous regardons le mappage pour 6.8, nous pouvons constater que le champ est indexé en tant que keyword. Si nous regardons le mappage d’index 7.2, nous voyons que system.syslog.pid est un alias de process.pid. De ce côté, tout est normal. Ce n’est pas ça qui est à l’origine du conflit. Par contre, si nous suivons l’alias et que nous nous penchons sur le type de données pour process.pid, nous constatons qu’il s’agit désormais du type long. C’est le transfert du type keyword à long qui a provoqué le conflit.
Maintenant, étudions un conflit provoqué par un champ incompatible. Un cas classique pour toutes les migrations Filebeat : le champ source. Dans Filebeat 6, source est un champ keyword qui contient habituellement un chemin vers un fichier (ou parfois une adresse source syslog). Dans ECS, et donc dans les mappages de champ Filebeat 7, source devient un objet avec des champs imbriqués servant à décrire la source d’un événement réseau (source.ip, source.port, etc.). Étant donné qu’un champ intitulé source existe déjà dans Beats 7, nous ne pouvons pas créer un champ d’alias ici.
Nous avons identifié deux champs sur lesquels nous pouvons intervenir dans le cadre de notre procédure de migration. Nous y reviendrons dans un moment.
Alias
Gardons notre tableau de bord Syslog [Système Filebeat] Beats 6 ouvert. Étant donné que le modèle d'indexation filebeat-* a changé depuis le premier chargement du tableau de bord, procédons à un rechargement intégral de la page avec Commande + R ou F5.
À partir d’un nouvel onglet, ouvrons le nouveau tableau de bord Tableau de bord Syslog ECS [Système Filebeat].
Lorsque nous nous penchons sur la recherche enregistrée en bas du tableau de bord 6.8, nous voyons qu’il y a des divergences dans les données. Certains événements ont des valeurs pour system.syslog.program et system.syslog.message, d’autres non. Lorsque nous ouvrons ceux qui ont des valeurs vides, nous constatons qu’il s’agit des mêmes événements Syslog prélevés par 7.2, mais avec des noms de champ différents. Pour la même période dans l’onglet avec le tableau de bord ECS, nous observons le même comportement inversé. Les champs ECS process.name et message sont remplis pour les événements 7.2, mais pas pour les événements 6.8.
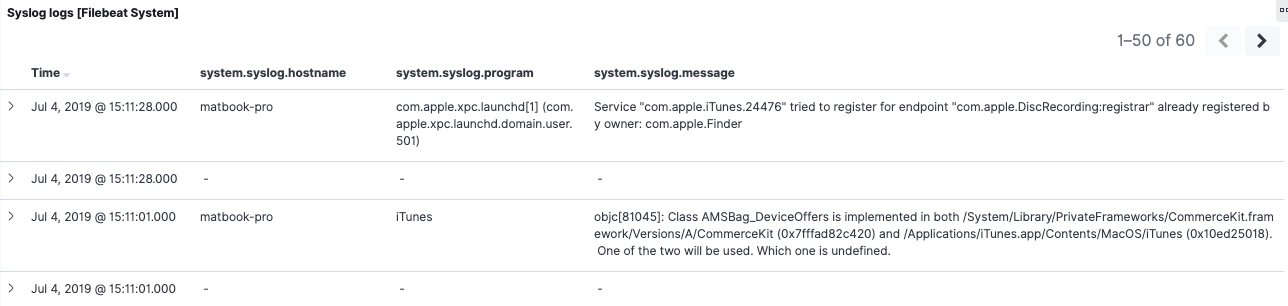
Il s’agit d’un cas concret dans lequel les alias de champ ne peuvent pas nous aider. Les recherches enregistrées s’appuient sur le contenu du document, pas sur le mappage d’index. Comme nous l’avons déjà mentionné dans l’aperçu, si la continuité est essentielle pour vous, procédez à une réindexation pour re-remplir les champs (et modifier les événements entrants). Nous aborderons ce sujet sous peu.
Voyons à présent en quoi les alias de champ peuvent nous aider. Étudiez la visualisation en forme de donut dans le tableau de bord 6.8 et survolez l’anneau extérieur, qui affiche les valeurs de system.syslog.program :
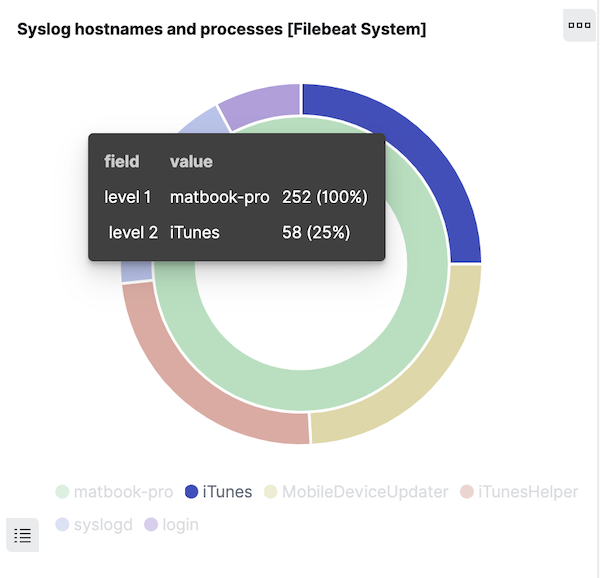
Cliquez sur une section de l’anneau pour appliquer un filtre sur les messages générés par un programme. Sélectionnons uniquement le filtre sur le nom du programme :
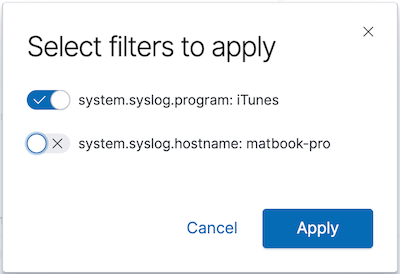
Nous venons d’ajouter un filtre sur un champ qui n’est plus présent dans 7.2 : system.syslog.program. Ceci dit, nous pouvons toujours voir les deux ensembles de messages dans la recherche enregistrée :
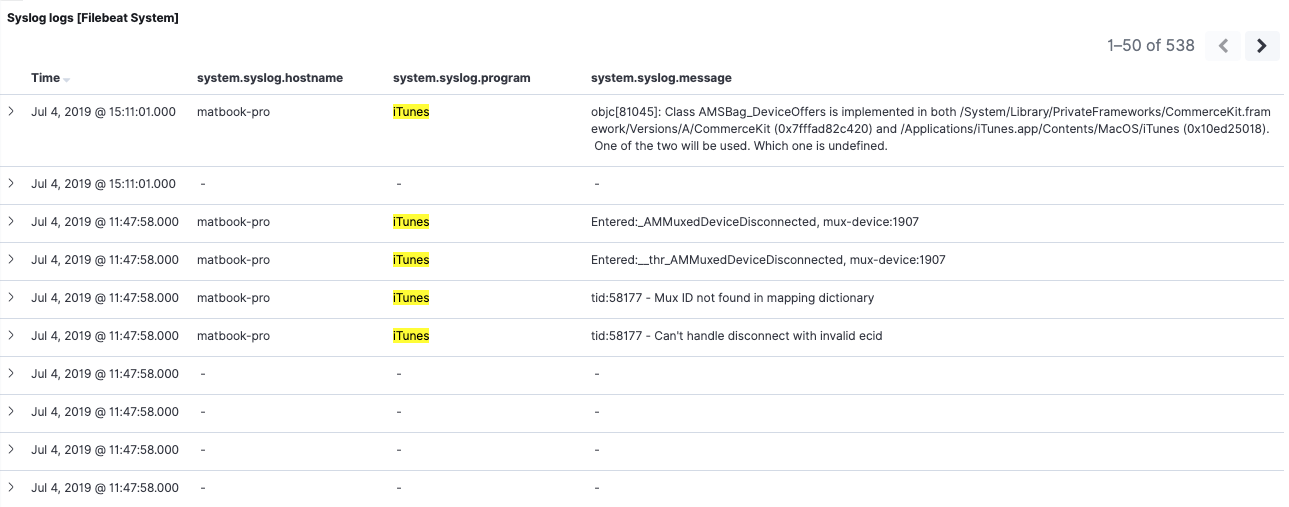
Si nous nous penchons sur les éléments 7.2, nous constatons que le filtre a aussi été correctement appliqué sur ces éléments. Cela confirme que notre filtre sur system.syslog.program fonctionne avec nos données 7.2, grâce à l’alias system.syslog.program.
Notez que la visualisation (soutenue par une agrégation Elasticsearch) affiche aussi les résultats de façon correcte pour 6.8 et 7.2 sur le champ system.syslog.program migré.
Si nous revenons au tableau de bord 7.2, sans filtres actifs, nous pouvons consulter les données 6.8 et 7.2. Si nous appliquons le même filtre comme nous l’avons fait sur 6.8, en revanche, nous remarquons que le comportement est différent. Le filtrage pour process.name:iTunes renvoie désormais des événements 7.2 uniquement. Pourquoi ? Car les index 6.8 n’ont pas de champ nommé process.name, ni d’alias pour ce nom.
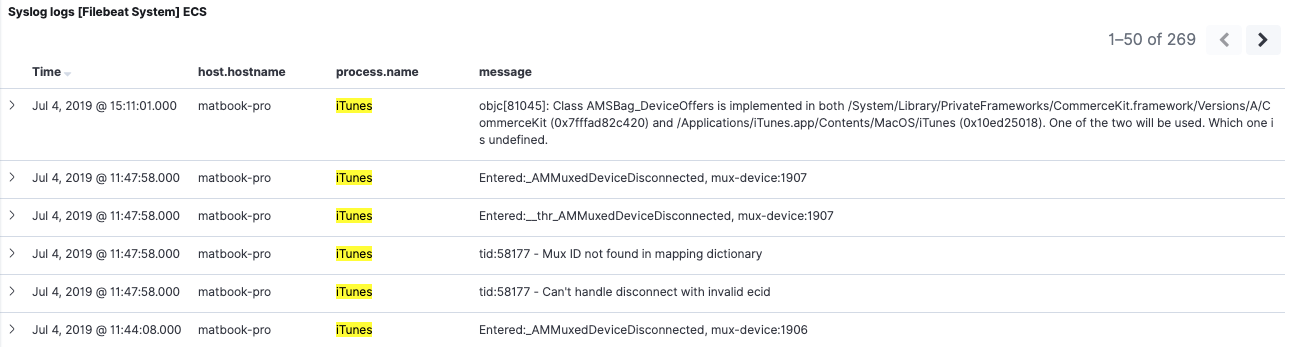
Réindexation pour une transition fluide
Comme nous l’avons vu, la réindexation permet de résoudre trois différents aspects de la migration : la résolution des conflits de types de données, la résolution de champs incompatibles et le re-remplissage des champs ECS pour préserver la continuité. Passons en revue un exemple de chacun de ces aspects.
Voici comment nous allons modifier nos données Beats 6 :
- Conflit de type de données : changez les types de données pour system.syslog.pid de keyword à long.
- Champ incompatible : Supprimez le fichier source de Filebeat après avoir copié son contenu dans log.file.path. Vous éliminerez ainsi le conflit avec l’ensemble du champ source d’ECS. Remarque : dans Beats 6.6 et versions supérieures, log.file.path est déjà rempli avec la même valeur … mais ce n’est pas le cas dans les versions précédentes de Beats 6. C’est pourquoi nous allons le copier si besoin.
- Re-remplissez le champ ECS process.name avec la valeur de system.syslog.process.
Voici comment procéder à ces changements :
- Nous modifierons le modèle d’index Filebeat 6.8 pour utiliser les nouveaux types de données, ainsi qu’ajouter et supprimer des définitions de champ.
- Nous créerons un nouveau pipeline d’ingestion qui modifie les événements 6.8 en supprimant ou en copiant des champs.
- Nous testerons le pipeline avec l’API _simulate.
- Nous utiliserons le pipeline pour réindexer les anciennes données.
- Nous attacherons également un renvoi à ce nouveau pipeline à la fin du pipeline d’ingestion Filebeat 6.8 pour modifier les événements entrants.
Modification du modèle d’index
Les améliorations apportées aux types de données doivent être intégrées au modèle d’index. Elles prendront effet lors du déploiement de l’index. Par défaut, le déploiement a lieu le lendemain. Si vous vous servez de la gestion du cycle de vie des index dans 6.8, vous pouvez forcer le déploiement avec l’API de substitution.
Affichez le modèle d’index actuel à partir des outils de développement Kibana :
GET _template/filebeat-6.8.1
Les modèles d’index ne peuvent pas être modifiées. Ils doivent être entièrement écrasés (voir documentation). Préparez un appel API PUT avec l’intégralité du modèle d’index tout y ajustant quelques éléments :
- Supprimez la définition de source (toutes les lignes commençant par
-ci-dessous). - Ajoutez une définition de champ pour program.name.
- Changez le type du champ system.syslog.pid sur long.
PUT _template/filebeat-6.8.1
{
"order" : 1,
"index_patterns" : [
"filebeat-6.8.1-*"
]
...
"mappings": {
"properties" : {
- "source" : {
- "ignore_above" : 1024,
- "type" : "keyword"
- },
"program" : {
"properties" : {
"name": {
"type": "keyword",
"ignore_above": 1024
}
}
},
"system" : {
"properties" : {
"syslog": {
"properties" : {
"pid" : {
"type" : "long"
}
...
}
Dès que le corps de l’appel API est prêt, exécutez-le pour écraser le modèle d’index. Si vous prévoyez de re-remplir un certain nombre de champs ECS, jetez un œil aux exemples de modèles ECS Elasticsearch dans le référentiel git ECS.
Réindexation
La prochaine étape consiste à écrire un nouveau pipeline d’ingestion pour modifier nos événements Beats 6.8. Pour notre exemple, nous allons copier system.syslog.program dans process.name, source dans log.file.path (sauf s’il est déjà rempli) et supprimer le champ source :
PUT _ingest/pipeline/filebeat-system-6-to-7
{ "description": "Pipeline to modify Filebeat 6 system module documents to better match ECS",
"processors": [
{ "set": {
"field": "process.name",
"value": "{{system.syslog.program}}",
"if": "ctx.system?.syslog?.program != null"
}},
{ "set": {
"field": "log.file.path",
"value": "{{source}}",
"if": "ctx.containsKey('source') && ctx.log?.file?.path == null"
}},
{ "remove": {
"field": "source"
}}
],
"on_failure": [
{ "set": {
"field": "error.message",
"value": "{{ _ingest.on_failure_message }}"
}}
]
}
Apprenez-en davantage sur les pipelines d’ingestion et le langage Painless (utilisé dans les clauses if).
Nous pouvons tester ce pipeline avec l’API _simulate en ayant des événements entièrement remplis. Néanmoins, nous utiliserons ici une procédure bien plus minimaliste, convenant mieux dans le contexte d’un article de blog. Comme vous pouvez le constater, log.file.path est rempli pour un événement (Beats 6.6 et versions supérieures), mais pas pour l’autre (6.5 et versions antérieures) :
POST _ingest/pipeline/filebeat-system-6-to-7/_simulate
{ "docs":
[ { "_source": {
"log": { "file": { "path": "/var/log/system.log" } },
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}},
{ "_source": {
"source": "/var/log/system.log",
"system": {
"syslog": {
"program": "syslogd"
}}}}
]
}
La réponse à l’appel API contient deux événements modifiés. Nous pouvons confirmer que notre pipeline fonctionne car le champ source n’apparaît plus et que les deux événements ont une valeur stockée pour log.file.path.
Nous pouvons désormais procéder à une réindexation sur les index qui ne reçoivent plus d’écritures (p. ex. index d’hier et d’avant) à l’aide de ce pipeline d’ingestion pour chaque index Filebeat que nous migrons. Lisez attentivement les documents _reindex pour comprendre comment faire une réindexation en arrière-plan, contraindre votre opération de réindexation, etc. Voici une réindexation simple applicable aux quelques événements dont nous disposons :
POST _reindex
{ "source": { "index": "filebeat-6.8.1-2019.07.04" },
"dest": {
"index": "filebeat-6.8.1-2019.07.04-migrated",
"pipeline": "filebeat-system-6-to-7"
}}
Si vous reproduisez cette procédure en parallèle et que vous ne disposez que des index d’aujourd’hui, n’hésitez pas à tester tout de même l’appel API et regardez le mappage des index migrés. Mais ne supprimez pas les index d’aujourd’hui par la suite. Ils seront juste recréés car Filebeat 6.8 continue à envoyer des données.
Autrement, une fois que les index inactifs ont été réindexés, nous pouvons confirmer que les nouveaux index disposent des correctifs souhaités, et de là, supprimer les anciens index.
Modification des événements entrants
La plupart des Beats peuvent être configurés pour effectuer des envois directement dans un pipeline d’ingestion de leur sortie Elasticsearch (idem pour la sortie Elasticsearch de Logstash). Étant donné que nous nous servons d’un module Filebeat dans cette démo (qui utilise déjà des pipelines d’ingestion), nous devrons modifier le pipeline du module à la place.
Le pipeline d’ingestion installé par la configuration Filebeat 6.8 à prendre en charge se nomme filebeat-6.8.1-system-syslog-pipeline. Tout ce que nous avons à faire, c’est d’ajouter un renvoi vers notre propre pipeline à la fin du pipeline Syslog Filebeat.
Nous allons afficher le pipeline que nous sommes sur le point de modifier :
GET _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
Ensuite, nous allons préparer l’appel API pour écraser le pipeline en collant l’intégralité du pipeline dessous l’appel API PUT. Ensuite, nous ajouterons un processeur de “pipeline” à la fin, pour appeler notre nouveau pipeline.
PUT _ingest/pipeline/filebeat-6.8.1-system-syslog-pipeline
{ "description" : "Pipeline for parsing Syslog messages.",
"processors" :
[
{ "grok" : { ... }
...
{ "pipeline": { "name": "filebeat-system-6-to-7" } }
],
"on_failure" : [
{ ... }
]
}
Après avoir exécuté l’appel API, tous les événements entrants seront modifiés pour mieux correspondre à ECS, avant d’être indexés.
Pour finir, nous pouvons utiliser _update_by_query pour modifier les documents copiés précédemment avant de modifier le pipeline. Nous pouvons déterminer les documents qui doivent être mis à jour en repérant ceux disposant encore du champ source :
GET filebeat-6.8.1-*/_search
{ "query": { "exists": { "field": "source" }}}
Et nous réindexerons uniquement ces documents :
POST filebeat-6.8.1-*/_update_by_query?pipeline=filebeat-system-6-to-7
{ "query": { "exists": { "field": "source" }}}
Vérification des conflits
Après que tous les index ayant des conflits ont été supprimés, seuls les champs réindexés sont conservés. Nous pouvons actualiser le modèle d'indexation pour confirmer la suppression effective des conflits. Si nous revenons à notre tableau de bord Filebeat 7, nous constaterons que les données 6.8 qu’il contient sont désormais plus utiles grâce à notre re-remplissage du champ process.name :
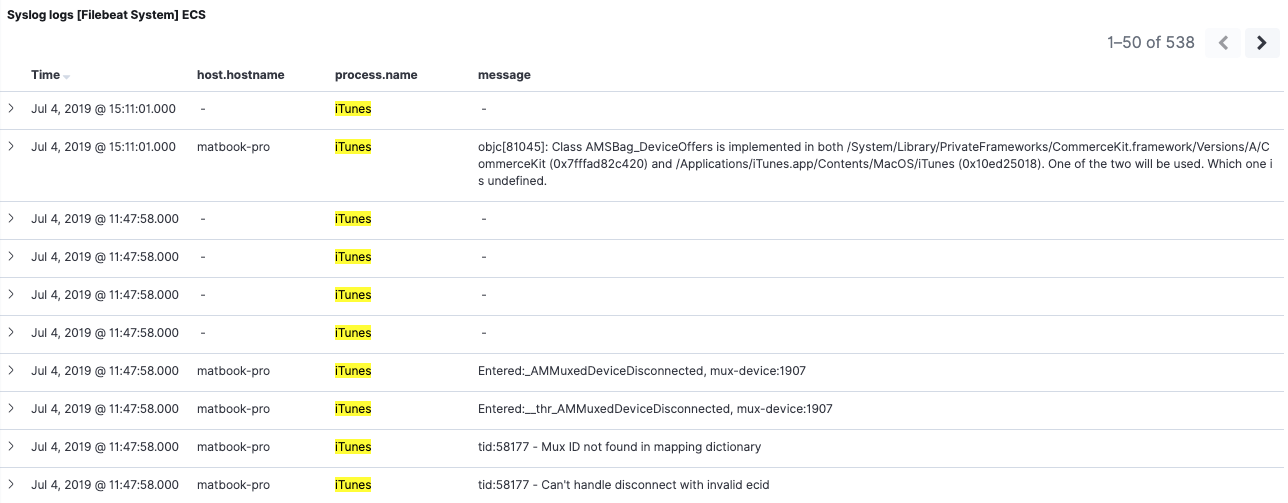
Dans notre exemple, nous avons uniquement re-rempli un champ. Bien entendu, vous pouvez re-remplir le nombre de champs que vous souhaitez.
Nettoyage après la migration
Au cours de votre migration, vous pouvez être amenés à modifier vos tableaux de bord et applications personnalisés utilisant des événements Beats via l’API pour utiliser de nouveaux noms de champs ECS.
Une fois que votre migration vers Beats 7 est achevée et que plus aucun alias de champ n’est utilisé, nous pouvons les supprimer pour tirer parti des avantages abordés précédemment en matière d’économies de mémoire. Pour supprimer les alias, retirons l’attribut migration.6_to_7.enabled de filebeat.yml, puis écrasons le modèle Filebeat 7.2 avec :
./filebeat setup --template -e -E 'setup.template.overwrite=true'
Tout comme précédemment, le nouveau modèle sans alias sera effectif lors du prochain déploiement d’index Filebeat 7.2.
Conclusion
Dans cet article, nous avons abordé les différentes étapes pour migrer vos données vers ECS dans un environnement Beats. Nous avons étudié les avantages d’une procédure de mise à niveau, ainsi que ces limitations. Ces limitations peuvent être palliées en réindexant les anciennes données et même en modifiant les données Beats 6 entrantes lors du processus d’ingestion.
Après avoir détaillé les étapes de la migration, nous avons illustré la théorie par la pratique à l’aide d’un exemple de mise à niveau du module de système Filebeat de la version 6.8 vers la version 7.2. Nous avons étudié les différences entre les événements de Filebeat 6.8 et 7.2, puis nous avons décrit les étapes possibles pour réindexer des données anciennes, et les modifier lors de leur entrée.
La mise en place d’un schéma a inévitablement un impact conséquent sur les installations existantes. Nous sommes néanmoins convaincus que cette migration est avantageuse. Pour en savoir davantage, vous pouvez lire Lancement d'Elastic Common Schema et Why Observability loves the Elastic Common Schema (Quand observabilité rime avec Elastic Common Schema).
Si votre environnement utilise des pipelines d’ingestion de données autres que Beats, restez connecté. Nous prévoyons de publier prochainement un autre article de blog sur la procédure pour migrer un pipeline d’ingestion personnalisé vers ECS.
Si vous avez des questions sur ECS ou si vous avez besoin d’aide avec votre mise à niveau Beats, consultez les forums de discussion et intégrez la balise elastic-common-schema à votre question. Pour en savoir plus sur ECS, lisez notre documentation et apportez votre contribution à ECS sur GitHub.
Références
Documentation
- Assistant de mise à niveau
- Mise à niveau de la Suite Elastic
- Changements majeurs dans la version 7.0
- Réindexation
- Pipeline d’ingestion
- API de simulation du pipeline d’ingestion
- Langage Painless
- Mappages et modèles d’index
- Fichier documentant tous les changements de champs : ecs-migration.yml
- Exemples de modèles d’index Elasticsearch ECS
Blogs et vidéos
- Lancement d'Elastic Common Schema (blog)
- Lancement d'Elastic Common Schema (webinar)
- ECS: How to migrate your data (ECS : Comment effectuer la migration de vos données) (webinar)
- Why observability loves the Elastic Common Schema (Quand observabilité rime avec Elastic Common Schema) (blog)
- Upgrading the Elastic Stack with the 7.x Upgrade Assistant (Mise à niveau de la Suite Elastic avec l’assistant de mise à niveau 7.x) (blog)
Stipulations générales
- Posez des questions sur ECS dans les forums de discussion et intégrez la balise “elastic-common-schema” à votre question.
- Documentation officielle sur ECS
- Référentiel Github ECS