Présentation du traitement du langage naturel moderne avec PyTorch dans Elasticsearch


 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Bonne nouvelle ! Dans la version 8.0, Elastic offre la possibilité de charger des modèles de Machine Learning PyTorch dans Elasticsearch pour appliquer le traitement du langage naturel (NLP) dans la Suite Elastic. Désormais, les utilisateurs Elasticsearch peuvent intégrer l'un des formats les plus populaires pour créer des modèles de NLP, qu'ils pourront ensuite incorporer dans un pipeline de données NLP dans Elasticsearch avec notre processeur d'inférence. Avec d'un côté la possibilité d'ajouter des modèles PyTorch, et de l'autre, l'utilisation de nouvelles API de recherche des plus proches voisins, c'est un tout nouveau vecteur (c'est le cas de le dire) qui s'offre dorénavant à Elastic Enterprise Search.
Le NLP, qu'est-ce que c'est ?
Le NLP concerne la façon dont nous pouvons utiliser les logiciels pour manipuler et comprendre les textes écrits ou oraux, ou le langage naturel. En 2018, Google a proposé une nouvelle technique open source pour l'entraînement préalable du NLP, appelée Bidirectional Encoder Representations from Transformers, ou BERT. BERT emploie "l'apprentissage par transfert". Pour s'entraîner, il utilise des ensembles de données de dimension Internet (pensez par exemple à Wikipédia et aux livres numériques) sans intervention humaine.
Plus concrètement, l'apprentissage par transfert permet d'entraîner préalablement un modèle BERT pour qu'il puisse comprendre le langage général. Un seul entraînement préalable suffit. Ensuite, vous n'avez plus qu'à réutiliser le modèle et à l'affiner en fonction de tâches plus spécifiques afin qu'il comprenne comment le langage est employé.
Pour prendre en charge des modèles semblables à BERT, c'est-à-dire qui utilisent le même générateur de tokens que BERT, Elasticsearch commencera par s'appuyer sur une grande partie des tâches NLP les plus courantes en s'aidant du modèle PyTorch. PyTorch est l'une des bibliothèques modernes de Machine Learning les plus populaires, qui compte une vaste communauté d'utilisateurs actifs. Cette bibliothèque prend en charge les réseaux de neurones profonds, comme l'architecture Transformer que BERT utilise.
Vous trouverez ci-dessous quelques exemples de tâches du NLP :
- Analyse des sentiments : classification binaire pour identifier les instructions positives et négatives.
- Reconnaissance d'entités nommées (NER) : création d'une structure à partir de texte non structuré, afin de tenter d'extraire des détails tels que le nom, l'emplacement, ou encore l'organisation.
- Classification de textes : une classification zero-shot vous permet de placer le texte dans différentes classes que vous choisissez, sans appliquer d'entraînement préalable.
- Plongements textuels : ils sont utilisés dans le cadre de la recherche des k plus proches voisins.

Le NLP dans Elasticsearch
Avec l'intégration de modèles NLP dans Elastic Platform, notre objectif est d'offrir une meilleure expérience utilisateur lors du chargement et de la gestion des modèles. Grâce au client Eland, qui sert au chargement des modèles PyTorch, et à l'interface utilisateur située sous Machine Learning > Model Management dans Kibana, qui permet de gérer les modèles dans un cluster Elasticsearch, les utilisateurs ont la possibilité de tester différents modèles afin d'en déterminer les performances avec les données. Nous souhaitions également en assurer l'évolutivité sur les nœuds disponibles dans un cluster et offrir de bonnes performances en matière de débit d'inférence.
Pour que tout cela soit possible, nous avions besoin d'une bibliothèque de Machine Learning avec laquelle réaliser une inférence. Pour ajouter la prise en charge de PyTorch dans Elasticsearch, nous avons dû utiliser la bibliothèque native libtorch, à laquelle PyTorch est adossé, qui ne s'occupera que des modèles PyTorch ayant été exportés ou enregistrés en tant que représentation TorchScript. Cette représentation de modèle spécifique est en effet celle dont libtorch a besoin et qui évitera à Elasticsearch d'avoir à exécuter un interpréteur Python.
En intégrant l'un des formats les plus populaires pour créer des modèles NLP dans des modèles PyTorch, Elasticsearch peut fournir une plateforme qui fonctionne avec un vaste éventail de tâches NLP et de cas d'utilisation. Il existe d'excellentes bibliothèques pour entraîner les modèles NLP. C'est pourquoi nous n'allons pas nous y intéresser pour le moment. Nous laissons cela à d'autres outils. NLP (PyTorch), Transformers (Hugging Face) et fairseq (Facebook) sont autant de bibliothèques qui vous permettront d'entraîner vos modèles. Quelle que soit celle que vous utiliserez, vous pourrez importer vos modèles dans Elasticsearch et exécuter ensuite une inférence. L'inférence Elasticsearch se fera initialement au moment de l'ingestion, et uniquement à ce moment. Par la suite, il sera possible de l'exécuter au moment de la requête.
Jusqu'à présent, vous pouviez appliquer des méthodes diverses et variées pour intégrer des modèles NLP via des appels API et des plug-ins, ou vous servir d'autres options pour diffuser des données vers et depuis Elasticsearch. Cependant, l'intégration de modèles NLP dans un pipeline de données Elasticsearch apporte de nombreux avantages :
- Création d'une infrastructure plus performante autour de vos modèles NLP
- Scaling de l'inférence de votre modèle NLP
- Maintien de la sécurité et de la confidentialité de vos données
Les modèles NLP peuvent être gérés de manière centralisée dans Kibana afin de distribuer les requêtes sur plusieurs nœuds de Machine Learning pour un équilibrage de charge optimisé.
Les appels d'inférence aux modèles PyTorch peuvent être distribués autour du cluster et permettre aux utilisateurs de scaler en fonction des charges à venir. Pour améliorer les performances, il est préférable de ne pas déplacer les données et d'optimiser les MV cloud pour toute inférence basée sur le processeur. En incorporant des modèles NLP à Elasticsearch, nous pouvons conserver les données dans un réseau global centralisé et sécurisé tout en veillant à la confidentialité des données et à la conformité. L'infrastructure commune, les performances de requête et la confidentialité des données peuvent être améliorées en incorporant des modèles NLP à Elasticsearch.
Workflow de mise en œuvre d'un modèle PyTorch
Pour mettre en œuvre un modèle NLP dans Elasticsearch, c'est très simple. Première étape : nous devons charger nos modèles dans Elasticsearch. Pour cela, nous pouvons nous servir des API REST accessibles dans n'importe quel client Elasticsearch. Néanmoins, nous avions envie d'utiliser des outils encore plus simples pour faciliter le processus. Dans notre client Eland, qui correspond à notre bibliothèque de Data Science en Python pour la Suite Elastic, nous présenterons quelques méthodes et scripts très simples pour charger les modèles à partir du disque local, ou pour extraire des modèles du hub de Hugging Face. Ce hub permet de partager des modèles entraînés, ce qui en fait une ressource très populaire. Dans tous les cas, quelle que soit l'approche que vous choisissez, des outils vous permettront de convertir les modèles PyTorch en représentations TorchScript, et de là, charger les modèles dans un cluster.
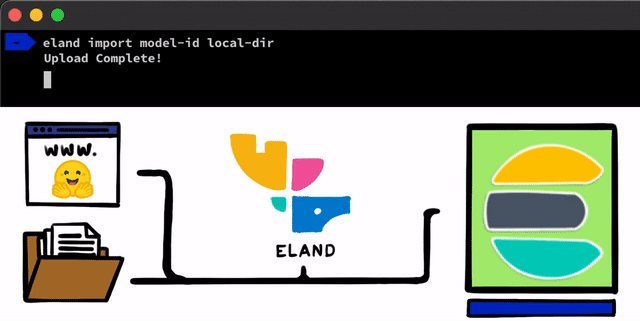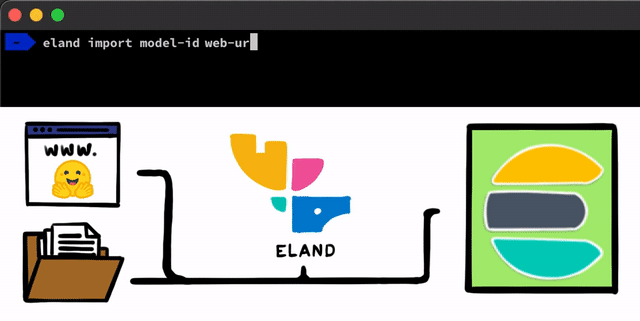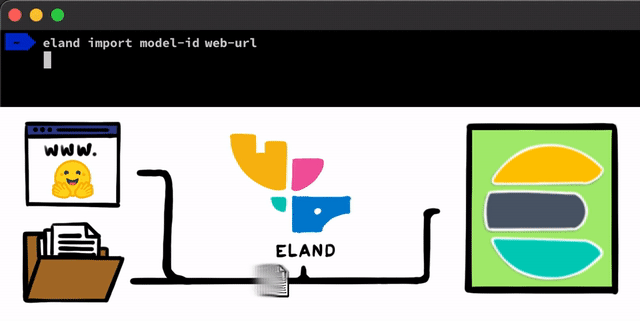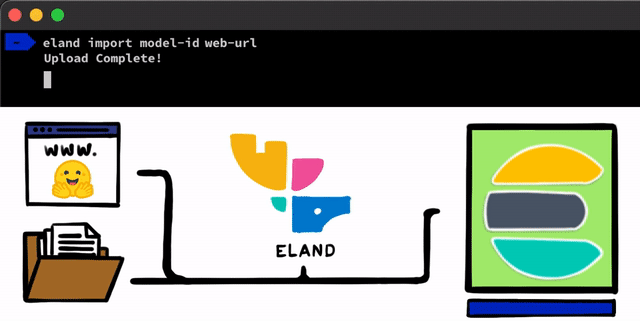
Une fois les modèles PyTorch chargés dans le cluster, vous pourrez les attribuer aux nœuds de Machine Learning de votre choix. Cela permettra de les charger dans la mémoire et de lancer les processus libtorch natifs.
Voilà ! Les modèles sont prêts pour l'inférence. Un processeur sera disponible pour l'inférence au moment de l'ingestion. Vous pouvez configurer le type de pipeline de traitement d'ingestion que vous souhaitez utiliser pour traiter les documents avant ou après l'inférence. Par exemple, nous pouvons exécuter une tâche d'analyse des sentiments. Lors de cette tâche, nous prenons le texte d'un champ de document comme entrée, renvoyons l'étiquette de classe positive ou négative qui a été prédite pour cette entrée, et ajoutons cette prédiction dans un champ de sortie du document. Le nouveau document qui en résulte peut être ensuite traité de façon plus poussée par d'autres processeurs d'ingestion, ou peut être indexé en l'état.
Prochaines étapes
Nous avons hâte de vous présenter d'autres exemples de modèles spécifiques et de tâches NLP dans les blogs et webinars à venir. Vous souhaitez tester un modèle en particulier dans Elasticsearch ? Lancez-vous dès aujourd'hui et racontez-nous votre expérience sur notre forum de discussion sur le Machine Learning ou notre communauté Slack. Pour les cas d'utilisation de production, Elasticsearch nécessite une licence Platinum ou Enterprise pour charger les modèles NLP et utiliser le processeur d'inférence. Mais vous pouvez déjà vous faire une idée du fonctionnement dès aujourd'hui grâce à un essai gratuit. Autre solution : vous pouvez créer un cluster Elastic Cloud et utiliser notre client Eland pour y charger le modèle. N'attendez plus ! Lancez-vous dès aujourd'hui avec un essai gratuit de 14 jours d'Elastic Cloud.
Une dernière chose… Si vous souhaitez en savoir plus sur les modèles NLP et sur leur intégration dans Elasticsearch, nous vous invitons à participer à notre webinar sur la présentation des modèles NLP et de la recherche vectorielle.
Ressources supplémentaires :
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer