Schéma d'écriture vs schéma de lecture
La Suite Elastic (également connue comme Suite ELK) est une plateforme populaire de stockage de logs.
De nombreux utilisateurs commencent à stocker des logs sans structure, hormis l'horodatage et quelques étiquettes pour filtrer facilement les données. C'est exactement ce que fait Filebeat par défaut : suivre les logs et les envoyer à Elasticsearch aussi vite que possible, sans extraire de structures supplémentaires. Aussi, l'interface utilisateur de Logs dans Kibana ne tire aucune conclusion de la structure des logs. Un simple schéma "@timestamp" et "message" est suffisant. Schéma minimal, voici comment nous appelons ce type de logging. Il pèse moins sur le disque, mais présente peu d'utilité au-delà de la simple recherche de mots-clés et du filtrage d'étiquettes.
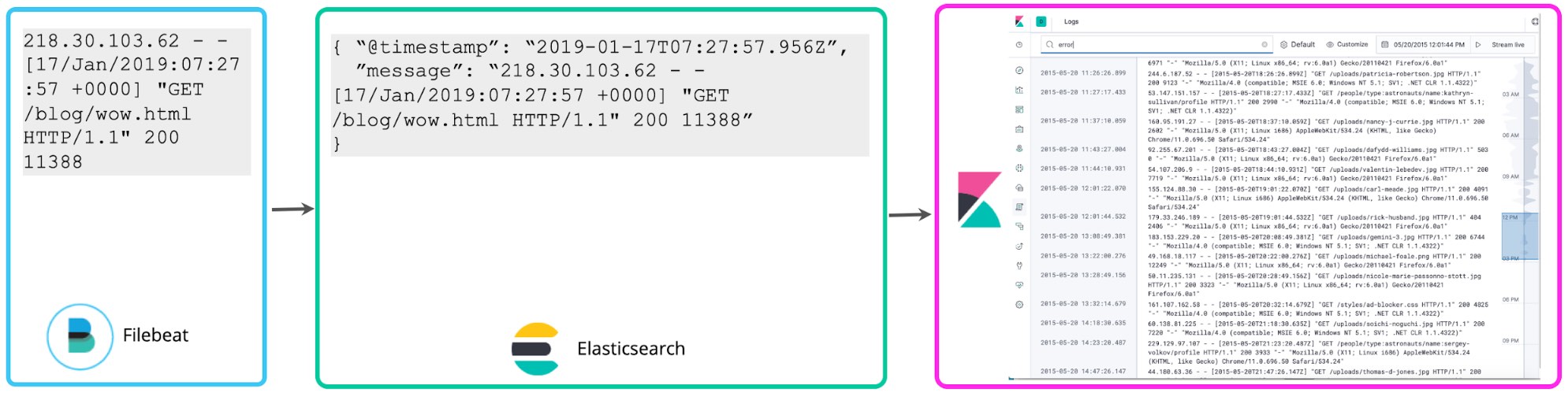
Une fois que vous vous serez familiarisé avec vos logs, vous éprouverez certainement le besoin de les exploiter davantage. Si vous identifiez des numéros dans les logs qui se rapportent à des codes d'état, il se peut que vous souhaitiez les compter pour savoir combien de codes d'état du type 5xx se sont produits dans l'heure. Les champs scriptés vous permettent d'appliquer un schéma aux logs au moment de la recherche pour extraire ces états et effectuer des agrégations, des visualisations et d'autres types d'actions. Cette approche de logging est souvent appelée schéma de lecture.
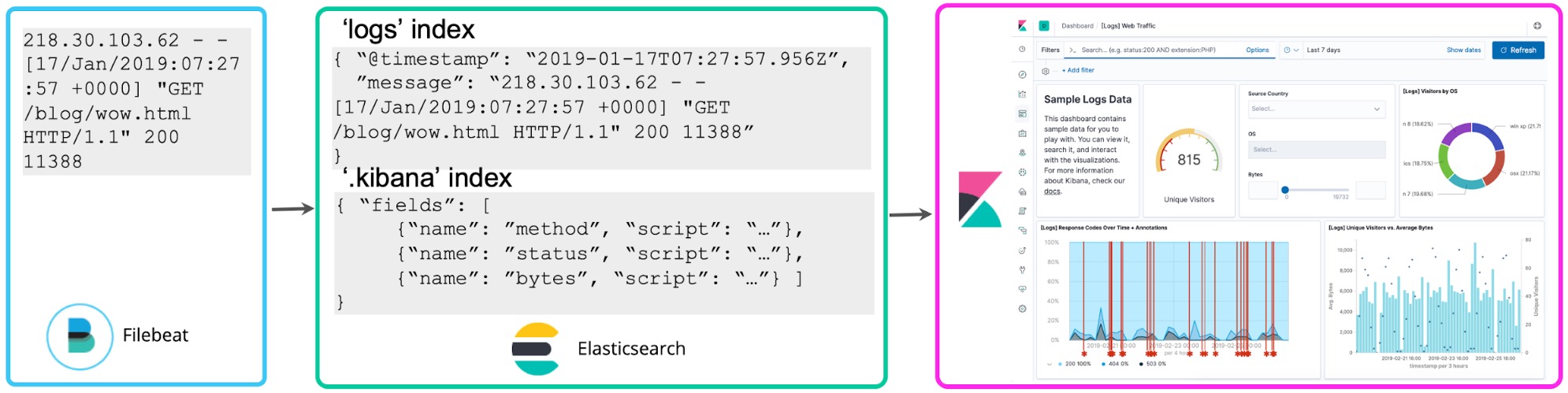
Bien que cette méthode soit pratique pour les explorations ad hoc, elle présente l'inconvénient de devoir exécuter l'extraction des champs chaque fois que vous effectuez une recherche ou actualisez une visualisation dans le cadre d'opérations continues de reporting et de présentation de tableau de bord. Au lieu de cela, une fois que vous avez choisi les champs structurés qui vous intéressent, un processus de réindexation peut être lancé en arrière-plan pour "perpétuer" ces champs scriptés dans des champs structurés au sein d'un index Elasticsearch permanent. Quant aux données transmises à Elasticsearch, vous pouvez configurer un Logstash ou un pipeline de nœuds d'ingestion pour extraire ces champs de façon proactive avec des processeurs dissect ou grok.
Cela nous mène à une troisième approche qui consiste à analyser les logs lors de leur écriture pour extraire de façon proactive les champs mentionnés ci-dessus. Ces logs structurés sont très appréciés des analystes, car ces derniers n'ont pas à réfléchir à la manière d'extraire les champs, ce qui leur permet d'accélérer leurs recherches et d'augmenter considérablement la valeur des résultats obtenus à partir des données des logs. De nombreux utilisateurs d'ELK ont adopté cette approche de "schéma d'écriture" d'analyse centralisée des logs.
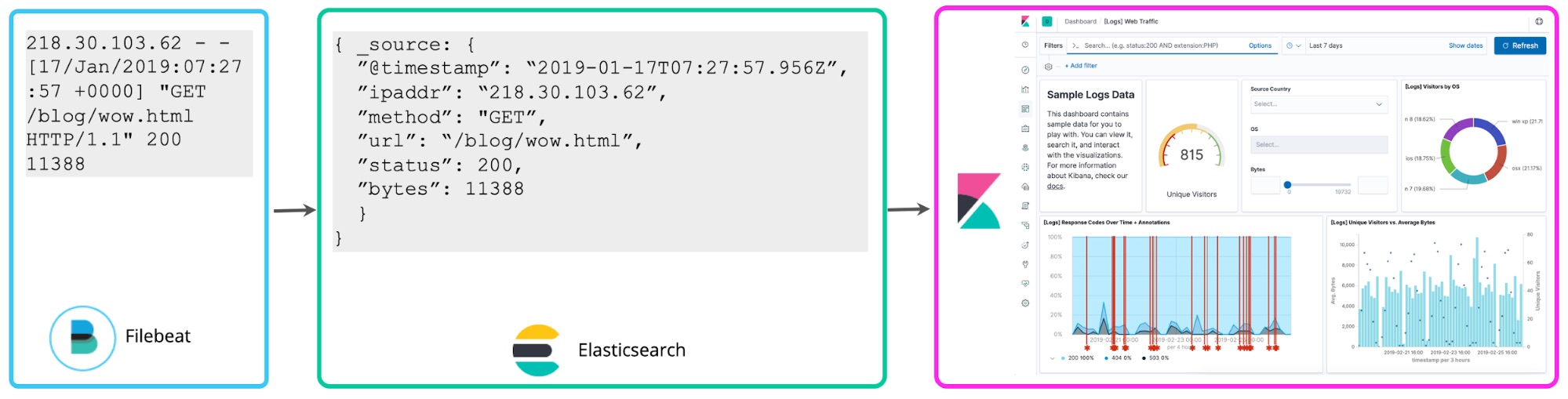
Au fil de cet article, nous allons explorer les compromis que ces approches présupposent et les analyser du point de vue de la planification. Nous reviendrons sur la valeur intrinsèque de la structuration préalable des logs et sur les raisons à mon avis naturelles d'adopter cette méthode à mesure que votre déploiement de logging centralisé évolue, même si votre structure de départ est très simple.
Bénéfices du schéma d'écriture (cassons les mythes)
Analysons d'abord la raison pour laquelle nous devrions structurer des logs alors que nous les enregistrons dans un cluster de logging centralisé.
Une meilleure expérience de recherche. Lorsque nous recherchons des informations importantes dans des logs, nous recherchons naturellement et simplement des mots-clés, tels qu'"erreur". Nous pouvons obtenir des résultats à partir d'une telle recherche en considérant chaque ligne de log comme un document dans un index inversé, puis en effectuant une recherche plein texte. Cependant, que se passera-t-il lorsque nous donnerons des instructions plus complexes comme "renvoie toutes les lignes de log pour lesquelles mon_champ est égal à N" ? Si le champ mon_champ n'est pas défini, nous ne pourrons pas donner directement cette instruction. Aussi, même si votre log contient cette information, vous devrez écrire une règle d'analyse dans le cadre de votre recherche pour extraire le champ afin de le comparer à la valeur attendue. Dans la Suite Elastic, lorsque vous structurez vos logs au préalable, la fonction de saisie semi-automatique de Kibana suggère automatiquement des champs et des valeurs à mesure que vous construisez vos recherches. Ainsi, les analystes peuvent voir leur productivité considérablement augmenter. Vous et vos collègues pouvez désormais poser directement des questions sans avoir à connaître les champs ni à écrire des règles complexes d'analyse qui servent à extraire les champs au moment de la recherche.
Des recherches et des agrégations d'historique plus rapides. Même si elles interrogent des données historiques volumineuses, les recherches lancées sur des champs structurés dans la Suite Elastic renvoient des résultats en quelques millisecondes. Par comparaison, les systèmes habituels de "schéma de lecture" prennent des minutes voire des heures pour afficher leurs résultats. Les opérations de filtrage et d'agrégations statistiques exécutées sur des champs structurés extraits et indexés au préalable sont beaucoup plus rapides que l'exécution d'expressions régulières sur chaque ligne de log qui servent à extraire un champ et lui appliquer des opérations mathématiques. N'oublions pas que l'obtention des résultats ne peut pas être accélérée au préalable dans le cadre de recherches ad hoc, car nous ne savons pas quelles recherches nous exécuterons pendant l'investigation.
Des logs aux indicateurs. Dans le sillage du point précédent, les valeurs numériques extraites à partir de logs structurés ressemblent étonnamment à des séries temporelles numériques ou à des indicateurs. D'un point de vue opérationnel, l'exécution d'agrégations sur ces points de données produit rapidement des informations de grande valeur. Les champs structurés vous permettent de traiter des points de données numériques à partir de logs sous forme d'indicateurs à grande échelle.
La vérité n'attend pas. Lorsque vous rapprochez des champs comme l'adresse IP et le nom d'hôte, faites-le lors de l'indexation et non lors de la recherche, car si vous le faites trop tard, le rapprochement pourrait ne plus correspondre à la transaction qui vous intéresse. Au bout d'une semaine, une adresse IP peut être associée à un autre nom d'hôte. Cela s'applique aux recherches effectuées dans des sources externes. Ces dernières présentent l'instantané le plus récent du mapping, comme le rapprochement entre un nom d'utilisateur et des systèmes de gestion d'identité, une étiquette d'inventaire et une CMDB, etc.
Détection et signalement d'anomalies en temps réel. Tout comme les agrégations, les opérations de détection et de signalement des anomalies fonctionnent de la façon la plus efficace à grande échelle, et ce, avec des champs structurés. Autrement, les exigences de traitement continu de votre cluster seront très coûteuses. De nombreux clients choisissent de ne pas créer d'alertes ou de tâches de détection des anomalies, car l'extraction des champs lors de la recherche représente un effort trop important pour le nombre d'alertes dont ils ont besoin. Cela signifie que les données de log recueillies ne servent qu'aux cas d'utilisation essentiellement réactifs, ce qui limite le retour sur investissement de ces projets.
Les logs dans le cadre d'initiatives d'observabilité. Si vous participez à une initiative d'observabilité, vous savez que vous ne pouvez pas vous contenter de collecter et de rechercher les logs. Les données de log doivent idéalement être liées aux indicateurs (tels que l'utilisation des ressources) et aux traces d'application pour qu'elles puissent raconter une histoire holistique à l'opérateur sur les événements du service, et ce, quelle que soit l'origine des points de données. Ces corrélations fonctionnent de façon optimale avec les champs structurés. Sinon, les recherches sont lentes, et l'analyse est inutilisable dans les situations pratiques à grande échelle.
Qualité des données. Lorsque vos événements sont préalablement traités, vous avez la possibilité d'identifier les données non valides, en double ou manquantes, puis de corriger ces problèmes. Avec le "schéma de lecture", vous ne savez pas si vos résultats sont précis, car la validité et l'exhaustivité de vos données n'ont pas été vérifiées au préalable. Les résultats obtenus pourraient être inexacts, et vous risquez par conséquent de tirer des conclusions incorrectes.
Contrôle d'accès granulaire. Il est difficile d'appliquer des règles de sécurité granulaires, telles que des restrictions au niveau du champ, à des données de log non structurées. Les filtres qui restreignent l'accès aux données lors de la recherche peuvent être utiles, mais ils présentent des limites considérables, telles que l'incapacité de renvoyer des résultats partiels pour constituer un sous-ensemble de champs. Dans la Suite Elastic, la sécurité au niveau du champ permet aux utilisateurs bénéficiant de moins de privilèges de consulter certains champs et pas d'autres dans tout l'ensemble de données. Ainsi, les données personnelles des logs peuvent être facilement protégées, et ce, avec flexibilité, tout en permettant à un ensemble plus vaste d'utilisateurs d'exploiter le reste des informations.
Exigences matérielles
L'un des mythes à propos du "schéma d'écriture" soutient que votre cluster aura besoin de plus ressources pour analyser les logs et stocker à la fois les formats analysés (ou "indexés") et non analysés. La réponse étant "ça dépend", examinons les facteurs à prendre en compte selon votre cas d'utilisation.
Analyse unique ou extraction continue de champs. L'analyse et le stockage des logs dans un format structuré utilisent des capacités de traitement au niveau de l'ingestion. Cependant, l'exécution répétée de recherches dans des logs non structurés qui reposent sur des déclarations complexes d'expressions régulières pour extraire des champs consomme à la longue beaucoup plus de mémoire vive et de ressources du CPU. Si le cas d'utilisation applicable à vos logs consiste à permettre quelques recherches occasionnelles, la structuration préalable des logs pourrait requérir un effort démesuré. En revanche, si vous prévoyez que vos logs fassent l'objet de recherches et d'agrégations fréquentes, le coût unique d'ingestion pourrait être inférieur aux coûts incessants liés à la réexécution des mêmes opérations lors de chaque recherche.
Exigences en matière d'ingestion. Avec des traitements préalables supplémentaires, votre débit d'ingestion risque de baisser un peu. Vous pouvez accroître votre infrastructure d'ingestion pour compenser cette charge en scalant indépendamment vos nœuds d'ingestion Elasticsearch ou vos instances Logstash. D'excellents blogs et références indiquent comment procéder. Si vous utilisez Elasticsearch Service dans Elastic Cloud, il suffit d'ajouter des nœuds capables d'effectuer des ingestions pour monter l'ingestion en charge.
Besoins de stockage. À vrai dire, même si cela semble contre-intuitif, les besoins de stockage pourraient diminuer si vous faites l'effort de comprendre au préalable la structure de vos logs. Les logs peuvent contenir trop d'informations et détourner l'attention de l'utilisateur. En les examinant à l'avance (même si vous n'analysez pas tous les champs), vous pouvez distinguer les lignes de log et les champs extraits à conserver en ligne dans votre cluster de logs centralisé de ceux que vous préférez archiver immédiatement. Cette approche permet d'éviter de stocker des logs qui comportent des données partiellement inutiles, susceptibles de détourner l'attention de l'utilisateur. Il s'agit ni plus ni moins de la mission des processeurs légers dissect et drop de Filebeat.
Même si, pour des raisons réglementaires, vous devez conserver chaque ligne de log, il existe des façons d'optimiser les coûts de stockage liés au "schéma d'écriture". N'oubliez pas que vous êtes aux commandes. Rien ne vous oblige à structurer complètement vos logs. Si votre cas d'utilisation vous le permet, ajoutez seulement les métadonnées structurées dont vous avez vraiment besoin et ignorez le reste de la ligne de log. Autrement, si vous structurez complètement vos logs et que chaque portion de données importantes est transmise à un stockage structuré, il est inutile de conserver le champ d'origine dans le cluster qui contient les logs indexés. Vous pouvez l'archiver dans un stockage à bas prix.
Si le stockage vous inquiète particulièrement, il existe de nombreuses façons d'optimiser Elasticsearch. Par exemple, vous pouvez augmenter les taux de compression avec seulement quelques réglages. Vous pouvez aussi utiliser les architectures hot-warm et le gel des indices pour optimiser le stockage à long terme des données peu utilisées. Néanmoins, si vous souhaitez éviter de longues minutes d'attente lorsque vous avez besoin de résultats rapides, n'oubliez pas que le stockage des données hot est relativement bon marché.
Définition préalable de la structure
Voici un autre mythe : il est difficile de structurer des logs avant de les stocker. Revenons sur cette affirmation.
Logs structurés. De nombreux logs sont déjà produits dans des formats structurés. JSON est pris en charge comme format de logging par les applications les plus courantes. Vous pouvez donc commencer à transmettre vos logs directement à Elasticsearch et à les stocker dans des formats structurés sans avoir à les analyser.
Règles d'analyse préconstruites. Elastic est officiellement compatible avec des dizaines de règles d'analyse préconstruites. Par exemple, les modules Filebeat structurent les logs de certains fournisseurs, alors que Logstash contient une bibliothèque de modèles grok. Bien d'autres règles d'analyse préconstruites sont disponibles auprès de la communauté.
Règles d'analyse autogénérées. Des outils comme Kibana Data Visualizer aident à définir des règles pour extraire les champs de logs personnalisés en vous suggérant automatiquement des façons de les analyser. Collez un échantillon de log, puis obtenez un modèle grok que vous pourrez utiliser dans le nœud d'ingestion ou dans Logstash.
Que se passe-t-il lorsque le format de votre log change ?
Voici un dernier mythe : le "schéma d'écriture" complique la prise en compte des modifications apportées aux formats de log. C'est simplement faux : quelqu'un devra s'occuper des changements de format de log, et ce, quelle que soit l'approche choisie pour extraire les données de vos logs, à moins que vous ne vous contentiez d'effectuer des recherches plein texte. Que vous utilisiez un pipeline de nœuds d'ingestion qui traite les logs au moyen d'un modèle grok lors de leur indexation ou un champ Kibana scripté qui procède de la même façon au moment de la recherche, la logique qui permet d'extraire les champs devra être adaptée chaque fois que le format des logs sera modifié. Quant aux modules Filebeat dont nous assurons la maintenance, nous guettons les nouvelles versions des logs que vous recevez en amont pour effectuer les modifications de compatibilité et les tests nécessaires.
Voici plusieurs façons de traiter les modifications de structure de log au moment de l'écriture.
Modifier la logique d'analyse en amont. Si vous savez que le format du log va changer, vous pouvez créer un pipeline de traitement parallèle et recevoir les deux versions du log pendant une période de transition. Cela s'applique généralement au format des logs dont vous avez le contrôle en interne.
Écrire un schéma minimal en cas d'échec d'analyse. Il est parfois impossible de connaître les modifications à l'avance, et il arrive que les logs dont nous n'avons pas le contrôle changent sans préavis. Vous pouvez prévoir cette possibilité dans le pipeline de logs dès le départ. En cas d'échec de l'analyse grok, utilisez le schéma minimal qui sépare l'horodatage du reste du message, puis envoyez un message à l'opérateur. À partir de là, vous pouvez créer un champ scripté pour le nouveau format du log afin de ne pas interrompre le workflow de l'analyste, modifier le pipeline, puis envisager de réindexer les champs pour la durée de l’interruption dans la logique d'analyse.
Retarder l'événement d'écriture en cas d'échec d'analyse. Si aucun schéma minimal ne répond à vos besoins, vous pouvez empêcher l'écriture de la ligne de log en cas d'échec de la logique d'analyse, puis placer l'événement dans une "file d'attente de lettres mortes" (cette fonctionnalité est prête à l'emploi dans Logstash) avant d'envoyer une alerte à l'opérateur chargé de réparer la logique et de réexécuter les événements de la file d'attente de lettres mortes dans le nouveau pipeline d'analyse. Cette solution interrompt l'analyse, mais vous n'aurez pas à créer de champs scriptés ni à procéder à des réindexations.
Une analogie appropriée
Je ne pensais pas que cet article serait aussi long. Je vous félicite d'être arrivé jusqu'ici ! Les bonnes analogies m'aident à intérioriser les concepts. Neil Desai, spécialiste de la sécurité chez Elastic, m'a récemment présenté l'une des meilleures analogies pour comparer le "schéma de lecture" et le "schéma d'écriture". J'espère qu'elle vous sera utile.

Pour conclure, le choix vous appartient
Comme je l'ai annoncé dès le départ, il n'y a pas forcément une réponse unique pour chaque déploiement de logging centralisé qui nous indique le schéma à adopter. En réalité, la plupart des déploiements que nous observons sont à mi-chemin ; certains logs sont très structurés alors que d'autres suivent le schéma le plus simple (@timestamp et message). Tout dépend de ce que vous voulez faire avec les logs et de vos préférences. Préférez-vous la vitesse et l'efficacité des recherches structurées, ou la possibilité d'écrire les données aussi vite que possible sur le disque sans rien faire en amont ? La Suite Elastic accepte les deux approches.
Pour commencer à traiter des logs dans la Suite Elastic, déployez un cluster dans Elasticsearch Service ou téléchargez-le localement. Découvrez la nouvelle app Logs dans Kibana. Logs optimise votre workflow pour que vous puissiez traiter les logs, et ce, quelle que soit leur forme, que les logs soient structurés ou non.