Switching from the Java High Level Rest Client to the new Java API Client


 Share on Twitter
Share on TwitterShare on Twitter

 Share on LinkedIn
Share on LinkedInShare on LinkedIn

 Share on Facebook
Share on FacebookShare on Facebook

 Share by Email
Share by EmailShare by Email

 Print this page
Print this pagePrint
I'm often seeing questions on discuss related to the Java API Client usage. For this, in 2019, I started a GitHub repository to provide some code examples that actually work and answer the questions asked by the community.
Since then, the High Level Rest Client (HLRC) has been deprecated and the new Java API Client has been released.
In order to keep answering questions, I needed recently to upgrade the repository to this new client. Although it uses the same Low Level Rest Client behind the scenes and an upgrade documentation has been provided, it's not really trivial to upgrade it.
I found interesting to share all the steps I had to perform to do this. If you are "just looking" for the pull requests that made the upgrade, have a look at:
This blog post will detail some of the major steps you can see in those pull requests.
The Java High Level Rest Client
We are starting with a project with the following characteristics:
Maven project (but this can be applied to a Gradle project as well)
Running with Elasticsearch 7.17.16 using either:
docker compose
Using the High Level Rest Client 7.17.16
The client dependencies are:
<!-- Elasticsearch HLRC -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.16</version>
</dependency>
<!-- Jackson for json serialization/deserialization -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.15.0</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.0</version>
</dependency>We are checking if a local Elasticsearch instance is yet running or not on http://localhost:9200. If not, we are starting Testcontainers:
@BeforeAll
static void startOptionallyTestcontainers() {
client = getClient("http://localhost:9200");
if (client == null) {
container = new ElasticsearchContainer(
DockerImageName.parse("docker.elastic.co/elasticsearch/elasticsearch")
.withTag("7.17.16"))
.withPassword("changeme");
container.start();
client = getClient(container.getHttpHostAddress());
assumeNotNull(client);
}
}To build the client (RestHighLevelClient), we are using:
static private RestHighLevelClient getClient(String elasticsearchServiceAddress) {
try {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("elastic", "changeme"));
// Create the low-level client
RestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
.setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));
// Create the high-level client
RestHighLevelClient client = new RestHighLevelClient(restClient);
MainResponse info = client.info(RequestOptions.DEFAULT);
logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);
return client;
} catch (Exception e) {
logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);
return null;
}
}As you may have noticed, we are trying to call the GET / endpoint to make sure the client is actually connected before starting our tests:
MainResponse info = client.info(RequestOptions.DEFAULT);And then, we can start to run our tests, like this example:
@Test
void searchData() throws IOException {
try {
// Delete the index if exist
client.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);
} catch (ElasticsearchStatusException ignored) { }
// Index a document
client.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);
// Refresh the index
client.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);
// Search for documents
SearchResponse response = client.search(new SearchRequest("search-data").source(
new SearchSourceBuilder().query(
QueryBuilders.matchQuery("foo", "bar")
)
), RequestOptions.DEFAULT);
logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
}So if we want to upgrade this code to 8.11.3, we need to
- Upgrade the code to the new Elasticsearch Java API Client using the same 7.17.16 version
- Upgrade both server and client to 8.11.3
Another very nice strategy is to upgrade the server first and then the client. It requires that you set the compatibility mode of the HLRC:
RestHighLevelClient esClient = new RestHighLevelClientBuilder(restClient)
.setApiCompatibilityMode(true)
.build()I chose to do that in two steps so we have better control of the upgrade process and we avoid mixing problems. The first step of the upgrade is the biggest one. The second one is much lighter and mainly the difference is about the fact that Elasticsearch is now secured by default (password and SSL self-signed certificates).
In the rest of this post, I will sometime put as a comment the "old" Java code so you can easily compare what changed for the most important parts.
The new Elasticsearch Java API Client
So we need to modify our pom.xml from:
<!-- Elasticsearch HLRC -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.17.16</version>
</dependency>to:
<!-- Elasticsearch Java API Client -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>7.17.16</version>
</dependency>Easy, right?
Well, not that easy . . . because now our project does not compile anymore. So let's make the needed adjustments. First, we need to change the way we are creating an ElasticsearchClient instead of the RestHighLevelClient:
static private ElasticsearchClient getClient(String elasticsearchServiceAddress) {
try {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY,
new UsernamePasswordCredentials("elastic", "changeme"));
// Create the low-level client
// Before:
// RestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
// .setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));
// After:
RestClient restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))
.setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider))
.build();
// Create the transport with a Jackson mapper
ElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());
// And create the API client
// Before:
// RestHighLevelClient client = new RestHighLevelClient(restClient);
// After:
ElasticsearchClient client = new ElasticsearchClient(transport);
// Before:
// MainResponse info = client.info(RequestOptions.DEFAULT);
// After:
InfoResponse info = client.info();
// Before:
// logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);
// After:
logger.info("Connected to a cluster running version {} at {}.", info.version().number(), elasticsearchServiceAddress);
return client;
} catch (Exception e) {
logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);
return null;
}
}The main change is that we now have a ElasticsearchTransport class between the RestClient (Low Level) and the ElasticsearchClient. This class takes care of JSON encoding and decoding. This includes the serialization and deserialization of application classes, which previously had to be done manually and is now handled by the JacksonJsonpMapper.
Also note that request options are set on the client. We don't need anymore to pass the RequestOptions.DEFAULT whatever the API, here the info API (GET /):
InfoResponse info = client.info();The "getters" have been simplified a lot as well. So instead of calling info.getVersion().getNumber(), we now call info.version().number(). No more get prefix!
Using the new client
Let's switch the searchData() method we saw before to the new client. Deleting an index is now:
try {
// Before:
// client.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);
// After:
client.indices().delete(dir -> dir.index("search-data"));
} catch (/* ElasticsearchStatusException */ ElasticsearchException ignored) { }What can we see in this code?
We are heavily using lambda expressions now, which take a builder object as parameter. It requires to switch mentally to this new design pattern. But this is super smart actually as with your IDE, you just need to have auto completion to see exactly what are the options, without needing to import any class or just know the class name in advance. With some practice, it becomes a super elegant way to use the client. If you prefer using builder objects, they are still available, since this is what these lambda expressions use behind the scenes. However, it makes the code much more verbose, so you really should try using lambdas.
dir is here the Delete Index Request builder. We just need to define the index we want to delete with index("search-data").
The ElasticsearchStatusException changed to ElasticsearchException.
To index a single JSON document, we now do:
// Before:
// client.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);
// After:
client.index(ir -> ir.index("search-data").id("1").withJson(new StringReader("{\"foo\":\"bar\"}")));Same as we saw before, the use of lambdas (ir) is helping us to create the Index Request. Here we just have to define the index name (index("search-data")) and the id (id("1")) and provide the JSON document with withJson(new StringReader("{\"foo\":\"bar\"}")).
The refresh API call is now straightforward:
// Before:
// client.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);
// After:
client.indices().refresh(rr -> rr.index("search-data"));Searching is another beast. It will look complicated at the begining but you will see with some practice how easy it is to produce your code:
// Before:
// SearchResponse response = client.search(new SearchRequest("search-data").source(
// new SearchSourceBuilder().query(
// QueryBuilders.matchQuery("foo", "bar")
// )
// ), RequestOptions.DEFAULT);
// After:
SearchResponse<Void> response = client.search(sr -> sr
.index("search-data")
.query(q -> q
.match(mq -> mq
.field("foo")
.query("bar"))),
Void.class);The lambda expression parameters are builders:
sr is the SearchRequest builder.
q is the Query builder.
mq is the MatchQuery builder.
If you take a closer look at the code, you might see that it's very close to a json search request as we know it:
{
"query": {
"match": {
"foo": {
"query": "bar"
}
}
}
}Here is actually how I'm coding this, step by step:
client.search(sr -> sr, Void.class);I defined Void as the bean I want to return, which here means that I don't care about decoding the _source JSON field as I just want to access to the response object.
Then I want to define the index I want to search for data in:
client.search(sr -> sr.index("search-data"), Void.class);And because I want to provide a query, I'm basically writing:
client.search(sr -> sr
.index("search-data")
.query(q -> q),
Void.class);My IDE now helps me to find which query I want to use:
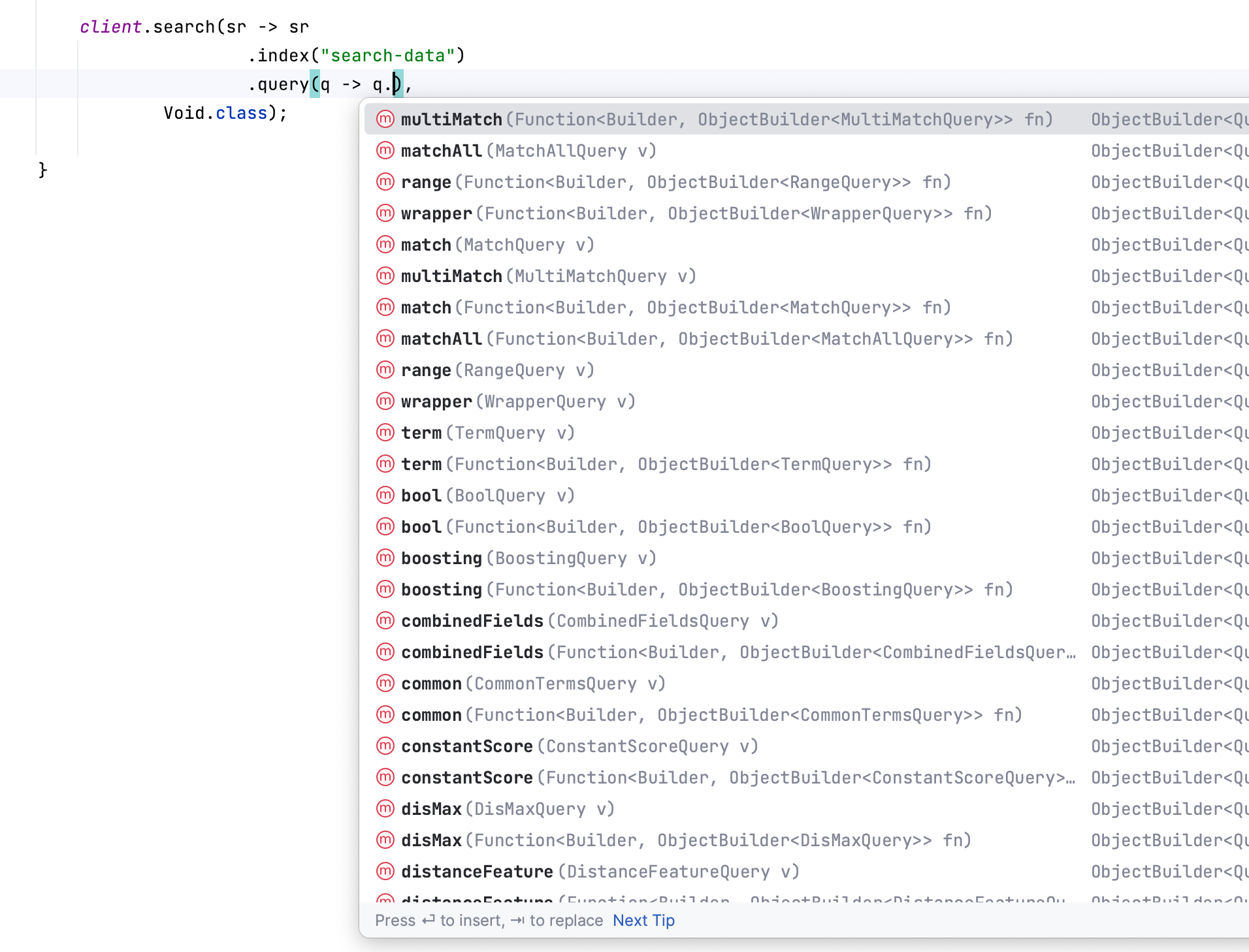
I want to use a Match query:
client.search(sr -> sr
.index("search-data")
.query(q -> q
.match(mq -> mq)),
Void.class);I just have to define the field I want to search on (foo) and the query I want to apply (bar):
client.search(sr -> sr
.index("search-data")
.query(q -> q
.match(mq -> mq
.field("foo")
.query("bar"))),
Void.class);I can now ask my IDE to generate a field from the result and I have my full call:
SearchResponse<Void> response = client.search(sr -> sr
.index("search-data")
.query(q -> q
.match(mq -> mq
.field("foo")
.query("bar"))),
Void.class);I can read from the response object the total number of hits with:
// Before:
// logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
// After:
logger.info("response.hits.total.value = {}", response.hits().total().value());Exists API
Let's see how we can switch the call to the exists API:
// Before:
boolean exists1 = client.exists(new GetRequest("test", "1"), RequestOptions.DEFAULT);
boolean exists2 = client.exists(new GetRequest("test", "2"), RequestOptions.DEFAULT);This can now become:
// After:
boolean exists1 = client.exists(gr -> gr.index("test").id("1")).value();
boolean exists2 = client.exists(gr -> gr.index("test").id("2")).value();Bulk API
To batch index/delete/update operations to Elasticsearch, you should definitely use the Bulk API:
BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
BulkResponse response = client.bulk(br -> {
br.index("bulk");
for (int i = 0; i < 1000; i++) {
br.operations(o -> o.index(ir -> ir.document(data)));
}
return br;
});
logger.info("bulk executed in {} ms {} errors", response.errors() ? "with" : "without", response.ingestTook());
if (response.errors()) {
response.items().stream().filter(p -> p.error() != null)
.forEach(item -> logger.error("Error {} for id {}", item.error().reason(), item.id()));
}Note that the operation can also be a DeleteRequest:
br.operations(o -> o.delete(dr -> dr.id("1")));BulkProcessor to BulkIngester helper
One of the nice HLRC feature I have always liked a lot is the BulkProcessor. It's like a "fire and forget" kind of feature, which is extremely useful when you want to send a lot of documents using a batch (the Bulk API).
As we saw previously, we need to manually wait for an array to be filled and then prepare the bulk request.
With the BulkProcessor, it's much easier. You just add your index/delete/update operations and the BulkProcessor will automatically create the bulk request anytime you are hitting a threshold:
Number of documents
Size of the global payload
A given timeframe
// Before:
BulkProcessor bulkProcessor = BulkProcessor.builder(
(request, bulkListener) -> client.bulkAsync(request, RequestOptions.DEFAULT, bulkListener),
new BulkProcessor.Listener() {
@Override public void beforeBulk(long executionId, BulkRequest request) {
logger.debug("going to execute bulk of {} requests", request.numberOfActions());
}
@Override public void afterBulk(long executionId, BulkRequest request, BulkResponse response) {
logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without");
}
@Override public void afterBulk(long executionId, BulkRequest request, Throwable failure) {
logger.warn("error while executing bulk", failure);
}
})
.setBulkActions(10)
.setBulkSize(new ByteSizeValue(1L, ByteSizeUnit.MB))
.setFlushInterval(TimeValue.timeValueSeconds(5L))
.build();Let's move that part to the new BulkIngester to inject our Person objects:
// After:
BulkIngester<Person> ingester = BulkIngester.of(b -> b
.client(client)
.maxOperations(10_000)
.maxSize(1_000_000)
.flushInterval(5, TimeUnit.SECONDS));Much more readable, right? One of the main points here is that you are not forced to provide a listener anymore, although I believe it's still a good practice to handle correctly errors. If you want to provide a listener, just do:
// After:
BulkIngester<Person> ingester = BulkIngester.of(b -> b
.client(client)
.maxOperations(10_000)
.maxSize(1_000_000)
.flushInterval(5, TimeUnit.SECONDS))
.listener(new BulkListener<Person>() {
@Override public void beforeBulk(long executionId, BulkRequest request, List<Person> persons) {
logger.debug("going to execute bulk of {} requests", request.operations().size());
}
@Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, BulkResponse response) {
logger.debug("bulk executed {} errors", response.errors() ? "with" : "without");
}
@Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, Throwable failure) {
logger.warn("error while executing bulk", failure);
}
});Whenever you need in your code, adding some requests to the BulkProcessor was:
// Before:
void index(Person person) {
String json = mapper.writeValueAsString(person);
bulkProcessor.add(new IndexRequest("bulk").source(json, XContentType.JSON));
}It's now:
// After:
void index(Person person) {
ingester.add(bo -> bo.index(io -> io
.index("bulk")
.document(person)));
}If you want to send raw json Strings, you should do this this way using Void type:
BulkIngester<Void> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10));With a proper bean, this would have bean something like:
void index(String json) {
BinaryData data = BinaryData.of(json.getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));
}When your application exits, you need to make sure that you are closing the BulkProcessor, which will cause the pending operations to be flushed before, so you won't be missing any document:
// Before:
bulkProcessor.close();Which is now easy to translate to:
// After:
ingester.close();Of course, you can omit the close() call when using a try-with-resources pattern as the BulkIngester is AutoCloseable:
try (BulkIngester<Void> ingester = BulkIngester.of(b -> b
.client(client)
.maxOperations(10_000)
.maxSize(1_000_000)
.flushInterval(5, TimeUnit.SECONDS)
)) {
BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
for (int i = 0; i < 1000; i++) {
ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));
}
}Bonus
We have already touched that a bit in the BulkIngester part, but one of the great additions added by the new Java API Client is that you can now provide Java Beans instead of doing our serialization/deserialization manually. And this is a time saver when it comes to coding.
So to index a Person object, we can do:
void index(Person person) {
client.index(ir -> ir.index("person").id(person.getId()).document(person));
}The power in my humble opinion comes with the search. We can now read directly our entities:
client.search(sr -> sr.index("search-data"), Person.class);
SearchResponse<Person> response = client.search(sr -> sr.index("search-data"), Person.class);
for (Hit<Person> hit : response.hits().hits()) {
logger.info("Person _id = {}, id = {}, name = {}",
hit.id(), // Elasticsearch _id metadata
hit.source().getId(), // Person id
hit.source().getName()); // Person name
}Here the source() method gives directly access to the Person instance. You don't need anymore to deserialize yourself the json _source field.
Share
- Share on Twitter
Share on Twitter
- Share on LinkedIn
Share on LinkedIn
- Share on Facebook
Share on Facebook
- Share by Email
Share by Email
- Print this page
Print