Universal Profiling
Optimisation et durabilité favorisées avec le profilage continu
Adoptez une approche écologique grâce à la visibilité complète des systèmes au sein des environnements cloud-native complexes. Avec le profilage fluide ininterrompu basé sur OpenTelemetry, vous pouvez optimiser les performances à tous les niveaux de votre application, de vos services et de votre infrastructure sans qu'aucune instrumentation ne soit nécessaire.
L'ingénierie de performance associée à la durabilité avec la disponibilité générale d'Elastic Universal Profiling
En savoir plusDécouvrez la dernière contribution d'Elastic : l'agent Universal Profiling
Lire l'articleElastic a été nommée "Visionary" dans le rapport Gartner 2023 "Magic Quadrant for Application Performance Monitoring". Découvrez pourquoi.
En savoir plusUn profilage qui s'exécute de manière ininterrompue
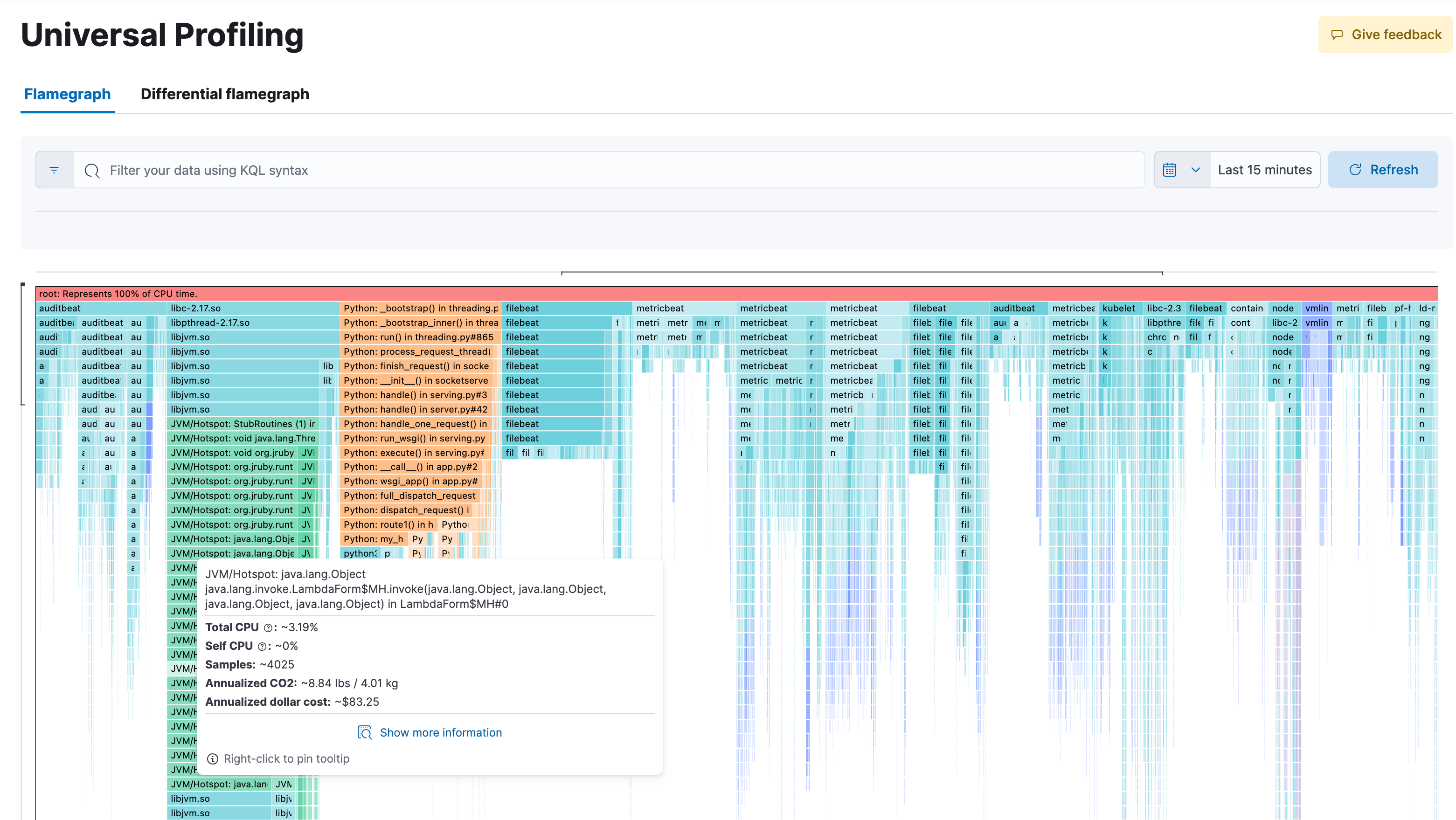
Bénéficiez d'une visibilité sans précédent à tous les niveaux avec un profilage ininterrompu de l'ensemble du système. En s'appuyant sur la technologie eBPF et sur OpenTelemetry, Universal Profiling profile chaque ligne de code qui s'exécute sur votre machine. Cet agent s'intéresse non seulement au code de votre application, mais aussi au noyau et aux bibliothèques tierces. En recueillant uniquement les données nécessaires d'une manière peu encombrante, il peut s'exécuter en continu sur les systèmes de production sans aucune conséquence notable. (La surcharge processeur est inférieure à 1 % !) Aucune instrumentation ni aucune modification intrusive du code n'est requise.
L'optimisation des performances à votre portée
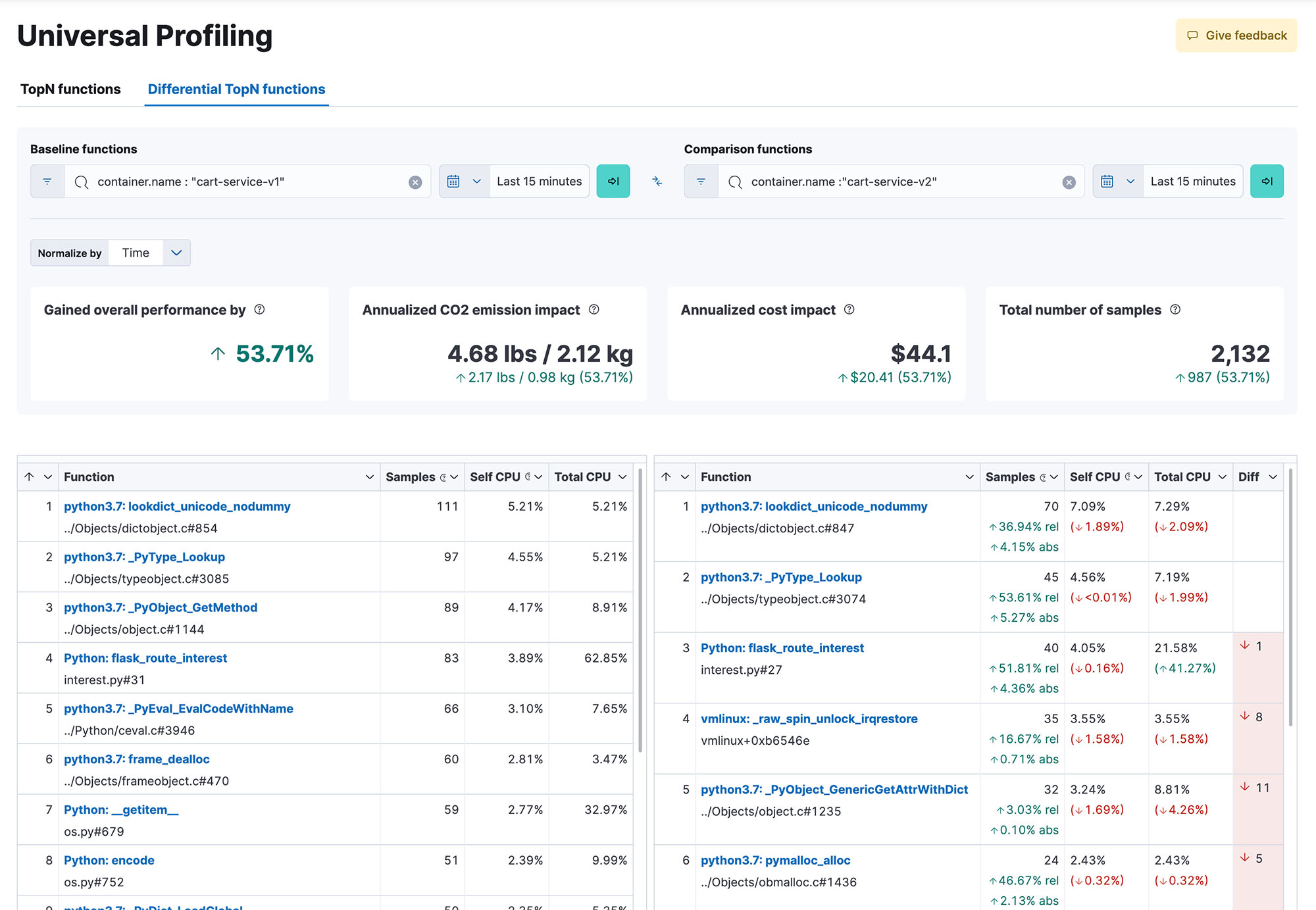
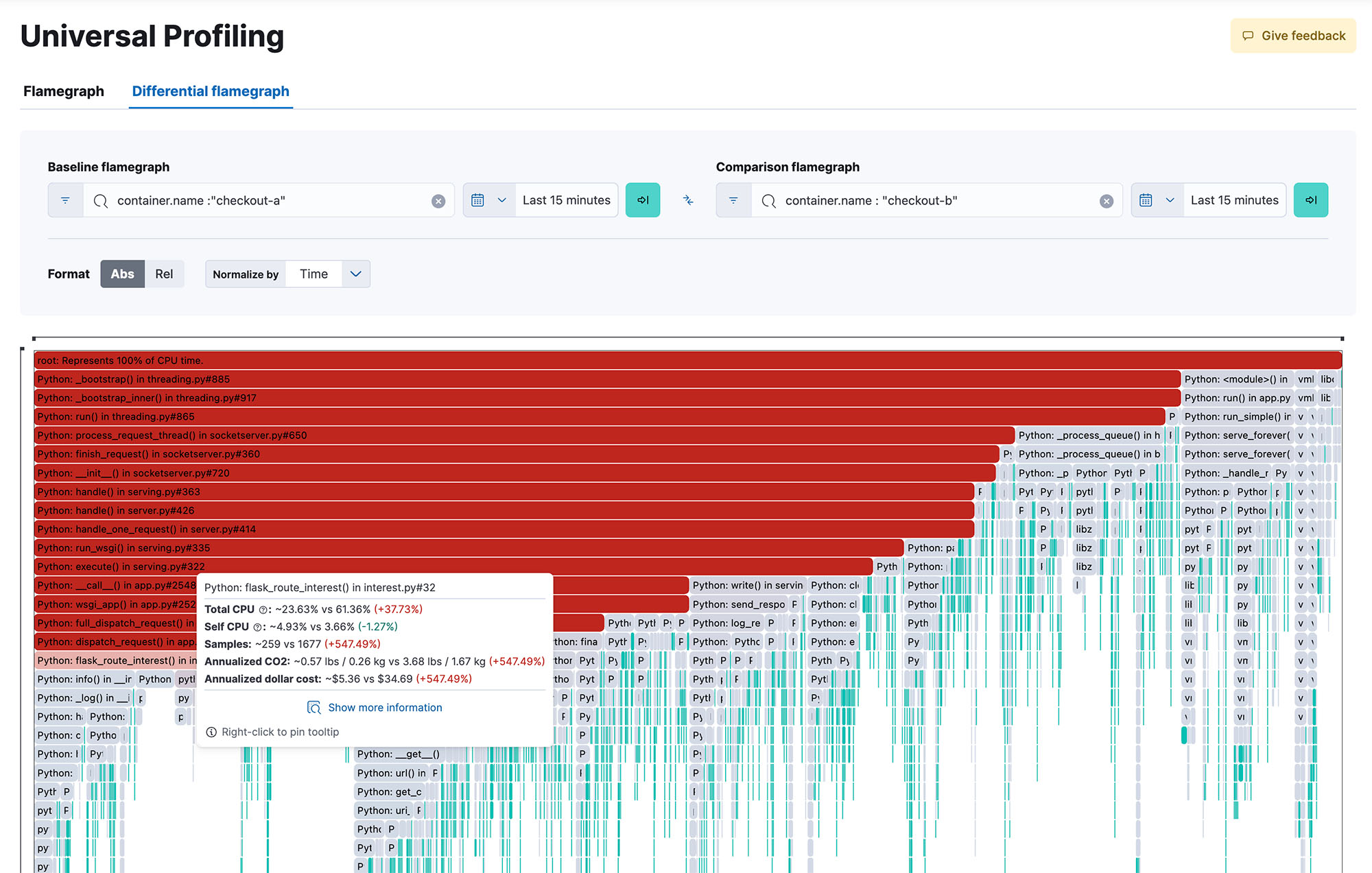
Bénéficiez d'une visibilité complète du système dans l'intégralité de votre code lors de son exécution, toutes méthodes, toutes classes, tous threads et tous conteneurs confondus. En outre, vous pouvez comparer les versions afin d'identifier les régressions de performance. Grâce à des flame-graphs réactifs et simples d'utilisation, vous pouvez explorer les performances de l'ensemble de votre système dans une vue unique. Repérez le code le plus gourmand en ressources afin d'identifier et d'éliminer les goulets d'étranglement en matière de performances, d'optimiser les dépenses liées au cloud et de réduire l'empreinte carbone de votre infrastructure.
Un déploiement fluide et flexible
Avec Elastic Universal Profiling, il n'y a pas besoin de changer le code source d'une application. De même, aucune instrumentation ni aucune autre opération intrusive ne sont nécessaires. Déployez simplement l'agent et recevez les données de profilage en seulement quelques minutes. L'agent peut être déployé à l'aide d'Elastic Agent, exécuté manuellement en tant que binaire natif ou en tant que conteneur Docker privilégié, ou bien déployé de façon automatique avec le framework d'orchestration de votre cluster.
Une vaste prise en charge de l'écosystème
La prise en charge du profilage comprend des traces linguistiques mixtes sur presque tous les environnements d'exécution linguistiques, dont : PHP, Python, Java (ou tout langage JVM), Go, Rust, C/C++, Node.js/V8, Ruby, Perl et Zig. À cela s'ajoute une prise en charge des principaux frameworks de conteneurisation et d'orchestration, qu'ils s'exécutent sur site ou qu'ils soient adossés à une plateforme Kubernetes gérée, comme GKE, AKS ou EKS.

Le profilage continu d'un système dans son ensemble, un moyen parmi d'autres pour observer vos charges de travail
Monitorez votre infrastructure, vos logs et vos utilisateurs, à partir d'une seule et même solution.