Qu'est-ce que la génération augmentée de récupération (RAG) ?
Définition de la Génération augmentée de récupération (RAG)
La génération augmentée de récupération (RAG) est une technique qui complète la génération de texte avec des informations provenant de sources de données privées ou propriétaires. Elle combine un modèle de récupération, conçu pour effectuer des recherches dans de grands ensembles de données ou bases de données, à un modèle de génération tel qu'un grand modèle de langage (LLM), qui extrait des informations et génère une réponse texte lisible.
La génération augmentée de récupération peut améliorer la pertinence de l'expérience de recherche, en ajoutant du contexte provenant de sources de données supplémentaires et en complétant une base de données de LLM originale grâce à un entraînement. Cela améliore les résultats du grand modèle de langage, sans avoir besoin d'entraîner de nouveau le modèle. Les autres sources d'informations peuvent aller de nouvelles informations sur Internet pour lesquelles le LLM n'a pas été entraîné, à du contexte commercial propriétaire, en passant par des documents internes confidentiels appartenant à des entreprises.
La RAG est précieuse pour différentes tâches, comme les réponses aux questions et la génération de contenu, car elle permet au système d'IA générative d'utiliser des sources d'informations externes pour produire des réponses plus précises et plus sensibles au contexte. Il implémente des méthodes de récupération de recherche, généralement de recherche sémantique ou de recherche hybride, pour répondre à l'intention de l'utilisateur et délivrer des résultats plus pertinents.
Apprenez en plus sur la génération augmentée de récupération (RAG) et découvrez comment cette approche lie vos données propriétaires en temps réel aux modèles d'IA générative pour offrir de meilleures expériences utilisateur et une meilleure précision.
Alors, la récupération d'informations, qu'est-ce que c'est ?
La récupération d'informations (IR) fait référence au processus de recherche et d'extraction d'informations pertinentes à partir d'une source de connaissances ou d'un ensemble de données. Ça ressemble beaucoup au fait d'utiliser un moteur de recherche pour rechercher des informations sur Internet. Vous entrez une recherche, et le système récupère et vous montre les documents ou pages web les plus susceptibles de contenir les informations que vous recherchez.
La récupération d'informations implique des techniques visant à indexer et à rechercher de façon efficace de grands ensembles de données ; il est ainsi plus facile d'accéder aux informations spécifiques dont vous avez besoin à partir d'un large pool de données disponibles. En plus des moteurs de recherche web, les systèmes d'IR sont souvent utilisés dans les bibliothèques numériques, les systèmes de gestion de documents et diverses applications d'accès aux informations.
L'évolution des modèles de langage d'IA
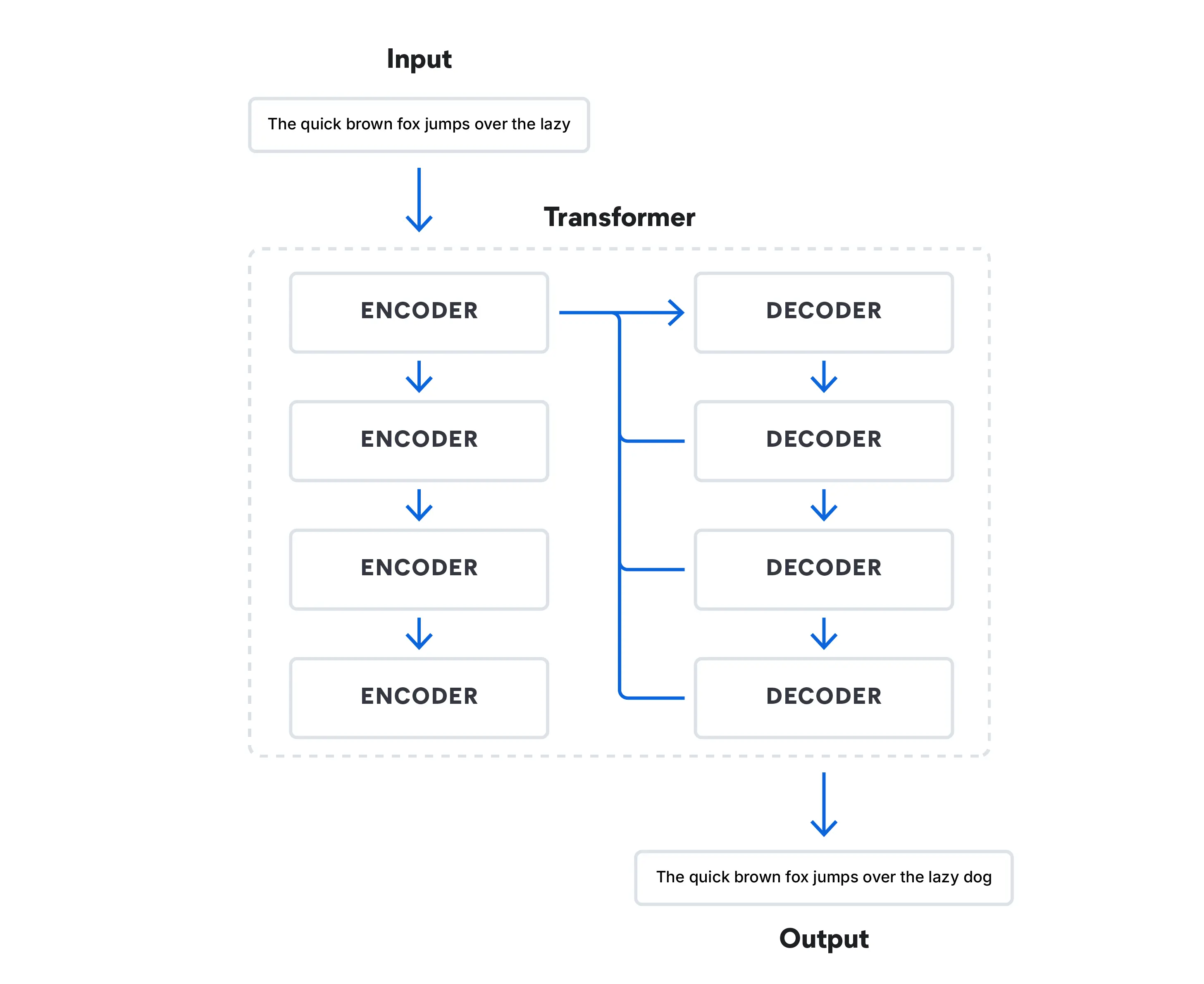
Les modèles de langage d'IA ont considérablement évolué au fil des années :
- Dans les années 1950 et 1960, le domaine n'en était qu'à ses balbutiements, avec des systèmes simples basés sur des règles avec une compréhension limitée du langage.
- Les années 1970 et 1980 ont introduit des systèmes experts : ils encodaient des connaissances humaines pour résoudre des problèmes, mais avaient des capacités linguistiques très limitées.
- Les années 1990 ont vu apparaître les méthodes statistiques, qui utilisaient des approches axées sur les données pour des tâches de langage.
- Dans les années 2000, les techniques de Machine Learning comme les machines à vecteurs de support (qui catégorisaient différents types de données textuelles dans un espace à haute dimensionnalité) avaient émergé, bien que le Deep Learning n'en soit encore qu'à ses débuts.
- Les années 2010 ont marqué un changement radical dans le Deep Learning. L'architecture Transformer a changé le traitement du langage naturel avec son utilisation de mécanismes d'attention, qui a permis aux modèles de se concentrer sur différentes parties d'une séquence d'entrée lors de son traitement.
Aujourd'hui, les modèles Transformer traitent les données d'une façon pouvant simuler un discours humain, en prédisant le mot qui suit dans une séquence de mots. Ces modèles ont révolutionné le domaine et mené à la montée des LLM, tels que BERT (Bidirectional Encoder Representations from Transformers) de Google.
Nous voyons une combinaison de gros modèles pré-entraînés et de modèles spécialisés conçus pour des tâches spécifiques. Des modèles tels que la RAG continuent à gagner du terrain, étendant la portée des modèles de langage d'IA générative par-delà les limites de l'entraînement standard. En 2022, OpenAI a lancé ChatGPT, qui est probablement le LLM basé sur une architecture Transformer le plus connu qui soit. Parmi ses concurrents se trouvent des modèles de fondation basés sur le chat tels que Google Bard et Bing Chat de Microsoft. LLaMa 2 de Meta, qui n'est pas un chatbot de consommateur, mais un LLM open source, est disponible librement pour les chercheurs qui savent comment fonctionnent les LLM.
Article connexe : Choisir un LLM : le guide 2024 de prise en main des grands modèles de langage open source
Comment fonctionne la RAG ?
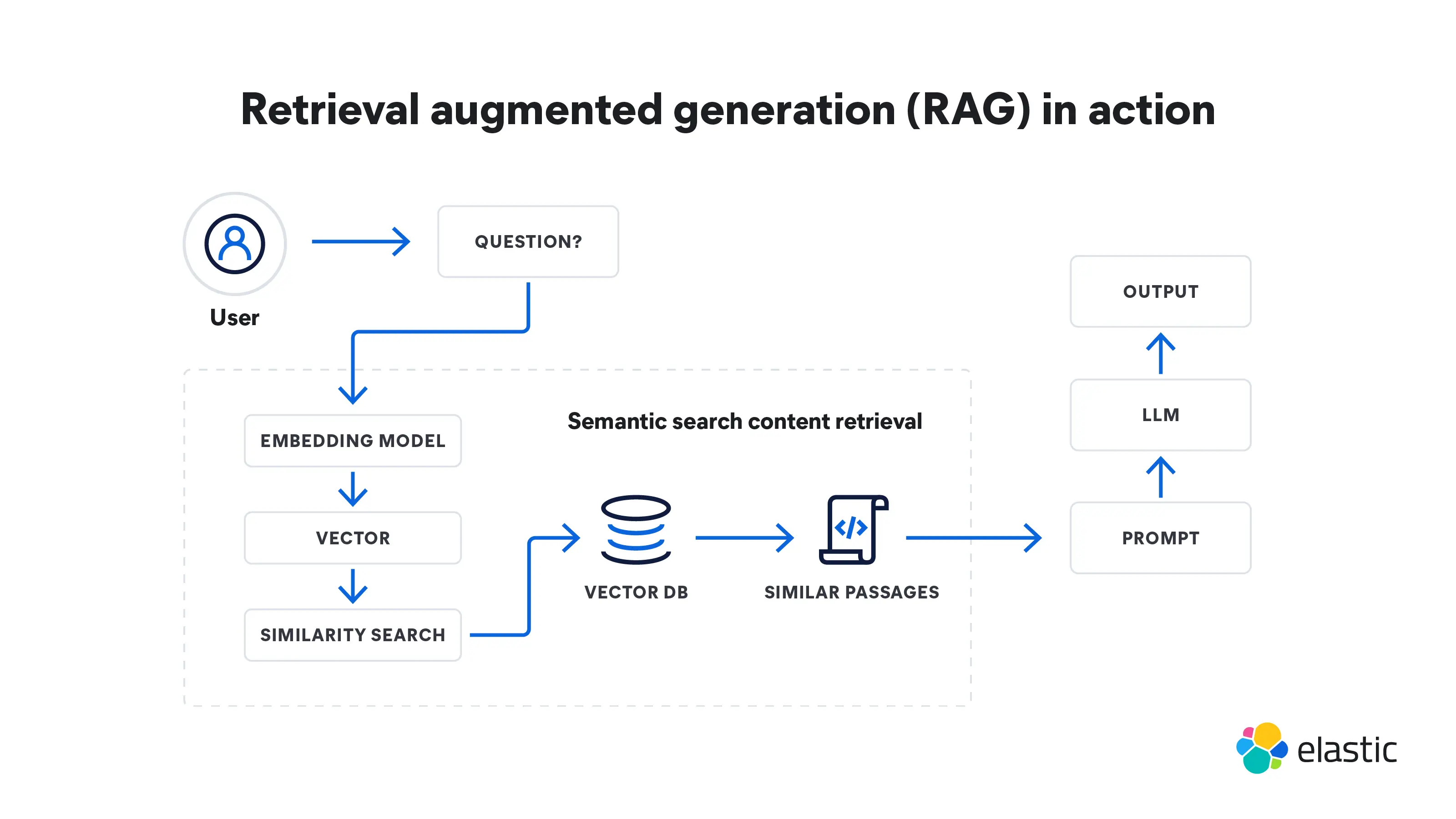
La génération augmentée de récupération est un processus à plusieurs étapes qui commence avec la récupération, pour aller jusqu'à la génération. Voici comment elle fonctionne :
Récupération
- La RAG commence avec une requête d'entrée. Il peut s'agir d'une question d'un utilisateur ou d'une partie de texte nécessitant une réponse détaillée.
- Un modèle de récupération se saisit d'informations pertinentes provenant de bases de connaissances, de bases de données ou de sources externes, voire de plusieurs sources en même temps. L'endroit où le modèle effectue ses recherches dépend de ce que demande la requête d'entrée. Les informations récupérées servent désormais de sources de référence pour les faits et le contexte dont le modèle a besoin.
- Les informations récupérées sont converties en vecteurs dans un espace à haute dimensionnalité. Ces vecteurs de connaissances sont stockés dans une base de données vectorielle.
- Le modèle de récupération classe les informations récupérées sur la base de leur pertinence avec la requête d'entrée. Des documents ou des passages ayant le score le plus élevé sont sélectionnés pour un traitement supplémentaire.
Génération
- Ensuite, un modèle de génération, comme un LLM, utilise les informations récupérées pour générer des réponses texte.
- Le texte généré peut passer par des étapes post-traitement supplémentaires pour garantir qu'il est grammaticalement correct et cohérent.
- Ces réponses sont globalement plus précises et ont plus de sens en contexte, car elles ont été modelées par les informations supplémentaires fournies par le modèle de récupération. Cette capacité est particulièrement importante dans des domaines spécialisés dans lesquels les données Internet publiques ne sont pas suffisantes.
Avantages de RAG
La génération augmentée de récupération a plusieurs avantages par rapport aux modèles de langage qui fonctionnent de façon isolée. Voici plusieurs façons dont elle a amélioré la génération de texte et les réponses :
- La RAG s'assure que votre modèle peut accéder aux derniers faits et informations pertinentes les plus à jour, car elle met régulièrement à jour ses références externes. Cela garantit que les réponses qu'il génère incorporent les dernières informations qui pourraient être pertinentes pour l'utilisateur qui réalise la requête. Vous pouvez également implémenter une sécurité au niveau des documents pour contrôler l'accès aux données au sein d'un flux de données et restreindre les autorisations de sécurité à des documents en particulier.
- La RAG est une option plus rentable, car elle requiert moins d'informatique et de stockage, ce qui signifie que vous n'avez plus à posséder votre propre LLM ou à dépenser du temps et de l'argent à affiner votre modèle.
- C'est une chose de revendiquer l'exactitude, mais encore faut-il la prouver. La RAG peut citer ses sources externes et les fournir à l'utilisateur pour étayer ses réponses. S'il le décide, l'utilisateur peut alors évaluer les sources pour confirmer que la réponse reçue est exacte.
- Bien que les chatbots alimentés par LLM puissent élaborer des réponses plus personnalisées que les réponses scriptées d'avant, la RAG peut adapter encore plus ses réponses. C'est la raison pour laquelle il peut utiliser des méthodes de récupération de recherche (généralement une recherche sémantique) pour indiquer en référence toute une gamme de points contextuels lorsqu'il synthétise sa réponse en mesurant l'intention.
- Lorsqu'il est confronté à une requête complexe pour laquelle il n'a pas été entraîné, un LLM peut parfois "halluciner" et fournir une réponse inexacte. En fournissant une base solide à ses réponses grâce à des références supplémentaires provenant de sources de données pertinentes, la RAG peut répondre de façon plus précise à des demandes ambiguës.
- Les modèles de RAG sont polyvalents et peuvent être appliqués à toute une gamme de tâches de traitement du langage naturel, y compris des systèmes de dialogue, de la génération de contenu et de la récupération d'informations.
- Les partis pris peuvent être un problème dans de nombreuses IA créées par l'être humain. En se fiant à des sources externes approuvées, la RAG peut aider à diminuer les partis pris dans ses réponses.
Génération augmentée de récupération ou ajustement
La génération augmentée de récupération et l'ajustement sont deux approches différentes de l'entraînement des modèles de langage d'IA. Là où la RAG associe la récupération d'un large éventail de connaissances externes à de la génération de texte, l'ajustement se concentre sur une gamme limitée de données à des fins distinctes.
Dans l'ajustement, un modèle pré-entraîné est entraîné davantage sur des données spécialisées pour les adapter à un sous-ensemble de tâches. Cela implique de modifier les pondérations et les paramètres du modèle sur la base du nouvel ensemble de données, lui permettant ainsi d'apprendre des modèles de tâches spécifiques tout en conservant les connaissances acquises de par son pré-entraînement initial.
L'ajustement peut être utilisé pour tout type d'IA. Un exemple simple consiste à apprendre à reconnaître des chatons dans le contexte de l'identification de photos de chats sur Internet. Dans les modèles basés sur le langage, l'ajustement peut aider à réaliser des tâches telles que la classification de texte, l'analyse du sentiment et la reconnaissance d'une entité nommée, en plus de la génération de texte. Cependant, ce processus peut être extrêmement chronophage et coûteux. La RAG accélère le processus et réunit ces coûts en diminuant les besoins en informatique et en stockage.
Parce qu'elle a accès à des ressources externes, la RAG est particulièrement utile lorsqu'une tâche exige d'incorporer des informations en temps réel ou dynamiques depuis Internet ou des bases de connaissances d'entreprise pour générer des réponses éclairées. L'ajustement présente différents atouts : si la tâche en question est bien définie et que l'objectif est d'optimiser les performances sur cette tâche seule, l'ajustement peut être très efficace. Les deux techniques présentent l'avantage de ne pas devoir entraîner de LLM à partir de rien pour chaque tâche.
Défis et limites de la génération augmentée de récupération
Bien que la RAG offre des avantages importants, elle doit également faire face à plusieurs défis et limites :
- La RAG repose sur des connaissances extérieures. Elle peut produire des résultats inexacts si les informations récupérées sont incorrectes.
- Le composant de récupération de la RAG implique de rechercher des informations dans d'importantes bases de données sur Internet, ce qui peut s'avérer informatiquement coûteux et lent, bien que cela reste plus rapide et moins cher que l'ajustement.
- L'intégration fluide des composants de récupération et de génération nécessite une conception et une automatisation prudentes, ce qui peut conduire à de potentielles difficultés lors de l'entraînement et du déploiement.
- La récupération d'informations à partir de sources externes peut soulever des préoccupations de confidentialité lorsqu'il s'agit de traiter des données sensibles. Le fait d'adhérer à des exigences de confidentialité et de conformité peut également limiter les sources auxquelles la RAG peut accéder. Toutefois, ce problème peut être résolu par un accès au niveau du document, dans lequel vous accordez des autorisations d'accès et de sécurité à des rôles spécifiques.
- La RAG se base sur une exactitude factuelle. Il peut avoir du mal à générer du contenu créatif ou fictif, ce qui limite son utilisation dans la génération de contenu créatif.
Tendances à venir concernant la génération augmentée de récupération
Les tendances à venir de la génération augmentée de récupération se concentrent sur comment rendre la technologie de RAG plus efficace et adaptable sur diverses applications. Voici quelques tendances à surveiller :
Personnalisation
Les modèles de RAG continueront à incorporer des connaissances spécifiques. Cela leur permettra de fournir des réponses encore plus personnalisées, en particulier dans des applications comme les recommandations de contenu et les assistants virtuels.
Comportement personnalisable
En plus de la personnalisation, les utilisateurs eux-mêmes peuvent également bénéficier d'un contrôle accru sur la façon dont les modèles de RAG se comportent et répondent lorsqu'il s'agit de les aider à obtenir les résultats qu'ils recherchent.
Scalabilité
Les modèles de RAG pourront gérer des volumes encore plus importants de données et d'interactions utilisateur qu'actuellement.
Modèles hybrides
L'intégration de la RAG à d'autres techniques d'IA (par exemple, l'apprentissage par renforcement) permettra d'avoir des systèmes encore plus polyvalents et sensibles au contexte qui pourront gérer simultanément divers types de données et de tâches.
Déploiement en temps réel et à latence faible
À mesure que les modèles de RAG améliorent leur délai de récupération et de temps de réponse, ils seront utilisés davantage dans des applications nécessitant des réponses rapides (tels que les chatbots et les assistants virtuels).
Découvrez les grandes tendances en matière de recherche technique pour 2024. Regardez ce webinar pour vous familiariser avec les bonnes pratiques et les méthodologies émergentes, ainsi que pour découvrir les grandes tendances incontournables pour les développeurs en 2024.
Génération augmentée de récupération avec Elasticsearch
Avec Elasticsearch, vous pouvez créer une recherche qui utilise la RAG pour vos expériences d'application d'IA, de site web, de clients ou d'employés génératives. Elasticsearch fournit une boîte à outils complète qui vous permet de :
- Stocker et réaliser des recherches dans des données propriétaires et autres bases de données externes dans lesquelles puiser du contexte
- Générer des résultats de recherche hautement pertinents à partir de vos données à l'aide de plusieurs méthodes : recherche textuelle, vectorielle, hybride ou sémantique
- Créer des réponses plus précises et des expériences plus intéressantes pour vos utilisateurs
Découvrez comment Elasticsearch peut améliorer l'IA générative pour votre entreprise
Pour aller plus loin sur la RAG
- Découvrez AI Playground
- La RAG, au-delà des bases
- Elasticsearch – le moteur de recherche le plus pertinent pour la RAG
- Choisir un LLM : le guide 2024 de prise en main des grands modèles de langage open source
- Comprendre les algorithmes de recherche propulsée par l'IA
- Comment créer un chatbot : conseils et recommandations à l'attention des développeurs à l'ère de l'intelligence artificielle
- Tendances techniques de 2024 : l'évolution des technologies de recherche et d'IA générative
- Prototypez et intégrez plus rapidement les LLM
- La base de données vectorielle la plus téléchargée au monde : Elasticsearch
- Démystifier ChatGPT : différentes méthodes pour concevoir des solutions de recherche avec IA
- Récupération ou poison : contrer les attaques contre la chaîne d'approvisionnement de l'IA