Qu'est-ce que le Machine Learning supervisé ?
Définition du Machine Learning supervisé
Le Machine Learning supervisé est un type de Machine Learning (ML) utilisé pour entraîner des algorithmes à partir d'un ensemble de données étiquetées. En fournissant à l'algorithme un large ensemble de données déjà classifiées, on lui permet d'apprendre à prédire des résultats avec précision. Cette méthode est la plus courante en Machine Learning.
Elle repose sur la reconnaissance de modèles dans les données. En analysant un ensemble spécifique de données étiquetées, un algorithme peut détecter des modèles et générer des prédictions basées sur ces modèles lorsqu'il est sollicité. Pour arriver à une prédiction précise, le processus de Machine Learning supervisé nécessite la collecte de données, puis leur étiquetage. Ensuite, l'algorithme est entraîné sur ces données étiquetées afin de classifier des informations ou de prédire des résultats de manière fiable. La qualité des sorties dépend directement de la qualité des données : de meilleures données mènent à de meilleures prédictions.
Les exemples de machine learning supervisé vont de la reconnaissance d’images et d’objets à l’analyse des sentiments des clients, à la détection du spam et à l’analyse prédictive. Par conséquent, le machine learning supervisé est utilisé dans plusieurs secteurs tels que la santé, la finance et le commerce électronique pour aider à optimiser la prise de décision et stimuler l’innovation.
Comment fonctionne le Machine Learning supervisé ?
Le machine learning supervisé fonctionne en collectant et en étiquetant des données, puis en formant des modèles et en itérant le processus à l'aide de nouveaux ensembles de données. Le processus se déroule en deux étapes : définition du problème que le modèle est censé résoudre, puis collecte de données :
- Étape 1 : Définir le problème que le modèle est censé résoudre. Le modèle est-il utilisé pour faire des prédictions liées à l’entreprise, automatiser la détection du spam, analyser le sentiment des clients ou identifier des images ? Cela détermine les données qui seront requises, pour passer à l'étape suivante du workflow
- Étape 2 : Collecte des données. Une fois les données étiquetées, elles sont transmises à l’algorithme en cours de formation. Le modèle est ensuite testé, affiné et déployé pour effectuer des tâches de classification ou de régression.
Collecte de données et étiquetage
La collecte de données est la première étape du Machine Learning supervisé. Les données peuvent provenir de diverses sources, telles que des bases de données, des capteurs ou des interactions utilisateurs. Elles sont ensuite prétraitées pour garantir leur cohérence et leur pertinence. Une fois collecté, cet ensemble de données volumineux est étiqueté. Chaque élément de données d'entrée reçoit une étiquette correspondante. Bien que la classification des données puisse être longue et coûteuse, elle est essentielle pour apprendre au modèle à reconnaître des modèles et à faire des prédictions. La qualité et la précision de ces étiquettes influencent directement la capacité du modèle à apprendre et à générer des prédictions pertinentes. Vos sorties dépendent directement de la qualité de vos données d'entrée.
Entraînement des modèles
Pendant l'entraînement, l'algorithme analyse les données d'entrée et apprend à les associer aux bonnes étiquettes de sortie. Ce processus implique l'ajustement des paramètres du modèle afin de minimiser la différence entre les sorties prédites et les étiquettes réelles. Le modèle améliore sa précision en apprenant de ses erreurs au cours de l'entraînement. Une fois le modèle entraîné, il est soumis à une évaluation. Des données de validation sont utilisées pour mesurer la précision du modèle. En fonction des résultats obtenus, le modèle est ajusté si nécessaire.
Plus un modèle absorbe de données, plus il apprend de modèles, et plus ses prédictions deviennent précises — en théorie. L'apprentissage continu est un pilier du Machine Learning : la performance d’un modèle s'améliore à mesure qu'il continue à apprendre à partir de jeux de données étiquetés.
Une fois déployé, le Machine Learning supervisé peut accomplir deux types de tâches : la classification et la régression.
La classification repose sur un algorithme qui attribue une classe à un point de données ou à un ensemble de données discrètes. En d'autres termes, elle permet de distinguer différentes catégories de données. Dans les problèmes de classification, la frontière de décision établit les classes.
La régression repose sur un algorithme qui comprend la relation entre des variables dépendantes et indépendantes continues. Dans les problèmes de régression, la frontière de décision établit la ligne de meilleure adéquation ou la proximité probabiliste.
Algorithmes de Machine Learning supervisé
Différents algorithmes et techniques sont utilisés en Machine Learning supervisé pour les tâches de classification et de régression, allant de la classification de texte aux prédictions statistiques.
Arbre de décision
Un algorithme d'arbre de décision est un algorithme d'apprentissage supervisé non paramétrique, composé d'un nœud racine, de branches, de nœuds internes et de nœuds feuilles. Les données entrent par le nœud racine, passent par les branches jusqu'aux nœuds internes, où l'algorithme traite les entrées et prend une décision, produisant des nœuds feuilles comme sortie. Les arbres de décision peuvent être utilisés pour des tâches de classification et de régression. Ce sont des outils utiles pour l'exploration de données et la découverte de connaissances, car ils permettent à l'utilisateur de suivre pourquoi une sortie a été produite ou pourquoi une décision a été prise. Cependant, les arbres de décision sont sujets au surapprentissage (overfitting) et ont du mal à gérer des structures plus complexes. C'est pourquoi les arbres de décision plus petits sont souvent plus efficaces.
Régression linéaire
Les algorithmes de régression linéaire prédisent la valeur d'une variable - la variable dépendante - en fonction de la valeur d'une autre variable - la variable indépendante. Les prédictions sont basées sur le principe d'une relation linéaire entre les variables, ou sur le fait qu'il existe une connexion « linéaire » entre des variables continues telles que le salaire, le prix ou l'âge. Les modèles de régression linéaire sont utilisés pour faire des prédictions dans les domaines de la biologie, des sciences sociales, environnementales et comportementales, et des affaires.
Réseaux de neurones
Les réseaux de neurones utilisent des nœuds composés d'entrées, de poids, de seuils (souvent appelés biais) et de sorties. Ces nœuds sont organisés en couches — une couche d'entrée, des couches cachées et une couche de sortie — qui ressemblent au fonctionnement du cerveau humain, d'où le terme neuronal. Les réseaux de neurones, considérés comme des algorithmes de deep learning, construisent une base de connaissances à partir de données d'entraînement étiquetées, leur permettant ainsi d'identifier des modèles et des relations complexes au sein des données. Les réseaux de neurones sont un système adaptatif capable d'« apprendre » de ses erreurs pour s'améliorer en continu. Ils sont utilisés dans des applications telles que la reconnaissance d'images et le traitement du langage.
Random forest
Les algorithmes de forêt aléatoire (random forest) sont un ensemble de plusieurs algorithmes d'arbres de décision non corrélés, programmés pour produire un résultat unique à partir de multiples sorties. Les paramètres des forêts aléatoires incluent la taille des nœuds, le nombre d'arbres et le nombre de caractéristiques. Ces hyperparamètres sont définis avant l'entraînement. L'utilisation de fonctionnalités de bagging et de randomisation des caractéristiques garantit une variabilité des données dans le processus décisionnel, produisant ainsi des prédictions plus précises. C'est la principale différence entre les arbres de décision et les forêts aléatoires. En conséquence, les forêts aléatoires offrent une plus grande flexibilité. Le bagging des fonctionnalités permet d'estimer les valeurs manquantes, assurant ainsi une meilleure précision lorsque certains points données sont absents.
Machine à vecteurs de support (SVM)
Les machines à vecteurs de support (SVM) sont principalement utilisées pour la classification des données et, occasionnellement, pour la régression. Pour les applications de classification, un SVM construit une frontière de décision permettant de distinguer ou classer des points de données, par exemple des fruits contre des légumes, ou des mammifères contre des reptiles. Les SVM peuvent être utilisés dans des applications de reconnaissance d'images ou de classification de texte.
Naïve Bayes
L'algorithme Naïve Bayes est un algorithme de classification probabiliste basé sur le théorème de Bayes. Il suppose que les fonctionnalités d'un ensemble de données sont indépendantes et que chaque caractéristique, ou prédicteur, a un poids égal dans le résultat. Cette hypothèse est dite « naïve » car elle est souvent contredite dans des scénarios réels, où les caractéristiques peuvent être dépendantes. Par exemple, le prochain mot dans une phrase dépend généralement de celui qui le précède. Malgré cela, la probabilité individuelle de chaque variable rend les algorithmes Naïve Bayes très efficaces sur le plan computationnel, en particulier pour des tâches comme la classification de texte et le filtrage anti-spam.
K plus proches voisins (kNN)
L'algorithme des k plus proches voisins (KNN) est un algorithme d'apprentissage supervisé qui utilise la proximité des variables pour prédire des sorties. En d'autres termes, il repose sur l'hypothèse que des points de données similaires se trouvent à proximité les uns des autres. Une fois entraîné sur des données étiquetées, l'algorithme calcule la distance entre une requête et les données qu'il a mémorisées — sa base de connaissances — pour formuler une prédiction. Le KNN peut utiliser différentes méthodes de calcul de distance (Manhattan, Euclidienne, Minkowski, Hamming) pour établir la frontière de décision sur laquelle repose la prédiction. Le KNN est utilisé pour des tâches de classification et de régression, y compris le classement par pertinence, la recherche de similarité, la reconnaissance de motifs et les moteurs de recommandation de produits.
Défis et limitations du Machine Learning supervisé
Bien que le Machine Learning supervisé permette des prédictions d'une grande précision, il s'agit d'une technique gourmande en ressources. Cela repose sur des processus d'étiquetage de données coûteux, nécessitant de grands ensembles de données, et, par conséquent, est vulnérable au surapprentissage (overfitting).
- Le coût de l'étiquetage des données : l'un des principaux défis de l'apprentissage supervisé est la nécessité de disposer de grands ensembles de données étiquetées avec précision. La qualité de ces étiquettes est directement proportionnelle à la précision du modèle, ce qui rend la qualité primordiale. Ce processus est long et coûteux, nécessitant parfois des compétences d'expert, en fonction du domaine ou de la complexité des données, comme dans les secteurs de la santé ou des finances. Dans des secteurs comme la santé ou les finances, où les données sont sensibles et complexes, l'obtention d'ensemble de données étiquetés de haute qualité peut être particulièrement difficile.
- Besoin de grands ensembles de données : la dépendance des modèles supervisés à l'égard de grands ensembles de données représente un défi important pour deux raisons : la collecte et l'étiquetage de données de qualité en grande quantité sont très coûteux, et trouver le bon équilibre entre trop de données et suffisamment de bonnes données est délicat. Des ensembles de données volumineux sont nécessaires pour un entraînement efficace, mais des ensembles trop larges peuvent conduire à un surapprentissage (overfitting).
- Surapprentissage : le surapprentissage est une préoccupation courante dans l'apprentissage supervisé. Il se produit lorsqu'un modèle est exposé à trop de données d'entraînement et capte du bruit ou des détails non pertinents — il est possible d'avoir trop de données. Cela affecte la qualité des prédictions et conduit à une mauvaise performance sur des données nouvelles ou non vues. Pour contrer ou éviter le surapprentissage, les ingénieurs utilisent des techniques telles que la validation croisée, la régularisation ou l'élagage (pruning).
Le prétraitement des données est au cœur de ces défis. Bien qu'il puisse être long et coûteux, avec les bons outils, il permet de réduire les problèmes liés au coût, à la qualité et au surapprentissage.
Machine Learning supervisé vs non supervisé
Le Machine Learning peut être supervisé, non supervisé ou semi-supervisé. Chaque méthode d'entraînement des données produit des résultats différents et est utilisée dans des contextes variés. Le Machine Learning supervisé nécessite des ensembles de données étiquetées pour entraîner le modèle, mais améliore sa précision grâce à des ensembles de données volumineux et de haute qualité.
En revanche, le machine learning non supervisé utilise des ensembles de données non marquées pour former un modèle de prédiction. Le modèle identifie lui-même les modèles entre les points de données non étiquetés, ce qui entraîne parfois une précision moindre. Le learning non supervisé est souvent utilisé pour les tâches de regroupement, d'association ou de réduction de la dimensionnalité.
Machine Learning semi-supervisé
Le Machine Learning semi-supervisé est une combinaison des techniques supervisées et non supervisées. Les algorithmes semi-supervisés sont entraînés sur de petites quantités de données étiquetées et de grandes quantités de données non étiquetées. Cela permet d'obtenir de meilleurs résultats que les modèles non supervisés avec un nombre limité d'exemples étiquetés. Le semi-supervisé est une méthode hybride qui peut être particulièrement utile lorsque l'étiquetage de grands ensembles de données est peu pratique ou coûteux.
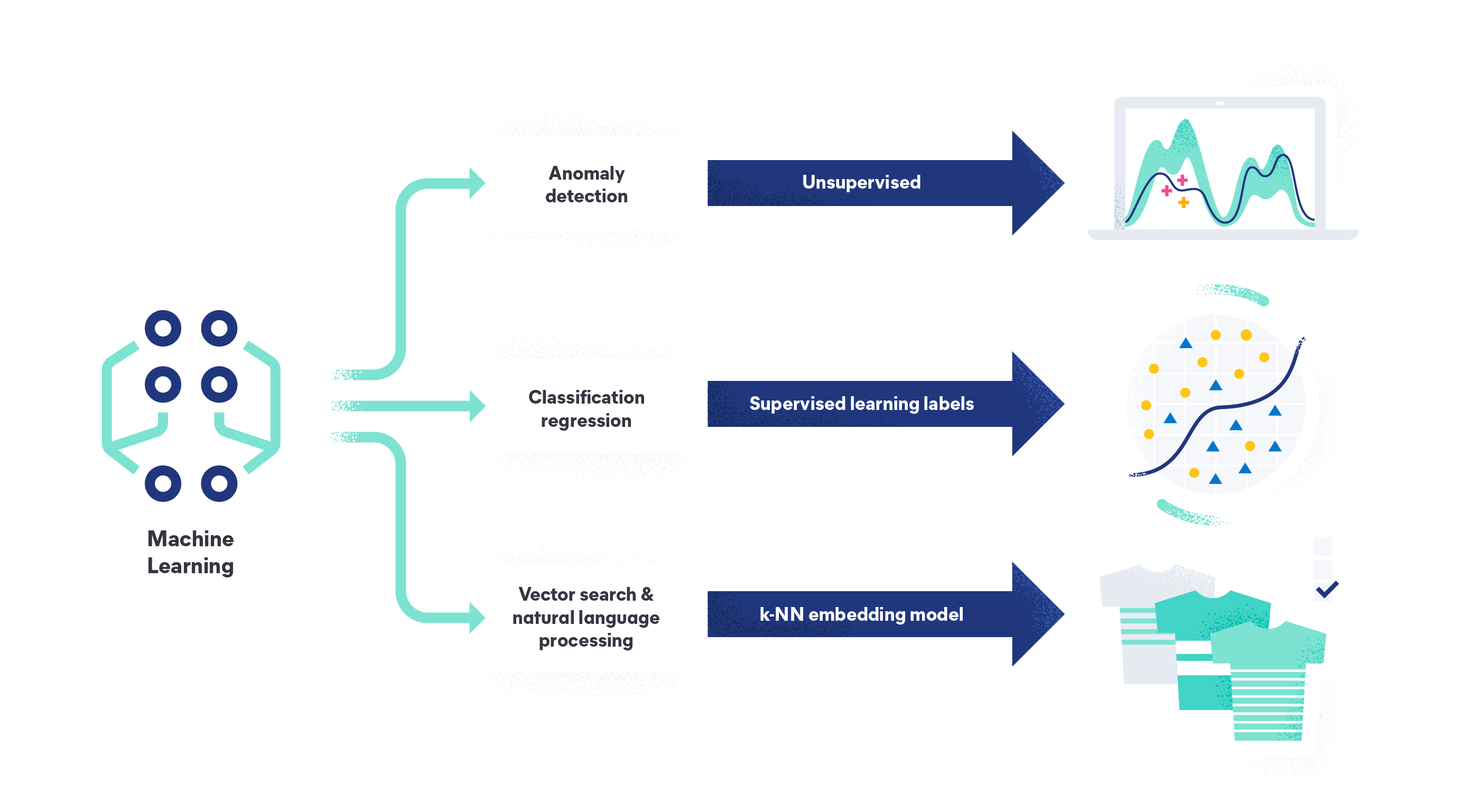
Comprendre la différence entre ces méthodes de Machine Learning est crucial pour choisir la solution adaptée à la tâche à accomplir.
Machine Learning en toute simplicité avec Elastic
Le Machine Learning commence par les données — c’est là qu’Elastic intervient.
Avec le machine learning d'Elastic, vous pouvez analyser vos données pour trouver des anomalies, effectuer des analyses de trames de données et analyser des données en langage naturel. Grâce au machine learning d'Elastic, il n'est plus nécessaire de faire appel à une équipe de science des données, de concevoir une architecture système en partant de zéro ou de transférer des données vers un framework tiers pour la formation des modèles. En tant que Search AI platform, nos fonctionnalités vous permettent d'ingérer, de comprendre et de créer des modèles à partir de vos données, ou de vous fier à notre modèle non supervisé prêt à l'emploi pour la détection des anomalies et des valeurs aberrantes.
Découvrez comment Elastic peut vous aider à relever vos défis liés aux données grâce au Machine Learning.