- Elasticsearch Guide: other versions:
- What is Elasticsearch?
- What’s new in 8.14
- Quickstart
- Set up Elasticsearch
- Installing Elasticsearch
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Miscellaneous cluster settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- Health Diagnostic settings
- Index lifecycle management settings
- Data stream lifecycle settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Monitoring settings
- Nodes
- Networking
- Node query cache settings
- Search settings
- Security settings
- Shard allocation, relocation, and recovery
- Shard request cache settings
- Snapshot and restore settings
- Transforms settings
- Thread pools
- Watcher settings
- Advanced configuration
- Important system configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Plugins
- Upgrade Elasticsearch
- Index modules
- Mapping
- Dynamic mapping
- Explicit mapping
- Runtime fields
- Field data types
- Aggregate metric
- Alias
- Arrays
- Binary
- Boolean
- Completion
- Date
- Date nanoseconds
- Dense vector
- Flattened
- Geopoint
- Geoshape
- Histogram
- IP
- Join
- Keyword
- Nested
- Numeric
- Object
- Percolator
- Point
- Range
- Rank feature
- Rank features
- Search-as-you-type
- Semantic text
- Shape
- Sparse vector
- Text
- Token count
- Unsigned long
- Version
- Metadata fields
- Mapping parameters
- Mapping limit settings
- Removal of mapping types
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Index templates
- Data streams
- Ingest pipelines
- Example: Parse logs
- Enrich your data
- Processor reference
- Append
- Attachment
- Bytes
- Circle
- Community ID
- Convert
- CSV
- Date
- Date index name
- Dissect
- Dot expander
- Drop
- Enrich
- Fail
- Fingerprint
- Foreach
- Geo-grid
- GeoIP
- Grok
- Gsub
- HTML strip
- Inference
- Join
- JSON
- KV
- Lowercase
- Network direction
- Pipeline
- Redact
- Registered domain
- Remove
- Rename
- Reroute
- Script
- Set
- Set security user
- Sort
- Split
- Trim
- Uppercase
- URL decode
- URI parts
- User agent
- Ingest pipelines in Search
- Aliases
- Search your data
- Query DSL
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Categorize text
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Frequent item sets
- Geo-distance
- Geohash grid
- Geohex grid
- Geotile grid
- Global
- Histogram
- IP prefix
- IP range
- Missing
- Multi Terms
- Nested
- Parent
- Random sampler
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Time series
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Average bucket
- Bucket script
- Bucket count K-S test
- Bucket correlation
- Bucket selector
- Bucket sort
- Change point
- Cumulative cardinality
- Cumulative sum
- Derivative
- Extended stats bucket
- Inference bucket
- Max bucket
- Min bucket
- Moving function
- Moving percentiles
- Normalize
- Percentiles bucket
- Serial differencing
- Stats bucket
- Sum bucket
- Bucket aggregations
- Geospatial analysis
- EQL
- ES|QL
- SQL
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Data management
- ILM: Manage the index lifecycle
- Tutorial: Customize built-in policies
- Tutorial: Automate rollover
- Index management in Kibana
- Overview
- Concepts
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Troubleshooting index lifecycle management errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Data tiers
- Autoscaling
- Monitor a cluster
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure the Elastic Stack
- Elasticsearch security principles
- Start the Elastic Stack with security enabled automatically
- Manually configure security
- Updating node security certificates
- User authentication
- Built-in users
- Service accounts
- Internal users
- Token-based authentication services
- User profiles
- Realms
- Realm chains
- Security domains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- JWT authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Looking up users without authentication
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Role restriction
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enable audit logging
- Restricting connections with IP filtering
- Securing clients and integrations
- Operator privileges
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Watcher
- Command line tools
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- How to
- Troubleshooting
- Fix common cluster issues
- Diagnose unassigned shards
- Add a missing tier to the system
- Allow Elasticsearch to allocate the data in the system
- Allow Elasticsearch to allocate the index
- Indices mix index allocation filters with data tiers node roles to move through data tiers
- Not enough nodes to allocate all shard replicas
- Total number of shards for an index on a single node exceeded
- Total number of shards per node has been reached
- Troubleshooting corruption
- Fix data nodes out of disk
- Fix master nodes out of disk
- Fix other role nodes out of disk
- Start index lifecycle management
- Start Snapshot Lifecycle Management
- Restore from snapshot
- Troubleshooting broken repositories
- Addressing repeated snapshot policy failures
- Troubleshooting an unstable cluster
- Troubleshooting discovery
- Troubleshooting monitoring
- Troubleshooting transforms
- Troubleshooting Watcher
- Troubleshooting searches
- Troubleshooting shards capacity health issues
- Troubleshooting an unbalanced cluster
- Capture diagnostics
- REST APIs
- API conventions
- Common options
- REST API compatibility
- Autoscaling APIs
- Behavioral Analytics APIs
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat component templates
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Prevalidate node removal
- Nodes reload secure settings
- Nodes stats
- Cluster Info
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Create or update desired nodes
- Get desired nodes
- Delete desired nodes
- Get desired balance
- Reset desired balance
- Cross-cluster replication APIs
- Connector APIs
- Create connector
- Delete connector
- Get connector
- List connectors
- Update connector API key id
- Update connector configuration
- Update connector index name
- Update connector filtering
- Update connector name and description
- Update connector pipeline
- Update connector scheduling
- Update connector service type
- Create connector sync job
- Cancel connector sync job
- Delete connector sync job
- Get connector sync job
- List connector sync jobs
- Check in a connector
- Update connector error
- Update connector last sync stats
- Update connector status
- Check in connector sync job
- Set connector sync job error
- Set connector sync job stats
- Data stream APIs
- Document APIs
- Enrich APIs
- EQL APIs
- ES|QL APIs
- Features APIs
- Fleet APIs
- Graph explore API
- Index APIs
- Alias exists
- Aliases
- Analyze
- Analyze index disk usage
- Clear cache
- Clone index
- Close index
- Create index
- Create or update alias
- Create or update component template
- Create or update index template
- Create or update index template (legacy)
- Delete component template
- Delete dangling index
- Delete alias
- Delete index
- Delete index template
- Delete index template (legacy)
- Exists
- Field usage stats
- Flush
- Force merge
- Get alias
- Get component template
- Get field mapping
- Get index
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Import dangling index
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- List dangling indices
- Open index
- Refresh
- Resolve index
- Resolve cluster
- Rollover
- Shrink index
- Simulate index
- Simulate template
- Split index
- Unfreeze index
- Update index settings
- Update mapping
- Index lifecycle management APIs
- Create or update lifecycle policy
- Get policy
- Delete policy
- Move to step
- Remove policy
- Retry policy
- Get index lifecycle management status
- Explain lifecycle
- Start index lifecycle management
- Stop index lifecycle management
- Migrate indices, ILM policies, and legacy, composable and component templates to data tiers routing
- Inference APIs
- Info API
- Ingest APIs
- Licensing APIs
- Logstash APIs
- Machine learning APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get model snapshots
- Get model snapshot upgrade statistics
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Reset jobs
- Revert model snapshots
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Upgrade model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Delete data frame analytics jobs
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Preview data frame analytics
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Update data frame analytics jobs
- Machine learning trained model APIs
- Clear trained model deployment cache
- Create or update trained model aliases
- Create part of a trained model
- Create trained models
- Create trained model vocabulary
- Delete trained model aliases
- Delete trained models
- Get trained models
- Get trained models stats
- Infer trained model
- Start trained model deployment
- Stop trained model deployment
- Update trained model deployment
- Migration APIs
- Node lifecycle APIs
- Query rules APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Root API
- Script APIs
- Search APIs
- Search Application APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Clear service account token caches
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Create service account tokens
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete service account token
- Delete users
- Disable users
- Enable users
- Enroll Kibana
- Enroll node
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get service accounts
- Get service account credentials
- Get Security settings
- Get token
- Get user privileges
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- Query API key information
- Query User
- Update API key
- Update Security settings
- Bulk update API keys
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SAML complete logout
- SAML service provider metadata
- SSL certificate
- Activate user profile
- Disable user profile
- Enable user profile
- Get user profiles
- Suggest user profile
- Update user profile data
- Has privileges user profile
- Create Cross-Cluster API key
- Update Cross-Cluster API key
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- SQL APIs
- Synonyms APIs
- Text structure APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Migration guide
- Release notes
- Elasticsearch version 8.14.3
- Elasticsearch version 8.14.2
- Elasticsearch version 8.14.1
- Elasticsearch version 8.14.0
- Elasticsearch version 8.13.4
- Elasticsearch version 8.13.3
- Elasticsearch version 8.13.2
- Elasticsearch version 8.13.1
- Elasticsearch version 8.13.0
- Elasticsearch version 8.12.2
- Elasticsearch version 8.12.1
- Elasticsearch version 8.12.0
- Elasticsearch version 8.11.4
- Elasticsearch version 8.11.3
- Elasticsearch version 8.11.2
- Elasticsearch version 8.11.1
- Elasticsearch version 8.11.0
- Elasticsearch version 8.10.4
- Elasticsearch version 8.10.3
- Elasticsearch version 8.10.2
- Elasticsearch version 8.10.1
- Elasticsearch version 8.10.0
- Elasticsearch version 8.9.2
- Elasticsearch version 8.9.1
- Elasticsearch version 8.9.0
- Elasticsearch version 8.8.2
- Elasticsearch version 8.8.1
- Elasticsearch version 8.8.0
- Elasticsearch version 8.7.1
- Elasticsearch version 8.7.0
- Elasticsearch version 8.6.2
- Elasticsearch version 8.6.1
- Elasticsearch version 8.6.0
- Elasticsearch version 8.5.3
- Elasticsearch version 8.5.2
- Elasticsearch version 8.5.1
- Elasticsearch version 8.5.0
- Elasticsearch version 8.4.3
- Elasticsearch version 8.4.2
- Elasticsearch version 8.4.1
- Elasticsearch version 8.4.0
- Elasticsearch version 8.3.3
- Elasticsearch version 8.3.2
- Elasticsearch version 8.3.1
- Elasticsearch version 8.3.0
- Elasticsearch version 8.2.3
- Elasticsearch version 8.2.2
- Elasticsearch version 8.2.1
- Elasticsearch version 8.2.0
- Elasticsearch version 8.1.3
- Elasticsearch version 8.1.2
- Elasticsearch version 8.1.1
- Elasticsearch version 8.1.0
- Elasticsearch version 8.0.1
- Elasticsearch version 8.0.0
- Elasticsearch version 8.0.0-rc2
- Elasticsearch version 8.0.0-rc1
- Elasticsearch version 8.0.0-beta1
- Elasticsearch version 8.0.0-alpha2
- Elasticsearch version 8.0.0-alpha1
- Dependencies and versions
Downsampling a time series data stream
editDownsampling a time series data stream
editDownsampling provides a method to reduce the footprint of your time series data by storing it at reduced granularity.
Metrics solutions collect large amounts of time series data that grow over time.
As that data ages, it becomes less relevant to the current state of the system.
The downsampling process rolls up documents within a fixed time interval into a
single summary document. Each summary document includes statistical
representations of the original data: the min, max, sum and value_count
for each metric. Data stream time series dimensions
are stored unchanged.
Downsampling, in effect, lets you to trade data resolution and precision for storage size. You can include it in an index lifecycle management (ILM) policy to automatically manage the volume and associated cost of your metrics data at it ages.
Check the following sections to learn more:
How it works
editA time series is a sequence of observations taken over time for a specific entity. The observed samples can be represented as a continuous function, where the time series dimensions remain constant and the time series metrics change over time.
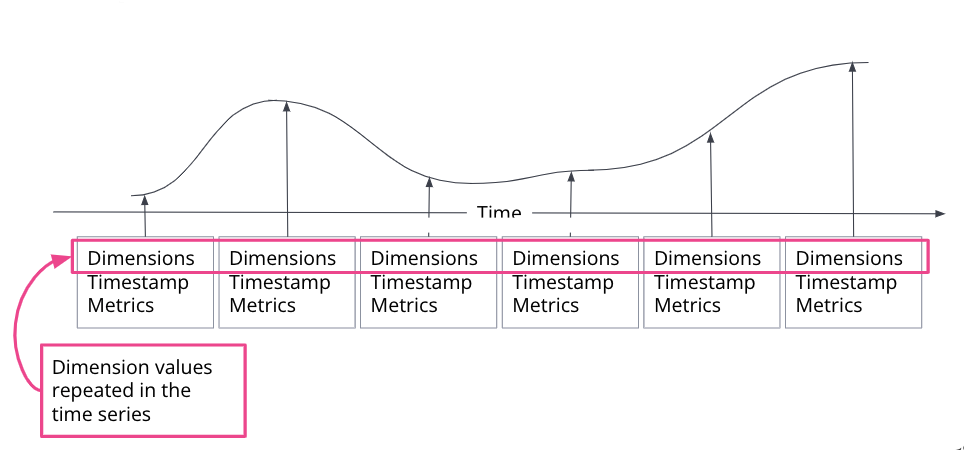
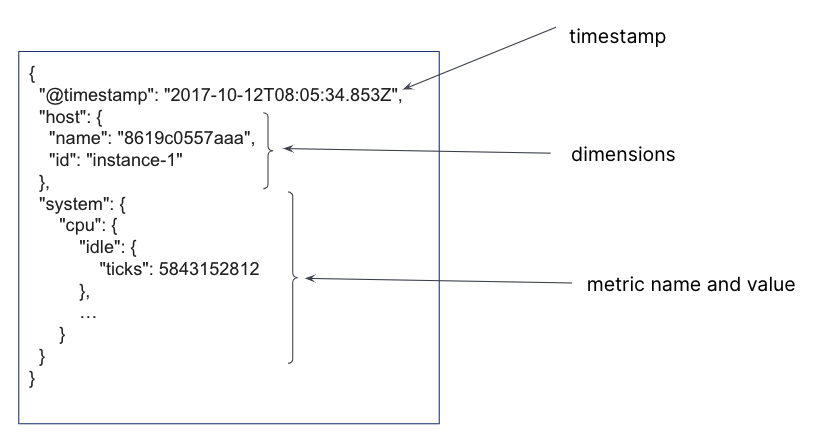
In an Elasticsearch index, a single document is created for each timestamp, containing the immutable time series dimensions, together with the metrics names and the changing metrics values. For a single timestamp, several time series dimensions and metrics may be stored.
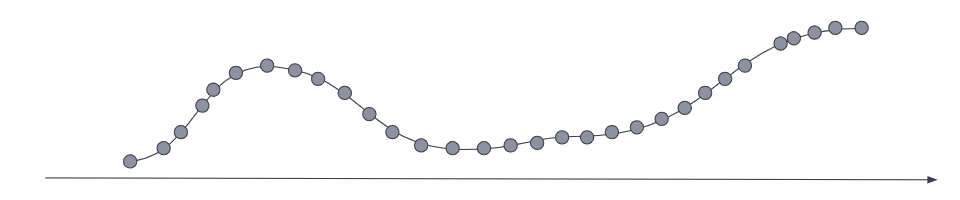
For your most current and relevant data, the metrics series typically has a low sampling time interval, so it’s optimized for queries that require a high data resolution.
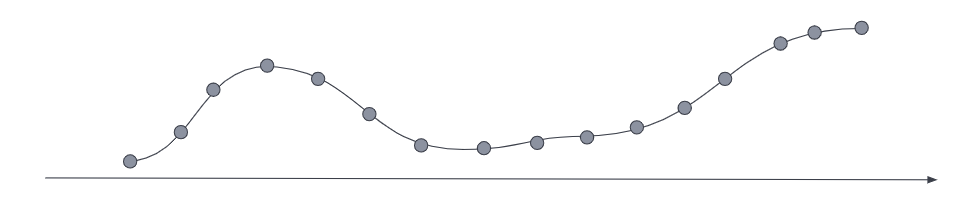
Downsampling works on older, less frequently accessed data by replacing the
original time series with both a data stream of a higher sampling interval and
statistical representations of that data. Where the original metrics samples may
have been taken, for example, every ten seconds, as the data ages you may choose
to reduce the sample granularity to hourly or daily. You may choose to reduce
the granularity of cold archival data to monthly or less.
Running downsampling on time series data
editTo downsample a time series index, use the
Downsample API and set fixed_interval to
the level of granularity that you’d like:
response = client.indices.downsample( index: 'my-time-series-index', target_index: 'my-downsampled-time-series-index', body: { fixed_interval: '1d' } ) puts response
POST /my-time-series-index/_downsample/my-downsampled-time-series-index { "fixed_interval": "1d" }
To downsample time series data as part of ILM, include a
Downsample action in your ILM policy and set fixed_interval
to the level of granularity that you’d like:
response = client.ilm.put_lifecycle( policy: 'my_policy', body: { policy: { phases: { warm: { actions: { downsample: { fixed_interval: '1h' } } } } } } ) puts response
PUT _ilm/policy/my_policy { "policy": { "phases": { "warm": { "actions": { "downsample" : { "fixed_interval": "1h" } } } } } }
Querying downsampled indices
editYou can use the _search and _async_search
endpoints to query a downsampled index. Multiple raw data and downsampled
indices can be queried in a single request, and a single request can include
downsampled indices at different granularities (different bucket timespan). That
is, you can query data streams that contain downsampled indices with multiple
downsampling intervals (for example, 15m, 1h, 1d).
The result of a time based histogram aggregation is in a uniform bucket size and
each downsampled index returns data ignoring the downsampling time interval. For
example, if you run a date_histogram aggregation with "fixed_interval": "1m"
on a downsampled index that has been downsampled at an hourly resolution
("fixed_interval": "1h"), the query returns one bucket with all of the data at
minute 0, then 59 empty buckets, and then a bucket with data again for the next
hour.
Notes on downsample queries
editThere are a few things to note about querying downsampled indices:
- When you run queries in Kibana and through Elastic solutions, a normal response is returned without notification that some of the queried indices are downsampled.
-
For
date histogram aggregations,
only
fixed_intervals(and not calendar-aware intervals) are supported. -
Timezone support comes with caveats:
-
Date histograms at intervals that are multiples of an hour are based on
values generated at UTC. This works well for timezones that are on the hour, e.g.
+5:00 or -3:00, but requires offsetting the reported time buckets, e.g.
2020-01-01T10:30:00.000instead of2020-03-07T10:00:00.000for timezone +5:30 (India), if downsampling aggregates values per hour. In this case, the results include the fielddownsampled_results_offset: true, to indicate that the time buckets are shifted. This can be avoided if a downsampling interval of 15 minutes is used, as it allows properly calculating hourly values for the shifted buckets. -
Date histograms at intervals that are multiples of a day are similarly
affected, in case downsampling aggregates values per day. In this case, the
beginning of each day is always calculated at UTC when generated the downsampled
values, so the time buckets need to be shifted, e.g. reported as
2020-03-07T19:00:00.000instead of2020-03-07T00:00:00.000for timezoneAmerica/New_York. The fielddownsampled_results_offset: trueis added in this case too. - Daylight savings and similar peculiarities around timezones affect reported results, as documented for date histogram aggregation. Besides, downsampling at daily interval hinders tracking any information related to daylight savings changes.
-
Date histograms at intervals that are multiples of an hour are based on
values generated at UTC. This works well for timezones that are on the hour, e.g.
+5:00 or -3:00, but requires offsetting the reported time buckets, e.g.
Restrictions and limitations
editThe following restrictions and limitations apply for downsampling:
- Only indices in a time series data stream are supported.
- Data is downsampled based on the time dimension only. All other dimensions are copied to the new index without any modification.
- Within a data stream, a downsampled index replaces the original index and the original index is deleted. Only one index can exist for a given time period.
- A source index must be in read-only mode for the downsampling process to succeed. Check the Run downsampling manually example for details.
- Downsampling data for the same period many times (downsampling of a downsampled index) is supported. The downsampling interval must be a multiple of the interval of the downsampled index.
- Downsampling is provided as an ILM action. See Downsample.
- The new, downsampled index is created on the data tier of the original index and it inherits its settings (for example, the number of shards and replicas).
-
The numeric
gaugeandcountermetric types are supported. -
The downsampling configuration is extracted from the time series data stream
index mapping. The only additional
required setting is the downsampling
fixed_interval.
Try it out
editTo take downsampling for a test run, try our example of running downsampling manually.
Downsampling can easily be added to your ILM policy. To learn how, try our Run downsampling with ILM example.
On this page