ニューヨーク市のタクシー乗降データでMachine Learningを体験する
容易に使用することができ、パワフルなMachine Learningを体験いただくには、みなさん自身のデータを使用されることが一番ですが、公開されているデータセットを用いても十分に実感できます。ニューヨーク市のタクシーの乗降データを用いて異常検知を行って見ましょう。リリース5.4を対象にします。
データの準備
ニューヨーク市のTaxi and Limousine Commissionのページより、2016年11月のYellowタクシーの乗降データをダウンロードします。このデータセットには、乗車時間・地域、降車時間・地域、料金などの情報が含まれています。CSVファイルとして提供されていますので、Logstashを使用してElasticsearchに取り組みます。事前にElasticsearch、Kibana、Logstash及びX-Packのインストールを忘れずに行ってください。地域は数字のコードとして記録されていて、これを直接利用することもできますが、Elasticsearchに取り込む際には、このようなコードを非正規化するとあとで利用する際に便利です。この地域コードもCSVファイルとして提供されていますので、Logstashのtranslate filter(別途インストールが必要)を使用して変換しやすいように事前に加工しておきます。
$ curl https://s3.amazonaws.com/nyc-tlc/misc/taxi+_zone_lookup.csv | cut -d, -f 1,3 | tail +2 > taxi.csv
以下の通りLogstashの設定ファイルnyc-taxi-yellow-translate-logstash.confを作成します。
input {
stdin { type => "tripdata" }
}
filter {
csv {
columns => ["VendorID","tpep_pickup_datetime","tpep_dropoff_datetime","passenger_count","trip_distance","RatecodeID","store_and_fwd_flag","PULocationID","DOLocationID","payment_type","fare_amount","extra","mta_tax","tip_amount","tolls_amount","improvement_surcharge","total_amount"]
convert => {"extra" => "float"}
convert => {"fare_amount" => "float"}
convert => {"improvement_surcharge" => "float"}
convert => {"mta_tax" => "float"}
convert => {"tip_amount" => "float"}
convert => {"tolls_amount" => "float"}
convert => {"total_amount" => "float"}
convert => {"trip_distance" => "float"}
convert => {"passenger_count" => "integer"}
}
date {
match => ["tpep_pickup_datetime", "yyyy-MM-dd HH:mm:ss", "ISO8601"]
timezone => "EST"
}
date {
match => ["tpep_pickup_datetime", "yyyy-MM-dd HH:mm:ss", "ISO8601"]
target => ["@tpep_pickup_datetime"]
remove_field => ["tpep_pickup_datetime"]
timezone => "EST"
}
date {
match => ["tpep_dropoff_datetime", "yyyy-MM-dd HH:mm:ss", "ISO8601"]
target => ["@tpep_dropoff_datetime"]
remove_field => ["tpep_dropoff_datetime"]
timezone => "EST"
}
translate {
field => "RatecodeID"
destination => "RatecodeID"
dictionary => [
"1", "Standard rate",
"2", "JFK",
"3", "Newark",
"4", "Nassau or Westchester",
"5", "Negotiated fare",
"6", "Group ride"
]
}
translate {
field => "VendorID"
destination => "VendorID_t"
dictionary => [
"1", "Creative Mobile Technologies",
"2", "VeriFone Inc"
]
}
translate {
field => "payment_type"
destination => "payment_type_t"
dictionary => [
"1", "Credit card",
"2", "Cash",
"3", "No charge",
"4", "Dispute",
"5", "Unknown",
"6", "Voided trip"
]
}
translate {
field => "PULocationID"
destination => "PULocationID_t"
dictionary_path => "taxi.csv"
}
translate {
field => "DOLocationID"
destination => "DOLocationID_t"
dictionary_path => "taxi.csv"
}
mutate {
remove_field => ["message", "column18", "column19", "RatecodeID", "VendorID", "payment_type", "PULocationID", "DOLocationID"]
}
}
output {
# stdout { codec => dots }
elasticsearch {
hosts => "localhost:9200"
user => "elastic"
password => "changeme"
index => "nyc-taxi-yellow-%{+YYYY.MM.dd}"
}
}
地域コードが記載されているCSVファイルtaxi.csvのロケーション、Elasticsearchノード、認証を行うユーザ名、パスワード等を必要に応じて変更し、Logstashを実行します。
$ tail +2 yellow_tripdata_2016-11.csv | bin/logstash -f nyc-taxi-yellow-translate-logstash.conf
取り込みが完了したらKibanaの Management タブよりindex pattern nyc-taxi-yellow-*を作成します。Time-field name としては@timestamp、もしくはtpep_pickup_datetimeを指定します。
Single Metric Jobの作成
では、異常の発見を試みて見ましょう。Kibanaの Machine Learning より Create a new job > Create a single metric job を選択します。From a New Search, Select Index では、nyc-taxi-yellow-*を選択します。Aggregation に Sum、Field にpassernger_count、Bucket span を 30m に設定し、Use full nyc-taxi-yellow-*data ボタンを押します。タクシーの利用は昼前の時間に多くて、深夜から早朝の時間にかけて減るような周期性があることがわかります。これで、データを取り込んだ全ての期間に渡って、30分間隔でタクシーの乗車人数に異常がないか調べることができます。Name にnyc-taxi-singleなどと入力し、Create job ボタンを押します。すぐに異常検知のJobが実行され、数秒で完了します。薄い青色のエリアは学習によって得られたモデルで、正常な値の範囲と考えることができます。このデータセットでは、24日にから25日にかけて異常が検知され、その度合いに応じて黄色やオレンジ色でマークされました。
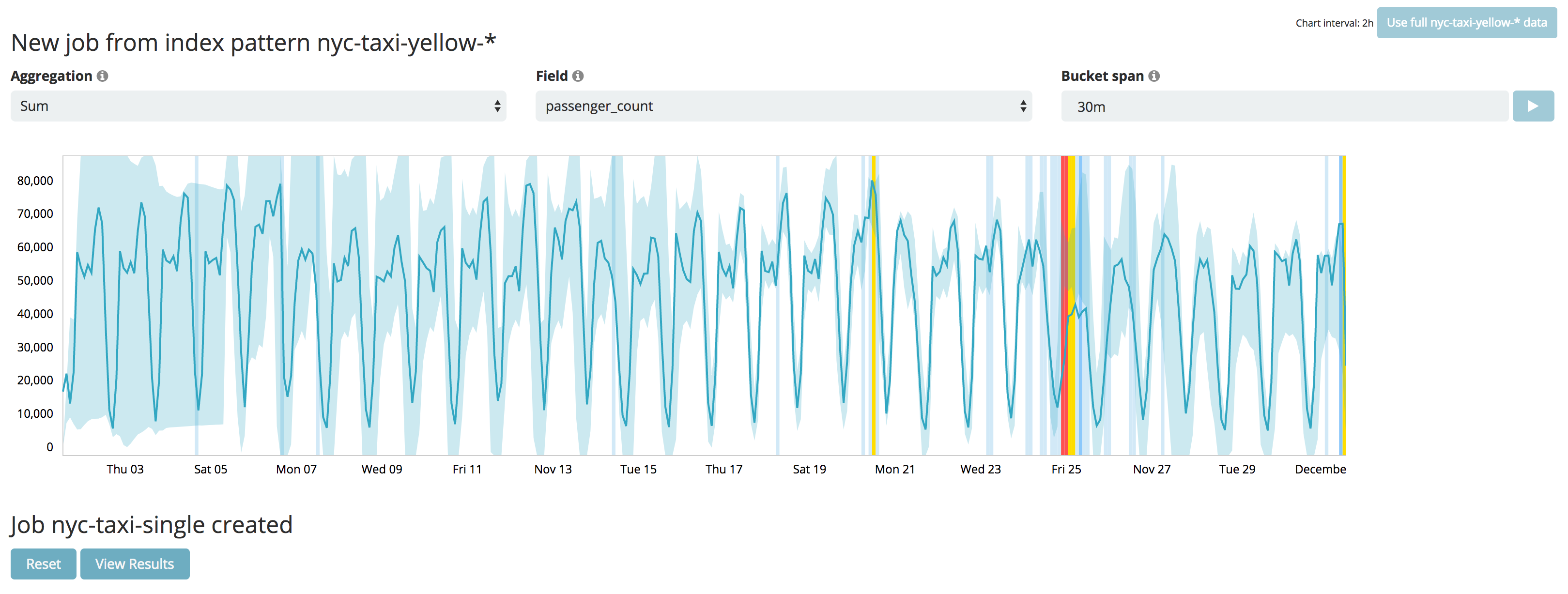
View Results ボタンを押して内容を確認して見ます。
Single Metric Viewer
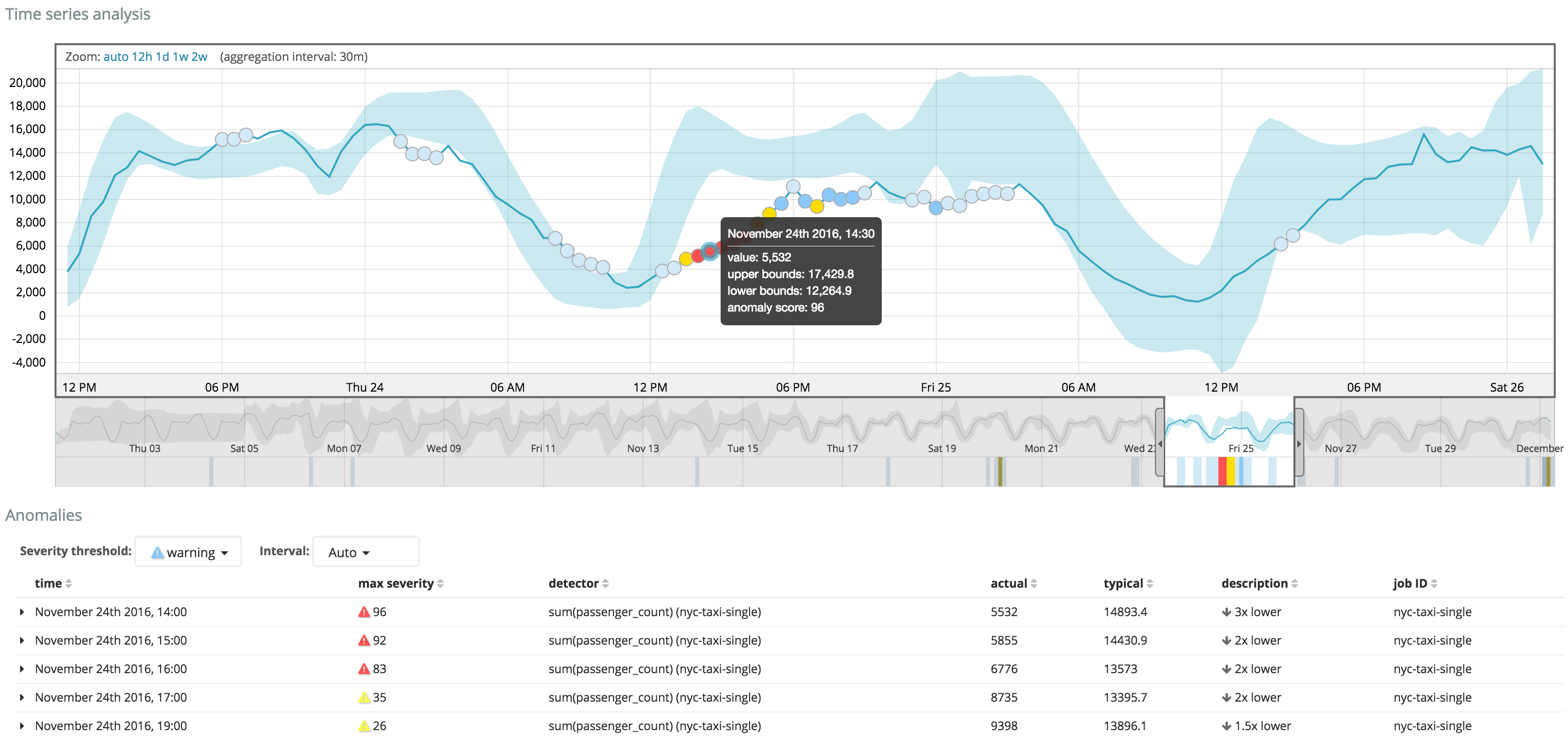
上段では、検知された異常にズームすることができます。下段では異常と判断された理由などを確認することができます。max severit が96である異常には actual が5532、typpical が14893.4と記載されています。これは、Machine Learningが作成したモデルによると、この時間帯には 14893.4 の乗車人数が予測されるのにも関わらず実際には 5532 しか乗車しなかった、ということを表します。この値が出現する確率は 2.70135e-21 で、非常に低いことがわかります。
なぜ、このような異常が記録されたのでしょうか。日本に住む私には馴染みがありませんが、この日は感謝祭で、アメリカでは家族で家で過ごす習慣があるようです。そのためニューヨーク市ではタクシーの乗車人数が異常なほど少なかったということが言えそうです。
Multiple Metric Jobの作成
さらに別の角度からこのデータセットを検証します。Create a new job から Create a multiple metric job を選択し、同じインデックスパターンnyc-taxi-yellow-*を選択します。この画面では、複数の Field についてそれぞれ別のメトリックを指定できる他、データの分割(Split)、異常の因子となる Key Fields を選択することができます。
先ほどのpassernger_countのSumに加えて、total_amountのMax、Key Fields では PULocationID_t.keyword をチェックします。これで、乗車人数や、最大支払い金額の異常と、特定の乗車地域が影響を及ぼしていれば、それも表示することが可能です。Job Details の Name にはnyc-taxi-multiなどと入力し、Create job ボタンを押します。このJobは先ほどのSingle Metricに比べて複雑ですので、実行には数分程度かかる可能性があります。
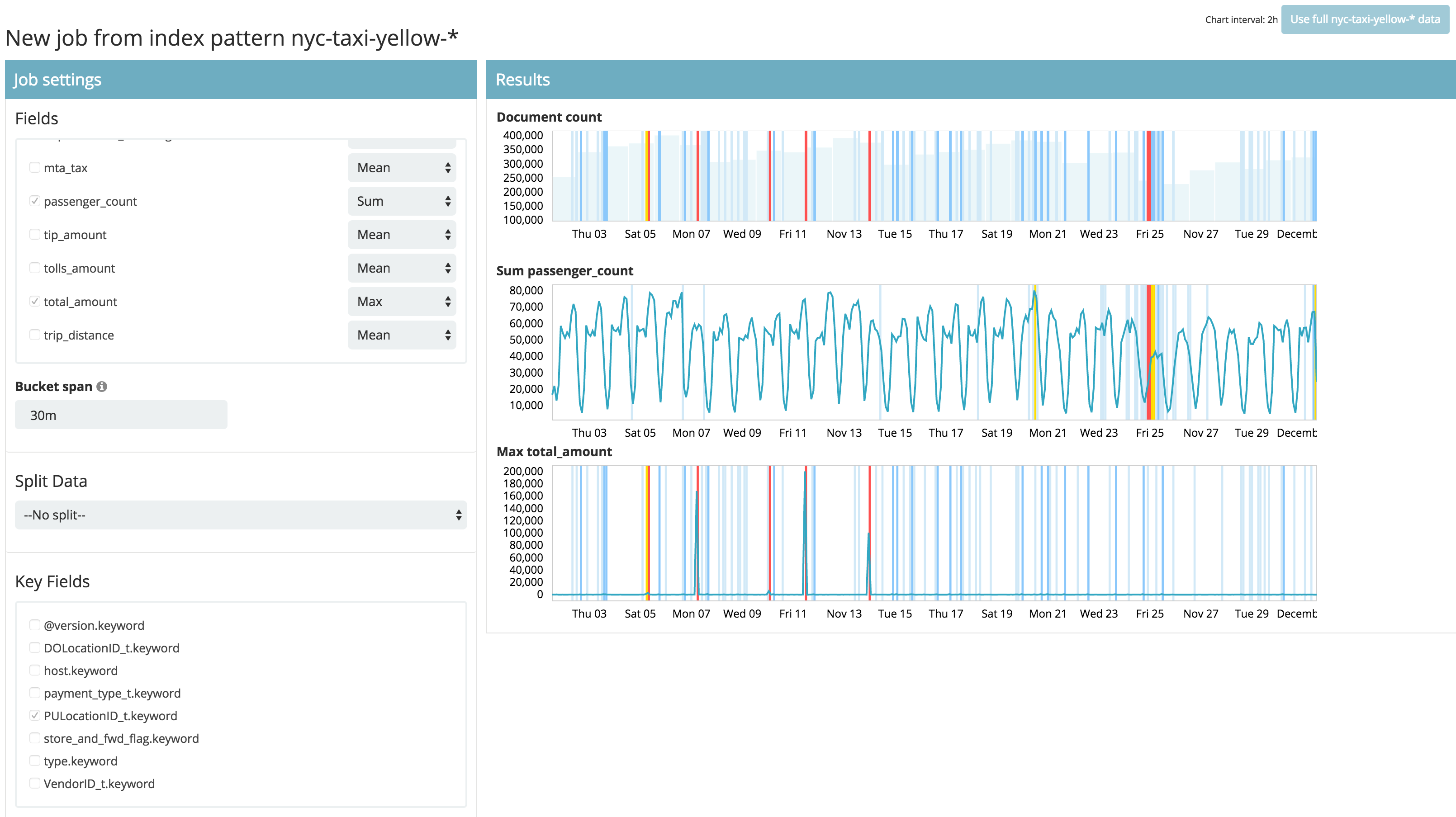
完了したら同じく詳細を確認します。
Anomaly Explorer

感謝祭の日に加えて、さらにいくつかの異常が11月4日から13日にかけて発生していることがわかります。11月4日の異常は、不明な地域NVで発生しています。Swim laneの該当部分をクリックして下段の Anomalies を確認すると料金として3024.3ドル払った人がいるようです。他の異常も同様で、極端に多くの金額を払った人たちがいるようです。興味があれば Discover タブから元のデータを確認することもできますが、これはタクシードライバーが決済端末の操作を誤ったものと考えられます。11月13日の異常を確認するとpayment_type_tがDisputeと記録されていて、クレジットカード会社に異常な請求が行われた際に、このように表示されるようです。
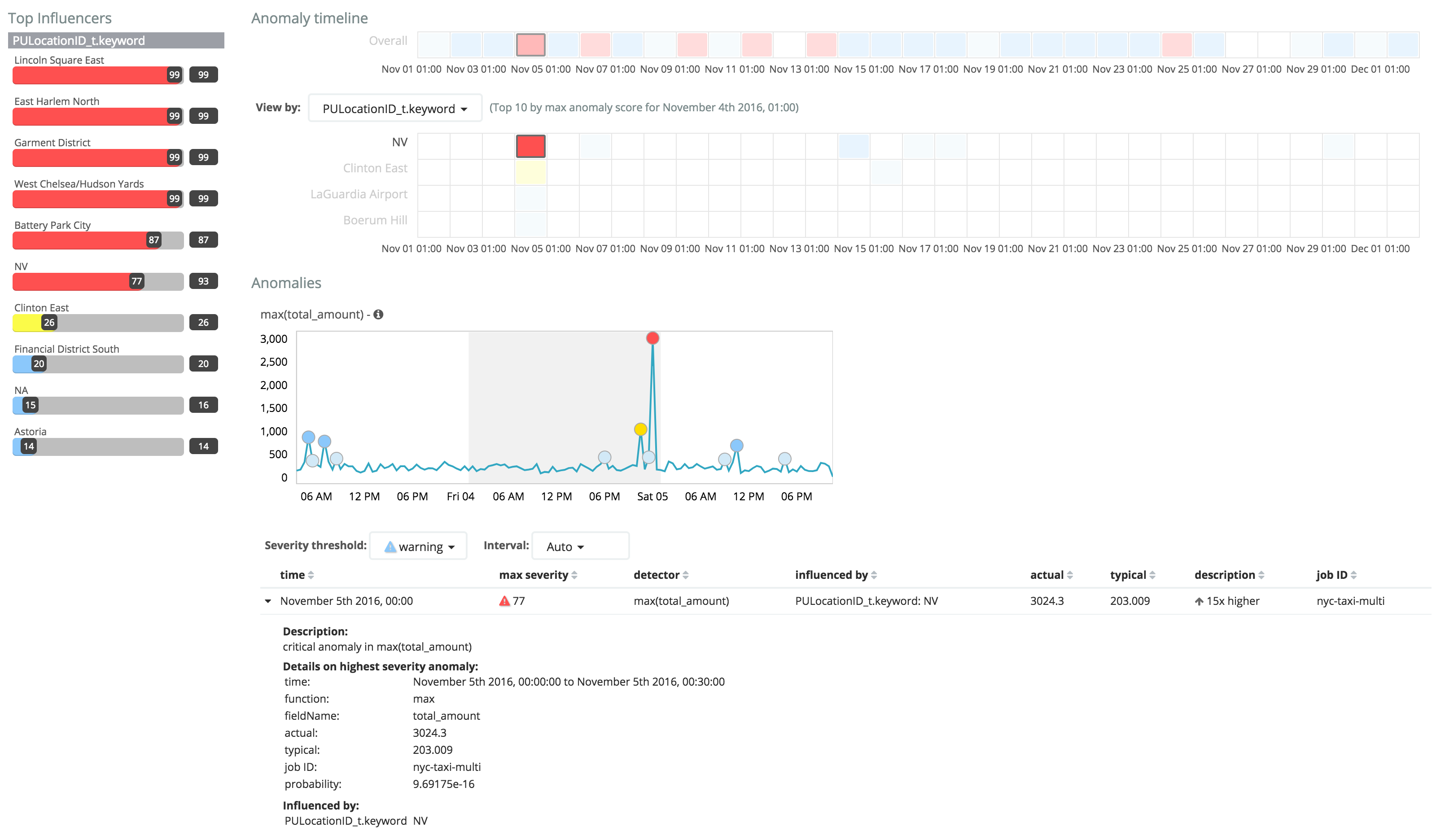
興味深いことに、感謝祭の日の異常に影響を与えた地域が表示されていません。これにより、特定の乗車地域によらず、ニューヨーク市全体でタクシーの乗車人数が少なかったということが言えます。ニューヨーク市は広大で、様々な出身地、宗教、職業の人たちが住んでおり、地域それぞれの特色もありますが、この日には全域にわたって同様の傾向があり、外出せずにきっと家族と感謝祭を過ごしたということでしょう。
まとめ
同じように異常が検知できましたでしょうか。ニューヨーク市の地理や、タクシーの料金体系などの知識がないのにも関わらず、いくつかの異常を検知することができました。また、単純な閾値を用いた旧来の方法では、このような周期性があるようなデータから異常を検出するのは困難でしょう。さらに異常と検出された理由なども容易に確認することができました。ここではご紹介できませんでしたが、大量のデータからリアルタイムに異常を検知するというElasticsearchの特性を生かせるのも、Machine Learningの利点です。IT運用、ITセキュリティはもちろんのこと、IoT、金融などの分野でも活用がはじまっています。次はぜひみなさん自身のデータでお試しください。
その他の日本語情報
- ブログ: Machine Learningで「他とは違う」イベントを検知する
- ビデオ: Machine Learning: Elastic Stackを利用した異常検知
- ビデオ: 時系列データの異常検知 実践入門
Machine Learningの設定などでお困りの場合には、こちらからお気軽にお問い合わせください。