Elasticでの機械学習モデルの使用


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
Elasticはニーズに応じた機械学習モデルをサポート
Elastic®では、自社のユースケースと機械学習(ML)に関する専門知識のレベルに応じた機械学習を適用できます。具体的な選択肢は以下のとおりです。
- 組み込みのモデルを活用する。特定のセキュリティ脅威や、オブザーバビリティとセキュリティのソリューションにおける各種システム問題に対応するモデルとは別に、すぐに使える独自のElastic Learned Sparse Encoderモデルと、英語以外のテキストデータを使用する際に便利な言語特定機能を利用できます。
- HuggingFaceモデルハブを含め、あらゆる場所からサードパーティのPyTorchモデルにアクセスする。
- 自分で訓練したモデル(現時点では主にNLP変換器)を読み込む。
組み込みのモデルを使用すると、MLの専門知識がなくてもすぐに価値を引き出すことができるほか、さまざまなモデルを試し、自社のデータで最も高いパフォーマンスを発揮するモデルを探すこともできます。
Elasticのモデル管理は、クラスター内の複数のノードにまたがって拡張でき、また高スループットと低遅延のワークロードの両方で優れた推論パフォーマンスを実現できるように設計されています。その理由の1つは、推論を実行するインジェストパイプラインが強化され、インジェストフェーズおよびデータ分析や検索中には、計算負荷の高いモデルの推論に専用のノードが使用されるためです。
次のセクションでは、Elasticにモデルを読み込ませるためのElandライブラリと、それがElasticsearch®内で使用するさまざまな種類の機械学習機能(最新の変換器モデルや自然言語処理(NLP)モデルから回帰用のブーストツリーモデルまで)にどのように役立つかについて詳しく解説します。
ElandでMLモデルをElasticに読み込む
Elandライブラリでは、MLモデル(PyTorchを使用して訓練されていることが条件)をElasticsearchに読み込むための簡単なインターフェースが提供されます。ネイティブライブラリのlibtorchを使用し、モデルがTorchScript表現としてエクスポートまたは保存されていることを前提に、Elasticsearchはモデルの推論中にPythonインタープリターが実行されるのを回避します。
PyTorchでNLPモデルを構築するための最も人気の高い形式の1つを統合することで、Elasticsearchは多くのさまざまなNLPタスクやユースケースに対応するプラットフォームとなります。詳細は、この後の変換器についてのセクションで解説します。
Elandを使用してモデルをアップロード方法は、コマンドライン、Docker、独自のPythonコマンドの3種類があります。DockerはElandおよびそのあらゆる依存関係のローカルインストールが必要ないため、それほど複雑ではありません。Elandにアクセスした後のコードサンプルは以下のとおりです。この例では、DistilBERT NERモデルをアップロードします。

この後のセクションでは、eland_import_hub_modelの各引数について解説します。また、同じコマンドをDockerコンテナーから発行できます。
アップロードが完了すると、KibanaのMLモデル管理のユーザーインターフェースを使用して、Elasticsearchクラスターでモデルを管理できます。スループットの向上のために割り当てを増やしたり、システムの(再)設定中にモデルを停止/再開したりすることができます。
サポート対象のモデル
Elasticではさまざまな変換器モデルに加え、以下の最も人気のある教師あり学習ライブラリがサポートされています。
- NLPおよび埋め込みモデル:標準BERTモデルインターフェースに準拠し、WordPieceトークン化アルゴリズムを使用するすべての変換器モデルです。サポートされているモデルアーキテクチャーの完全なリストについては、こちらを参照してください。
- 教師あり学習:scikit-learn、XGBoost、LightGBMライブラリからの訓練済みモデルです。シリアル化され、Elasticsearchで推論モデルとして使用されます。ElasticのドキュメントにはElasticのデータに対するXGBoost分類のトレーニングの例が記載されています。またデータフレーム分析を使用してElasticで訓練された教師ありモデルをエクスポート/インポートすることもできます。
- 生成AI:LLM用に提供されたAPIを使用してクエリ(Elasticから取得したコンテキストでエンリッチされている可能性がある)を渡し、返された結果を処理することができます。詳細な手順については、GitHubレポジトリへのリンクと、ChatGPTのAPIを介して通信するサンプルコードが記載されているこちらのブログを参照してください。
次のセクションでは、検索アプリケーションのコンテキストで使用する可能性が高いNLP変換器モデルについて説明します。
Elasticに変換器とNLPを簡単に適用する方法
ここでは、NLPモデルを読み込んで使用する手順について解説します。今回はHugging Faceが開発した人気のNERモデルを例に、以下のコードスニペットで指定された引数を確認しましょう。

- Elastic Cloudの識別子を指定します。または、--urlを使用します。
- クラスターにアクセスするための認証情報を入力します。利用可能な認証方法を検索できます。
- Hugging Faceモデルハブで、モデルの識別子を指定します。
- NLPタスクの種類を指定します。サポートされている値は、fill_mask、ner、text_classification、text_embedding、zero_shot_classificationです。
モデルを読み込んだら、次はデプロイする必要があります。これはKibanaの[Machine Learning](機械学習)タブの[Model Management](モデル管理)画面で実行します。その後、通常はモデルをテストして正常に機能することを確認します。
これで、デプロイされたモデルを推論に使用する準備ができました。たとえば、固有表現を抽出するには、読み込まれたNERモデルで_inferエンドポイントを呼び出します。
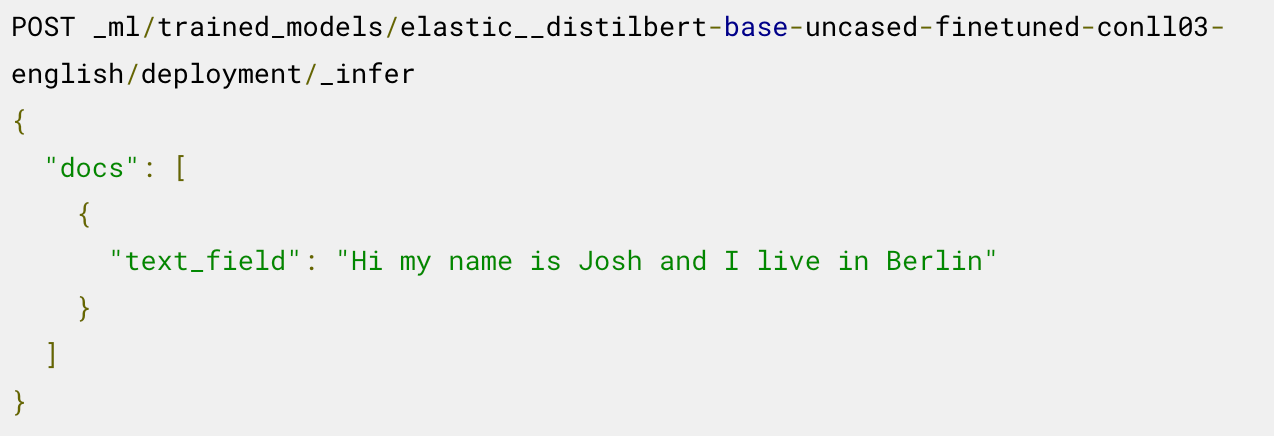
モデルによって、人物"Josh"と場所"Berlin"という2つの固有表現が特定されました。

このモデルを推論パイプラインで使用してデプロイを調整する方法など、その他の手順については、同じ例を使ったこちらのブログをお読みください。
テキスト埋め込みを作成し、ベクトル検索を適用して関連するドキュメントを見つけるなど、セマンティック検索を適用する方法については、こちらのブログを参照してください。モデルのパフォーマンスの検証を含め、手順ごとの説明が記載されています。
どのモデルにどの種類のタスクが適しているか分からない場合は、こちらの表が役に立ちます。
Hugging Faceモデル | task-type |
|---|---|
ner | |
text_embedding | |
text_classification | |
zero_shot_classification | |
| 質問と回答 | question_answering |
Elasticでは、2つのテキストの類似性を比較することもtext_similarityタスクタイプとしてサポートされています。これはドキュメントのテキストを、提供された別のテキスト入力と比較してランキングするのに便利で、"クロスエンコーディング"と呼ばれる場合もあります。
詳細はこちらのリソースを参照
- PyTorch変換器のサポートと、Elandの設計に関する検討事項
- Elasticに変換器を読み込み推論で使用するための手順
- ブログ:ChatGPTを使用して機密データを照会する方法
- テキスト分類タスクに事前訓練済みの変換器を適応させ、Elasticにカスタムモデルを読み込む
- 英語以外のテキストを、英語のみに対応するモデルに渡す前に識別できる組み込みの言語識別子
Elastic、Elasticsearch、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。他のすべての会社名および製品名は、各所有者の商標、ロゴ、登録商標である場合があります。
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷

