NLP를 배포하는 방법: 명명된 엔티티 인식(NER) 예제


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
자연어 처리(NLP)에 대한 여러 블로그 시리즈의 일부로, 명명된 엔티티 인식(NER) NLP 모델을 사용하여 구조화되지 않은 텍스트 필드에서 미리 정의된 범주의 엔티티를 찾고 추출하는 예를 자세히 살펴보겠습니다. 공개적으로 사용 가능한 모델을 사용하여, 해당 모델을 Elasticsearch에 배포하고, 새로운 _infer API로 텍스트에서 명명된 엔티티를 찾고, 문서가 Elasticsearch로 수집될 때 엔티티를 추출하기 위해 수집 파이프라인에서 NER 모델을 사용하는 방법을 보여드리겠습니다.
NER 모델은 자연어를 사용하여 전체 텍스트 필드에서 사람, 장소 및 조직과 같은 엔티티를 추출하는 데 유용합니다.
이 예제에서 우리는 NER 모델을 통해 책 레미제라블의 단락을 실행하고, 모델을 사용하여 텍스트에서 문자와 위치를 추출하고 그 사이의 관계를 시각화할 것입니다.
Elasticsearch에 NER 모델 배포
먼저, 텍스트 필드에서 문자와 위치의 이름을 추출할 수 있는 NER 모델을 선택해야 합니다. 다행히도 우리가 선택할 수 있는 몇 가지 NER 모델이 Hugging Face에있으며, Elastic 설명서를 보면 Elastic의 uncased NER 모델을 위해 시험해 볼 수 있는 모델이 한 가지 있습니다.
사용할 NER 모델을 선택했으므로, Eland를 사용하여 모델을 설치할 수 있습니다. 이 예에서는 Docker 이미지를 통해 Eland 명령을 실행할 것이지만, 먼저 다음과 같이 Eland GitHub 리포지토리를 복제하여 Docker 이미지를 빌드하고 클라이언트 시스템에서 Eland의 Docker 이미지를 만들어야 합니다.
git clone git@github.com:elastic/eland.git
cd eland
docker build -t elastic/eland .
이제 eland Docker 클라이언트가 준비되었으므로 다음 명령으로 새 Docker 이미지에서 eland_import_hub_model 명령을 실행하여 NER 모델을 설치할 수 있습니다.
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url $ELASTICSEARCH_URL \
--hub-model-id elastic/distilbert-base-uncased-finetuned-conll03-english \
--task-type ner \
--startELASTICSEACH_URL을 여러분의 Elasticsearch 클러스터의 URL로 바꿔야 합니다. 인증을 위해 URL에 https://username:password@host:port 형식으로 관리자 사용자 이름과 비밀번호를 포함해야 합니다.
eland import 명령의 마지막에 --start 옵션을 사용했기 때문에, Elasticsearch는 사용 가능한 모든 머신 러닝 노드에 모델을 배포하고 메모리에 모델을 로드합니다. 모델이 여러 개 있고 배포할 모델을 선택하려면, Kibana의 머신 러닝 > 모델 관리 사용자 인터페이스를 사용하여 모델의 시작과 중지를 관리할 수 있습니다.
NER 모델 테스팅
배포된 모델은 새로운 _infer API를 사용하여 평가할 수 있습니다. 입력은 분석하고자 하는 스트링입니다. 아래 요청에서, text_field는 모델 구성에서 정의된 대로 모델이 입력을 찾을 것으로 예상되는 필드 이름입니다. 기본적으로, 모델이 Eland를 통해 업로드된 경우 입력 필드는 text_field입니다.
Kibana의 개발자 도구 콘솔에서 다음 예를 사용해 보세요.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_infer
{
"docs": [
{
"text_field": "Hi my name is Josh and I live in Berlin"
}
]
}
모델은 두 개의 엔티티를 발견했습니다. 사람 "Josh"와 위치 "Berlin"입니다.
{
"predicted_value" : "Hi my name is [Josh](PER&Josh) and I live in [Berlin](LOC&Berlin)",
"entities" : {
"entity" : "Josh",
"class_name" : "PER",
"class_probability" : 0.9977303419824,
"start_pos" : 14,
"end_pos" : 18
},
{
"entity" : "Berlin",
"class_name" : "LOC",
"class_probability" : 0.9992474323902818,
"start_pos" : 33,
"end_pos" : 39
}
]
}
predicted_value는 주석이 달린 텍스트 형식의 입력 스트링이고, class_name은 예측 클래스이며, class_probability는 예측에 대한 신뢰 수준을 나타냅니다. start_pos와 end_pos는 식별된 엔티티의 시작 및 끝 문자 위치입니다.
유추 수집 파이프라인에 NER 모델 추가
_infer API는 재미있고 쉬운 시작 방법이지만, 단일 입력만 허용하고 탐지된 엔티티가 Elasticsearch에 저장되지 않습니다. 또 다른 대안은 문서들이 유추 프로세서로 수집 파이프라인을 통해 수집될 때 문서들에 대해 대량 유추를 수행하는 것입니다.
스택 관리 UI에서 수집 파이프라인을 정의하거나 Kibana Console에서 구성할 수 있습니다. 여기에는 여러 수집 프로세서가 포함됩니다.
PUT _ingest/pipeline/ner
{
"description": "NER pipeline",
"processors": [
{
"inference": {
"model_id": "elastic__distilbert-base-uncased-finetuned-conll03-english",
"target_field": "ml.ner",
"field_map": {
"paragraph": "text_field"
}
}
},
{
"script": {
"lang": "painless",
"if": "return ctx['ml']['ner'].containsKey('entities')",
"source": "Map tags = new HashMap(); for (item in ctx['ml']['ner']['entities']) { if (!tags.containsKey(item.class_name)) tags[item.class_name] = new HashSet(); tags[item.class_name].add(item.entity);} ctx['tags'] = tags;"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{ _index }}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
inference 프로세서부터 시작하며, field_map의 목적은 paragraph(소스 문서에서 분석할 필드)를 text_field(모델이 사용하도록 구성된 필드의 이름)에 매핑하는 것입니다. target_field는 유추 결과를 쓸 필드의 이름입니다.
script 프로세서는 엔티티를 가져와 유형별로 그룹화합니다. 최종 결과는 입력 텍스트에서 탐지된 사람들, 위치 및 조직의 목록입니다. 우리는 생성된 필드에서 시각화를 구축할 수 있도록 이 Painless 스크립트를 추가하고 있습니다.
on_failure 구문은 오류를 잡아내기 위한 것입니다. 이것은 두 가지 동작을 정의합니다. 먼저, _index 메타 필드를 새 값으로 설정하면 이제 거기에 문서가 저장됩니다. 둘째, 오류 메시지가 새 필드인 ingest.failure에 기록됩니다. 유추는 쉽게 고칠 수 있는 여러 가지 이유로 실패할 수 있습니다. 모델이 배포되지 않았거나 일부 원본 문서에서 입력 필드가 누락되었을 수 있습니다. 실패한 문서를 다른 인덱스로 리디렉션하고 오류 메시지를 설정하면, 실패한 유추는 손실되지 않으며 나중에 검토할 수 있습니다. 오류가 해결되면, 실패한 인덱스에서 재색인하여 실패한 요청을 복구합니다.
유추를 위한 텍스트 필드 선택
NER는 많은 데이터 세트에 적용될 수 있습니다. 여기에서는 고전인 빅토르 위고가 1862년에 발표한 소설 레미제라블을 예로 들었습니다. Kibana의 파일 업로드 기능을 사용하여 우리의 샘플 json 파일의 레미제라블 단락을 업로드할 수 있습니다. 본문은 14,021개의 JSON 문서로 나뉘며, 각 문서는 하나의 단락을 포함합니다. 임의의 단락을 예로 들면, 다음과 같습니다.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"line": 12700
}
단락이 NER 파이프라인을 통해 수집되면, Elasticsearch에 저장된 결과 문서는 식별된 한 사람으로 표시됩니다.
{
"paragraph": "Father Gillenormand did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"@timestamp": "2020-01-01T17:38:25",
"line": 12700,
"ml": {
"ner": {
"predicted_value": "Father [Gillenormand](PER&Gillenormand) did not do it intentionally, but inattention to proper names was an aristocratic habit of his.",
"entities": [{
"entity": "Gillenormand",
"class_name": "PER",
"class_probability": 0.9806354093873283,
"start_pos": 7,
"end_pos": 19
}],
"model_id": "elastic__distilbert-base-cased-finetuned-conll03-english"
}
},
"tags": {
"PER": [
"Gillenormand"
]
}
}
태그 클라우드는 단어 발생 빈도에 따라 단어의 크기를 조정하는 시각화이며, 레미제라블에서 발견되는 엔티티를 보기 위한 완벽한 인포그래픽입니다. Kibana를 열고 새 집계 기반 시각화를 만든 다음 Tag Cloud를 선택합니다. NER 결과가 들어 있는 인덱스를 선택하고 tags.PER.keyword 필드에 용어 집계를 추가합니다.
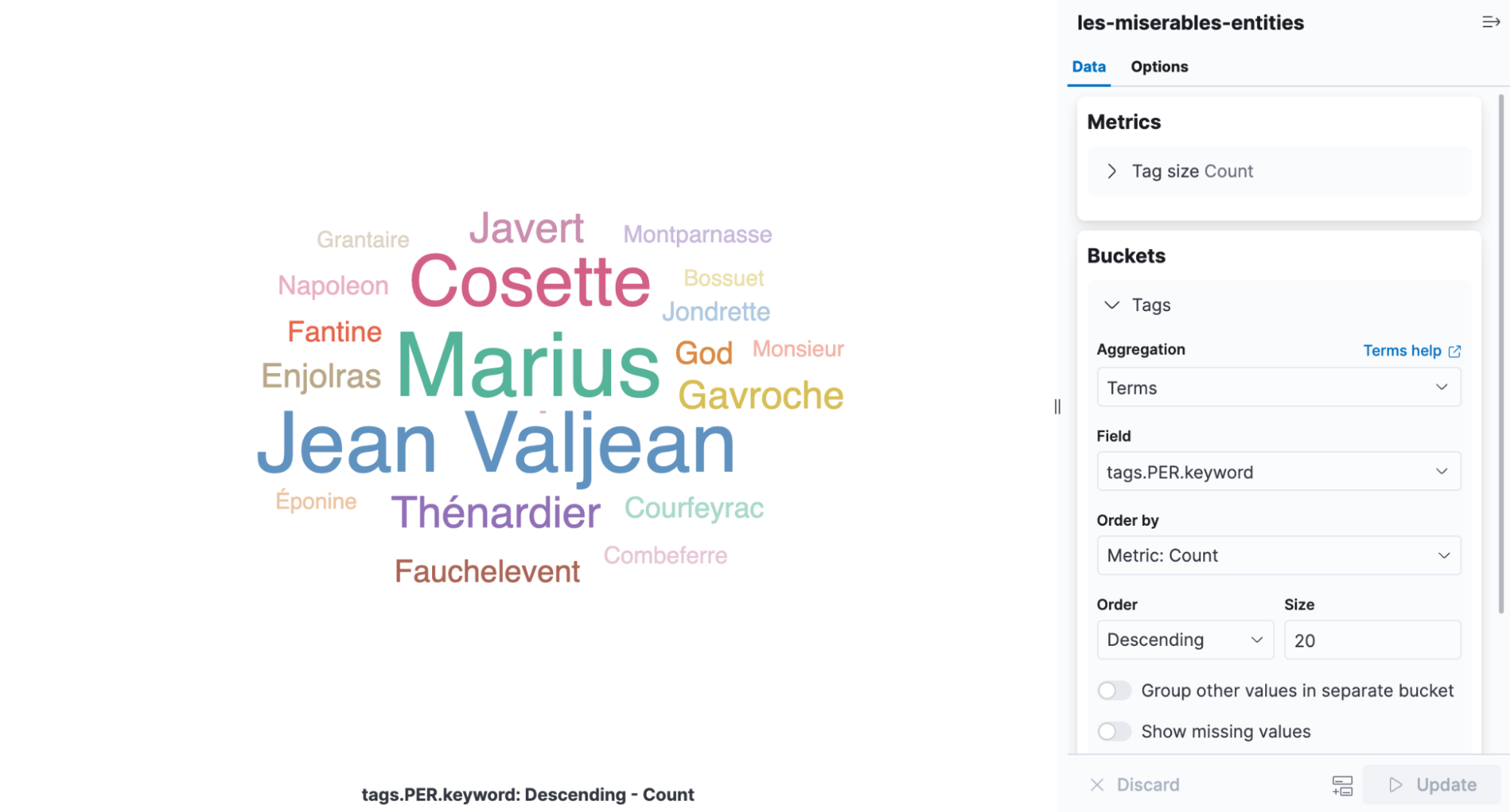
책에서 가장 많이 언급되는 인물들이 Cosette, Marius, Jean Valjean이라는 것을 시각화에서 쉽게 알 수 있습니다.
배포 조정
모델 관리 UI로 돌아가면, 배포 통계에서 평균 유추 시간을 확인할 수 있습니다. 이것은 단일 요청에 대한 유추를 수행하기 위해 네이티브 프로세스에 의해 측정된 시간입니다. 배포를 시작할 때 CPU 리소스의 사용 방법을 제어하는 두 가지 매개 변수 inference_threads와 model_threads가 있습니다.
inference_threads는 요청당 모델을 실행하는 데 사용되는 스레드 수입니다. 증가하는 inference_threads는 바로 평균 유추 시간을 줄입니다. 병렬적으로 평가되는 요청 수는 model_threads에 의해 제어됩니다. 이 설정은 평균 유추 시간을 줄이지 않고 처리량을 증가시킵니다.
일반적으로 inference_threads의 수를 늘려서 지연 시간을 조정하고 model_threads의 수를 늘려서 처리량을 높입니다. 두 설정 모두 기본적으로 하나의 스레드로 설정되므로, 이를 수정하여 얻을 수 있는 성능이 많습니다. 효과는 NER 모델을 사용하여 입증됩니다.
스레드 설정 중 하나를 변경하려면, 배포를 중지하고 다시 시작해야 합니다. 배포가 일반적으로 중지를 방지하는 수집 파이프라인에 의해 참조되기 때문에 ?force=true 매개 변수가 중지 API로 전달됩니다.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_stop?force=true
그리고 4개의 유추 스레드로 다시 시작합니다. 평균 유추 시간은 배포를 다시 시작할 때 재설정됩니다.
POST _ml/trained_models/elastic__distilbert-base-uncased-finetuned-conll03-english/deployment/_start?inference_threads=4레미제라블 단락을 처리할 때, 평균 유추 시간은 요청당 55.84밀리초입니다. 이에 비해 하나의 스레드에 대해서는 173.86밀리초입니다.
더 자세히 알아보고 사용해 보기
NER은 지금 사용할 준비가 된 NLP 작업 중 하나일 뿐입니다. 텍스트 분류, 제로샷 분류, 텍스트 임베딩도 이용 가능합니다. Elastic Stack에 배포할 수 있는 대략적인 모델 목록과 함께 NLP 설명서에서 더 많은 예를 찾아보실 수 있습니다.
NLP는 흥미로운 로드맵과 함께 Elastic Stack 8.0의 주요 신기능입니다. Elastic Cloud에서 클러스터를 구축하여 새로운 기능을 알아보고 최신 개발 정보를 받아 보세요. 오늘 무료 14일 체험판에 등록하고 이 블로그의 예제를 직접 사용해 보세요.
다른 NLP 관련 글을 읽고 싶으시면 다음을 참조하세요.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기