File Data Visualizer를 이용해 CSV와 로그 데이터를 Elasticsearch로 가져오기
Elastic Stack 6.5에서 새로운 File Data Visualizer 기능이 도입되었습니다. 사용자는 이 새 기능을 이용해 구분 기호를 포함한 파일(CSV 등), NDJSON 또는 반구조적 텍스트(로그 파일 등)를 업로드할 수 있습니다. 여기서 새 Elastic 머신 러닝 find_file_structure 끝점은 이를 분석하고 데이터에 대한 발견 사항을 다시 보고하게 됩니다. 여기에는 UI에서 Elasticsearch로 파일을 가져오는 데 사용할 수 있는 제안된 수집 파이프라인과 매핑이 포함됩니다.
이 기능의 목적은 Kibana나 Machine Learning을 이용해 데이터를 탐색하고자 하는 사용자가 복잡한 수집 프로세스를 익힐 필요 없이 소량의 데이터를 손쉽게 Elasticsearch로 가져올 수 있도록 하는 것입니다.
최근의 좋은 예를 하나 들자면, 배포 경험이 별로 없는 Elastic 마케팅 팀원이 작성한 이 블로그 포스팅입니다. Kibana의 geo_point 시각화를 사용하여 지진 위치를 탐색하고 분석하는 데 도움이 되도록 이 팀원은 File Data Visualizer를 이용해 지진 데이터를 손쉽게 Elasticsearch로 가져올 수 있었습니다.
예제: CSV 파일을 Elasticsearch로 가져오기
이 기능을 보여드릴 수 있는 가장 좋은 방법은 예제를 단계별로 따라가보는 것입니다. 다음 예제에서 항공편 예약 웹사이트의 가상 데이터를 포함하고 있는 CSV 파일 데이터를 사용해 보겠습니다. 데이터가 어떻게 보이는지 알려드리기 위해 파일의 첫 다섯 줄만 보여드리겠습니다.
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
File Data Visualizer 내에서 CSV 가져오기 구성
File Data Visualizer 기능은 Kibana의 Machine Learning > Data Visualizer 섹션에서 찾아볼 수 있습니다. 사용자는 파일을 선택하거나 끌어다 놓을 수 있는 페이지를 보게 됩니다. 버전 6.5 기준으로, 최대 파일 크기는 100MB로 제한됩니다.
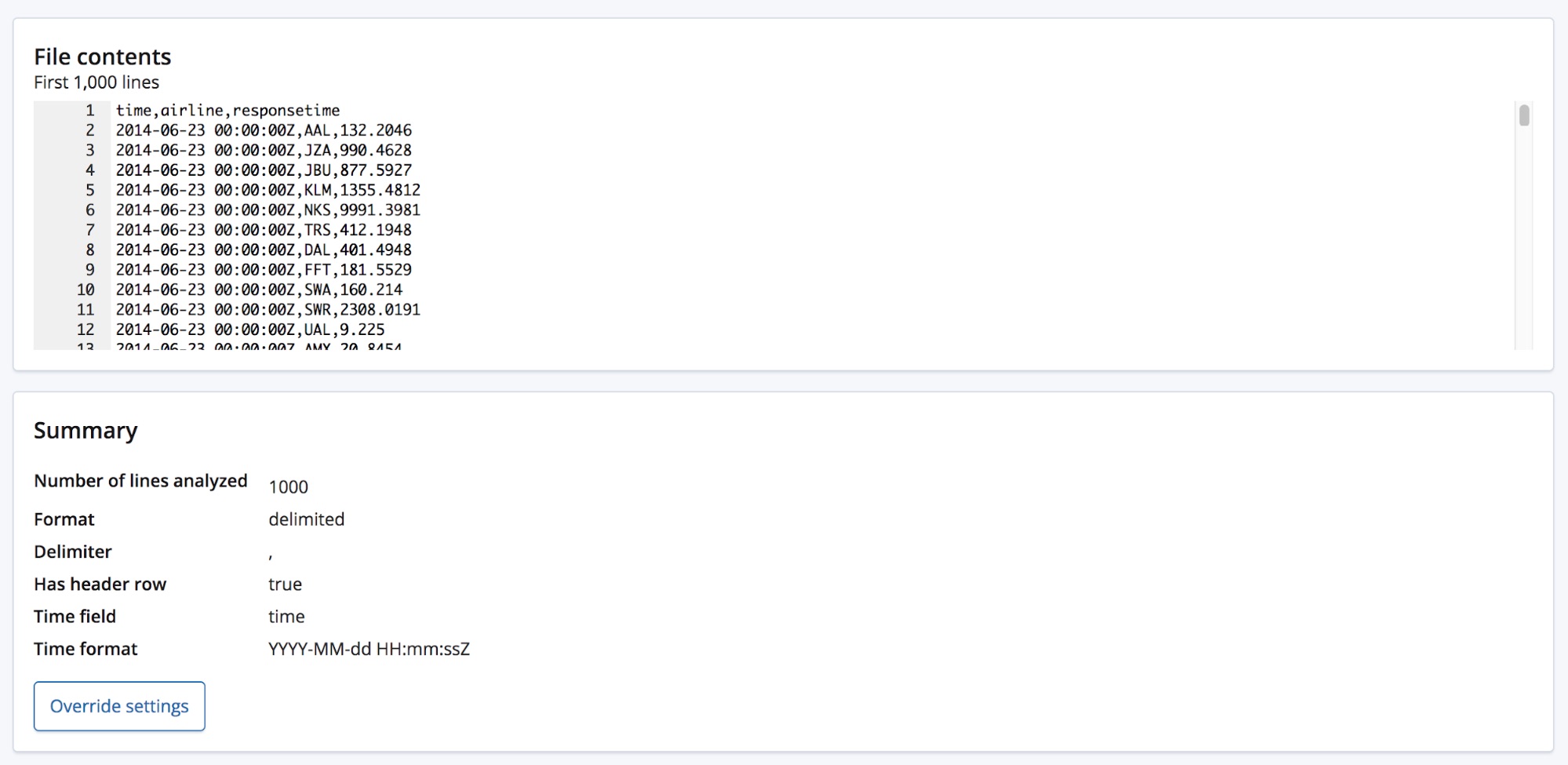
CSV 파일을 선택하면, 이 페이지는 파일의 첫 1,000줄을 그 분석을 실행하는 find_file_structure 끝점으로 보내고 그 발견 사항을 다시 반환합니다. UI의 Summary(요약) 섹션을 보면, 데이터가 구분 기호로 분리된 형식으로 되어 있다는 것을 정확하게 감지했으며 구분 기호가 쉼표 문자라는 것을 알 수 있습니다.
또한 머리글 행이 있다는 것도 감지했고, 이러한 필드 이름을 사용하여 각 열의 데이터에 레이블을 붙였습니다. 첫 열은 알려진 날짜 형식과 일치했고, 이 날짜 형식은 Time field로 강조되어 있습니다.
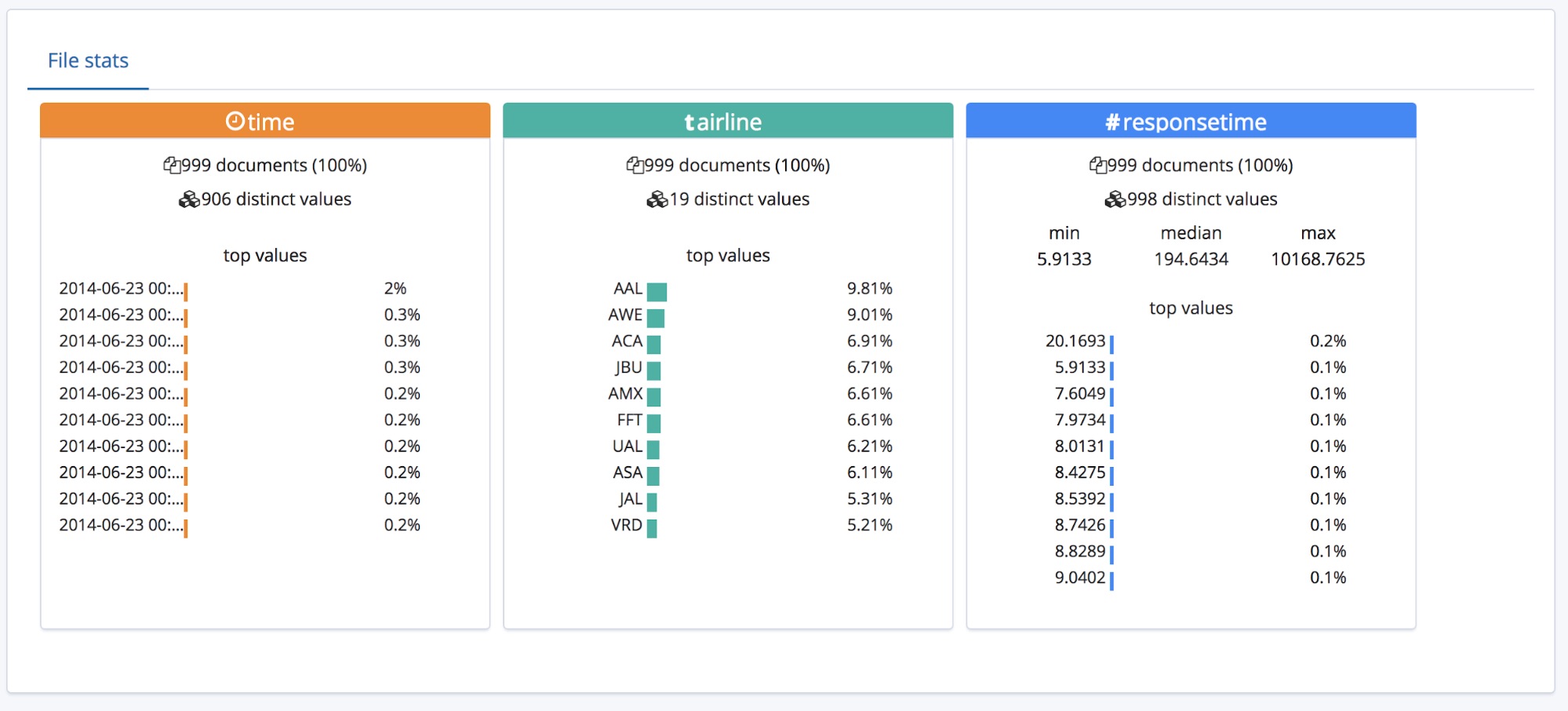
이 Summary(요약) 섹션 밑에는 필드 섹션이 있습니다. 이것은 원래의 Data Visualizer 기능을 사용해본 적이 있는 분들께는 친숙할 것입니다.
세 가지 유형의 필드가 정확히 파악되었으며, 각 필드마다 개요 수준의 통계 일부가 기재되어 있는 것을 볼 수 있습니다. 각 필드에 대해 가장 많이 발생하는 값 상위 10개도 기재되어 있습니다. 숫자 필드로 식별된 responsetime의 경우, min, median, max 값도 표시되어 있습니다.
이 모두는 머리글이 있는 CSV 파일에 아주 적합하지만, 데이터가 맨 위에 머리글 행을 포함하지 않는 경우 어떻게 될까요?
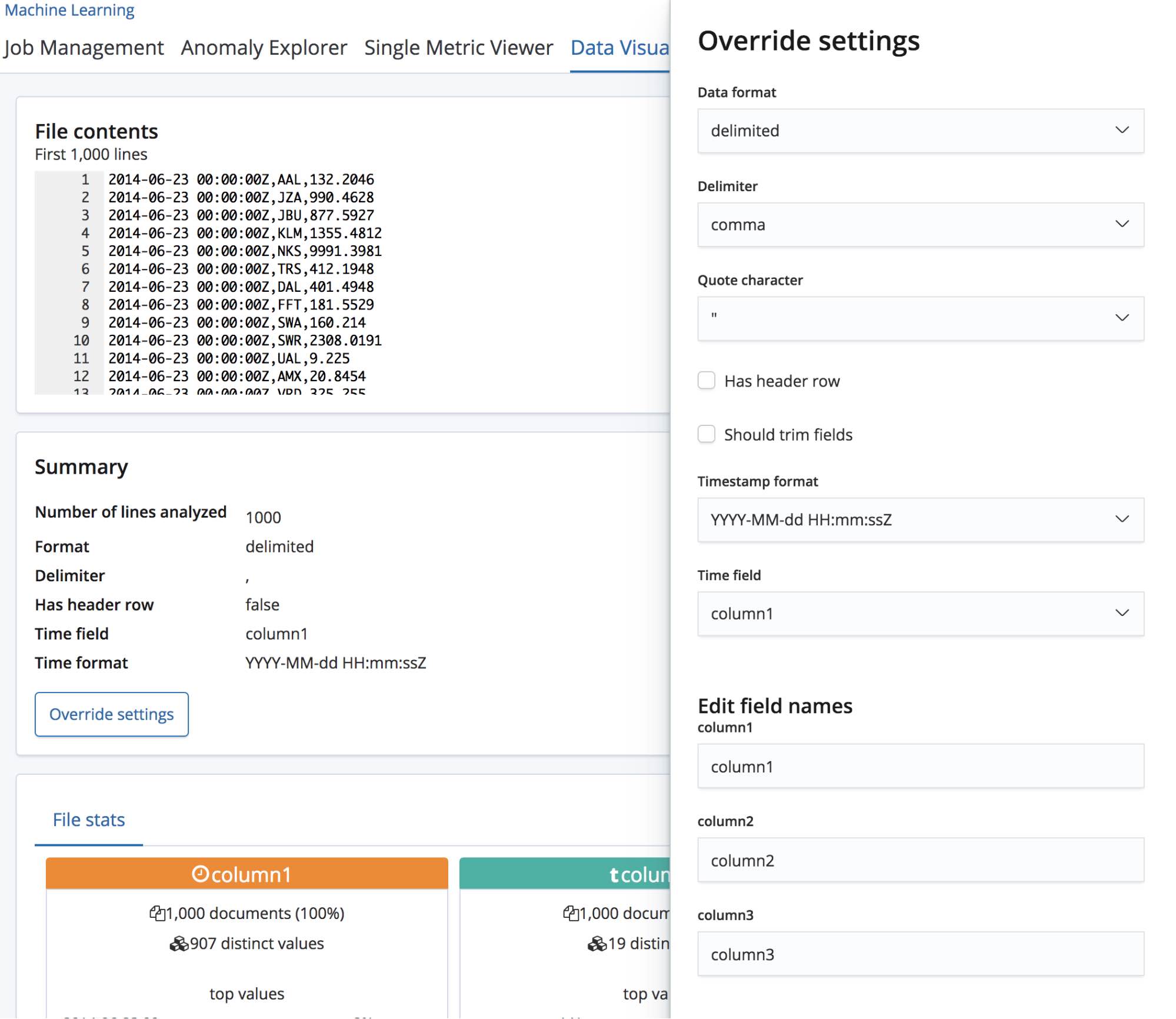
이 경우, find_file_structure 끝점은 임시 필드 이름을 사용하게 됩니다. 예제 파일에서 첫 줄을 제거하고 다시 업로드하여 이것을 보여드릴 수 있습니다. 이제 필드에 column1, column2, column3이라는 일반적인 이름을 붙어 있습니다.
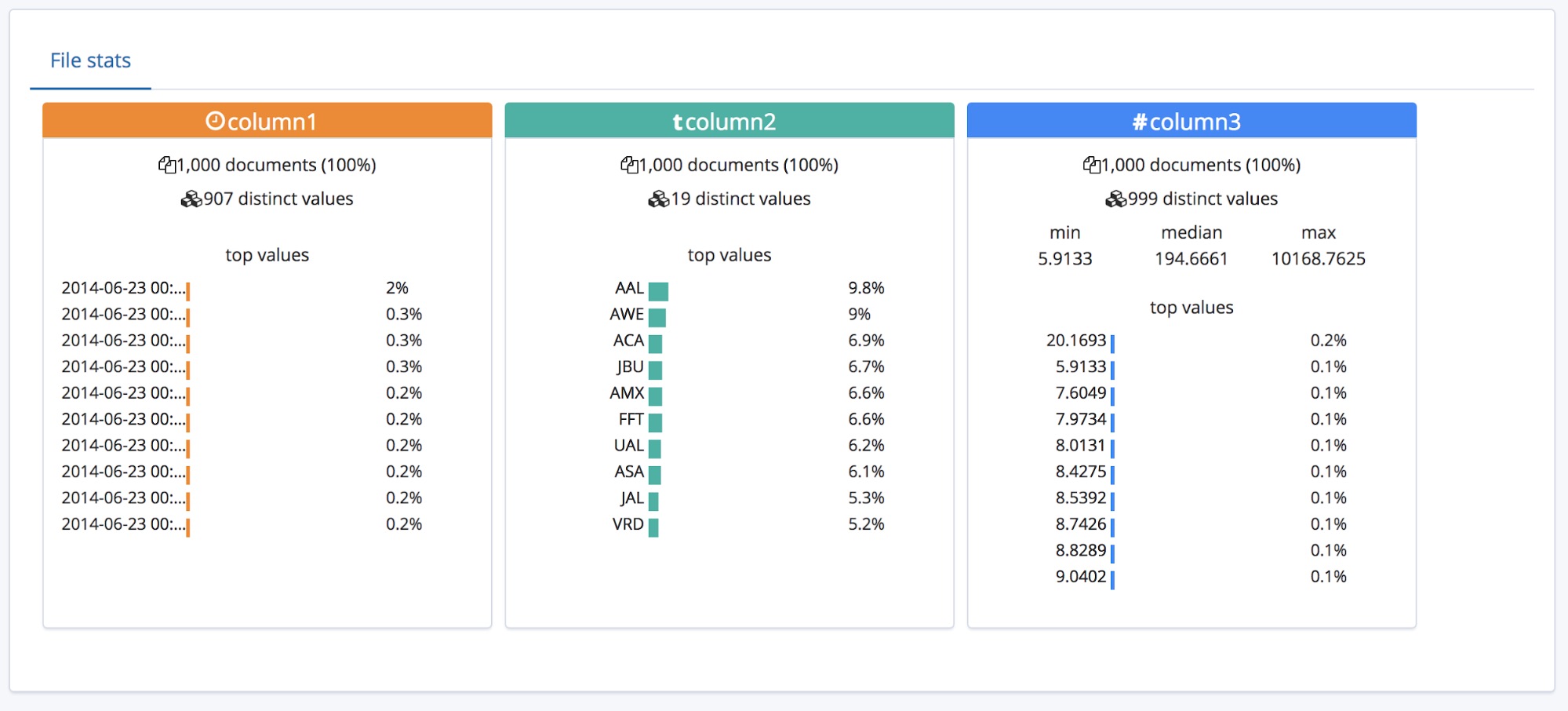
사용자가 도메인에 대해 조금 알게 되면 이러한 필드의 이름을 좀더 나은 것으로 바꾸고 싶어할 수도 있습니다. Override settings(재정의 설정) 버튼을 사용해 이름을 바꿀 수 있습니다.
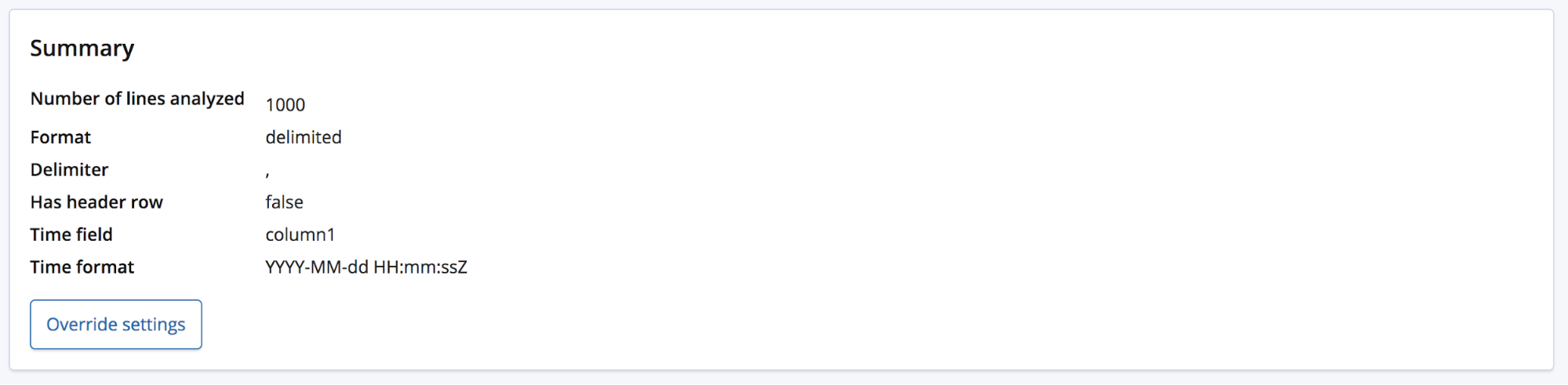
이러한 필드의 이름 바꾸기와 더불어, Data format(날짜 형식), Delimiter(구분 기호), Quote character(따옴표)와 같은 다른 설정도 바꿀 수 있습니다. find_file_structure 끝점이 데이터에 관한 경험을 바탕으로 추측해놓은 것을 이 섹션에서 정정할 수 있다고 생각하시면 됩니다. 여러 개의 날짜 필드를 가질 수도 있으며, 여기서는 그 중에서 첫 번째 것을 선택했습니다. 또는 파일에 머리글 행이 포함되었더라도 필드 이름을 완전히 바꾸고 싶을 수도 있습니다.
이러한 설정이 만족스러우면, 페이지 왼쪽 하단에 있는 Import(가져오기) 버튼을 누르면 됩니다.
CSV 데이터를 Elasticsearch로 가져오기
이제 데이터를 Elasticsearch로 가져올 수 있는 Import(가져오기) 페이지로 이동합니다. 이 기능은 반복되는 프로덕션 프로세스의 일부로 사용되기 위한 것이 아니라 데이터의 초기 탐색일 뿐이라는 점에 유의하시기 바랍니다. 주된 이유는 자동화 옵션이 부족하다는 점이며, 이 기능이 현재 실험 중에 있기 때문이기도 합니다.
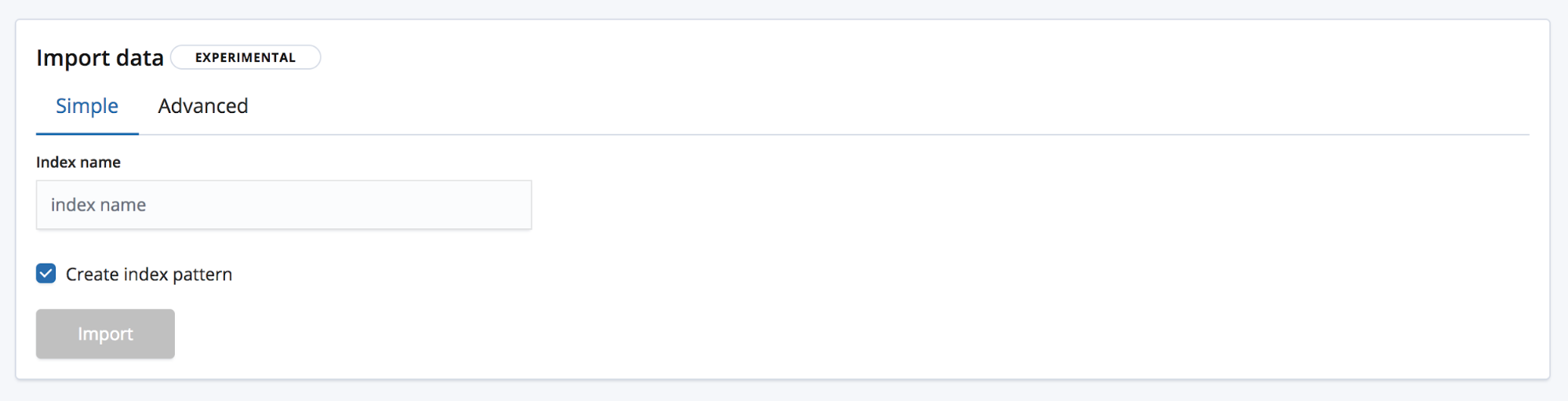
가져오기에는 두 가지 모드가 있습니다. Simple(단순) 모드에서는 사용자의 필요를 위해 새로운 고유 인덱스 이름만 제공하며, 인덱스 패턴을 만들려고 하는지 여부도 선택하게 됩니다.
그리고 Advanced(고급) 모드에서는 사용자가 인덱스를 생성하는 데 사용하게 되는 설정에 대해 좀더 정밀한 컨트롤을 갖게 됩니다.
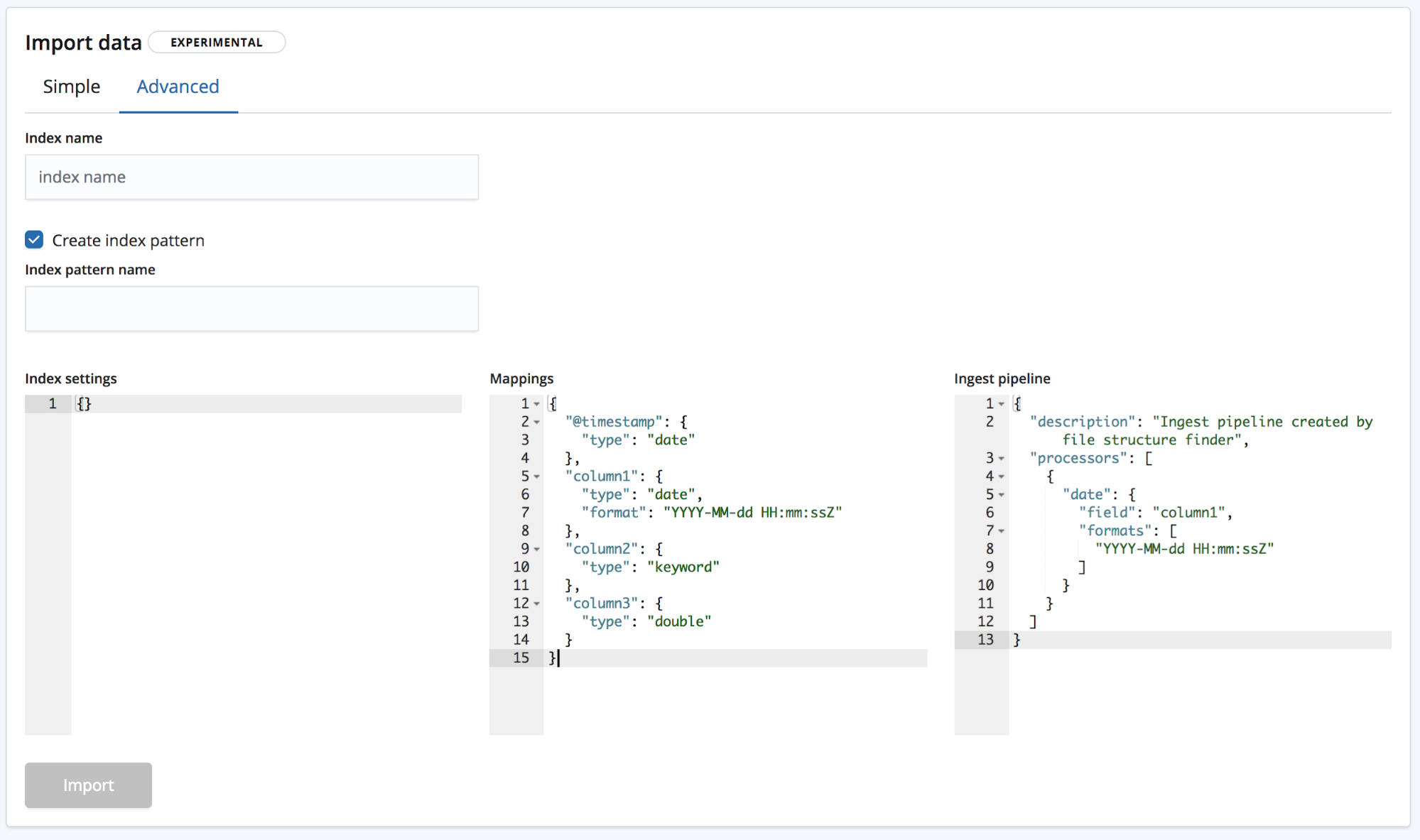
- Index settings(인덱스 설정) - 기본 설정으로, 인덱스를 생성하고 가져오는 데 추가 설정이 필요없지만, 인덱스 설정을 사용자 정의하는 옵션은 여전히 제공됩니다.
- Mappings(매핑) -
find_file_structure는 식별한 필드와 유형을 바탕으로 매핑 객체를 제공합니다. 가능한 매핑 목록은, Elasticsearch 매핑 설명서를 참조하세요. - Ingest pipeline(수집 파이프라인) -
find_file_structure는 기본 수집 파이프라인 객체를 제공합니다. 이것은 데이터를 수집할 때 사용되며 추가 데이터를 업로드하는 데 사용될 수 있습니다.
버전 6.5 내에서는 새로운 인덱스 생성만 허용되며, 인덱스 손상 위험을 줄이기 위해 기존 인덱스에 데이터를 추가하는 기능은 제공되지 않습니다.
가져오기 버튼을 클릭하면 가져오기 프로세스가 시작됩니다. 이것은 번호가 매겨진 여러 단계로 이루어집니다.
- Processing file(파일 처리) - 대량 api를 사용해 수집될 수 있도록 데이터를 NDJSON 문서로 전환
- Creating index(인덱스 만들기) - 설정과 매핑 객체를 사용해 인덱스 만들기
- Creating ingest pipeline(수집 파이프라인 만들기) - 수집 파이프라인 객체를 사용해 수집 파이프라인 만들기
- Uploading the data(데이터 업로드) - 새로운 Elasticsearch 인덱스로 데이터 로딩
- Creating index pattern(인덱스 패턴 만들기) - Kibana 인덱스 패턴 만들기(사용자가 선택한 경우)

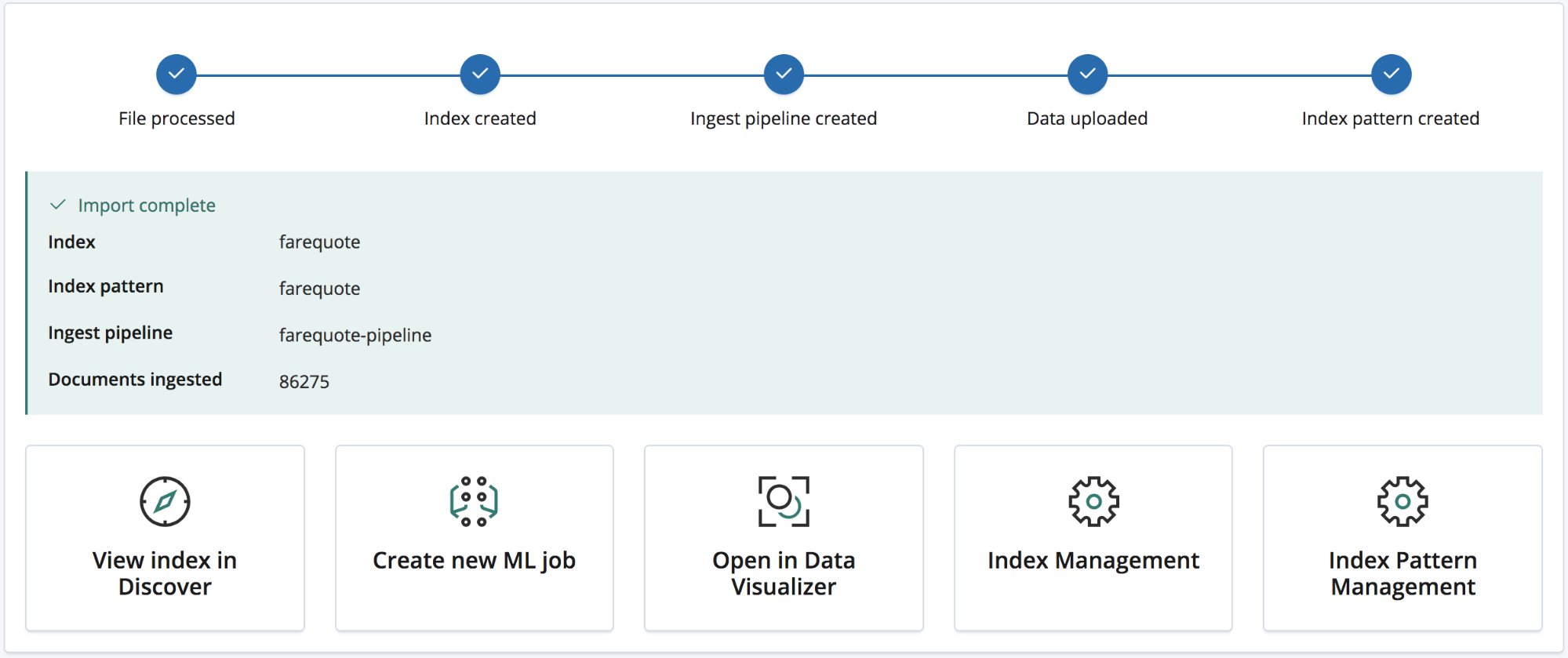
가져오기가 완료되면, 생성된 인덱스 이름, 인덱스 패턴, 수집 파이프라인의 요약 목록과 수집된 문서의 개수가 사용자에게 제공됩니다.
아울러, 새로 가져온 데이터 탐색을 위해 여러 Kibana 링크도 제공됩니다. 플래티넘과 체험판 구독 사용자에게는 데이터에서 신속하게 머신 러닝 작업을 만들기 위한 링크도 제공됩니다.
예제: 로그 파일과 다른 반구조적 텍스트를 Elasticsearch로 가져오기
지금까지 CSV 데이터에 대해 다뤄봤습니다. 그리고 NDJSON은 가져오는 데 필요한 처리가 거의 없어 훨씬 간단합니다. 하지만 반구조적 텍스트는 어떨까요? CSV 데이터 분석이 일반적인 로그 파일 데이터, 달리 말해 반구조적 텍스트와 어떻게 다른지 살펴보겠습니다.
다음은 라우터가 생성한 로그 파일의 세 줄입니다.
<190>38377: GOW45-AR002: Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378: GOW45-AR002: Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379: GOW45-AR002: Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
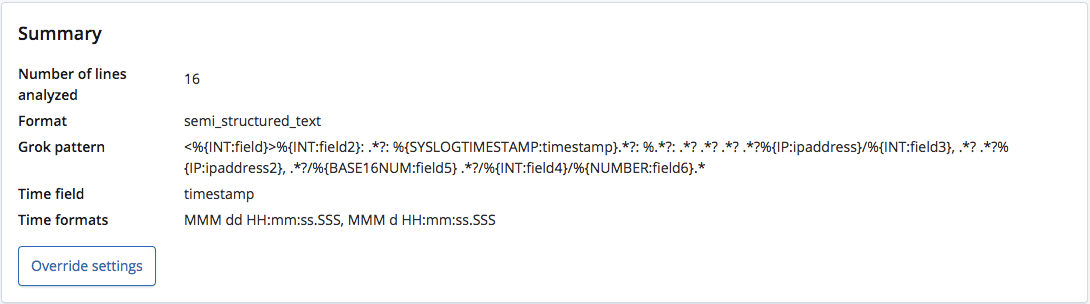
find_file_structure 끝점이 분석할 때, 형식이 반구조적 텍스트라는 것을 정확히 인식하며 각 줄에서 필드와 그 유형을 추출하기 위한 Grok 패턴을 생성합니다. 이러한 필드 중에, 어느 것이 시간 필드와 그 형식인지도 인식합니다.
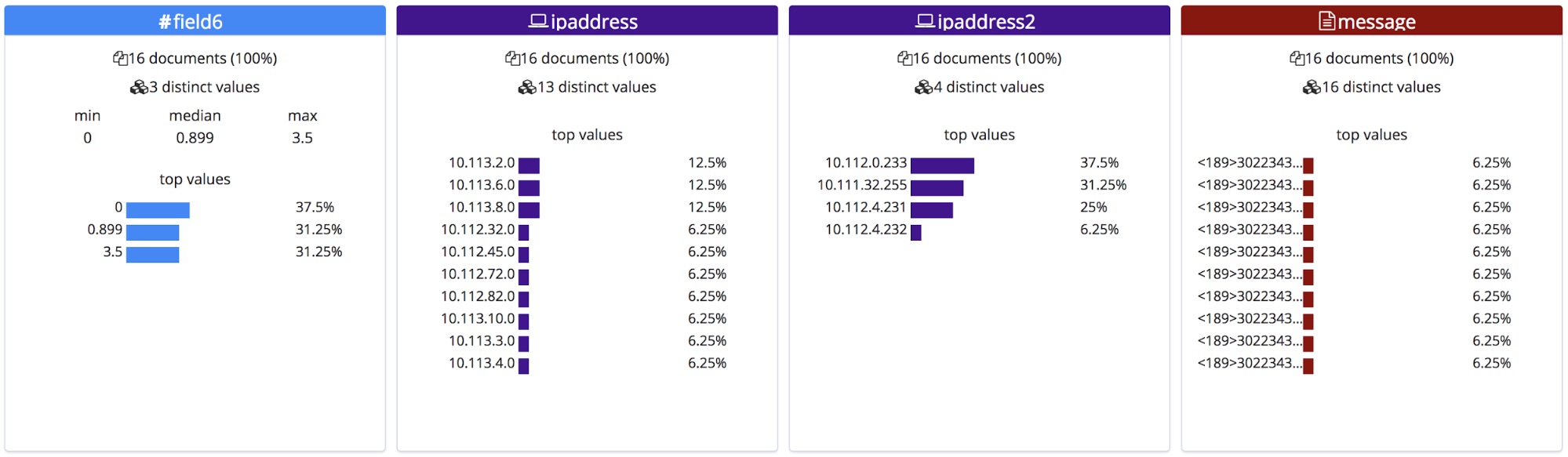
머리글이 있는 CSV 파일이나 NDJSON 파일과는 달리, 이러한 필드에 대한 정확한 이름을 알 수가 없습니다. 따라서 끝점은 그 유형을 바탕으로 일반적인 이름을 부여합니다.
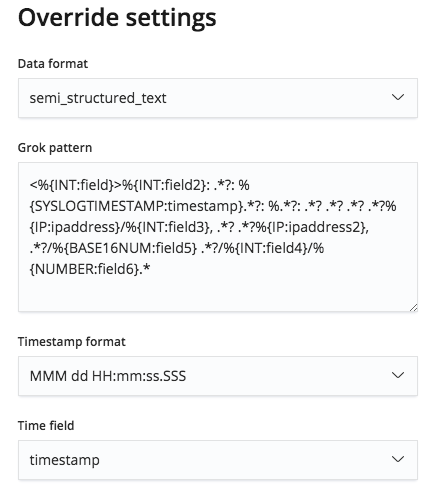
그러나, 이 Grok 패턴은 Override settings(재정의 설정) 메뉴를 통해 편집이 가능하며 따라서 필드 이름과 그 유형을 정정할 수 있습니다.
그러면 이 정정된 필드 이름이 File(파일) 통계 섹션에 표시됩니다. 이것은 알파벳 순으로 정렬되며, 그 순서가 살짝 변경되었다는 것을 주목해서 보시기 바랍니다.
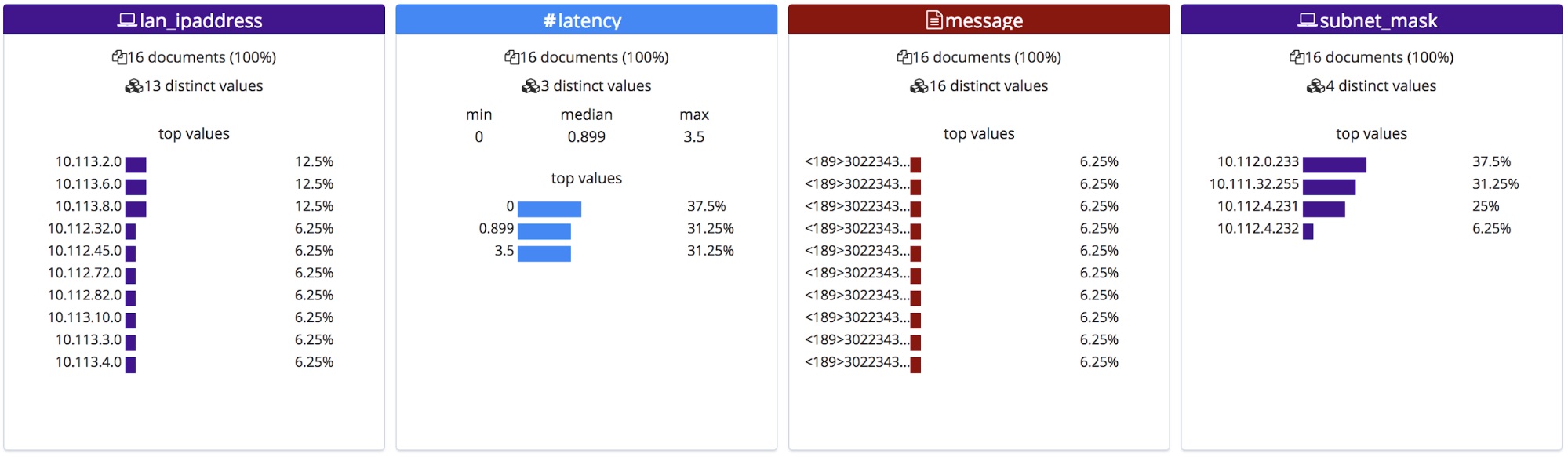
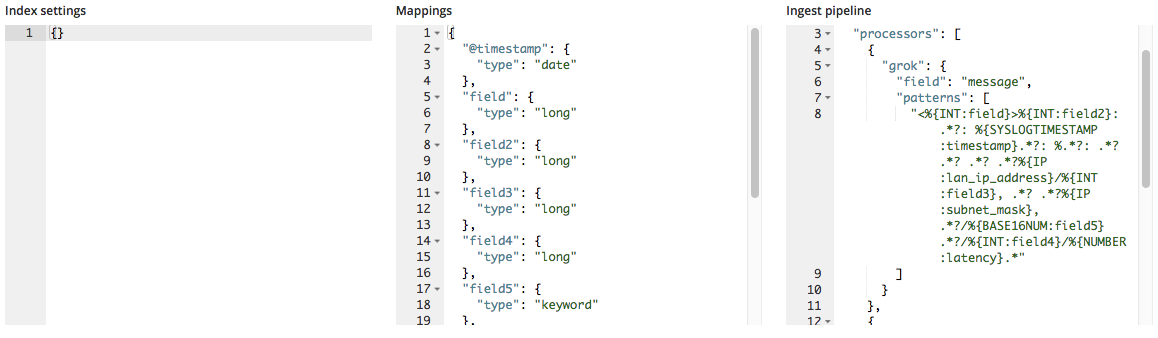
가져올 때, 이 새 필드 이름이 매핑 객체에 추가되며, Grok 패턴은 수집 파이프라인에서 프로세서 목록에 추가됩니다.
결론
이 글을 통해 버전 6.5의 새로운 File Data Visualizer 기능을 사용해 보고 싶은 마음이 드셨으면 좋겠습니다. 6.5에서 아직 실험 중인 기능이기 때문에 모든 파일 형식이 정확히 일치하지 않을 수도 있습니다. 하지만 체험판을 사용해 보시고 어땠는지 알려주세요. 사용자의 피드백은 이 기능을 정식 버전(GA)으로 더 빨리 출시하는데 도움이 됩니다.