Google Dataflow를 사용해 Google BigQuery에서 Elastic으로 직접 데이터 수집


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
오늘 Elastic Stack으로의 BigQuery 직접 데이터 수집 지원을 발표하게 되어 기쁘게 생각합니다. 이제 데이터 분석가와 개발자는 Google Cloud Console에서 클릭 몇 번만으로 Google BigQuery에서 Elastic Stack으로 데이터를 수집할 수 있습니다. Dataflow 템플릿을 활용하여 고객은 기본 통합을 통해 데이터 파이프라인 아키텍처를 단순화하고 에이전트 설치 및 관리와 관련된 운영 오버헤드를 제거할 수 있습니다.
많은 데이터 분석가와 개발자들은 Google BigQuery를 데이터 웨어하우스 솔루션으로, Elastic Stack을 검색 및 대시보드 시각화 솔루션으로 사용합니다. 두 솔루션 모두의 경험을 향상시키기 위해 Google과 Elastic은 함께 협력하여 BigQuery 테이블과 뷰에서 Elastic Stack으로 데이터를 수집하는 간단한 방법을 제공하게 되었습니다. 이 모든 것은 데이터 수집기 또는 ETL(추출, 변환, 로드) 도구를 설치하지 않고도 Google Cloud Console에서 클릭 몇 번만으로 가능합니다.
이 블로그 게시물에서는 Google BigQuery에서 Elastic Stack으로 에이전트 없는 데이터 수집을 시작하는 방법에 대해 설명합니다.
BigQuery + Elastic 사용 사례 간소화
BigQuery는 사용자 정의 애플리케이션, 데이터베이스, Marketo, NetSuite, Salesforce, 웹 클릭스트림 또는 심지어 Elasticsearch와 같은 다양한 소스의 데이터를 중앙 집중화할 수 있는 인기 있는 서버리스 데이터 웨어하우스 솔루션입니다. 사용자는 서로 다른 소스에서 온 데이터 세트의 조인을 수행한 다음 SQL 쿼리를 실행하여 데이터를 분석할 수 있습니다. BigQuery SQL 작업의 출력을 활용하여 BigQuery에서 더 많은 뷰와 테이블을 만들거나 조직의 다른 이해관계자 및 팀과 공유할 대시보드를 만드는 것이 일반적입니다. 이러한 대시보드는 Elastic의 기본 데이터 시각화 도구인 Kibana를 통해 얻을 수 있습니다!
BigQuery와 Elastic Stack의 또 다른 주요 사용 사례는 풀텍스트 검색입니다. BigQuery 사용자는 Elasticsearch로 데이터를 수집한 다음 Elasticsearch API 또는 Kibana를 사용하여 검색 결과를 쿼리하고 분석할 수 있습니다.
데이터 수집 간소화
Google Dataflow는 Apache Beam을 기반으로 하는 서버리스 비동기 메시징 서비스입니다. Logstash 대신 Dataflow를 사용하여 Google Cloud Console에서 직접 데이터를 수집할 수 있습니다. Google과 Elastic 팀은 함께 협력하여 BigQuery에서 Elastic Stack으로 데이터를 푸시하기 위한 즉시 사용 가능한 Dataflow 템플릿을 개발하게 되었습니다. 이 템플릿은 이전에 서버리스 방식으로 Logstash가 완료한 데이터 형식 변환과 같은 데이터 처리를 대체하며, 이전에 Elasticsearch 수집 파이프라인을 사용한 사용자에 대한 다른 변경 사항은 없습니다.
현재 BigQuery와 Elastic Stack을 사용하고 있는 경우, Logstash와 같은 별도의 데이터 프로세서나 사용자 정의 솔루션을 Google Compute Engine 가상 머신(VM)에 설치한 다음 이러한 데이터 프로세서 중 하나를 사용하여 BigQuery에서 Elastic Stack으로 데이터를 전송해야 합니다. VM을 프로비저닝하고 데이터 프로세서를 설치하려면 프로세스 및 관리 오버헤드가 필요합니다. 이제 Dataflow의 드롭다운 메뉴를 사용하여 이 단계를 건너뛰고 BigQuery에서 Elastic으로 직접 데이터를 수집할 수 있습니다. 마찰을 제거하는 것은 특히 Google Cloud Console에서 클릭 몇 번으로 수행할 수 있는 경우 많은 사용자에게 유용합니다.
다음은 데이터 수집 흐름의 요약입니다. 통합은 Elastic Cloud의 Elastic Stack을 사용 중이든, Google Cloud Marketplace의 Elastic Cloud를 사용 중이든 또는 자체 관리 환경을 사용 중이든, 모든 사용자에게 적용됩니다.
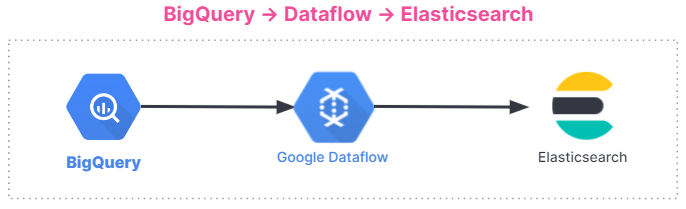
시작하기
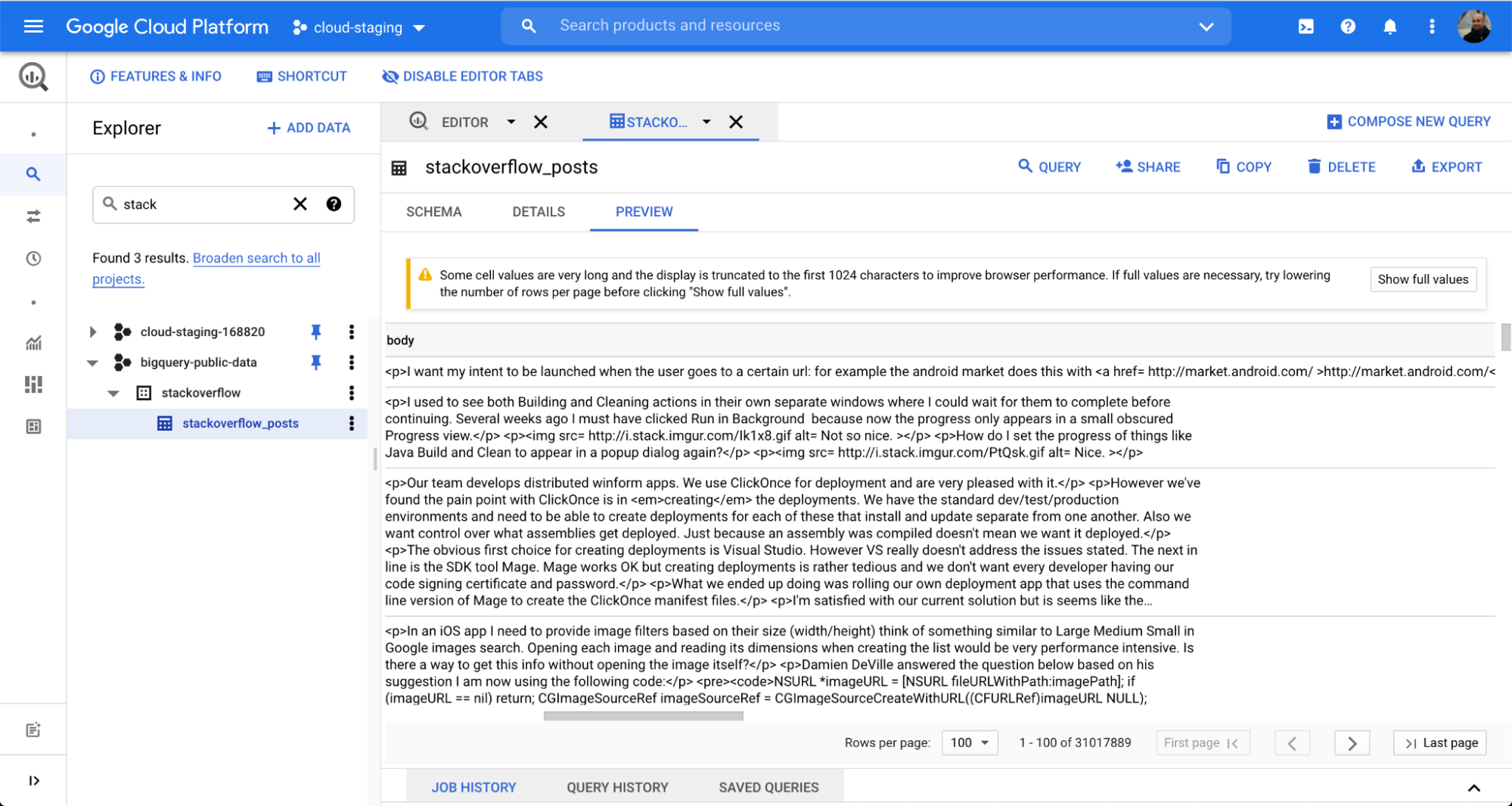
BigQuery에서 Elasticsearch로 데이터를 통합하는 것이 얼마나 쉬운지 설명하기 위해, 널리 사용되는 Q&A 포럼 Stack Overflow의 공개 데이터 세트를 사용하겠습니다. 클릭 몇 번만으로 Dataflow 배치 작업을 통해 데이터를 수집하고 Kibana에서 검색 및 분석을 시작할 수 있습니다.
BigQuery 데이터 세트 stackoverflow 아래에 있는 stackoverflow_posts라는 테이블을 사용했습니다. 여기에는 post body, title, comment_count, 등과 같은 열로 구성된 여러 필드가 있으며, 이를 Elasticsearch에 가져와 자유 텍스트 검색 및 집계를 수행하게 됩니다.
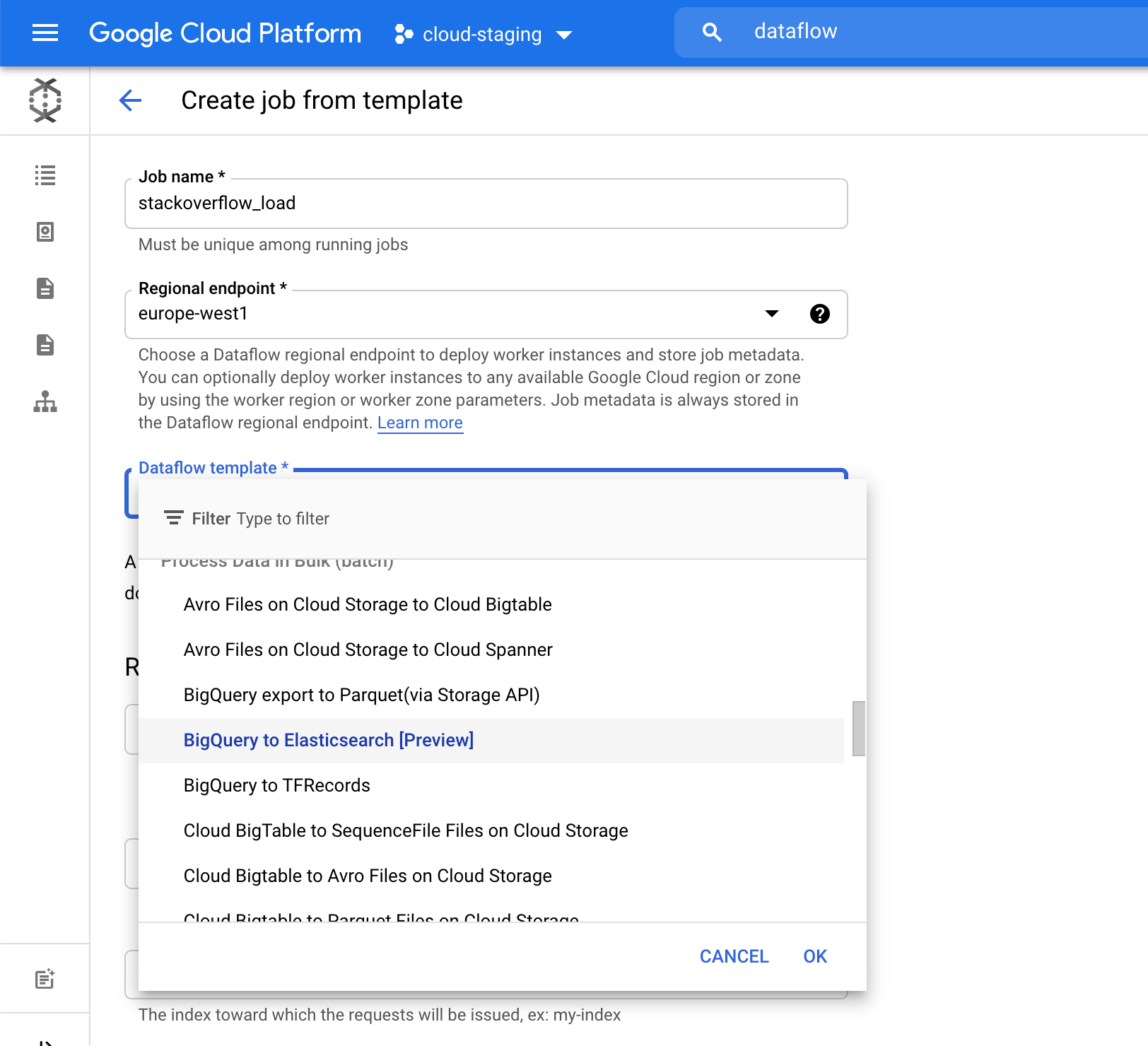
Elasticsearch index 필드에서 데이터를 로드할 인덱스 이름을 선택합니다. 예를 들어, 우리는 stack-posts 인덱스를 사용했습니다. BigQuery의 테이블은 my-project:my-dataset.my-table 형식으로 읽을 수 있습니다. 이 예에서는 bigquery-public-data:stackoverflow.stackoverflow_posts입니다.
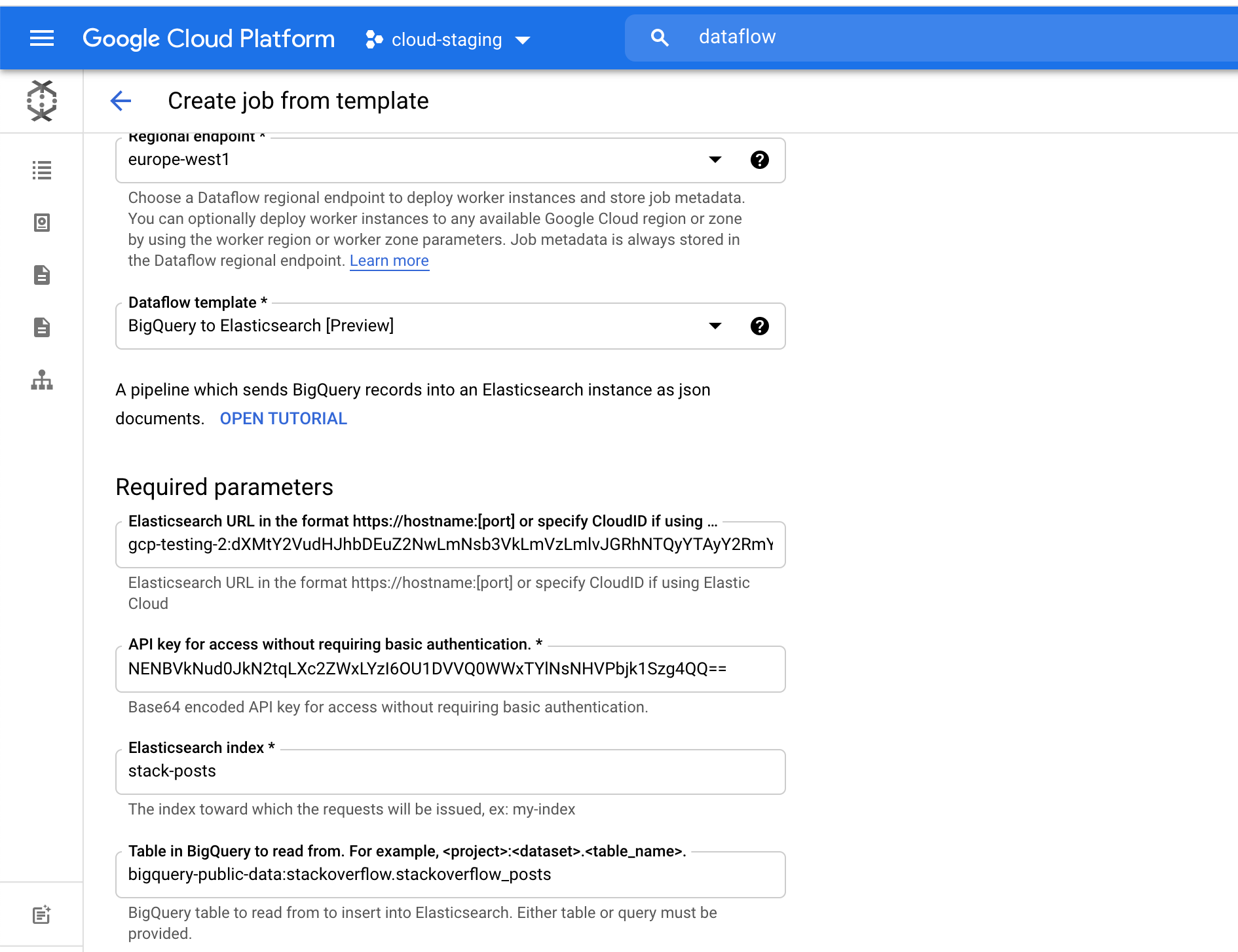
Run Job을 클릭하여 배치 처리를 시작합니다.
몇 분 안에 Elasticsearch 인덱스로 데이터가 유입되는 것을 볼 수 있습니다. 이 데이터를 시각화하려면 설명서를 따라 인덱스 패턴을 만드세요.
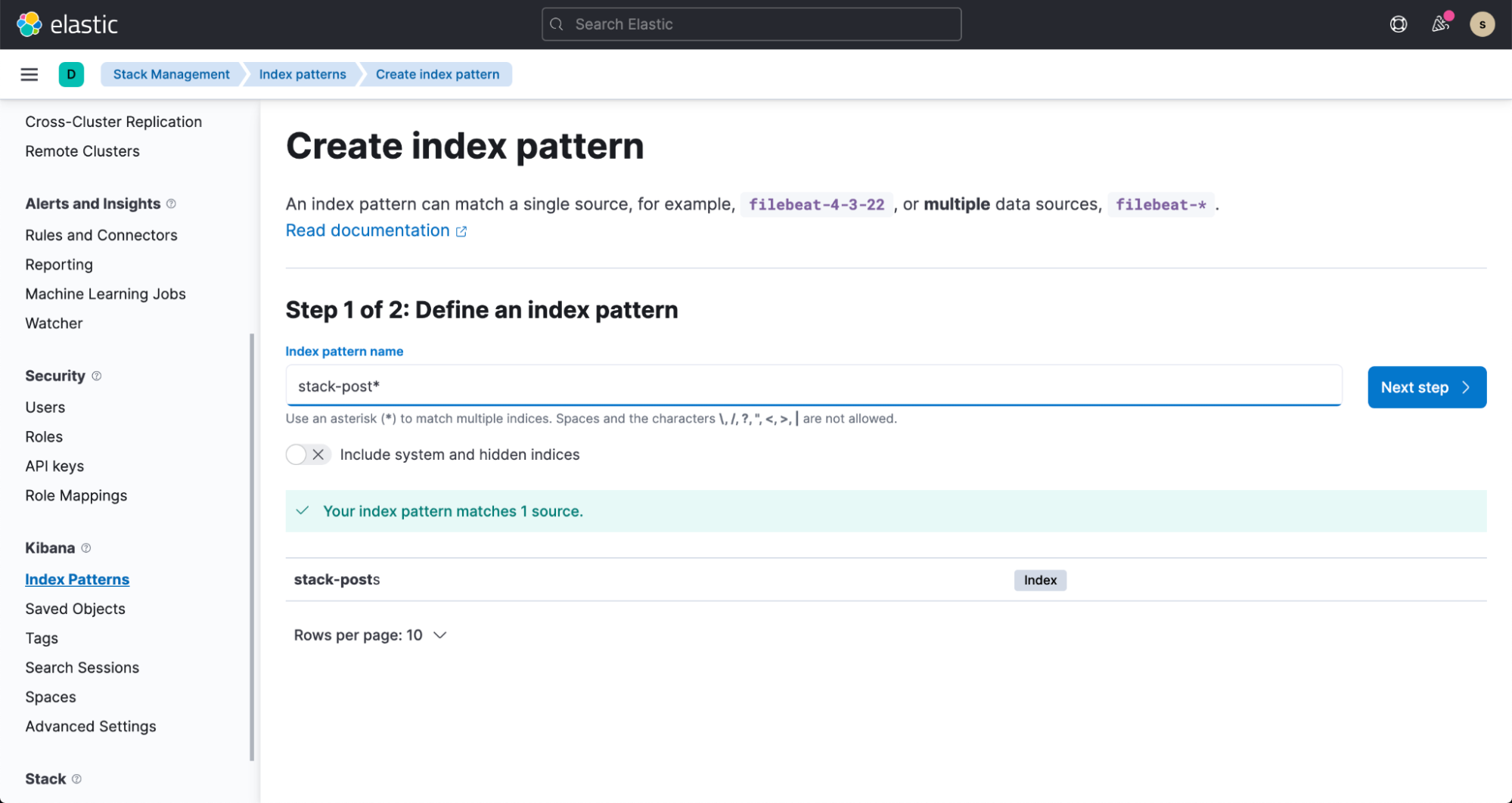
이제 Kibana의 Discover로 가서 여러분의 데이터 검색을 시작해 보세요!
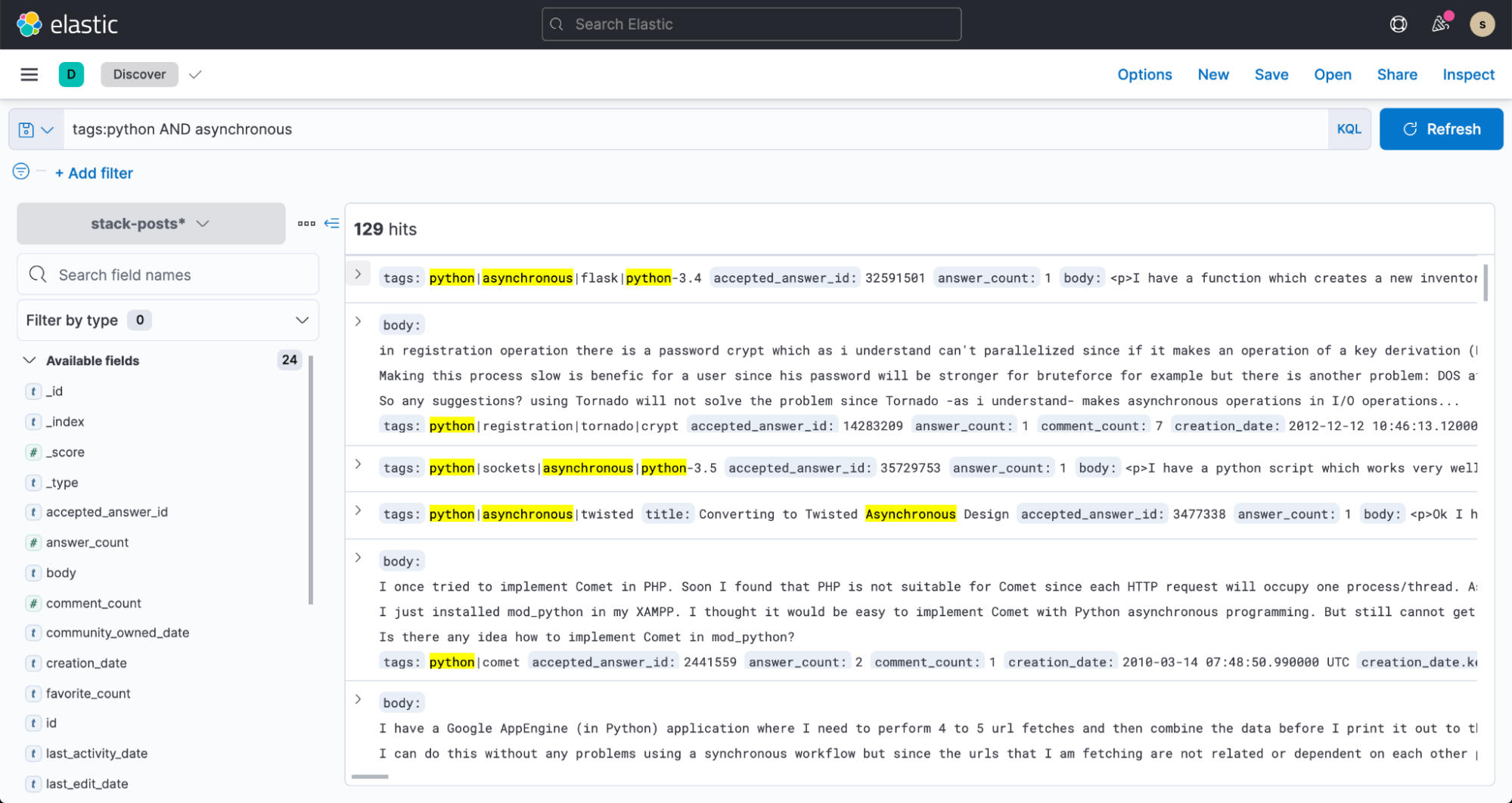
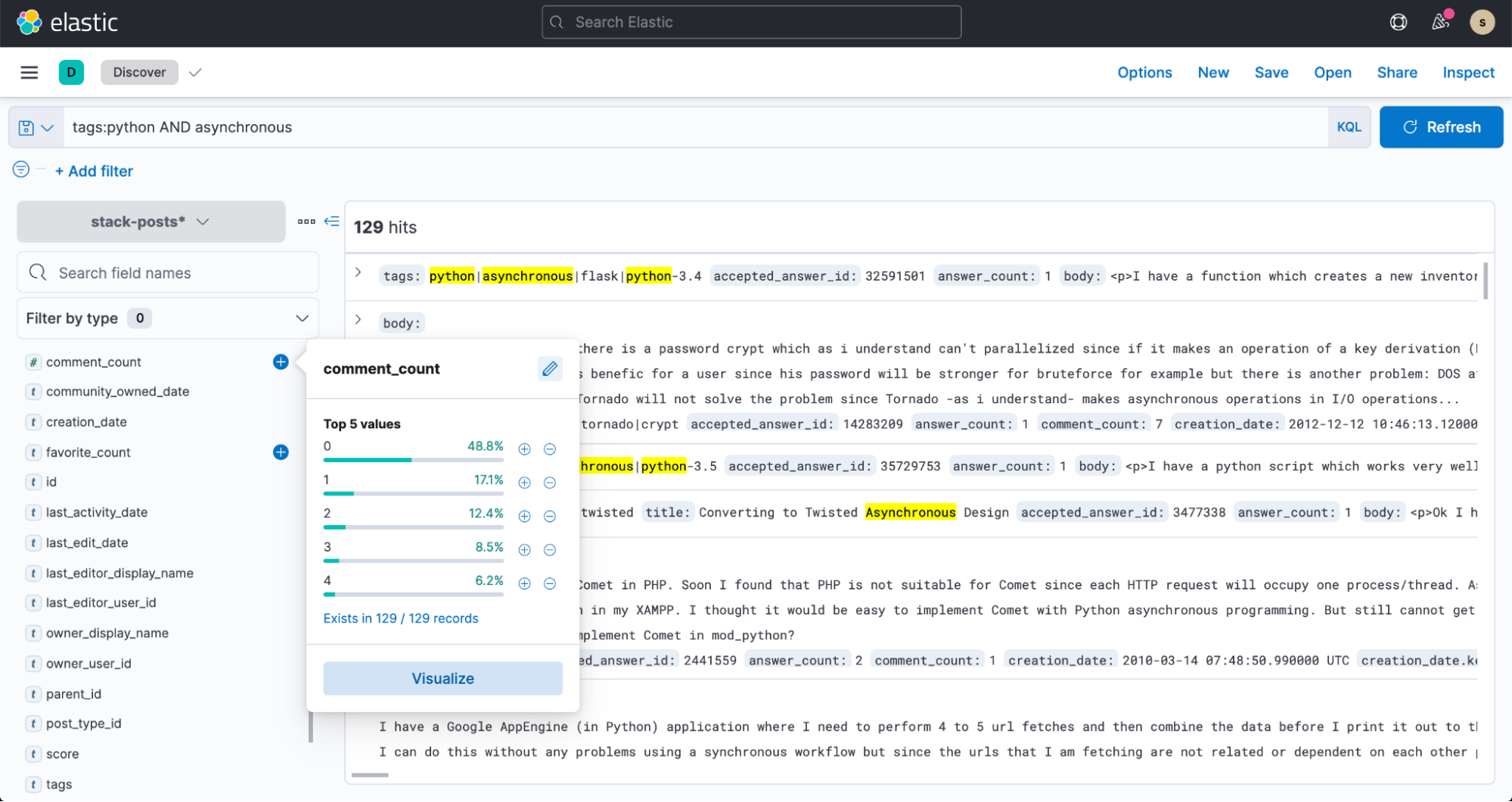
결론
Elastic은 끊임없는 개발을 통해 고객이 보다 쉽고 원활하게 원하는 곳에서 실행하고 원하는 것을 사용할 수 있도록 지원하고 있습니다. Google Cloud와의 이러한 간소화된 통합이 그 가장 최근의 예입니다. Elastic Cloud는 Elastic Stack의 가치를 확장하여 고객이 더 많은 것을, 더 빨리 할 수 있도록 하며, 이것은 고객이 플랫폼을 경험할 수 있는 가장 좋은 방법입니다. Google Cloud에서 Elastic을 사용하려면 Google Cloud Marketplace 또는 elastic.co를 방문하세요.공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기