Elasticsearch, Kibana, Beats를 사용한 Kafka 모니터링
우리는 2016년에 처음으로 Filebeat를 이용한 Kafka 모니터링에 대해 포스팅을 했습니다. 6.5 릴리즈 이래, Beats팀은 Kafka 모듈을 지원해 왔습니다. 이 모듈은 Kafka 클러스터를 모니터링하는 데 관련된 작업의 많은 부분을 자동화합니다.
이 블로그 포스팅에서는, Filebeat와 Metricbeat에서 Kafka 모듈로 로그와 메트릭 데이터를 수집하는 데 중점을 두도록 하겠습니다. 우리는 Elasticsearch Service에서 호스팅되는 클러스터로 데이터를 수집하며, Beats 모듈이 제공하는 Kibana 대시보드를 탐색해 볼 것입니다.
이 블로그 포스팅은 Elastic Stack 7.1을 사용합니다. 예제 환경은 GitHub에서 제공됩니다.
왜 모듈인가?
복잡한 Logstash Grok 필터를 가지고 작업해 본 사람이면 누구나 Filebeat 모듈을 통해 로그 수집을 설정하는 데 있어 그 단순함을 높이 평가할 것입니다. 모니터링 구성에서 모듈을 활용하면 그 밖에도 다음과 같은 다른 장점들이 있습니다.
- 로그와 메트릭 수집의 간소화된 구성
- Elastic Common Schema를 통한 표준화된 문서
- 최적의 필드 데이터 유형을 제공하는 합리적인 인덱스 템플릿
- 적절한 인덱스 크기 조정 Beats는 롤오버 API를 활용하여 Beats 인덱스를 위한 적절한 샤드 크기를 유지하도록 도와줍니다.
Filebeat와 Metricbeat가 지원하는 전체 모듈 목록은 설명서를 참조하세요.
환경 소개
우리 예제 설정은 세 개의 Kafka 클러스터 노드(kafka0, kafka1, kafka2)로 구성됩니다. 각 노드는 Kafka 2.1.1을 실행하며, Filebeat와 Metricbeat는 노드를 모니터링합니다. Beats는 Cloud ID를 통해 구성되어 우리의 Elasticsearch Service 클러스터로 데이터를 전송합니다. Filebeat와 Metricbeat로 전송된 Kafka 모듈은 시각화를 위해 Kibana 내에서 대시보드를 설정하게 됩니다. 한 가지 알려드리자면, 자체 클러스터에서 이것을 해보려고 하시는 경우, Elasticsearch Service의 14일 무료 체험판을 활용하실 수 있습니다. 여기에는 모든 필요한 기능들이 탑재되어 있습니다.
Beats 설정
다음으로, Beats를 구성하고 나서 시작하게 됩니다.
Beats 서비스 설치 및 활성화
시작하기 안내서를 따라 Filebeat와 Metricbeat를 설치하겠습니다. Ubuntu에서 실행하고 있기 때문에, APT 리포지토리를 통해 Beats를 설치하겠습니다.
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list sudo apt-get update sudo apt-get install filebeat metricbeat systemctl enable filebeat.service systemctl enable metricbeat.service
Elasticsearch Service 배포의 Cloud ID 구성
Elastic Cloud 콘솔에서 Cloud ID를 복사하여, 이를 사용해 Filebeat와 Metricbeat를 위한 출력을 구성합니다.
CLOUD_ID=Kafka_Monitoring:ZXVyb3BlLXdlc...
CLOUD_AUTH=elastic:password
filebeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/filebeat/filebeat.yml
metricbeat export config -E cloud.id=${CLOUD_ID} -E cloud.auth=${CLOUD_AUTH} > /etc/metricbeat/metricbeat.yml
Filebeat와 Metricbeat에서 Kafka와 시스템 모듈 활성화
다음으로, 양쪽 Beats에 대해 Kafka와 시스템 모듈을 활성화해야 합니다.
filebeat modules enable kafka system metricbeat modules enable kafka system
일단 활성화되면, Beats 설정을 실행할 수 있습니다. 이것은 모듈이 사용하는 인덱스 템플릿과 Kibana 대시보드를 구성합니다.
filebeat setup -e --modules kafka,system metricbeat setup -e --modules kafka,system
Beats 시작!
됐습니다. 이제 모든 것이 구성되었으므로, Filebeat와 Metricbeat를 시작해 봅시다.
systemctl start metricbeat.service systemctl start filebeat.service
모니터링 데이터 탐색
기본 로깅 대시보드는 다음을 보여줍니다.
- Kafka 클러스터가 직면한 최근의 예외. 예외는 예외 클래스별로 그룹화됩니다. 그리고 전체 예외 세부사항.
- 레벨별 로그 처리량 개요와 전체 로그 세부사항.
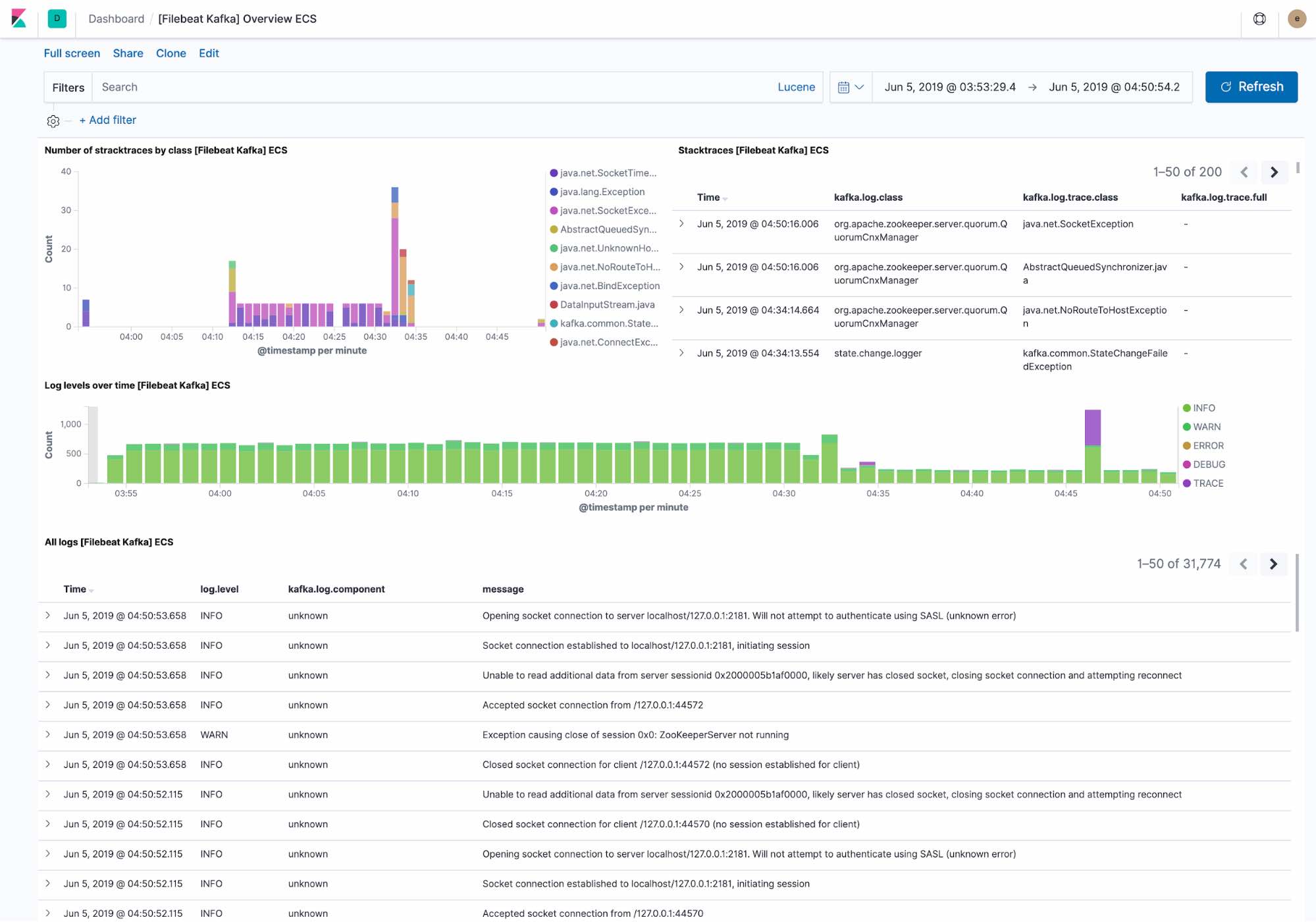
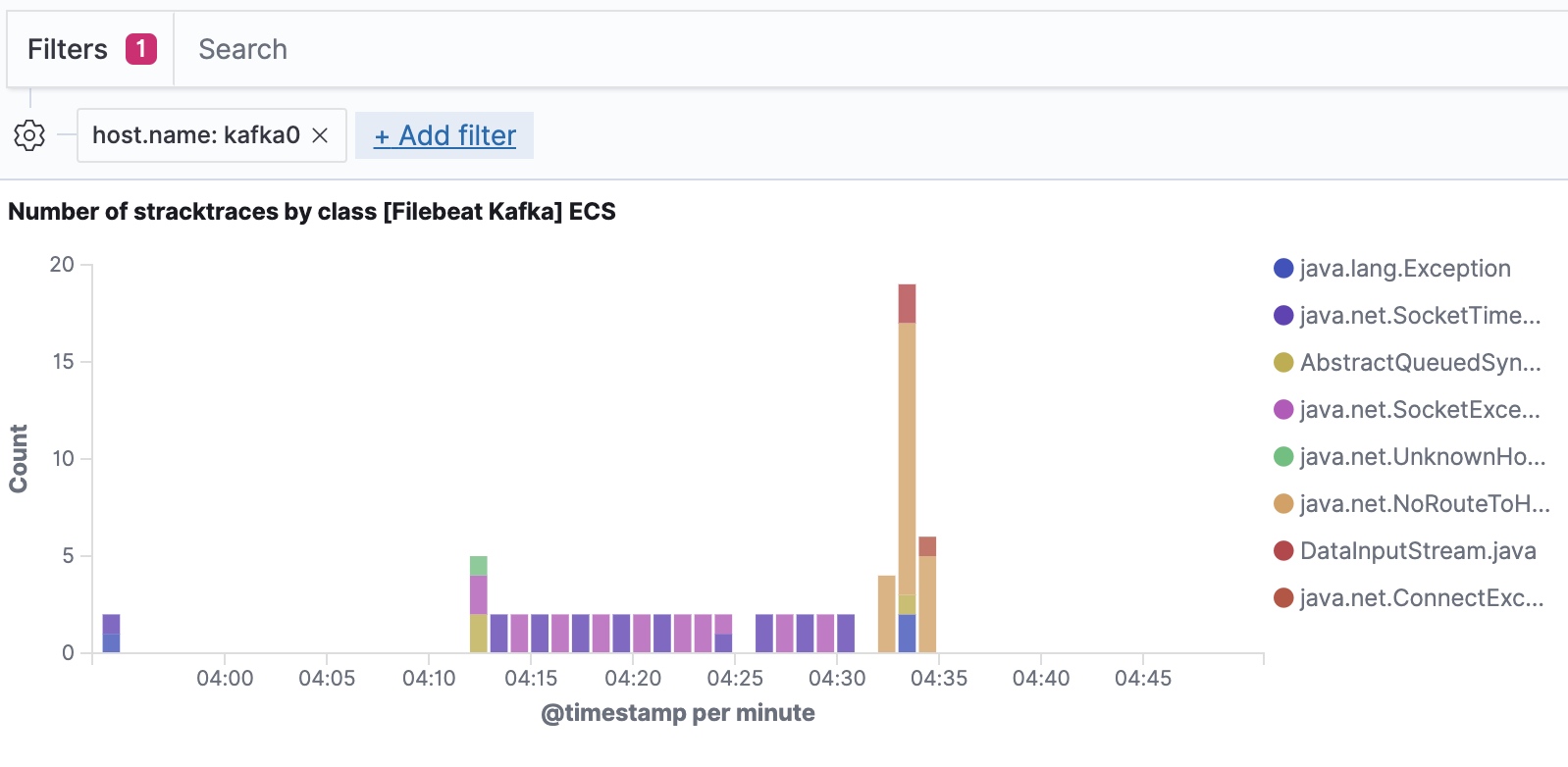
Filebeat는 Elastic Common Schema에 따라 데이터를 수집하며, 우리가 호스트 레벨까지 필터링해 들어갈 수 있게 해줍니다.
Metricbeat가 제공하는 대시보드는 Kafka 클러스터 내에서 모든 주제의 현재 상태를 보여줍니다. 또한 드롭다운을 통해 단일 주제로 대시보드를 필터링할 수도 있습니다.
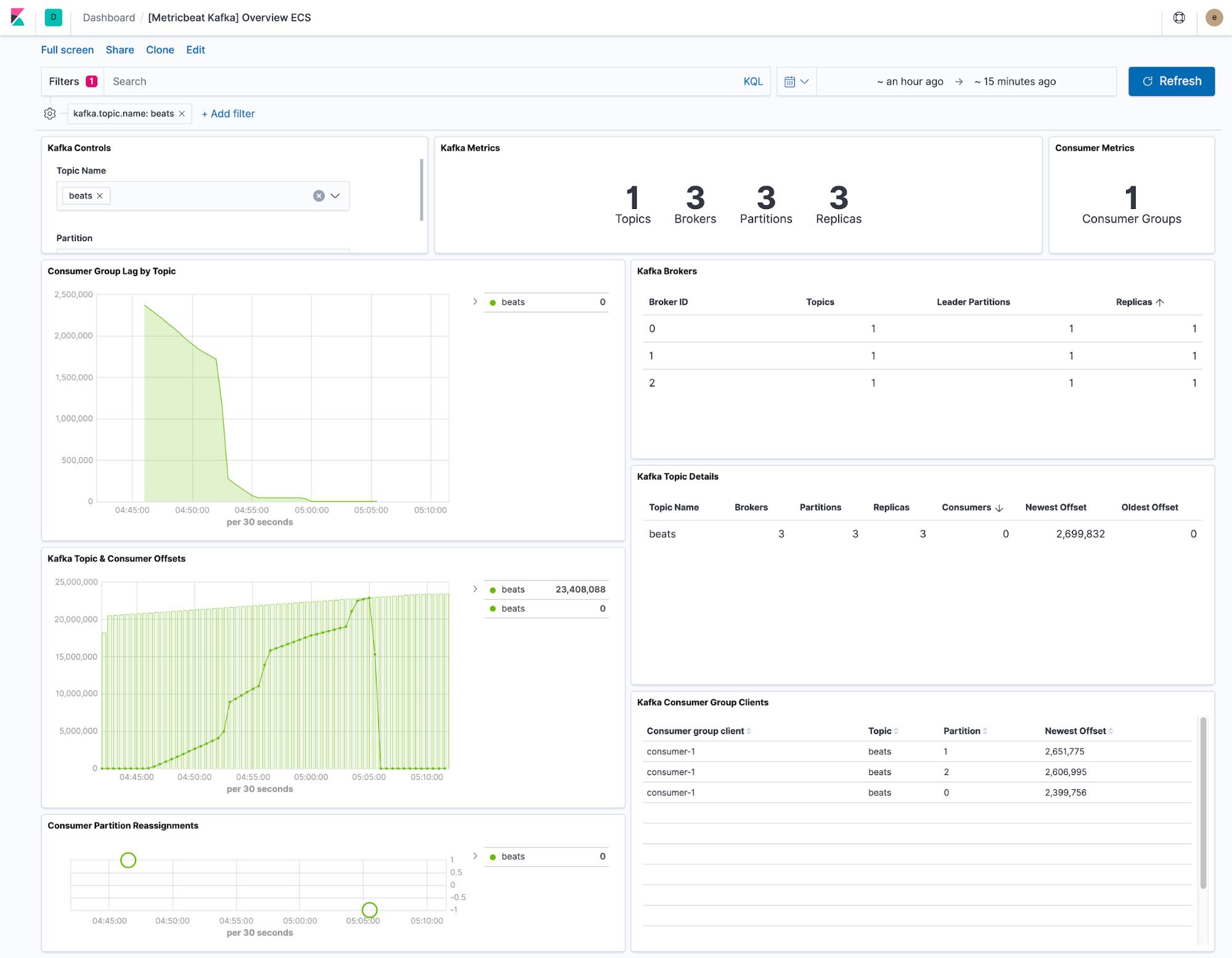
소비자 지연 및 오프셋 시각화는 소비자가 특정 주제에서 뒤처지고 있는지를 보여줍니다. 파티션당 오프셋은 또한 단일 파티션이 뒤떨어지고 있는지를 보여줍니다.
기본 Metricbeat 구성은 kafka.partition과 kafka.consumergroup, 이렇게 두 개의 데이터 세트를 수집합니다. 이 데이터 세트는 Kafka 클러스터와 그 소비자의 상태에 대한 인사이트를 제공합니다.
kafka.partition 데이터 세트에는 클러스터 내의 파티션 상태에 대한 모든 세부사항이 포함됩니다. 이 데이터는 다음을 위해 사용될 수 있습니다.
- 파티션이 클러스터 노드에 대해 어떻게 매핑되어 있는지를 보여주는 대시보드 구축
- 동기화되어 있는 복제가 없는 파티션에 대한 알림
- 시간별 파티션 할당 추적
- 시간별 파티션 오프셋 제한 시각화
전체적인 kafka.partition 문서는 아래에 나와 있습니다.

kafka.consumergroup 데이터 세트는 단일 소비자의 상태를 기록합니다. 이 데이터는 단일 소비자가 어느 파티션에서 읽고 있는지와 그 소비자의 현재 오프셋를 보여주는 데 사용될 수 있습니다.
