실용적인 BM25 - 제2부: BM25 알고리즘과 변수
이것은 유사성 순위(정확도)에 대해 3부작으로 구성된 실용적인 BM25 시리즈의 두 번째 게시물입니다. 이제 막 시작하고 계시다면, 제1부: Elasticsearch에서 샤드가 정확도 점수에 미치는 영향을 참조하세요.
BM25 알고리즘
무슨 일이 일어나고 있는지 설명하기 위해 꼭 필요한 만큼만 여기서 수학을 개입시켜 보겠습니다. 이것은 무슨 일이 일어나고 있는지에 대한 인사이트를 얻기 위해 BM25 공식의 구조를 살펴보는 부분입니다. 먼저 공식을 살펴본 다음, 각 구성 요소를 이해할 수 있는 부분으로 나누어 보겠습니다.
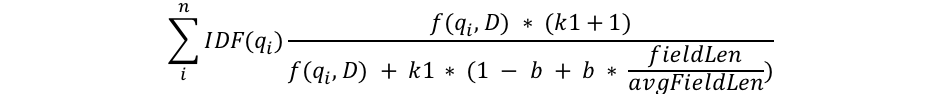
qi, IDF(qi), f(qi,D), k1, b 및 필드 길이에 대한 것 등과 같이 몇 가지 일반적인 구성 요소를 볼 수 있습니다. 다음은 각각의 내용입니다.
- qi는 i번째 쿼리 단어입니다.
예를 들어, "shane"을 검색하면 쿼리 단어가 1개뿐이므로 q0이 "shane"입니다. 영어로 "shane connelly"를 검색하면, Elasticsearch는 공백을 보고 이를 2개의 단어로 토큰화합니다. q0은 "shane"이고 q1은 "connelly"입니다. 이러한 쿼리 단어는 등식의 다른 부분들과 연결되고 모든 쿼리 단어가 요약됩니다. - IDF(gi)는 i번째 쿼리 단어의 역 문서 빈도입니다.
이전에 TF/IDF로 작업해 보신 적이 있는 분들은 IDF의 개념을 잘 알고 계실 수도 있습니다. 잘 모르시더라도, 걱정하지 마세요! (만약 그렇다면, TF/IDF의 IDF 수식과 BM25의 IDF 간에 차이가 있다는 점에 유의하세요.) Elastic 수식의 IDF 구성 요소는 모든 문서에서 어떤 단어가 출현하는 빈도를 측정하고 일반적인 단어에 "페널티를 적용"합니다. Lucene/BM25가 이 부분에 대해 사용하는 실제 수식은 다음과 같습니다.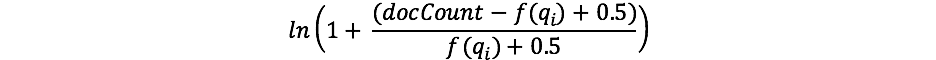
여기서 docCount는 샤드에서(search_type=dfs_query_then_fetch를 사용 중인 경우 여러 샤드에 걸쳐) 필드 값을 가진 총 문서 수입니다. f(qi)는 i번째 쿼리 단어를 포함하는 문서 수입니다. 이 예에서 "shane"은 4개 문서 모두에서 출현하므로 "shane"이라는 단어의 경우 다음과 같은 IDF("shane")로 끝나는 것을 볼 수 있습니다.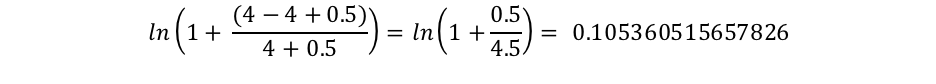
그러나 "connelly"는 두 개의 문서에만 표시되므로 IDF("connelly")는 다음과 같습니다.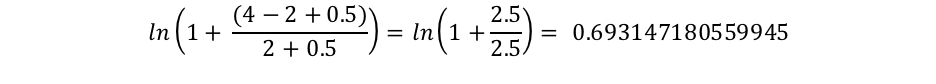
여기서 이러한 빈도수가 더 드문 단어를 포함하는 쿼리("connelly"는 4-문서 말뭉치에서 나타나는 "shane"보다 빈도수가 더 드물게 나타남)의 승수가 더 높으므로 최종 점수에 대한 기여도가 더 높다는 것을 알 수 있습니다. 이것은 직관적으로 이해가 됩니다. "the"라는 단어는 거의 모든 영어 문서에서 출현할 가능성이 높기 때문에, 사용자가 "the elephant"와 같은 것을 검색할 때 "elephant"는 아마도 (거의 모든 문서에 포함될) "the"라는 단어보다 더 중요하며, 따라서 우리는 "elephant"가 점수에 대해 더 높게 기여하기를 바랄 것입니다.
- 우리는 필드의 길이가 분모의 평균 필드 길이로 fieldLen/avgFieldLen으로 나뉘는 것을 확인할 수 있습니다.
어떤 문서가 평균 문서 길이에 비해 상대적으로 얼마나 긴지 생각할 수 있습니다. 문서가 평균보다 길면 분모가 커지고(점수가 감소), 평균보다 짧으면 분모가 작아집니다(점수가 증가). Elasticsearch에서 필드 길이의 구현은 단어 수(문자 길이와 같은 다른 요소 대비)를 기반으로 합니다. 이것은 원본 BM25 문서에 설명된 것과 정확히 일치하지만, 여러분이 특히 원하시는 경우 동의어를 처리할 수 있는 특별한 플래그(discount_overlaps)가 있습니다. 이에 대해 생각할 수 있는 방법은 문서에 있는 단어가 많을수록(최소한 쿼리와 일치하지 않는 단어) 문서에 대한 점수가 낮아진다는 것입니다. 다시 말씀드리지만, 이것은 직관적으로 이해가 됩니다. 어떤 문서가 300페이지짜리이고 그 문서에서 제 이름이 한 번 언급된다면, 저를 한 번 언급하는 어떤 짧은 트윗보다 저와 관련성이 더 높을 가능성이 더 적습니다. - 우리는 분모에 나타나는 변수 b와 우리가 방금 논의한 필드 길이의 비율을 곱한 것을 봅니다. b가 더 크면, 평균 길이 대비 문서 길이의 효과가 더 증폭됩니다. 이를 보려면, b를 0으로 설정하는 경우 길이 비율의 효과가 완전히 무효화되고 문서의 길이는 점수에 영향을 미치지 않는다고 상상할 수 있습니다. 기본적으로 Elasticsearch에서 b의 값은 0.75입니다.
- 마지막으로, 우리는 분자와 분모 양쪽 모두에 나타나는 점수의 두 가지 구성 요소인 k1과 f(qi,D)를 봅니다. 분자와 분모 양쪽 모두에 나타나기 때문에 수식만 보고는 이 두 가지 구성 요소가 어떤 역할을 하는지 알기가 어렵지만, 간단히 살펴보도록 하겠습니다.
- f(qi,D)는 "문서 D에서 i번째 쿼리 단어가 몇 번 출현하는가?"입니다. 이 모든 문서에서, f("shane", D)는 1이지만 f("connelly", D)는 다양합니다. 즉, 문서 3과 4의 경우 1이지만, 문서 1과 2의 경우 0입니다. 텍스트 "shane shane"이 있는 5번째 문서가 있다면 f(“shane”,D)는 2일 것입니다. 우리는 f(qi,D)가 분자와 분모 양쪽 모두에 있고, 우리가 다음으로 다루게 될 특별한 “k1” 요소가 있음을 알 수 있습니다. f(qi,D)에 대해 생각할 수 있는 방법은 문서에 쿼리 단어(들)이 더 많이 출현할수록 그 점수가 더 높아지게 된다는 것입니다. 이것은 직관적으로 이해가 됩니다. 우리의 이름이 아주 여러 번 포함된 문서는 한 번만 포함된 문서보다 우리와 관련이 있을 가능성이 높습니다.
- k1은 단어 빈도 포화 특성을 결정하는 데 도움이 되는 변수입니다. 즉, 단일 쿼리 단어가 해당 문서의 점수에 영향을 줄 수 있는 정도를 제한합니다. 이것은 점근선에 접근함으로써 이를 수행합니다. 다음에서 TF/IDF에 대한 BM25의 비교를 확인하실 수 있습니다.
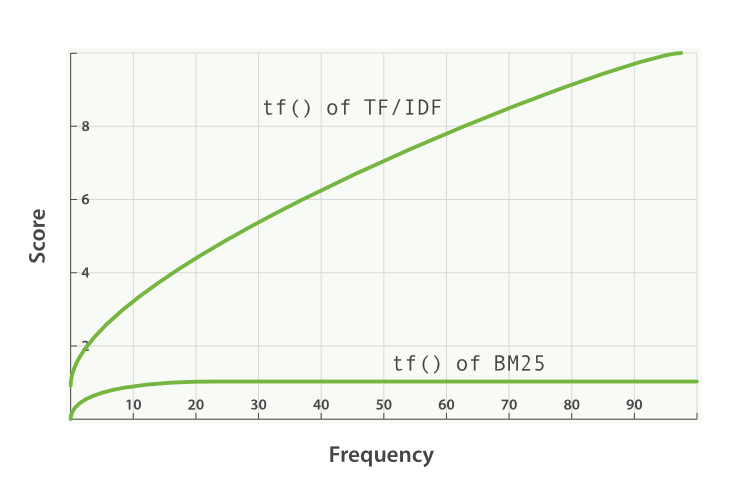
k1 값이 더 높으면/낮으면 "BM25의 tf()" 곡선의 기울기가 변한다는 것을 의미합니다. 이것은 "추가 빈도로 출현하는 단어가 추가 점수를 더하는" 방법을 변경하는 효과가 있습니다. k1의 해석은 평균 길이의 문서의 경우, 고려된 단어에 대한 최대 점수의 절반을 제공하는 단어 빈도의 값입니다. 점수에 대한 tf의 영향 곡선은 tf() ≤ k1일 때 빠르게 증가하고 tf() > k1일 때 점점 느려집니다.
k1을 사용해 이 예제를 계속 진행하면서, 우리는 "두 번째 'shane'을 문서에 추가하는 것이 두 번째 출현과 비교하여 첫 번째 출현이나 세 번째 출현보다 얼마나 더 점수에 기여해야 하는가?"라는 질문에 대한 답을 조절하고 있습니다. k1이 더 높으면 각 단어에 대한 점수가 해당 단어의 더 많은 인스턴스에 대해 상대적으로 더 많이 올라갈 수 있음을 의미합니다. k1의 값이 0이면 IDF(qi)를 제외한 모든 것이 취소됨을 의미합니다. 기본적으로 Elasticsearch에서 k1의 값은 1.2입니다..
새로운 지식을 통해 검색에 대해 다시 생각해 보기
people 인덱스를 삭제하고 search_type=dfs_query_then_fetch를 사용할 필요가 없도록 1개의 샤드로 다시 작성하겠습니다. k1의 값을 0으로, b의 값을 0.5으로 설정한 인덱스, b의 값을 0으로, k1의 값을 10으로 설정한 두 번째 인덱스(people2), b의 값을 1로, k1의 값을 5로 설정한 세 번째 인덱스(people3), 이렇게 세 가지 인덱스를 설정하여 우리의 지식을 테스트해 보겠습니다.
DELETE people
PUT people
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.5,
"k1": 0
}
}
}
}
}
PUT people2
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0,
"k1": 10
}
}
}
}
}
PUT people3
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 1,
"k1": 5
}
}
}
}
}
이제 세 가지 인덱스 모두에 몇 가지 문서를 추가하겠습니다.
POST people/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people2/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
POST people3/_doc/_bulk
{ "index": { "_id": "1" } }
{ "title": "Shane" }
{ "index": { "_id": "2" } }
{ "title": "Shane C" }
{ "index": { "_id": "3" } }
{ "title": "Shane P Connelly" }
{ "index": { "_id": "4" } }
{ "title": "Shane Connelly" }
{ "index": { "_id": "5" } }
{ "title": "Shane Shane Connelly Connelly" }
{ "index": { "_id": "6" } }
{ "title": "Shane Shane Shane Connelly Connelly Connelly" }
이제, 다음 작업을 할 때
GET /kr/people/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
우리는 people에서 모든 문서의 점수가 0.074107975라는 것을 볼 수 있습니다. 이것은 k1을 0으로 설정하는 것에 대한 우리의 이해와 일치합니다. 오직 검색어의 IDF만이 점수에 중요합니다!
이제 people2를 확인하겠습니다. people2는 b = 0이고 k1 = 10입니다.
GET /kr/people2/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
이 검색 결과에서 기억해 두어야 할 두 가지 사항이 있습니다.
먼저, 점수가 순수하게 "shane"이 나타나는 횟수에 따라 정렬된다는 것을 알 수 있습니다. 문서 1, 2, 3, 4는 모두 "shane"이 한 번 출현하므로 0.074107975라는 동일한 점수를 갖습니다. 문서 5는 “shane”이 두 번 출현하므로, f("shane", D5) = 2이기 때문에 더 높은 점수(0.13586462)를 가지며, 문서 6은 f("shane", D6) = 3이기 때문에 역시 더 높은 점수(0.18812023)를 갖습니다. 이것은 people2에서 b를 0으로 설정하는 우리의 직관과 일치합니다. 즉, 문서의 길이 또는 총 단어 수는 점수에 영향을 주지 않고 일치하는 단어의 수와 정확도만이 점수에 영향을 미칩니다.
두 번째로 주목해야 할 점은 이 6개의 문서를 사용하면 선형에 매우 가까운 것처럼 보이지만 이러한 점수 간의 차이는 비선형적이라는 것입니다.
- 검색어가 출현하지 않는 경우와 첫 번째 출현의 점수 차이는 0.074107975입니다
- 검색어의 두 번째 출현을 추가하는 것과 첫 번째 출현의 점수 차이는 0.13586462 - 0.074107975 = 0.061756645입니다
- 검색어의 세 번째 출현을 추가하는 것과 두 번째 출현의 점수 차이는 0.18812023 - 0.13586462 = 0.05225561입니다
0.074107975는 0.061756645에 상당히 근접하며, 0.05225561에 상당히 가깝지만, 분명히 감소하고 있습니다. 이것이 거의 선형으로 보이는 이유는 k1이 크기 때문입니다. 최소한 점수가 추가로 출현함에 따라 선형적으로 증가하지는 않는다는 것을 알 수 있습니다. 이러한 경우에는 각 추가 출현에서 동일한 차이가 발생할 것으로 예상됩니다. people3을 확인한 후에 다시 우리의 예상이 어떠한지 살펴보도록 하겠습니다.
이제 k1 = 5, b = 1인 people3을 확인해 보겠습니다.
GET /kr/people3/_search
{
"query": {
"match": {
"title": "shane"
}
}
}
다음과 같은 결과를 다시 보게 됩니다.
"hits": [
{
"_index": "people3",
"_type": "_doc",
"_id": "1",
"_score": 0.16674294,
"_source": {
"title": "Shane"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "6",
"_score": 0.10261105,
"_source": {
"title": "Shane Shane Shane Connelly Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "2",
"_score": 0.102611035,
"_source": {
"title": "Shane C"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "4",
"_score": 0.102611035,
"_source": {
"title": "Shane Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "5",
"_score": 0.102611035,
"_source": {
"title": "Shane Shane Connelly Connelly"
}
},
{
"_index": "people3",
"_type": "_doc",
"_id": "3",
"_score": 0.074107975,
"_source": {
"title": "Shane P Connelly"
}
}
]
우리는 people3에서 이제 일치하는 단어("shane")와 일치하지 않는 단어의 비율이 상대적 점수에 영향을 미치고 있는 유일한 것임을 알 수 있습니다. 따라서 단어 3개 중 일치하는 단어가 1개 뿐인 문서 3과 같은 문서들은 모두 정확히 절반의 단어들이 일치하는 2, 4, 5, 6보다 점수가 낮습니다. 그리고 그러한 모든 점수는 문서가 정확히 일치하는 문서 1의 점수보다 낮습니다.
여기서도, people2와 people3의 상위 점수 문서와 하위 점수 문서 사이에는 "큰" 차이가 있음을 알 수 있습니다. 역시 이것 또한 k1에 대한 값이 크기 때문입니다. 추가 연습으로, people2/people3을 삭제하고 k1 = 0.01과 같은 값으로 설정하면 더 적을수록 문서들 간의 점수 차이가 더 작은 것을 볼 수 있습니다. b = 0이고 k1 = 0.01인 경우,
- 검색어가 출현하지 않는 경우와 첫 번째 출현의 점수 차이는 0.074107975입니다
- 검색어의 두 번째 출현을 추가하는 것과 첫 번째 출현의 점수 차이는 0.074476674 - 0.074107975 = 0.000368699입니다
- 검색어의 세 번째 출현을 추가하는 것과 두 번째 출현의 점수 차이는 0.07460038 - 0.074476674 = 0.000123706입니다
따라서 k1 = 0.01의 경우, k1 = 5 또는 k1 = 10의 경우보다 각 추가 출현의 점수 영향이 훨씬 빨리 감소하는 것을 확인할 수 있습니다. 4번째 출현은 3번째 출현보다 점수에 훨씬 적게 추가될 것입니다. 즉, 단어 점수는 이러한 k1 값이 작을수록 훨씬 더 빨리 포화됩니다. 우리가 예상했던 대로입니다!
이렇게 하면 이러한 매개변수가 다양한 문서 집합에 어떤 영향을 미치는지 확인하는 데 도움이 될 것입니다. 이러한 지식을 바탕으로, 다음에는 적절한 b와 k1을 선택하는 방법과 Elasticsearch가 점수를 이해하고 여러분의 접근 방식을 반복하기 위한 도구를 제공하는 방법에 대해 살펴보겠습니다.
계속해서 이 시리즈의 다음 게시물인 제3부: Elasticsearch에서 b와 k1 선택 고려사항을 읽어보세요