LangChain 및 Elasticsearch를 사용한 개인정보 보호 우선 AI 검색


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
저는 지난 주말을 매력적인 "프롬프트 엔지니어링"의 세계에서 보냈습니다. 그리고 Elasticsearch®와 같은 벡터 데이터베이스가 어떻게 장기 메모리 및 시맨틱 지식 저장소 역할을 함으로써 ChatGPT와 같은 대규모 언어 모델(LLM)을 과급할 수 있는지 알게 되었습니다. 그러나, 저를(그리고 다른 많은 경험 많은 데이터 아키텍트들을) 괴롭혔던 한 가지는 현존하는 너무 많은 튜토리얼과 데모가 여러분의 프라이빗 데이터를 대형 웹 회사와 클라우드 기반 AI 회사에 보내는 것에 전적으로 의존하고 있다는 사실입니다.
프라이빗 데이터는 다양한 형태로 제공되며 한 가지 이상의 이유로 보호됩니다. 스타트업과 기업 모두 비슷하게 자사의 프라이빗 데이터가 때때로 경쟁 우위라는 것을 알고 있습니다. 내부 데이터와 고객 데이터는 종종 개인적으로 식별 가능한 정보를 가지고 있으며, 이는 보호되지 않을 경우 법인과 현실 세계의 인간 양쪽 모두에게 어떤 결과를 낳게 됩니다. Observability 및 보안 영역에서, 서드파티 서비스를 활용하는 주의 부족이 데이터 침해의 원인이 될 수 있습니다. AI 채팅 도구 사용과 관련된 사이버 보안 위반에 대한 혐의를 듣기도 했습니다.
개인 정보 보호 및 보안에 대한 강력한 약속을 한 Elastic과 같은 회사와 작업하거나 진정한 에어갭(air-gap)에 있는 배포를 할 때조차도 위험이 없거나 완전히 프라이빗한 설계는 없습니다. 그러나 저는 AI 검색을 개인 정보 보호 우선 접근 방식으로 가능하게 하는 데 대단히 실질적인 가치가 있다는 것을 알 수 있을 만큼 민감한 데이터 사용 사례를 충분히 활용하여 작업했습니다. Elasticsearch와 함께 OpenAI 도구를 사용하는 동료 Jeff Vestal의 훌륭하고 상세한 설명을 좋아하지만, 이 글에서는 다른 접근 방식을 취할 것입니다.
저는 이 프로젝트의 접근 방식에 대해 두 가지 목표를 가지고 있습니다.
- 프라이빗 - 프라이빗이라는 말은 문자 그대로입니다. 클라우드 호스트형 Elasticsearch를 사용하겠지만, 사용 사례에서 요구할 경우 완전히 물리적으로 분리된(air-gapped) 상태로 작동하기를 원합니다. 프라이빗한 지식을 서드파티에게 보내지 않고 AI 검색을 작동시킬 수 있다는 것을 증명해 봅시다.
- 재미 - 또한, 이 작업을 하는 동안 재미있는 시간이 되었으면 합니다. 우리는 데이터 과학 연습에서 인기 있는 커뮤니티 스타워즈 위키인 우키피디아(Wookieepedia)의 스크랩을 사용하고, 프라이빗 AI 트리비아 도우미를 만들 것입니다. 이 글을 쓰고 있을 때는 5월 4일이 가까워지고 있었고, 이 포스팅을 게시하는 현재는 그 날짜가 지났지만, 제 팬덤은 연중 내내 계속되고 있습니다.
따라하면서 직접 해보기 가장 쉬운 방법은 Elastic Cloud에서 Elasicsearch 인스턴스를 스핀업하고 제공된 Python 노트북을 통해 실행하여 프로젝트를 소규모로 구현하는 것입니다. 스타워즈 지식의 18만 개 단락에 대한 전체 우키피디아(Wookieepedia) 스크랩을 실행하여 정통한 스타워즈 지식 검색을 만들고 싶다면, 여기 GitHub 리포지토리에서 코드를 따라하실 수 있습니다.
모든 작업이 완료되면, 다음과 같이 표시됩니다.
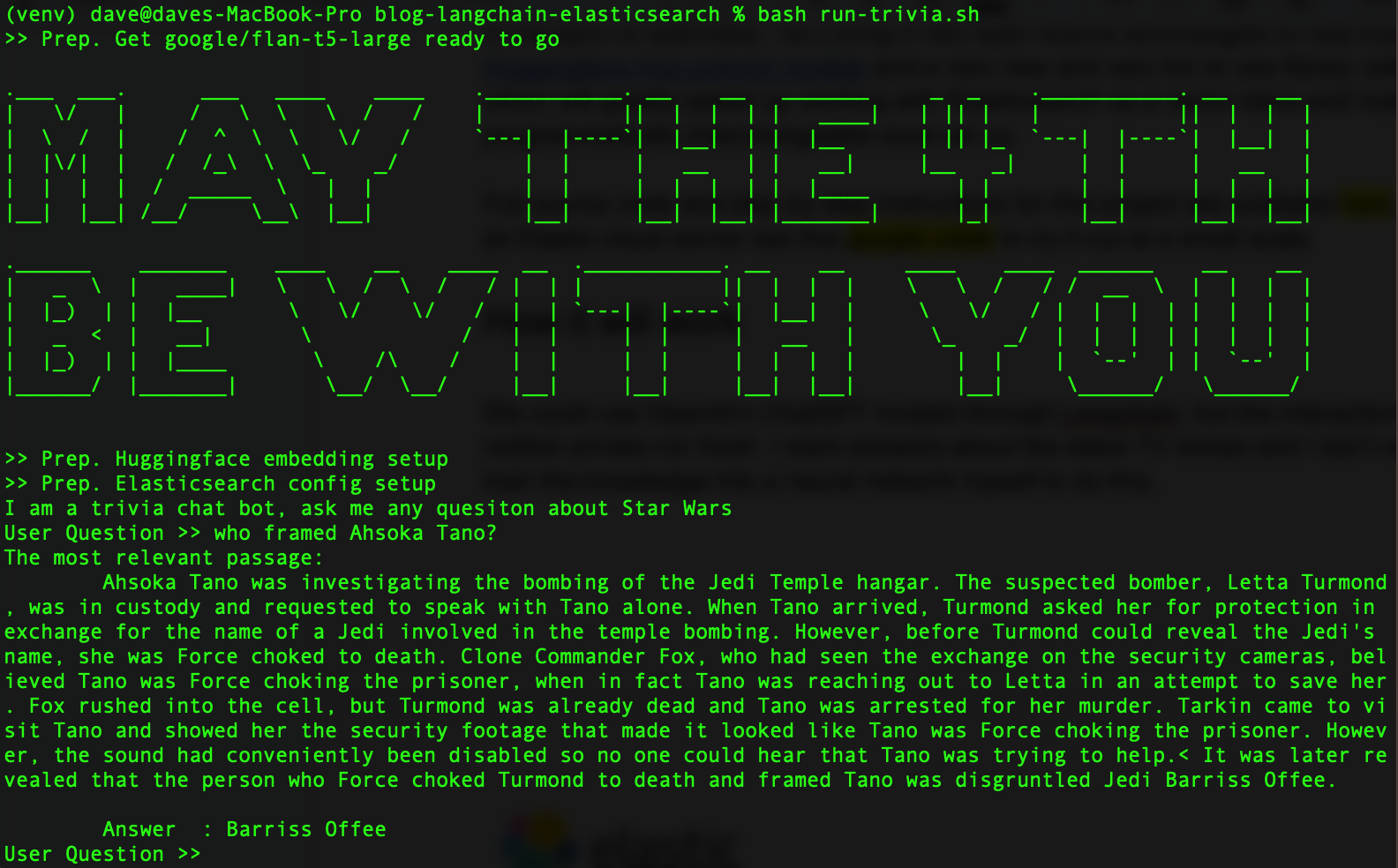
개방성의 정신으로, Elasticsearch를 돕는 두 가지 오픈 소스 기술을 도입해 봅시다. Hugging Face 트랜스포머 라이브러리와 LangChain이라는 Python 라이브러리를 사용하는 새롭고 재미있는 기술을 도입하여, Elasticsearch를 벡터 데이터베이스로 사용하는 작업을 가속화할 것입니다. 보너스로, LangChain은 일단 설정되면 LLM을 프로그래밍 방식으로 상호 교환할 수 있도록 하여 다양한 모델을 자유롭게 실험할 수 있습니다.
작동 방식
LangChain이란 무엇일까요? LangChain은 대규모 언어 모델에 의해 구동되는 애플리케이션을 개발하기 위한 Python과 JavaScript 프레임워크입니다. LangChain은 OpenAI의 API와 함께 작동할 것이지만, 또한 데이터베이스와 인공 지능 도구들 사이의 차이점들을 추상화하는 데 뛰어납니다.
그 자체로, ChatGPT는 스타워즈 트리비아에 나쁘지 않습니다. 그러나 훈련 데이터 세트는 이제 몇 년이 되었고 우리는 스타워즈 유니버스의 최신 TV 프로그램과 이벤트에 대한 답을 원합니다. 또한 우리는 이 데이터가 너무 프라이빗한 데이터여서 클라우드의 대형 LLM과 공유할 수 없는 것으로 가정하고 있음을 기억하세요. 우리는 더 최근의 데이터로 대형 언어 모델을 조정할 수 있지만, 이 작업을 수행하는 훨씬 더 쉬운 방법이 있습니다. 이를 통해 항상 이용 가능한 최신 데이터를 사용할 수 있습니다.
오늘은 더 작고 자가 호스팅하기 쉬운 LLM을 소개하겠습니다. 저는 주입된 컨텍스트에서 답변을 구문 분석할 수 있는 좋은 기능으로 훈련 부족을 보완하는 Google의 flan-t5-large 모델로 좋은 결과를 얻었습니다. 시맨틱 검색을 사용하여 우리의 프라이빗 지식을 검색한 다음 해당 컨텍스트를 개인 LLM에 질문과 함께 주입하겠습니다.
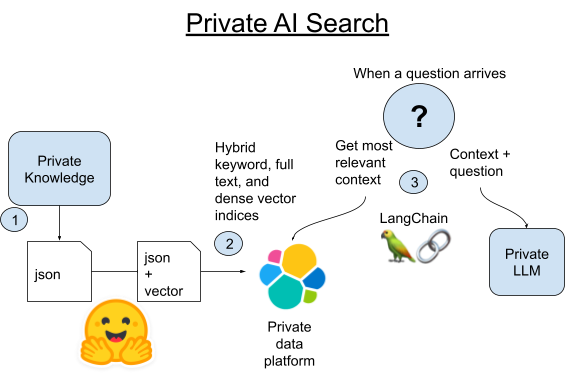
1. 우키피디아(Wookieepedia)에서 모든 캐논 기사를 스크랩하여 데이터를 단계별 Python Pickle 파일에 저장합니다.
2A. LangChain의 기본 제공 Vectorstore 라이브러리를 사용하여 해당 기사의 각 단락을 Elasticsearch에 로드합니다.
2B. 또는 LangChain을 Elasticsearch 자체에서 pytorch 트랜스포머를 호스팅하는 새로운 방법과 비교할 수 있습니다. 텍스트 임베딩 모델을 Elasticsearch에 배포하여 분산 컴퓨팅을 활용하고 프로세스 속도를 높일 것입니다.
3. 질문이 들어오면, Elasticsearch의 벡터 검색을 사용하여 질문과 의미론적으로 가장 유사한 단락을 찾게 됩니다. 그리고 나서 해당 단락을 질문에 대한 컨텍스트로서 작은 로컬 LLM의 프롬프트에 추가한 다음 이를 생성형 AI의 마법에 맡겨 트리비아 질문에 대한 짧은 답을 얻게 됩니다.
Python 및 Elasticsearch 환경 설정
컴퓨터에 Python 3.9 또는 유사한 것이 있는지 확인하세요. 저는 GPU 가속과의 더 쉬운 라이브러리 호환을 위해 3.9를 사용하지만, 이 프로젝트에는 필요하지 않습니다. Python의 최근 3.X 버전은 모두 작동합니다.
python3 -m venv venv
source venv/bin/activate
pip install --upgrade pip
pip install beautifulsoup4 eland elasticsearch huggingface-hub langchain tqdm torch requests sentence_transformers샘플 코드를 다운로드했다면, 다음 pip install 명령을 사용하여 제가 사용하던 코드의 정확한 버전을 끌어오기만 하면 됩니다.
pip install -r requirements.txt여기의 지침에 따라 Elasticsearch 클러스터를 설정할 수 있습니다. 무료 클라우드 체험판은 가장 쉽게 시작할 수 있는 방법입니다.
폴더에 .env 파일을 만들고 Elasticsearch를 위해 연결 세부 정보를 로드합니다.
export ES_SERVER="YOURDESSERVERNAME.es.us-central1.gcp.cloud.es.io"
export ES_USERNAME="YOUR READ WRITE AND INDEX CREATING USER"
export ES_PASSWORD="YOUR PASSWORD"1단계. 데이터 스크래핑
코드 리포지토리에는 Dataset/starwars_small_sample_data.pickle에 작은 데이터 세트가 있습니다. 작은 규모로 작업해도 괜찮으면 이 단계를 건너뛸 수 있습니다.
스크래핑 코드는 Dennis Bakhuis의 훌륭한 데이터 과학 블로그와 프로젝트에서 가져온 것입니다. 확인해 보세요! Dennis는 각 기사의 첫 단락만 가져오고, 저는 모든 것을 가져오기 위해 코드를 바꿨습니다. Dennis는 기본 메모리에 맞는 크기로 데이터를 유지해야 했을지도 모르지만, 우리는 이것을 페타바이트 범위로 잘 확장할 수 있는 Elasticsearch가 있기 때문에 그런 문제는 없습니다.
또한 여기에서 프라이빗 데이터 소스를 매우 쉽게 연결할 수 있습니다. LangChain에는 더 짧은 단위로 텍스트 데이터를 분할할 수 있는 몇 가지 우수한 유틸리티 라이브러리가 있습니다.
스크래핑은 이 글에서 중점을 두는 부분이 아닙니다. 소규모로 직접 실행하거나 소스 코드를 다운로드하여 다음과 같이 실행하려면 Python 노트북을 확인하세요.
source .env
python3 step-1A-scrape-urls.py
python3 step-1B-scrape-content.py
작업을 마치면, 이렇게 저장된 Pickle 파일을 살펴서 작동하는지 확인할 수 있습니다.
from pathlib import Path
import pickle
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for key, value in part.items():
title = value['title'].strip()
print(title)웹 스크래핑을 건너뛴 경우에는, bookFilePath를 "starwars_small_sample_data.pickle"로 변경하면 GitHub 리포지토리에 포함된 샘플을 사용할 수 있습니다.
2A단계. Elasticsearch에서 임베딩 로드
전체 코드는 제가 LangChain만으로 이 작업을 하는 방법을 보여줍니다. 코드의 핵심 부분은 위 예와 같이 저장된 Pickle 파일을 통해 루프하여 단락인 스트링 목록을 추출한 다음, 이를 LangChain Vectorstore의 from_texts() 함수에 전달하는 것입니다.
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
from pathlib import Path
import pickle
import os
from tqdm import tqdm
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
index_name = "book_wookieepedia_mpnet"
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
batchtext = []
bookFilePath = "starwars_*_data*.pickle"
files = sorted(Path('./Dataset').glob(bookFilePath))
for fn in files:
with open(fn,'rb') as f:
part = pickle.load(f)
for ix, (key, value) in tqdm(enumerate(part.items()), total=len(part)):
paragraphs = value['paragraph']
for p in paragraphs:
batchtext.append(p)
db.from_texts(batchtext,
embedding=hf,
elasticsearch_url=url,
index_name=index_name)
2B단계. Hosted Trained Model로 시간과 비용 절약
이전의 인텔 맥북에서 임베딩을 만드는 데 처리 시간이 아주 오래 걸린다는 사실을 알았습니다. 완곡하게 표현했는데, 사실 여러 날이 걸리는 작업이었습니다. Elastic의 호스트형 서비스의 동적으로 확장 가능한 머신 러닝(ML) 노드를 사용하면 더 적은 비용으로 더 빠르게 이 작업을 할 수 있다고 생각합니다. 무료 체험판 클러스터에서는 해당 계층을 확장할 수 없으므로, 이 단계는 어떤 분들께는 보다 합리적일 수 있습니다.
최종 결과: 이 접근 방식은 Elastic Cloud에서 실행하는 데 시간당 $5의 비용이 드는 노드에서 40분이 걸렸는데, 이는 로컬에서 수행할 수 있는 것보다 훨씬 빠르며 OpenAI의 현재 토큰 요금으로 임베딩을 처리하는 비용과 동등합니다. 이 작업을 효율적으로 수행하는 것은 더 큰 주제이지만, 새로운 기술을 배우거나 데이터를 프라이빗이 아닌 API로 전달할 필요 없이 Elastic Cloud에서 병렬 유추 파이프라인을 얼마나 빨리 작동시킬 수 있는지에 대해 감명을 받았습니다.
이 단계에서는, 임베딩 생성을 Elasticsearch 클러스터 자체로 오프로드하려고 합니다. 이를 통해 임베딩 모델을 호스팅하고 텍스트 단락을 분산 방식으로 임베딩할 수 있습니다. 이를 위해서는, 데이터를 로드하고 수집 파이프라인을 사용하여 최종 형식이 LangChain이 사용하는 인덱스 매핑과 일치하는지 확인해야 합니다. Kibana의 Dev Tools에서 다음 REST 명령을 실행합니다.
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
다음으로, 임베딩 모델을 eland Python 라이브러리를 이용하여 Elasticsearch에 업로드하겠습니다.
source .env
python3 step-3A-upload-model.py다음으로는 Elastic Cloud 콘솔로 이동하여 머신 러닝 계층을 총 vCPU 64개(현재 노트북의 8배)로 확장해 보겠습니다.
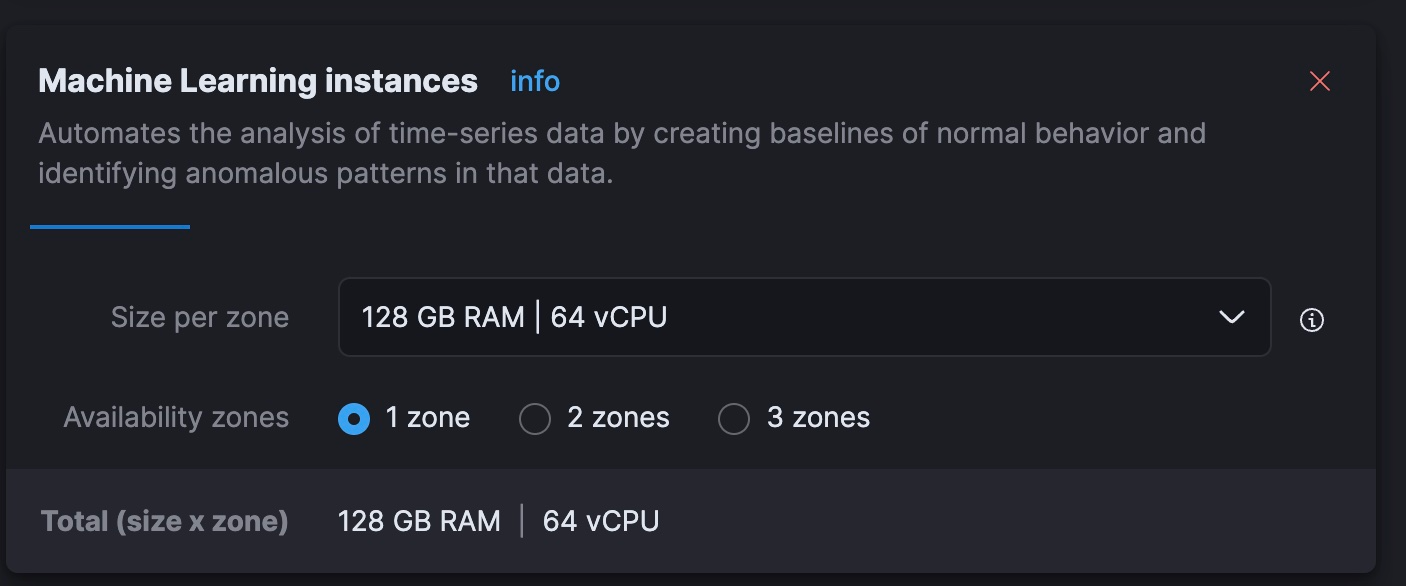
이제 Kibana에서 훈련된 머신 러닝 모델을 배포하겠습니다. 규모에 맞게, 성능 테스트에서 사용자는 모델 할당당 1개의 스레드로 시작하고 할당 수를 늘려 처리량을 높여야 하는 것으로 나타났습니다. 설명서 및 지침은 여기에서 찾아보실 수 있습니다. 제가 실험했는데, 이보다 작은 집합의 경우 각각 2개의 스레드에서 32개의 인스턴스로 가장 좋은 결과를 얻었습니다. 이를 설정하려면, 스택 관리 > 머신 러닝으로 이동하세요. 저장된 개체 동기화 기능을 사용하여 Kibana에서 Python 코드로 Elasticsearch에 입력한 모델을 볼 수 있도록 합니다. 그런 다음 이를 클릭하면 나타나는 메뉴에 모델을 배포합니다.

이제 Dev Tools를 다시 사용하여 문서에서 텍스트 단락을 처리하고 결과를 "벡터"라는 밀집 벡터 필드에 넣고, 단락을 예상되는 "텍스트" 필드에 복사하는 새 인덱스를 만들고 파이프라인을 수집합니다.
PUT /book_wookieepedia_mpnet
{
"settings": {
"number_of_shards": 4
},
"mappings": {
"properties": {
"metadata": {
"type": "object"
},
"text": {
"type": "text"
},
"vector": {
"type": "dense_vector",
"dims": 768
}
}
}
}
PUT _ingest/pipeline/sw-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__all-mpnet-base-v2",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
},
{
"set":{
"field": "vector",
"copy_from": "text_embedding.predicted_value"
}
},
{
"remove": {
"field": "text_embedding"
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
파이프라인이 작동하는지 테스트합니다.
POST _ingest/pipeline/sw-embeddings/_simulate
{
"docs": [
{
"_source": {
"text": "Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.",
"metadata": {
"a": "b"
}
}
}
]
}
이제 Elasticsearch를 위한 일반적인 Python 라이브러리를 사용하여 데이터를 일괄 로드할 준비가 되었으며, 수집 파이프라인을 대상으로 벡터 임베딩을 올바르게 생성하여 LangChain의 기대에 맞게 데이터를 변환할 수 있습니다.
source .env
python3 step-3B-batch-hosted-vectorize.py성공! 데이터는 OpenAI 기준으로 약 1,300만 개의 토큰이므로, OpenAI 또는 이에 준하는 클라우드 서비스에서 이러한 벡터를 생성하는 데 약 5.40달러가 소요됩니다. Elastic Cloud를 사용하면, 시간당 5달러의 비용이 드는 기계가 40분이 걸렸습니다.
데이터를 로드한 상태에서, 클라우드 콘솔을 사용하여 클라우드 머신 러닝을 0 또는 더 합리적인 수준으로 다시 축소해야 합니다.
3단계. 스타워즈 트리비아에서 승리하기
다음으로 LLM과 LangChain을 가지고 놀아 보겠습니다. 저는 이 코드를 유지하기 위해 라이브러리 파일 lib_llm.py를 만들었습니다.
from langchain import PromptTemplate, HuggingFaceHub, LLMChain
from langchain.llms import HuggingFacePipeline
from transformers import AutoTokenizer, pipeline, AutoModelForSeq2SeqLM
from langchain.vectorstores import ElasticVectorSearch
from langchain.embeddings import HuggingFaceEmbeddings
import os
cache_dir = "./cache"
def getFlanLarge():
model_id = 'google/flan-t5-large'
print(f">> Prep. Get {model_id} ready to go")
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(model_id, cache_dir=cache_dir)
pipe = pipeline(
"text2text-generation",
model=model,
tokenizer=tokenizer,
max_length=100
)
llm = HuggingFacePipeline(pipeline=pipe)
return llm
local_llm = getFlanLarge()
def make_the_llm():
template_informed = """
I am a helpful AI that answers questions.
When I don't know the answer I say I don't know.
I know context: {context}
when asked: {question}
my response using only information in the context is: """
prompt_informed = PromptTemplate(
template=template_informed,
input_variables=["context", "question"])
return LLMChain(prompt=prompt_informed, llm=local_llm)
## continued below
template_informed는 중요하지만 이해하기 쉬운 부분이기도 합니다. 우리가 하고 있는 작업은 컨텍스트와 사용자의 질문이라는 두 매개 변수를 취할 prompt template을 포맷하는 것입니다.
위에서 이 마지막 메인 코드를 계속 사용하면, 다음과 같습니다.
## continued from above
topic = "Star Wars"
index_name = "book_wookieepedia_mpnet"
# Create the HuggingFace Transformer like before
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
## Elasticsearch as a vector db, just like before
endpoint = os.getenv('ES_SERVER', 'ERROR')
username = os.getenv('ES_USERNAME', 'ERROR')
password = os.getenv('ES_PASSWORD', 'ERROR')
url = f"https://{username}:{password}@{endpoint}:443"
db = ElasticVectorSearch(embedding=hf, elasticsearch_url=url, index_name=index_name)
## set up the conversational LLM
llm_chain_informed= make_the_llm()
def ask_a_question(question):
## get the relevant chunk from Elasticsearch for a question
similar_docs = db.similarity_search(question)
print(f'The most relevant passage: \n\t{similar_docs[0].page_content}')
informed_context= similar_docs[0].page_content
informed_response = llm_chain_informed.run(
context=informed_context,
question=question)
return informed_response
# The conversational loop
print(f'I am a trivia chat bot, ask me any question about {topic}')
while True:
command = input("User Question >> ")
response= ask_a_question(command)
print(f"\tAnswer : {response}")
결론
그래서 약간의 데이터 랭글링으로, 우리는 이제 서드파티가 호스트하는 LLM에 우리의 데이터를 노출시키지 않고 AI를 사용했습니다. AI의 세계는 빠르게 변하고 있지만, 프라이빗 데이터의 보안과 통제를 보존하는 것은 우리 모두가 데이터 침해의 규제, 재정 및 인간적인 결과를 위해 심각하게 받아들여야 하는 사항입니다. 그것은 바뀔 것 같지 않습니다. 우리는 사기를 조사하고, 자국을 방어하고, 취약한 환자 커뮤니티의 결과를 개선하기 위해 검색을 사용하는 고객과 협력합니다. 개인 정보 보호는 중요합니다. 이러한 공간에서 Elastic이 어떻게 사용되는지에 대해 더 알고 싶으시면, 다음을 확인해 보세요.
여러분도 저만큼 LangChain과 사랑에 빠지셨나요? 현명한 늙은 제다이가 한때 말했듯이, "잘하셨어요. 더 큰 세상으로 나갈 첫 걸음을 내딛으셨습니다." 여기서 여러 가지 방향으로 나아가실 수 있습니다. LangChain은 AI 프롬프트 엔지니어링과의 작업에서 복잡함을 없애줍니다. 저는 Elasticsearch가 생성형 AI를 위한 장기 메모리로서 여기서 수행해야 할 다른 많은 역할이 있다는 것을 알고 있기 때문에, 빠르게 변화하는 이 공간에서 무엇이 밝혀지는지 볼 수 있어서 매우 기쁩니다.
이 블로그 포스팅에서, Elastic은 각 소유자가 소유하고 운영하는 서드파티 생성형 AI 도구를 사용했을 수 있습니다. Elastic은 서드파티 도구에 대한 어떠한 통제권도 없으며 당사는 그 내용, 작동 또는 사용에 대한 책임이나 법적 의무가 없고 이러한 도구의 사용으로 인해 발생할 수 있는 손실 또는 손상에 대해 책임을 지지 않습니다. 개인 정보, 민감한 정보 또는 기밀 정보와 함께 AI 도구를 사용할 때 주의하세요. 제출하신 모든 데이터는 AI 교육을 위해 또는 다른 목적으로 사용될 수 있습니다. 제공하시는 정보가 안전하게 유지되거나 기밀로 유지된다는 보장은 없습니다. 사용 전에 생성형 AI 도구의 개인 정보 보호 관행 및 사용 약관을 숙지하셔야 합니다.
Elastic, Elasticsearch 및 관련 상표는 미국 및 기타 국가에서 Elasticsearch N.V.의 상표, 로고 또는 등록 상표입니다. 기타 모든 회사 및 제품 이름은 해당 소유자의 상표, 로고 또는 등록 상표입니다.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기

