

Elasticsearch: Build an AI-powered search experience
Overview
Introduction to Elasticsearch
As you ramp up on Elastic, you’ll use the Elasticsearch Relevance Engine™ (ESRE), designed to power AI search applications. With ESRE, you can take advantage of a suite of developer tools including Elastic’s textual search, vector database, and our proprietary transformer model for semantic search.
Elastic offers a variety of search techniques, starting with BM25, the industry standard for textual search. It provides precise matching for specific searches, matching exact keywords, and it improves with tuning.
As you get started on vector search, keep in mind there are two forms of vector search: “dense” (aka, kNN vector search) and “sparse."
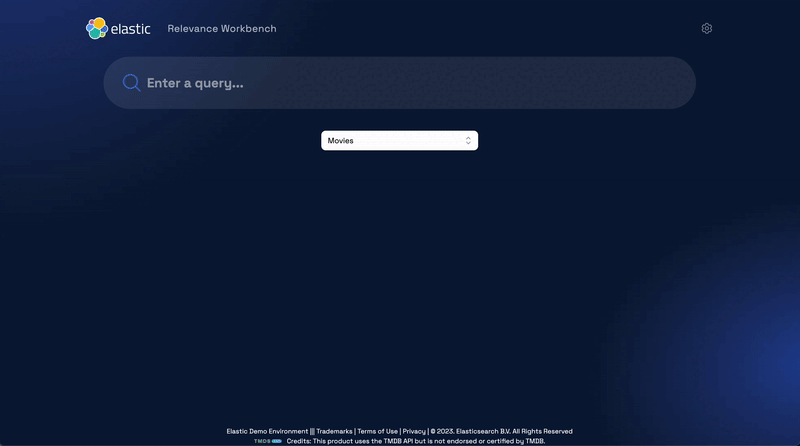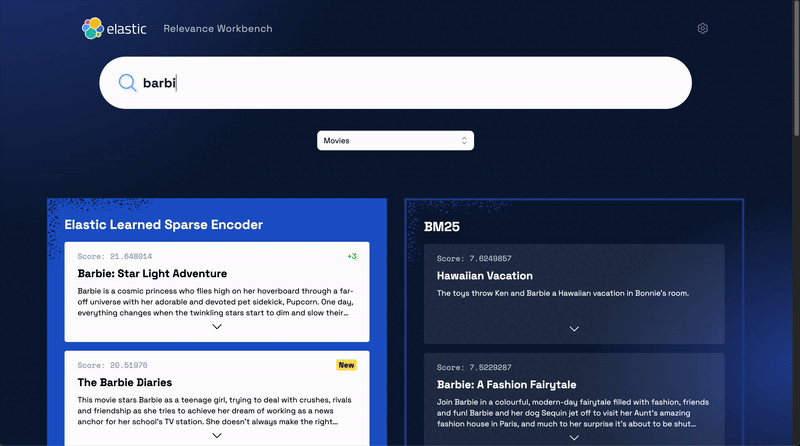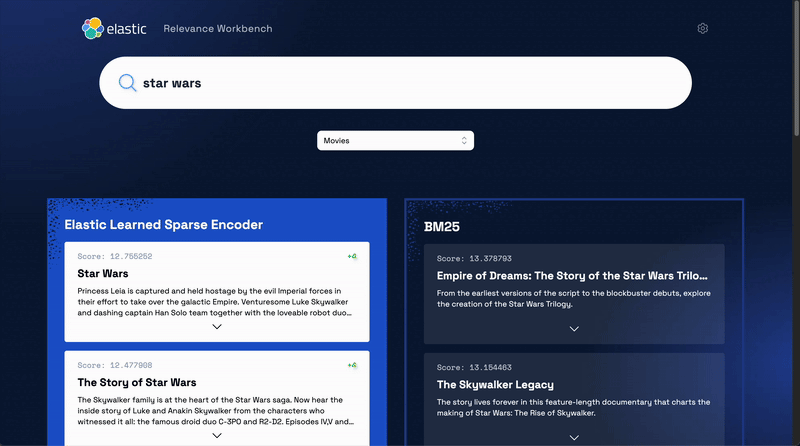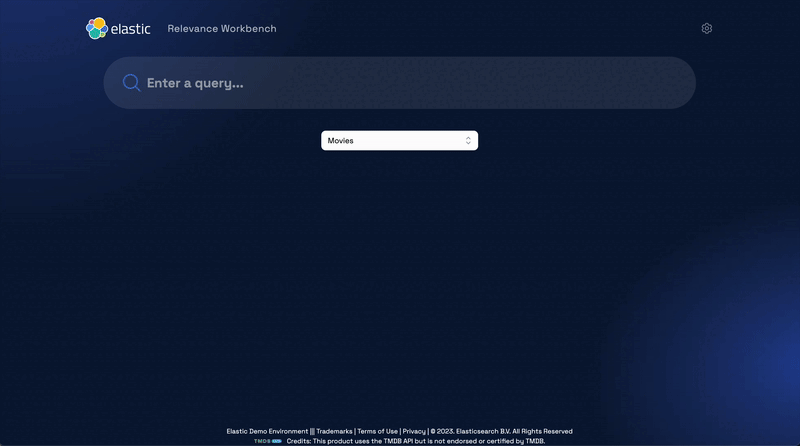
Elastic also offers an out-of-the-box the Learned Sparse Encoder model for semantic search. This model outperforms on a variety of datasets, such as financial data, weather records, question-answer pairs, among others. The model is built to provide great relevance across domains, without the need for additional fine tuning.
Check out this interactive demo to see how search results are more relevant when you test Elastic's Learned Sparse Encoder model against Elastic’s textual BM25 algorithm.
In addition, Elastic also supports dense vectors to implement similarity search on unstructured data beyond text, such as videos, images, and audio.
The advantage of semantic search and vector search is that these technologies allow customers to use intuitive language in their search queries. For example, if you wanted to search for workplace guidelines on a second income, you could search for "side hustle", which is not a term you're likely to see in a formal HR document.
In this guide, we'll demonstrate how to create an Elastic Cloud account, ingest data with the Elastic web crawler, and implement semantic search in just a few clicks.
Let's get started
Create an Elastic Cloud project
Get started with a 14-day trial. Once you go to cloud.elastic.co and create an account, follow the steps below to learn how to launch your first Elasticsearch Serverless project.
In this example, you will onboard a live website, the Elasticsearch Labs https://www.elastic.co/search-labs.
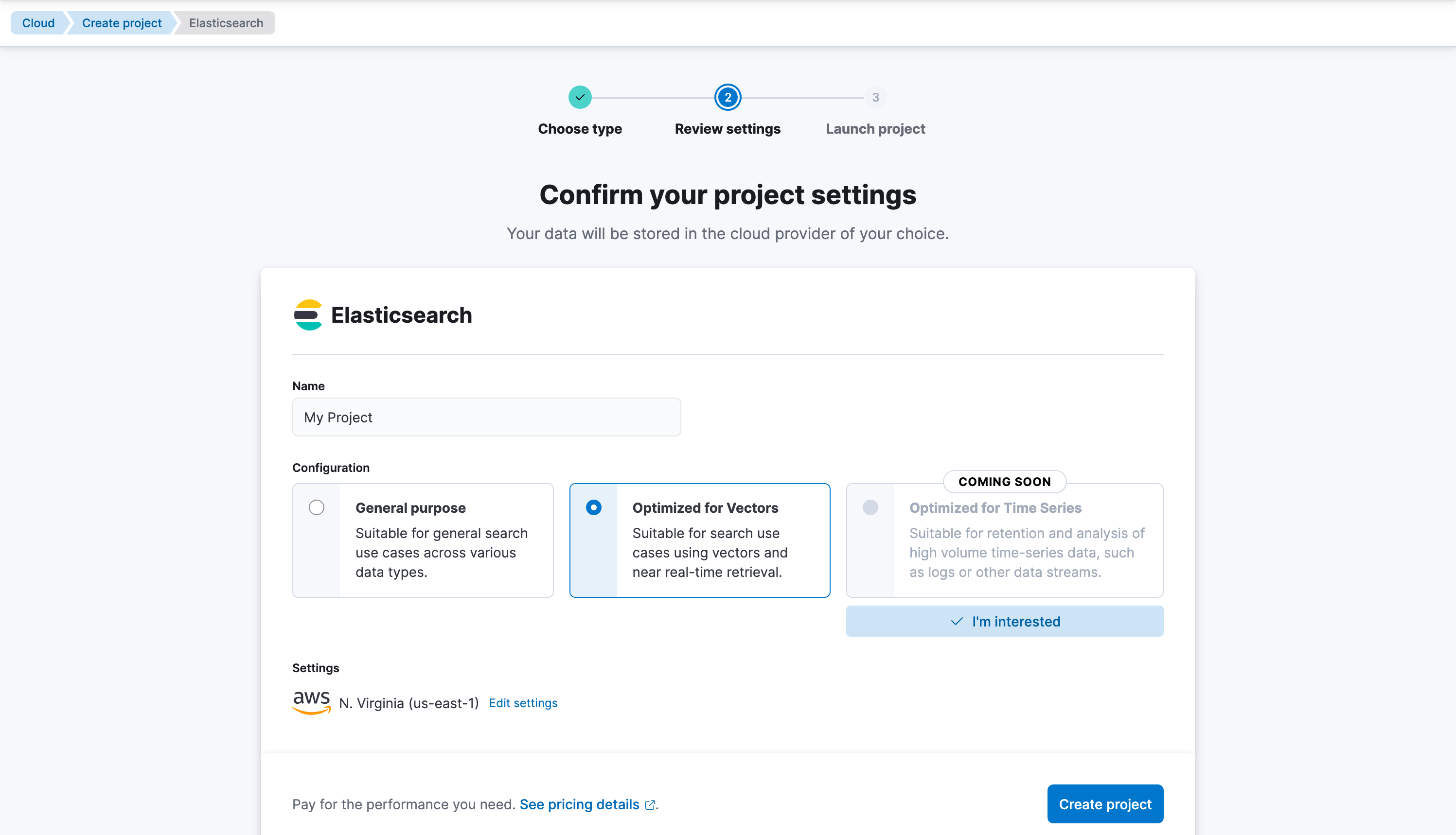
Select Create Project. Let’s create a Serverless project that is Optimized for Vectors, give it a name and create it.
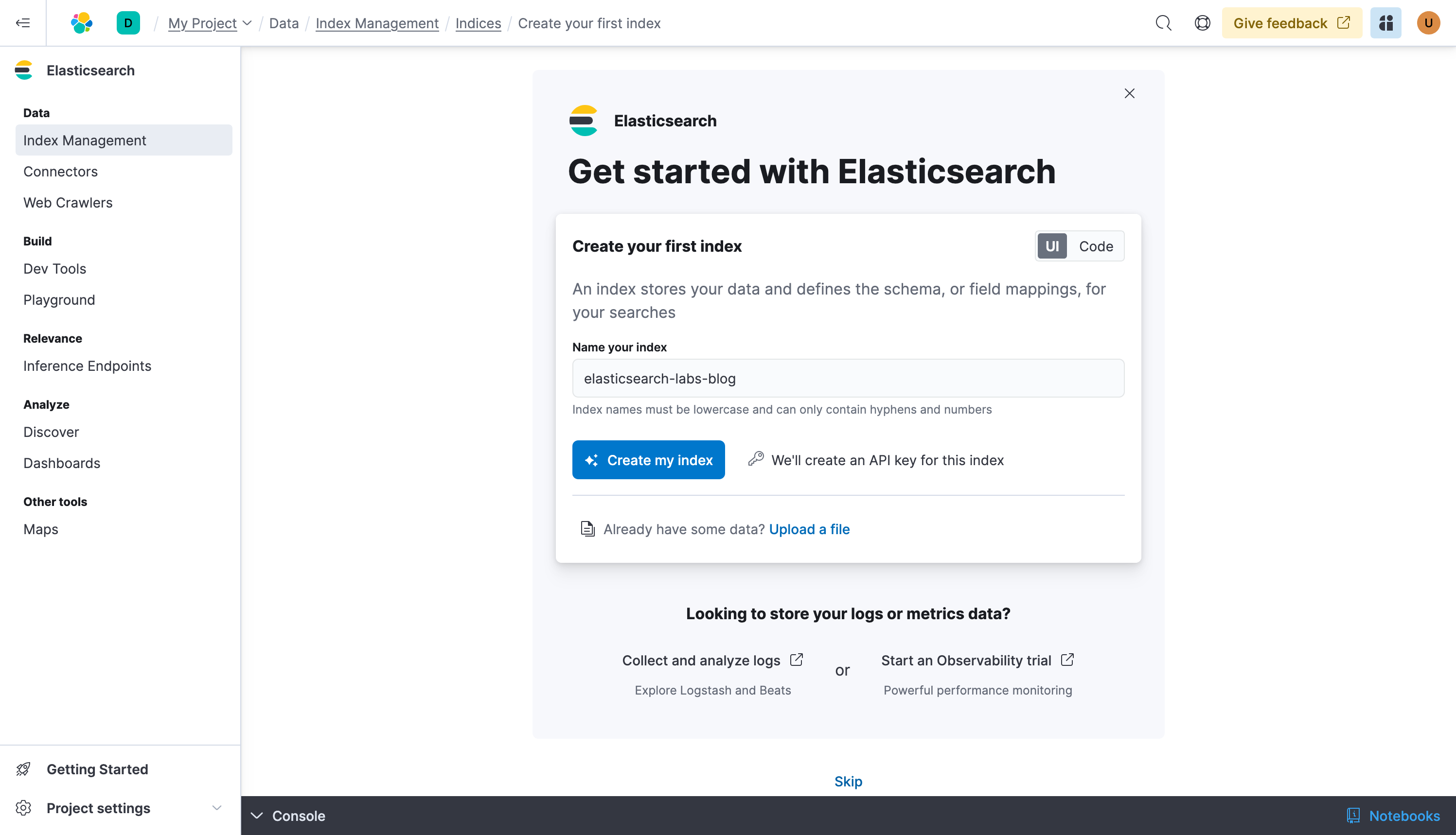
Let’s create our first Elasticsearch index, you can name it elasticsearch-labs-blog. Select Create my index.
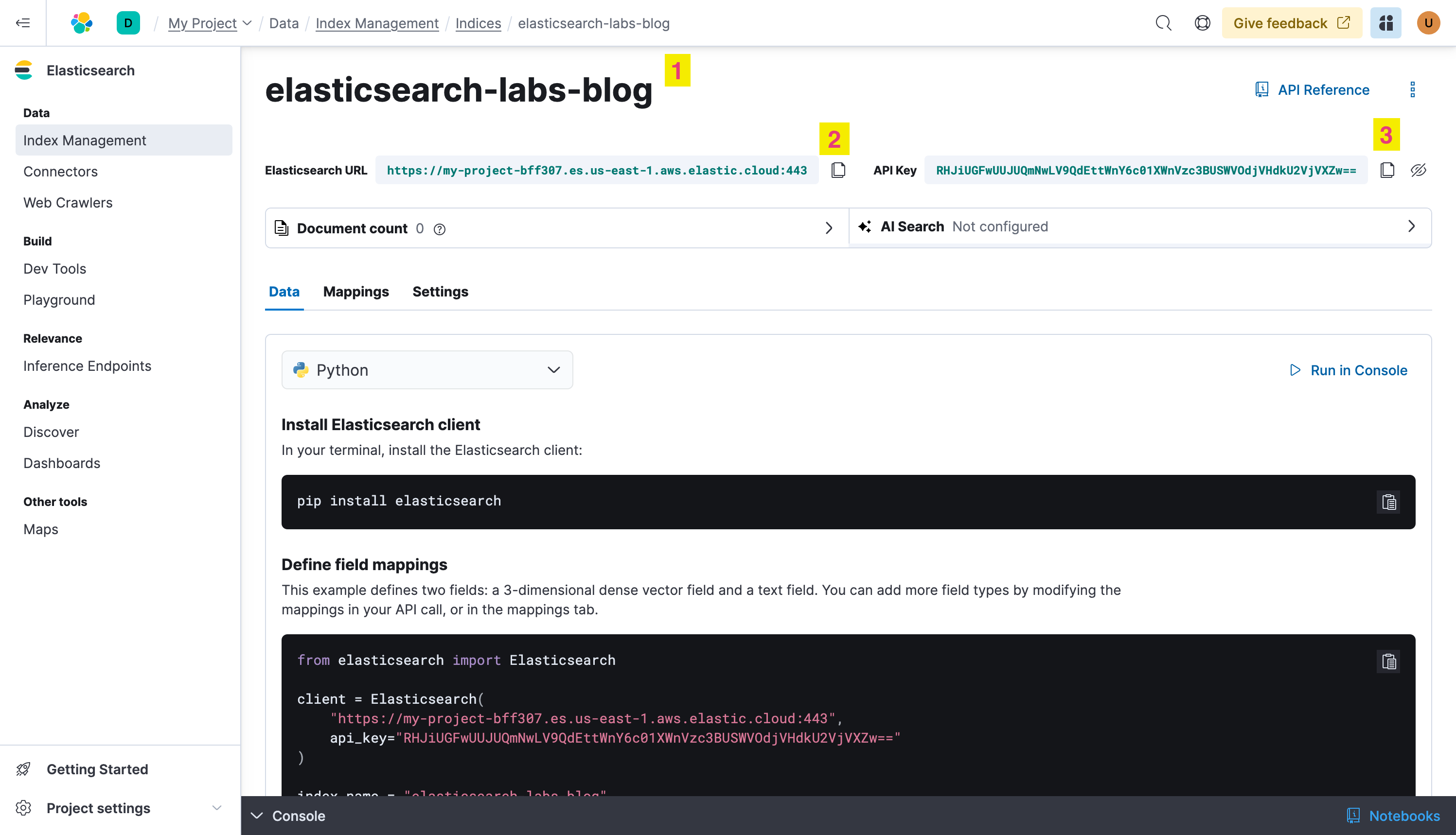
Your index is created, you have now the three things you need:
- The index: our data store
- The Elasticsearch URL: the endpoint to which you will send your data
- The API Key: the easiest of the authentication methods
Now before writing data to the index, let’s do a small configuration to ensure you have Semantic Search right from the start. Click on Mappings and + Add field, create a Text field called body, this is where the crawler will put the content of the web pages it reads.
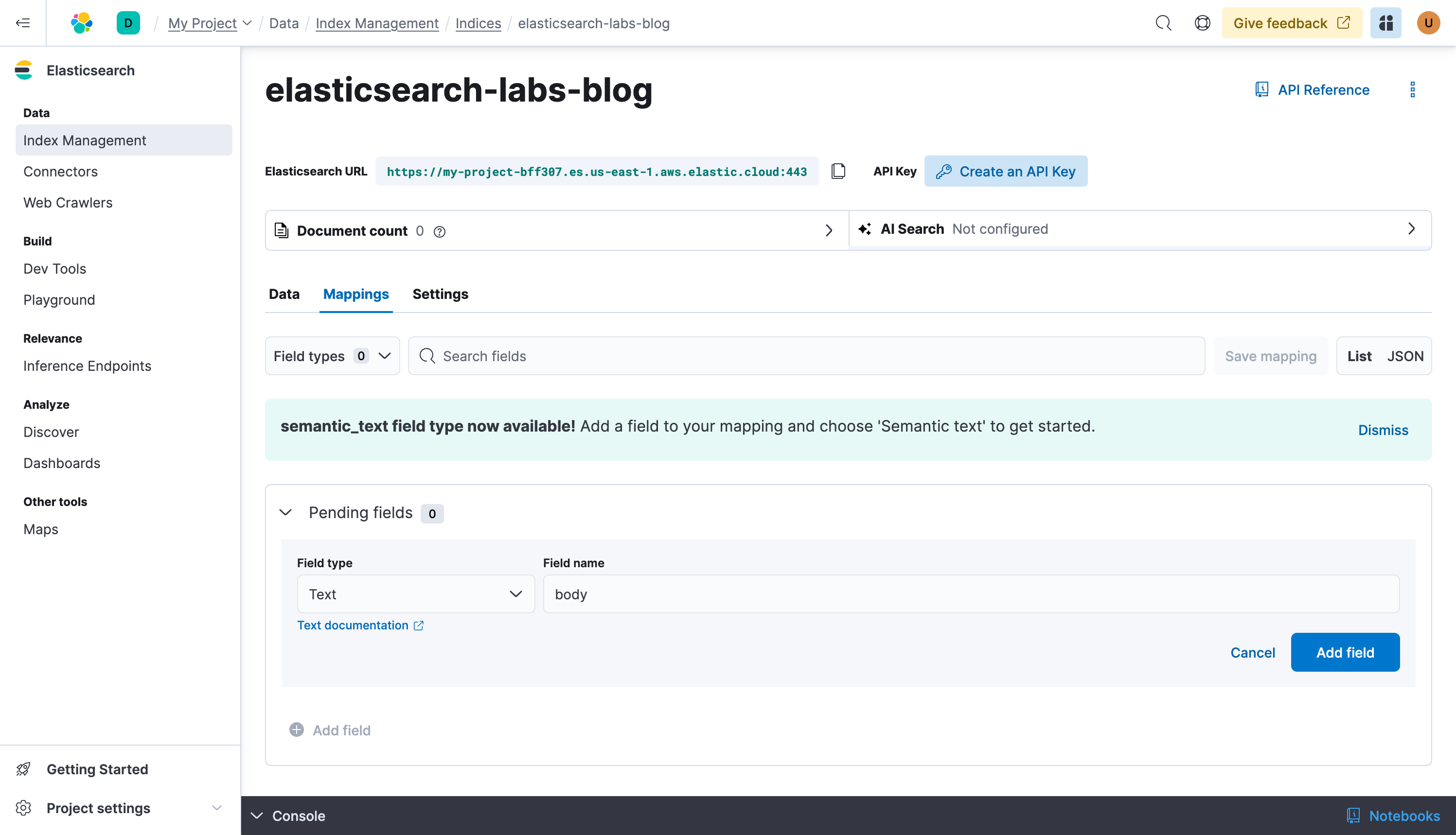
Next, add a Semantic Text type field, let’s give it a very creative name: semantic_text
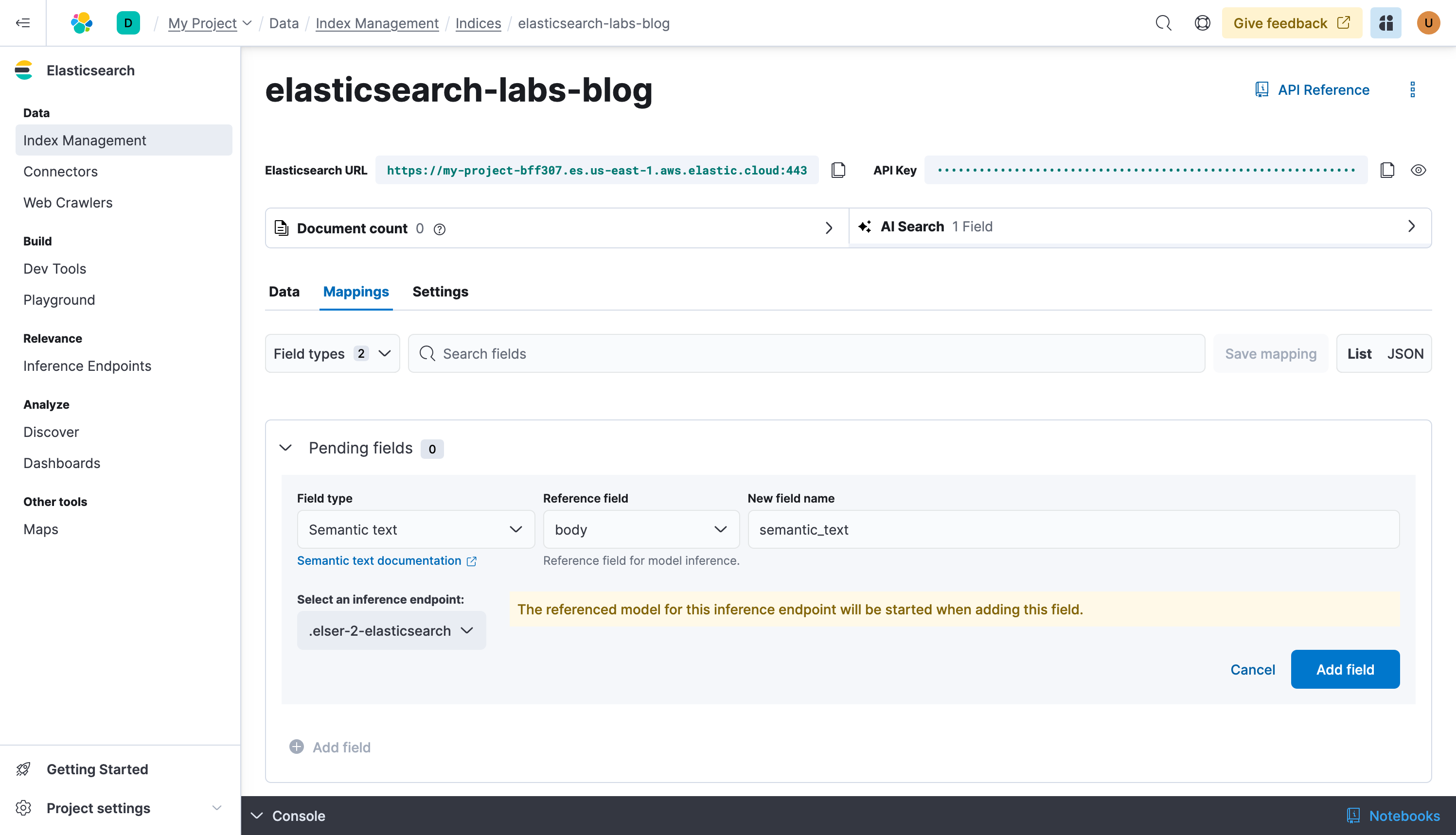
Let’s write data to it.
Configure the Elastic Open Web Crawler
You will need Docker to use the Open Web Crawler.
Here is a simple config file, it tells the crawler to read the https://www.elastic.co/search-labs blog and write it to the elasticsearch-labs-blog index at elasticsearch.host using the elasticsearch.api_key
Copy the following content to a file and call it crawler-config-blog.yml, change host and api_key accordingly:
domains:
- url: https://www.elastic.co
seed_urls:
- https://www.elastic.co/search-labs/blog
crawl_rules:
- policy: allow
type: begins
pattern: /search-labs/blog
- policy: deny
type: regex
pattern: .*
elasticsearch:
host: https://my-project-bff307.es.us-east-1.aws.elastic.cloud
api_key: RHJiUGFwUUJUQmNwLV9QdEttWnY6c01XWnVzc3BUSWVOdjVHdkU2VjVXZw==
pipeline_enabled: false
Now create a docker-compose.yml file
services:
crawler:
image: docker.elastic.co/integrations/crawler:latest
volumes:
- ./config:/app/config
stdin_open: true
tty: true
and start the service with:
docker-compose up -d
Now you are ready to start the crawling process:
docker-compose exec -it crawler bin/crawler crawl
crawler-config-blog.yml
After a few minutes you should have the whole Elasticsearch labs blogs indexed.
What just happened?
The blog content was indexed to the body field, then this content was transformed into a sparse vector inside the semantic_text field. This transformation involved two main steps. First, the content was divided into smaller, manageable chunks to ensure that the text is broken down into meaningful segments, which can be more effectively processed and searched. Next, each chunk of text was transformed into a sparse vector representation using text expansion techniques. This step leverages ELSER (Elastic Search Engine for Relevance) to convert the text into a format that captures the semantic meaning, enabling more accurate and relevant search results.
By indexing both the text field and the semantic_text field into Elasticsearch, the process combines the strengths of traditional keyword search and advanced semantic search. This hybrid search provides comprehensive search capabilities, ensuring that users can find relevant information based on both the raw text and its underlying meaning.
Working with Elasticsearch
Testing search queries
Now it’s time to search for the information you’re looking for. If you’re a developer who’s implementing search (i.e., for your web application) you should use the Console/Dev Tools to test and refine search results from your indexed data.
Let’s start with a simple multi_match query, which will match the text against the “title” and “body” fields. Since this is a classic lexical search (not semantic yet) the results of a query like “how to implement multilingual search” will match the words you are providing.
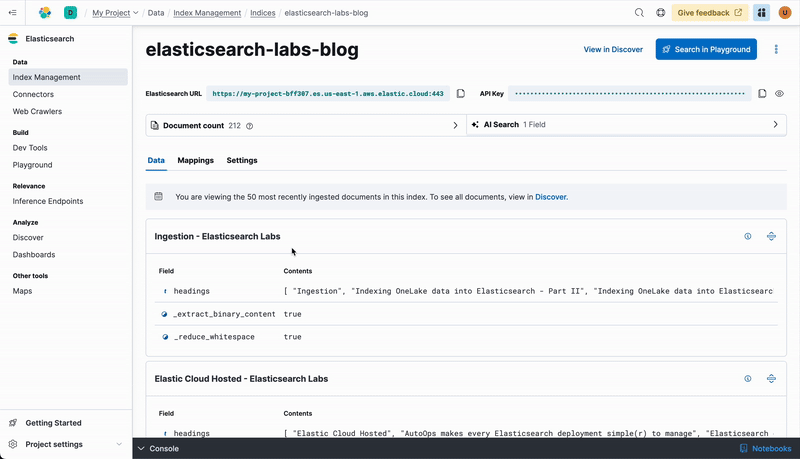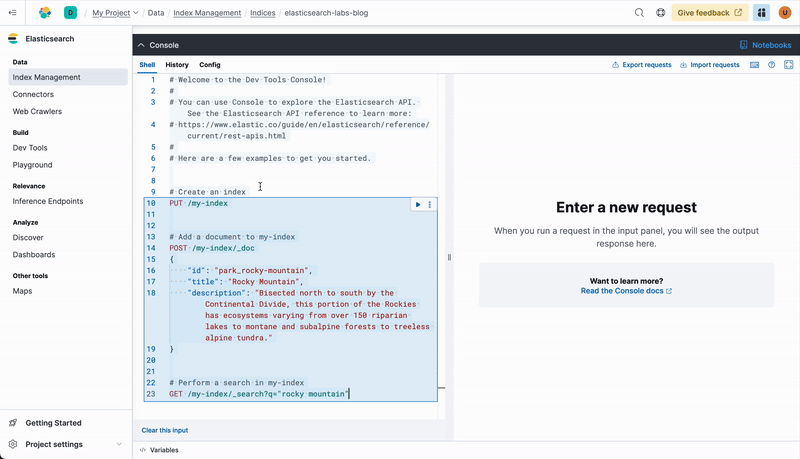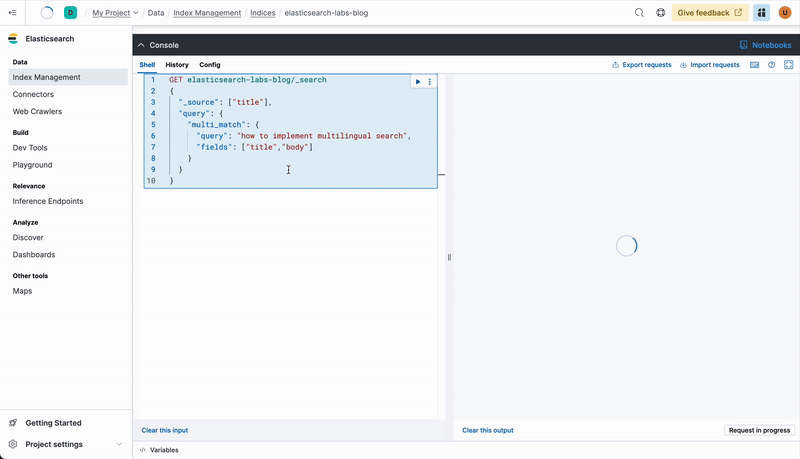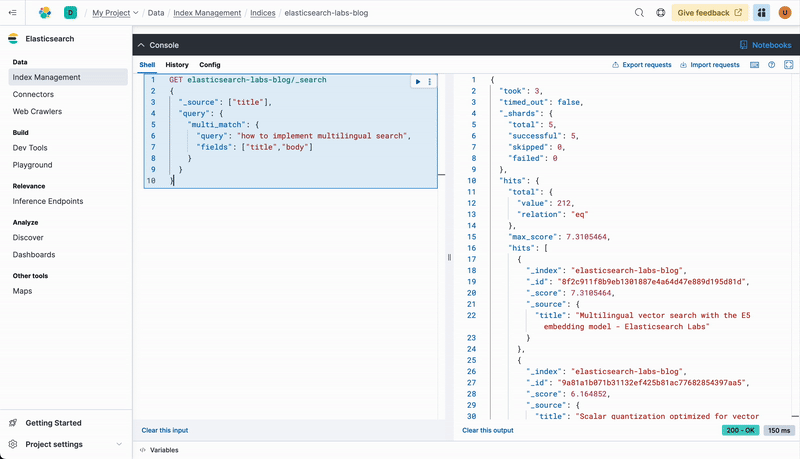
GET elasticsearch-labs-blog/_search
{
"_source": ["title"],
"query": {
"multi_match": {
"query": "how to implement multilingual search",
"fields": ["title","body"]
}
}
}
In this case the top 5 matches are good, but not great.
"Multilingual vector search with the E5 embedding model"
"Scalar quantization optimized for vector databases"
"How to migrate your Ruby app from OpenSearch to Elasticsearch"
"How to search languages with compound words"
"How To"
Create a semantic search query
Now try the same but with a semantic query, it will translate the text “how to implement multilingual search?” automatically into a vector representation and perform the query against the semantic_text field.
GET elasticsearch-labs-blog/_search
{
"_source": ["title"],
"query": {
"semantic": {
"field": "semantic_text",
"query": "how to implement multilingual search?"
}
}
}
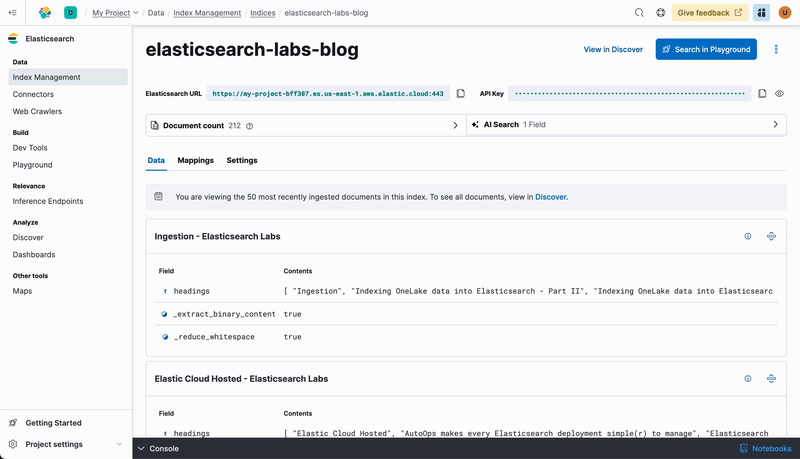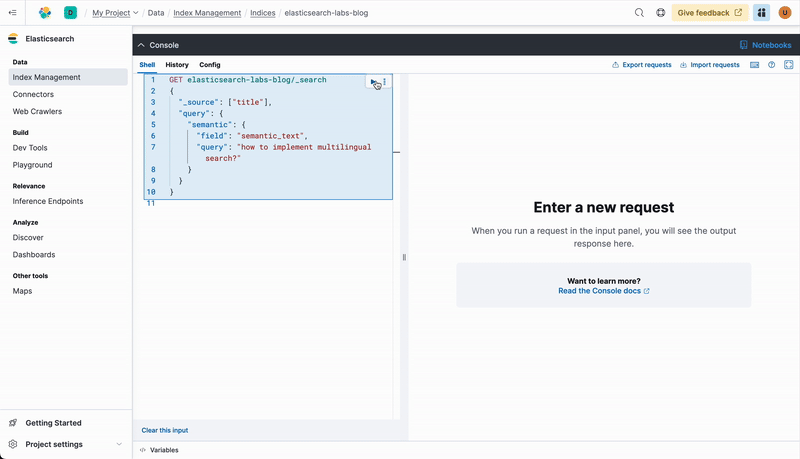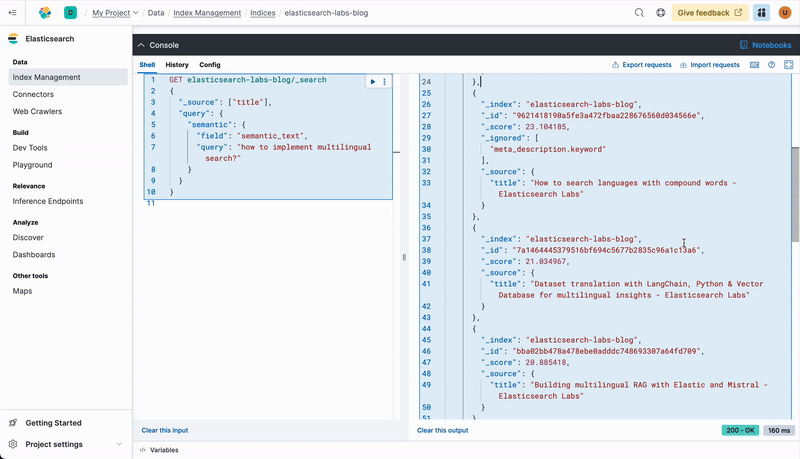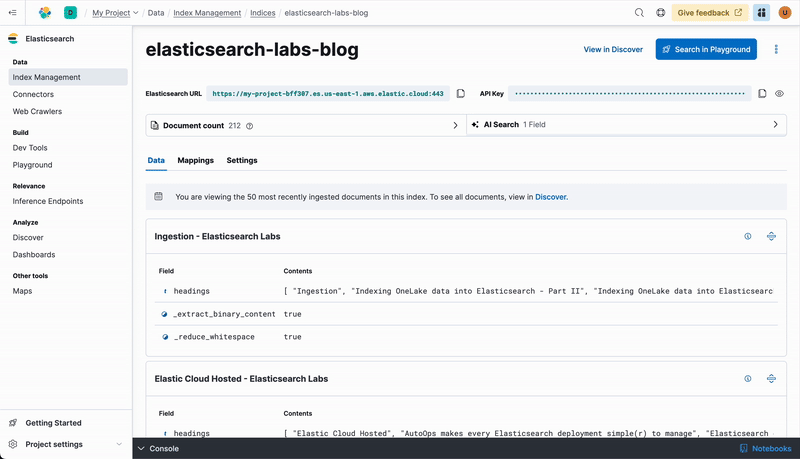
The 5 top results you get back from this semantic search look much better.
"Multilingual vector search with the E5 embedding model"
"How to search languages with compound words"
"Dataset translation with LangChain, Python & Vector Database for multilingual insights"
"Building multilingual RAG with Elastic and Mistral"
"Agentic RAG with Elasticsearch & Langchain"
Why not both? Create a hybrid search query
A more advanced example using Reciprocal Rank Fusion (RRF) is a technique used in hybrid retrieval systems to improve the relevance of search results. It combines different retrieval methods, such as lexical (traditional) search and semantic search, to enhance the overall search performance.
By leveraging RRF, the query ensures that the final list of documents is a balanced mix of the top results from both retrieval methods, thereby improving the overall relevance and diversity of the search results. This fusion technique mitigates the limitations of individual retrieval methods, providing a more comprehensive and accurate set of results.
GET elasticsearch-labs-blog/_search
{
"_source": [
"title"
],
"retriever": {
"rrf": {
"retrievers": [
{
"standard": {
"query": {
"multi_match": {
"fields": ["title","body"],
"query": "how to implement multilingual search"
}
}
}
},
{
"standard": {
"query": {
"semantic": {
"field": "semantic_text",
"query": "how to implement multilingual search"
}
}
}
}
]
}
}
}
The top 5 hits with hybrid search contain very good results, all highly relevant to how you can implement a multilingual search with Elasticsearch:
"Multilingual vector search with the E5 embedding model" "How to search languages with compound words" "Dataset translation with LangChain, Python & Vector Database for multilingual insights" "Building multilingual RAG with Elastic and Mistral" "Evaluating scalar quantization in Elasticsearch"
Next steps
Thanks for taking the time to set up semantic search for your data with Elastic Cloud. As you begin your journey with Elastic, understand some operational, security, and data components you should manage as a user when you deploy across your environment.
Ready to get started? Spin up a free 14-day trial on Elastic Cloud or try out these 15 minute hands-on learning on Search AI 101.